語意模型的累加式重新整理和即時資料
Power BI 中語意模型的累加式重新整理和實時數據提供有效率的方式來處理動態數據,並改善模型重新整理效能。 藉由自動化數據分割建立和管理,累加式重新整理可減少需要重新整理的數據量,並允許包含實時數據。 本文說明如何在Power BI 中設定和使用累加式重新整理功能,以擷取快速行動的數據並增強效能。
透過提供自動化的磁碟分割建立和經常載入新資料和更新資料的語意模型資料表管理,以累加式重新整理會擴充預定的重新整理作業。 針對大多數模型,一個或多個資料表包含經常變更,並以指數方式成長的交易資料,例如關聯式或星型資料庫結構描述的事實資料表。 可分割資料表的累加式重新整理原則、僅重新整理最新匯入的磁碟分割,以及選擇性地針對即時資料使用另一個 DirectQuery 磁碟分割等措施,都可以大幅減少必須重新整理的資料量。 同時,此原則可確保資料來源的最新變更包含在查詢結果中。
使用累加式重新整理和即時資料的優點:
- 快速變更的資料僅需要較少的重新整理週期。 DirectQuery 模式會在處理查詢時取得最新的資料更新,而不需要高重新整理頻率。
- 重新整理更為快速。 只需要重新整理已變更的最新資料。
- 重新整理更為可靠。 不需要長時間執行與揮發性資料來源的連線。 加速來源資料查詢的執行速度,減少網路問題干擾的可能性。
- 減少資源耗用量。 較少的重新整理資料可減少記憶體和其他資源在 Power BI 和資料來源系統的整體耗用。
- 已啟用大型語意模型。 可能內含數十億個資料列的語意模型將得以成長,而不需要使用各種重新整理作業完全重新整理整個模型。
- 設定十分簡單。 累加式重新整理原則在 Power BI Desktop 中只定義部分工作。 當 Power BI Desktop 發佈報表時,服務會在每次重新整理時自動套用這些原則。
將 Power BI Desktop 模型發佈到服務時,新模型中的每個資料表都有單一磁碟分割。 該單一磁碟分割包含該資料表的所有資料列。 如果資料表很大 (例如有數千萬個以上的資料列),則該資料表的重新整理可能需要很長的時間,並耗用過多的資源。
透過累加式重新整理,服務會進行動態分割,並將需要經常重新整理的資料與可以較不頻繁重新整理的資料分開。 系統會使用 Power Query 日期/時間參數與保留的區分大小寫名稱 RangeStart 和 RangeEnd 來篩選資料表資料。 當您在 Power BI Desktop 中設定累加式重新整理時,這些參數只會用於篩選載入至模型的短期資料。 當 Power BI Desktop 將報表發佈至 Power BI 服務時,服務會使用第一次重新整理作業建立累加式重新整理和歷史磁碟分割,並根據累加式重新整理原則設定選擇性地建立即時 DirectQuery 磁碟分割。 接著,服務會覆寫參數值,根據每個資料列的日期/時間值來篩選和查詢每個磁碟分割的資料。
每次後續重新整理時,查詢篩選只會傳回參數動態定義之重新整理期間內的資料列。 重新整理期間內具有日期/時間的資料列會重新整理。 具有日期/時間的資料列不會再排入重新整理期間,然後成為歷史記錄期間的一部分,不會重新整理。 如果累加式重新整理原則中包含即時 DirectQuery 磁碟分割,系統也會更新其篩選,以便接收重新整理期間之後發生的任何變更。 重新整理和歷史記錄期間都會向前復原。 建立新的累加式重新整理磁碟分割時,不再位於重新整理期間內的重新整理磁碟分割,會變成歷史磁碟分割。 經過一段時間後,歷史磁碟分割會因相互合併而變得較不精細。 當歷史磁碟分割不再處於原則所定義的歷史期間時,就會完全從模型中移除。 此行為稱為滾動視窗模式。
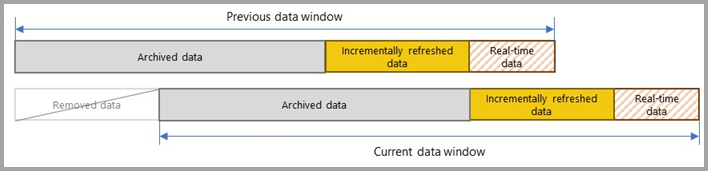
累加式重新整理的好處在於,服務會根據您定義的累加式重新整理原則,為您處理所有重新整理。 事實上,從原則中建立的流程和磁碟分割不會顯示在服務中。 在大部分情況下,僅需要定義完善的累加式重新整理原則,即可大幅改善模型重新整理效能。 不過,Premium 容量中的模型僅支援即時 DirectQuery 磁碟分割。 Power BI Premium 也會透過 XML for Analysis (XMLA) 端點啟用更進階的磁碟分割和重新整理案例。
需求
下一節將說明支援的方案和資料來源。
支援的方案
