本文說明 BM25 相關性和評分演算法,此演算法用來計算全文檢索搜尋的搜尋分數。 BM25 相關性專屬於全文檢索搜尋。 篩選查詢、自動完成和建議的查詢、通配符搜尋和模糊搜尋查詢不會針對相關性進行評分或排名。
全文檢索搜尋中使用的評分演算法
Azure AI 搜尋服務為全文檢索搜尋提供下列評分演算法:
| 演算法 | 使用方式 | 範圍 |
|---|---|---|
BM25Similarity |
固定演算法,用於所有 2020 年 7 月以後建立的搜尋服務。 您可以設定此演算法,但無法切換至較舊的演算法 (傳統)。 | 無限制。 |
ClassicSimilarity |
默認為 2020 年 7 月之前的舊版搜尋服務。 在較舊的服務上,您可以加入 加入 BM25 ,並根據每個索引選擇 BM25 演算法。 | 0 < 1.00 |
BM25 和傳統演算法都是類似 TF-IDF 的擷取函式,使用字詞頻率 (TF) 和反轉文件頻率 (IDF) 作為變數,以計算每個文件查詢配對的相關性分數,然後用於排名結果。 雖然概念上類似於傳統演算法,如使用者研究所測量,BM25 是以產生更直覺的相符項目的機率資訊擷取為根。
BM25 提供 進階自定義選項,例如允許使用者決定相關性分數如何隨著相符字詞的字詞頻率進行調整。
BM25 排名的運作方式
相關性評分是指搜尋分數 (@search.score) 的計算,可作為目前查詢內容中項目相關性的指標。 範圍無限制。 不過,分數越高,項目的相關性就愈高。
搜尋分數會根據字串輸入和查詢的統計屬性來計算。 Azure AI 搜尋服務會尋找符合搜尋字詞的文件 (部分或全部,視 searchMode 而定),優先列出包含多個搜尋字詞執行個體的文件。 如果字詞在資料索引間很少見,但在文件內很常見,搜尋分數會更高。 這種計算相關性的方法基礎稱為 TF-IDF (或 term frequency-inverse document frequency)。
一個結果集中可以有重複的搜尋分數。 多個命中擁有相同的搜尋分數時,評分相同的項目並未定義順序,因此順序不穩定。 再次執行查詢,您可能會看到項目的位置移位,特別是當您使用免費服務或使用多個複本的可計費服務時。 若有兩個項目的分數完全相同,則無法保證哪個項目先出現。
若要打破重複分數之間的系結,您可以依分數將$orderby子句新增至第一個順序,然後依另一個可排序字段排序 (例如, $orderby=search.score() desc,Rating desc)。
只有在索引中標示為 searchable 或在查詢中標示為 searchFields 的欄位才會用於評分。 只有標示為 retrievable 的欄位,或在查詢中 select 中指定的欄位,才會在搜尋結果中與其搜尋分數一同傳回。
注意
@search.score = 1 表示未評分或未排序的結果集。 所有結果的分數都是一致的。 若查詢表單為模糊搜尋、萬用字元或 RegEx 查詢或空白搜尋,會出現未評分的結果 (search=* 有時與篩選配對,而篩選是傳回相符項目的主要方式)。
下列影片區段快轉至正式推出的排名演算法 (用於 Azure AI 搜尋服務) 說明。 您可以觀看整段影片,以取得更多背景資訊。
文字結果中的分數
每當結果進行排名時,@search.score 屬性會包含用來排序結果的值。
下表識別評分屬性、演算法和範圍。
| 搜尋方法 | 參數 | 評分演算法 | 範圍 |
|---|---|---|---|
| 全文檢索搜尋 | @search.score |
BM25 演算法,使用索引中指定的參數。 | 無限制。 |
分數變化
搜尋分數傳達相關性的一般意義,反映與相同結果集中其他文件相對的相符強度。 但是某個查詢的分數不一定會與下一個查詢的分數一致,因此當使用查詢時,您可能會注意到搜尋文件的排序方式有些小差異。 為何可能發生此情況的原因有數個說明。
| 原因 | 描述 |
|---|---|
| 相同分數 | 如果多個文件具有相同分數,其中任何一個文件可能會先出現。 |
| 資料波動性 | 當您新增、修改或刪除文件時,索引內容會有所不同。 字詞頻率會在索引更新進行處理的一段時間後變更,這會影響相符文件的搜尋分數。 |