Power BI Premium、Premium Per User、Power BI Pro 和 Power BI Embedded 模型支援累加式重新整理。
只有 Power BI Premium、Premium Per User 和 Power BI Embedded 模型才支援使用 DirectQuery 即時取得最新資料。
支援的資料來源
累加式重新整理和即時資料最適合結構化的關聯資料來源,例如 SQL Database 和 Azure Synapse,但也適用於其他資料來源。 在任何情況下,您的資料來源都必須支援下列項目:
日期篩選 - 資料來源必須支援部分依日期篩選資料的機制。 對於關係型來源,這通常是目標數據表上日期/時間或整數數據類型的日期數據行。 RangeStart 和 RangeEnd 參數,必須是日期/時間數據類型,根據日期數據行篩選數據表數據。 針對以 yyyymmdd 形式表示之整數 Surrogate 索引鍵的日期資料行,您可以建立函數來轉換 RangeStart 和 RangeEnd 參數中的日期/時間值,以比對日期資料行的整數 Surrogate 索引鍵。 若要深入瞭解,請參閱 設定累加式重新整理和實時數據 - 將 DateTime 轉換為整數。
對於其他資料來源,RangeStart 和 RangeEnd 參數必須以某種方式傳遞至資料來源,才能進行篩選。 對於依日期整理檔案和資料夾的檔案型資料來源,RangeStart 和 RangeEnd 參數可用來篩選檔案和資料夾,以選取要載入的檔案。 針對 Web 型數據源,RangeStart 和 RangeEnd 參數可以整合到 HTTP 要求中。 例如,下列查詢可用於從 AppInsights 執行個體累加式重新整理追蹤:
let
strRangeStart = DateTime.ToText(RangeStart,[Format="yyyy-MM-dd'T'HH:mm:ss'Z'", Culture="en-US"]),
strRangeEnd = DateTime.ToText(RangeEnd,[Format="yyyy-MM-dd'T'HH:mm:ss'Z'", Culture="en-US"]),
Source = Json.Document(Web.Contents("https://api.applicationinsights.io/v1/apps/<app-guid>/query",
[Query=[#"query"="traces
| where timestamp >= datetime(" & strRangeStart &")
| where timestamp < datetime("& strRangeEnd &")
",#"x-ms-app"="AAPBI",#"prefer"="ai.response-thinning=true"],Timeout=#duration(0,0,4,0)])),
TypeMap = #table(
{ "AnalyticsTypes", "Type" },
{
{ "string", Text.Type },
{ "int", Int32.Type },
{ "long", Int64.Type },
{ "real", Double.Type },
{ "timespan", Duration.Type },
{ "datetime", DateTimeZone.Type },
{ "bool", Logical.Type },
{ "guid", Text.Type },
{ "dynamic", Text.Type }
}),
DataTable = Source[tables]{0},
Columns = Table.FromRecords(DataTable[columns]),
ColumnsWithType = Table.Join(Columns, {"type"}, TypeMap , {"AnalyticsTypes"}),
Rows = Table.FromRows(DataTable[rows], Columns[name]),
Table = Table.TransformColumnTypes(Rows, Table.ToList(ColumnsWithType, (c) => { c{0}, c{3}}))
in
Table
設定累加式重新整理時,會根據 RangeStart 和 RangeEnd 參數,針對資料來源執行包含日期/時間篩選的 Power Query 運算式。 如果在初始來源查詢之後的查詢步驟中指定篩選條件,請務必將查詢折疊結合初始查詢步驟與參考 RangeStart 和 RangeEnd 參數的步驟。 例如,在下列查詢表達式中, Table.SelectRows 會折疊,因為它會緊接著 Sql.Database 步驟,而 SQL Server 支援折疊:
let
Source = Sql.Database("dwdev02","AdventureWorksDW2017"),
Data = Source{[Schema="dbo",Item="FactInternetSales"]}[Data],
#"Filtered Rows" = Table.SelectRows(Data, each [OrderDateKey] >= Int32.From(DateTime.ToText(RangeStart,[Format="yyyyMMdd"]))),
#"Filtered Rows1" = Table.SelectRows(#"Filtered Rows", each [OrderDateKey] < Int32.From(DateTime.ToText(RangeEnd,[Format="yyyyMMdd"])))
in
#"Filtered Rows1"
不需要最終查詢來支援折疊。 例如,在下列表達式中,我們使用非折疊的 NativeQuery,但將 RangeStart 和 RangeEnd 參數直接整合到 SQL 中:
let
Query = "select * from dbo.FactInternetSales where OrderDateKey >= '"& Text.From(Int32.From( DateTime.ToText(RangeStart,"yyyyMMdd") )) &"' and OrderDateKey < '"& Text.From(Int32.From( DateTime.ToText(RangeEnd,"yyyyMMdd") )) &"' ",
Source = Sql.Database("dwdev02","AdventureWorksDW2017"),
Data = Value.NativeQuery(Source, Query, null, [EnableFolding=false])
in
Data
不過,如果累加式重新整理原則包含使用 DirectQuery 取得即時資料,就無法使用非折疊轉換。 如果是不含實時數據的純匯入模式原則,查詢混搭引擎可能會補償並套用本機篩選,這需要從數據源擷取數據表的所有數據列。 這可能會導致累加式重新整理變慢,而且程式可能會用盡 Power BI 服務 或內部部署數據閘道中的資源,從而有效地破壞累加式重新整理的目的。
因為不同資料類型資料來源的查詢折疊支援皆有所不同,所以您應該執行驗證,以確保針對資料來源執行的查詢中包含篩選邏輯。 在大部分情況下,Power BI Desktop 會在定義累加式重新整理原則時,嘗試為您執行此驗證。 對於 SQL Database、Azure Synapse、Oracle 和 Teradata 等 SQL 型資料來源而言,此驗證十分可靠。 不過,其他資料來源可能必須追蹤查詢才能驗證。 如果 Power BI Desktop 無法確認查詢,[Incremental refresh policy configuration] 對話框中會顯示警告。
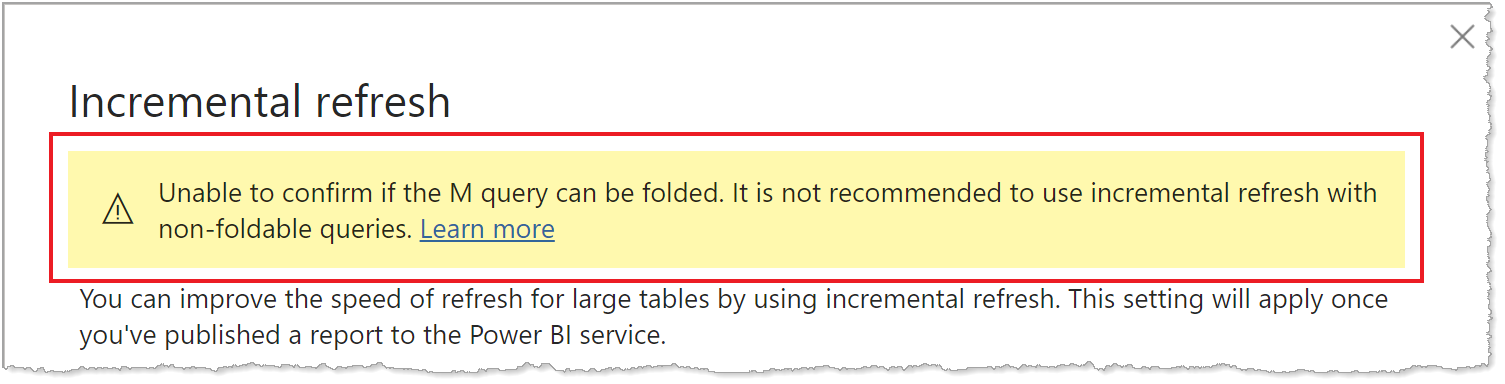
如果您看到此警告而想要驗證是否發生了必要的查詢折疊,則可使用 Power Query 診斷功能,或使用資料來源支援的工具來追蹤查詢,例如 SQL Profiler。 如果查詢折疊未發生,請確認篩選邏輯包含在要傳遞至資料來源的查詢中。 如果未包含,則查詢可能會包含阻礙折疊的轉換。
設定累加式重新整理解決方案之前,請務必詳細閱讀並瞭解 Power BI Desktop 中的查詢折疊指引 (英文) 和Power Query 查詢折疊。 這些文章可協助您判斷資料來源和查詢是否支持查詢折疊。
單一資料來源
當您使用 Power BI Desktop 設定累加式重新整理和即時資料,或透過 XMLA 端點使用表格式模型指令碼語言 (TMSL) 或表格式物件模型 (TOM) 來設定進階解決方案時,所有磁碟分割 (不論匯入或 DirectQuery) 都必須從單一來源查詢資料。