| 多個複本 | 對於使用多個複本的服務,會以平行方式針對每個複本發出查詢。 用來計算搜尋分數的索引統計資料是根據每個複本計算的,而結果會在查詢回應中進行合併和排序。 複本大多是彼此的鏡像,但統計資料可能會由於狀態中的小差異而有所不同。 例如,一個複本可能具有影響其統計資料的已刪除文件,而這些文件是合併自其他複本。 一般而言,每個複本統計資料中的差異在越小的索引中就會越明顯。 下一節提供關於此條件的詳細資訊。 |
查詢結果的分區化影響
分區是索引的區塊。 Azure AI 搜尋服務會將每個索引分割成分區,讓新增分割區的流程更快速 (透過將分區移至新的搜尋單位)。 在搜尋服務中,分區管理是實作細節且不可設定,但知道索引分區化有助於了解排名和自動完成行為偶爾會發生的異常狀況:
排名異常:搜尋分數會先在分區層級計算,然後再彙總成單一結果集。 根據分區內容的特性,來自某個分區相符項目的排名可能會高於另一個分區中的相符項目。 如果您注意到搜尋結果中的反直覺式排名,最有可能是因分區化的影響所造成,特別是索引很小時。 您可以選擇跨整個索引全域計算分數,以避免這些排名異常情況,但這樣做會產生效能損失。
自動完成異常:自動完成查詢,其中針對部分輸入字詞的前幾個字元進行比對,接受模糊參數,可接受拼字中略有偏差。 針對自動完成,模糊比對會受限於目前分區內的字詞。 例如,如果分區包含「Microsoft」,而輸入部分字詞「micro」,則搜尋引擎會比對該分區中的「Microsoft」,但不會在保留索引其餘部分的其他分區中進行比對。
下圖顯示複本、分割區、分區和搜尋單位之間的關聯。 其中顯示單一索引如何橫跨服務中具有兩個複本和兩個分割區的四個搜尋單位範例。 四個搜尋單位皆只會儲存索引的一半分區。 左資料行中的搜尋單位會儲存分區的前半部,組成第一個分割區,而右資料行中的搜尋單位則儲存分區的第二半,組成第二個分割區。 因為有兩個複本,所以每個索引分區有兩個複本。 頂端資料列中的搜尋單位會儲存一個複本,組成第一個複本,而底部資料列中的複本則儲存另一個複本,組成第二個複本。
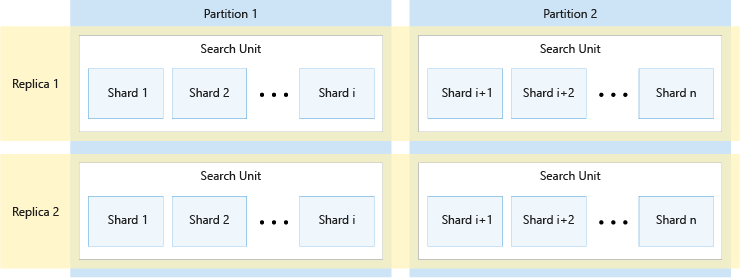
上圖只是其中一個範例。 另外還可能會有許多分割區和複本的組合,最多 36 個總搜尋單位。
注意
複本數和資料分割數可整除 12 (明確來說就是 1、2、3、4、6、12)。 Azure AI 搜尋服務會將每個索引預先劃分成 12 個分區,以便將其平均散佈到所有分割區。 例如,如果您的服務有三個資料分割,而您建立了索引,則每個資料分割將會包含 4 個該索引的分區。 Azure AI 搜尋服務將索引分區的方法是實作細節,有可能在未來版本中變更。 雖然現在分區數為 12,但您不應預期未來該數字永遠都會是 12。
評分統計資料和黏性工作階段
針對可擴縮性,Azure AI 搜尋服務會透過分區化流程水平散發每個索引,這表示會實際分開索引的各部分。
預設會根據「分區內資料」的統計屬性來計算文件的分數。 這種方法對大型資料主體通常不是問題,而且與根據所有分區的資訊來計算分數相比,可提供更佳的效能。 儘管如此,使用此效能最佳化會導致最終分屬不同分區中的兩份非常類似的文件 (或甚至是完全相同的文件) 最後得到不同的相關性分數。
如果您偏好根據所有分區的統計屬性來計算分數,您可以將 scoringStatistics=global 新增為查詢參數 (或將 "scoringStatistics": "global" 新增為查詢要求的主體參數)。
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "<query string>",
"scoringStatistics": "global"
}
使用 scoringStatistics,可確保相同複本中的所有分區都提供相同的結果。 也就是說,不同的復本可能會彼此稍有不同,因為它們一律會隨著索引的最新變更而更新。 在某些情況下,您可能會希望使用者在「查詢工作階段」期間取得更一致的結果。 在這種情況下,您可以提供 sessionId 作為查詢的一部分。