其他資料來源類型
藉由使用更多自訂查詢函數和查詢邏輯,累加式重新整理可以搭配其他類型的資料來源使用,如果根據 RangeStart 和 RangeEnd 篩選,則可以傳入單一查詢,例如儲存在資料夾中的 Excel 活頁簿檔案、SharePoint 中的檔案和 RSS 摘要。 請記住,這些是需要進一步自訂和測試的進階案例,且範圍超出本文所描述的內容。 請務必檢查本文稍後的社群一節,以取得有關如何取得針對特殊案例使用累加式重新整理之詳細資訊的建議。
時間限制
不論是否進行累加式重新整理,Power BI Pro 模型都有兩個小時的重新整理時間限制,且不支援使用 DirectQuery 取得即時資料。 針對 Premium 容量中的模型,時間限制為五小時。 重新整理作業需要大量進程和記憶體。 因為服務會在記憶體中維護模型的快照集,直到重新整理作業完成為止,所以比起模型所需的記憶體量,完整的重新整理作業可能會用上大約兩倍的記憶體。 重新整理作業也可能需要大量程式,耗用大量的可用CPU資源。 重新整理作業也必須依賴資料來源的動態連線,以及這些資料來源系統快速傳回查詢輸出的能力。 時間限制是用於限制可用資源遭到過度耗用的保護措施。
注意
使用 Premium 容量時,透過 XMLA 端點執行的重新整理作業沒有時間限制。 若要深入了解,請參閱使用 XMLA 端點的進階累加式重新整理 (英文)。
因為累加式重新整理會最佳化模型內磁碟分割層級的重新整理作業,所以可以大幅降低資源耗用量。 同時,即使使用累加式重新整理,除非重新整理作業經過 XMLA 端點,否則會受相同的兩小時和五小時限制所制約。 有效的累加式重新整理原則不僅可減少使用重新整理作業處理的資料量,也會減少模型中儲存的不必要歷史資料量。
査詢也可以受限於資料來源預設的時間限制。 大部分的關聯式資料來源都允許覆寫 Power Query M 運算式中的時間限制。 例如,下列表達式會使用 SQL Server 數據存取函 式,將 CommandTimeout 設定為兩小時。 原則範圍所定義的每個週期都會提交查詢,以觀察命令逾時設定:
let
Source = Sql.Database("myserver.database.windows.net", "AdventureWorks", [CommandTimeout=#duration(0, 2, 0, 0)]),
dbo_Fact = Source{[Schema="dbo",Item="FactInternetSales"]}[Data],
#"Filtered Rows" = Table.SelectRows(dbo_Fact, each [OrderDate] >= RangeStart and [OrderDate] < RangeEnd)
in
#"Filtered Rows"
對於 Premium 容量中可能包含數十億個資料列的極大型模型,您可以啟動初始重新整理作業。 啟動可允許服務為模型建立資料表和磁碟分割物件,但不會將資料載入和處理至任何磁碟分割中。 藉由使用 SQL Server Management Studio,您可以將磁碟分割設定為個別、循序或平行處理,以減少單一查詢中傳回的資料量,同時避開五小時的時間限制。 若要深入了解,請參閱進階累加式重新整理 - 防止初始完全重新整理時逾時。
目前日期與時間
目前日期和時間預設會根據重新整理時的國際標準時間 (UTC) 決定。 針對隨選、排程和 REST API 重新整理,您可以在 [重新整理] 下設定不同的時區,以在判斷目前日期和時間時納入考慮。 例如,已設定時區且在太平洋時間 (美國和加拿大) 下午 8:00 發生的重新整理,將會根據太平洋時間 (而非 UTC) 來判斷目前日期,這會在隔天傳回。
![[排程重新整理] 對話方塊的螢幕擷取畫面,其中顯示 [時區] 輸入欄位](media/incremental-refresh-overview/time-zone.png)
未透過 Power BI 服務叫用的重新整理作業,例如 XMLA TMSL 重新整理命令,不考慮時區設定,預設為 UTC。
設定累加式重新整理和即時資料
本節說明設定累加式重新整理和即時資料的重要概念。 當您準備好取得更詳細的逐步指示時,請參閱 設定累加式重新整理和實時數據。
您會在 Power BI Desktop 中完成累加式重新整理設定。 對於大多數模型來說,這只需要幾項作業即可完成。 但請謹記下列重點:
- 發佈至 Power BI 服務之後,您就無法從 Power BI Desktop 再次發佈相同的模型。 重新發佈會移除模型中已有的任何現有磁碟分割和資料。 如果您要發佈至 Premium 容量,可以使用開放原始碼 ALM 工具組,或使用 TMSL 等工具進行後續中繼資料結構描述變更。 若要深入了解,請參閱進階累加式重新整理 - 僅限中繼資料的部署。
- 發佈至 Power BI 服務之後,您無法以 .pbix 格式將模型下載回 Power BI Desktop。 因為服務中的模型可能會成長至極大規模,所以在一般桌面電腦上下載並開啟模型是不切實際的。
- 使用 DirectQuery 取得即時資料時,您無法將模型發佈至非 Premium 工作區。 只有 Power BI Premium 才支援使用即時資料的累加式重新整理。
建立參數
若要在 Power BI Desktop 中設定累加式重新整理,您必須先使用保留的區分大小寫名稱 RangeStart 和 RangeEnd 建立兩個 Power Query 日期/時間參數。 這些參數定義於 Power Query 編輯器的 [管理參數] 對話方塊中,一開始是用來篩選載入至 Power BI Desktop 模型資料表的資料,以僅將那些在該期間內具有日期/時間的資料列包含在內。
RangeStart 代表最舊或最早的日期/時間,而 RangeEnd 代表最新的或最近的日期/時間。 將模型發佈至服務之後,服務會自動覆寫 RangeStart 和 RangeEnd,以查詢累加式重新整理原則設定中指定之重新整理期間所定義的資料。
例如,FactInternetSales 資料來源資料表每天平均會有 10,000 個新資料列。 若要限制最初載入 Power BI Desktop 模型中的資料列數目,請在 RangeStart 和 RangeEnd 之間指定兩天的期間。
![[管理參數] 對話方塊的螢幕擷取畫面,其中顯示 RangeStart 和 RangeEnd 參數。](media/incremental-refresh-overview/manage-parameters.png)
篩選資料
定義 RangeStart 和 RangeEnd 參數後,您會在資料表的日期資料行上套用自訂日期篩選。 當您選取 [套用]時,您套用的篩選會選取載入模型的資料子集。
![已選取 [自訂篩選] 的資料行快顯功能表螢幕擷取畫面](media/incremental-refresh-overview/custom-filter.png)
在 FactInternetSales 範例中,根據參數建立篩選並套用步驟之後,會將兩天的資料 (大約 20,000 個資料列) 載入模型。
定義原則
套用篩選並將資料子集載入模型之後,您可以定義資料表的累加式重新整理原則。 將模型發佈至服務之後,服務會使用此原則來建立及管理資料表分割,並執行重新整理作業。 若要定義原則,您可以使用累加式重新整理和即時資料對話方塊來指定必要和選擇性設定。
![[累加式重新整理和即時資料] 對話方塊的螢幕擷取畫面,其中顯示 [累加式重新整理此資料表] 選項。](media/incremental-refresh-overview/incremental-refresh-dialog.png)
Table
[選取表格] 列表框預設為您在[表格檢視]中選取的表格。 使用滑桿啟用資料表的累加式重新整理。 如果資料表的 Power Query 運算式不包含以 RangeStart 和 RangeEnd 參數為基礎的篩選,則無法使用切換開關。
必要的設定
[Archive data starting before refresh date] 設定會決定歷史期間,模型中會包含該期間內具有日期/時間的資料列,以及目前未完成歷史期間的資料列,以及截至目前日期和時間之重新整理期間中的資料列。
例如,如果您指定五年,資料表會將過去五年的歷史資料儲存在年份磁碟分割中。 資料表也會包含目前年份的資料 (以季、月或日分割),最多可涵蓋重新整理期間。
針對 Premium 容量中的模型,您可以使用此設定所決定的細微性,選擇性地進行重新整理備份的歷史磁碟分割。 若要深入了解,請參閱進階累加式重新整理 - 磁碟分割。