sessionId 是您建立的唯一字串,可參考唯一的使用者工作階段。
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "<query string>",
"sessionId": "<string>"
}
只要使用相同的 sessionId,就會儘可能嘗試以相同的複本為目標,增加使用者所見結果的一致性。
注意
不斷重複使用相同的 sessionId 值可能會干擾複本間的要求負載平衡,並對搜尋服務的效能造成負面影響。 做為 sessionId 的值不能以 '_' 字元開頭。
相關性微調
在 Azure AI 搜尋中,針對關鍵詞搜尋和混合式查詢的文字部分,您可以設定 BM25 演演算法參數,並透過下列機制來微調搜尋相關性並提升搜尋分數。
| 方法 | 實作 | 描述 |
|---|---|---|
| BM25 演算法組態 | 搜尋索引 | 設定文件長度和字詞頻率如何影響相關性分數。 |
| 評分設定檔 | 搜尋索引 | 根據內容特性,提供用於提高相符搜尋分數的準則。 例如,您可以根據其營收潛力、促銷較新的專案,或提升庫存時間過長的專案來提升相符專案。 評分設定檔是索引定義的一部分,由加權欄位、函數和參數組成。 您可以使用評分設定檔變更來更新現有的索引,而不會產生索引重建。 |
| 語意排名 | 查詢要求 | 將機器閱讀理解套用至搜尋結果,進而將語意上更相關的結果提升至頂端。 |
| featuresMode 參數 | 查詢要求 | 此參數主要用於解除封裝 BM25 排名分數,但可用於提供 自定義評分解決方案的程式代碼中。 |
featuresMode 參數 (預覽版)
搜尋檔 要求支援 featuresMode 參數,提供有關欄位層級 BM25 相關性分數的詳細數據。 雖然 @searchScore 會針對文件全部計算 (此文件與該查詢內容的相關性),但 featuresMode 可揭露個別欄位相關資訊,並以 @search.features 結構表示。 結構包含查詢中使用的所有欄位 (查詢中透過 searchFields 的特定欄位,或索引中屬性為可搜尋的所有欄位)。
針對每個欄位,@search.features 為您提供下列值:
- 欄位顯示的不重複權杖數
- 與查詢字詞相對的相似度分數,或欄位內容相似度的量值
- 字詞頻率或查詢字詞在欄位中找到的次數
針對以「描述」和「標題」欄位為目標查詢時,包含 @search.features 的回應可能如下所示:
"value": [
{
"@search.score": 5.1958685,
"@search.features": {
"description": {
"uniqueTokenMatches": 1.0,
"similarityScore": 0.29541412,
"termFrequency" : 2
},
"title": {
"uniqueTokenMatches": 3.0,
"similarityScore": 1.75451557,
"termFrequency" : 6
}
}
}
]
您可以在自訂評分解決方案中取用這些資料點,或使用資訊來偵錯搜尋相關性問題。
featuresMode 參數並未記載於 REST API 中,但您可以在預覽 REST API 呼叫中使用它,以搜尋文字 (關鍵詞) 搜尋已排名為 BM25 的文字 (關鍵詞) 搜尋。
全文檢索查詢回應中的排名結果數目
根據預設,如果您未使用分頁,搜尋引擎會傳回全文檢索搜尋的前 50 個最高排名相符項目。 您可以使用 top 參數傳回較小的或較大的項目數(單一回應中最多 1,000 個)。 您可以使用 skip 和 next 來分頁結果。 分頁會決定每個邏輯頁面上的結果數目,並支援內容流覽。 如需詳細資訊,請參閱 圖形搜尋結果。
如果您的全文檢索查詢是混合式查詢的一部分,您可以將 設定maxTextRecallSize為增加或減少查詢文字端的結果數目。
全文檢索搜尋受限於最多 1,000 個相符項目 (請參閱 API 回應限制)。 一旦找到 1,000 個相符項目,搜尋引擎就不再尋找其他相符項目。