[Incrementally refresh data starting before refresh date] 設定會決定累加式重新整理期間,該期間會將內含日期/時間的所有資料列都包含於重新整理磁碟分割中,並使用各個重新整理作業進行重新整理。
例如,如果您指定三天的重新整理期間,則每次進行重新整理作業時,服務都會覆寫 RangeStart 和 RangeEnd 參數,以在三天期間內建立具有日期/時間的資料列查詢,而期間的開頭和結尾,則取決於目前的日期和時間。 系統會重新整理過去三天內 (最多至目前的重新整理作業時間) 具有日期/時間的資料列。 使用這種類型的原則,您可以預期服務中的 FactInternetSales 模型資料表 (其平均每天有 10,000 個新資料列),在每次重新整理作業時大約重新整理 30,000 個資料列。
指定只包含確保正確報告所需之最小資料列數目的期間。 當您為多個資料表定義原則時,即使每個資料表定義了不同的儲存和重新整理期間,您也必須使用相同的 RangeStart 和 RangeEnd 參數。
選擇性設定
[使用 DirectQuery 即時取得最新資料 (僅適用於進階版)] 設定可讓您使用 DirectQuery,從資料來源上擷取所選資料表的最新變更,而不受限於累加式重新整理期間。 所有日期/時間晚於累加式重新整理期間的資料列都會包含在 DirectQuery 磁碟分割中,並使用每個模型查詢從資料來源加以擷取。
例如,如果啟用此設定,在每個重新整理作業中,服務仍會覆寫 RangeStart 和 RangeEnd 參數,以在重新整理期間之後建立具有日期/時間的資料列查詢,且開始時間取決於目前的日期和時間。 目前重新整理作業時間之後具有日期/時間的資料列同時也會包含在內。 透過這種類型的原則,服務中的 FactInternetSales 模型資料表會包含最新的資料更新。
[只重新整理完整天數] 設定可確保整日的所有資料列都包含在重新整理作業中。 除非您啟用 [使用 DirectQuery 即時取得最新資料 (僅適用於進階版)] 設定,否則此設定是選用設定。 例如,假設您的重新整理排定在每天早上上午 4:00 執行。 如果在午夜到上午 4:00 這四個小時內,資料來源資料表中出現新的資料列,您就不會想將這些資料列包含在重新整理作業內。 一些商業計量,如石油和天然氣行業每天的桶數,對部分日子沒有意義。 另一個範例是重新整理財務系統中的資料,而在財務系統中,會在該月的第十二個日曆日期核准上個月的資料。 您可以將重新整理期間設定為一個月,並將重新整理排程在當月第十二天執行。 舉例來說,核取此選項後,即會在 2 月 12 日重新整理 1 月資料。
請記住,除非針對非UTC時間設定 [重新整理] 下的時區,否則服務中的重新整理作業會以UTC時間執行,以判斷有效日期和完成期間。
[偵測資料變更] 設定可啟用更具選擇性的重新整理。 您可以選取用來識別及重新整理資料出現變更的日期/時間資料行。 此設定假設這類資料行存在於資料來源中,通常用於稽核用途。 此資料行不應該與使用 RangeStart 和 RangeEnd 參數來分割資料的資料行相同。 會評估此資料行在累加式範圍之每個週期的最大值。 如果自上次重新整理之後就沒有變更期間,那麼就不需要重新整理期間,這可能會進一步將累加式重新整理的天數從三天減少為一天。
目前設計需要持續保存要偵測資料變更的資料行,並將其快取到記憶體。 下列技術可用來減少基數和記憶體耗用量:
- 重新整理時只保存數據行的最大值,或許是使用 Power Query 函式。
- 根據您的重新整理頻率需求,將精確度降低到可接受的層級。
- 定義自訂查詢,透過使用 XMLA 端點來偵測資料變更,並避免完全保存資料行值。
在某些情況下,可以進一步增強啟用 [ 偵測數據變更 ] 選項。 例如,您可能想要避免在記憶體內部快取中保存最後更新資料行,或啟用藉由擷取、轉換和載入 ETL 程序備妥設定/或指令資料表的案例,以只標記需要重新整理的資料分割。 在這類情況下,請針對 Premium 容量使用 TMSL 和/或 TOM 來覆寫偵測資料變更行為。 若要深入了解,請參閱進階累加式重新整理 - 偵測資料變更的自訂查詢。
發佈
設定累加式重新整理原則之後,您會將模型發佈至服務。 發佈完成時,您可以在模型上執行初始重新整理作業。
注意
具有累加式重新整理原則以使用 DirectQuery 即時取得最新資料的語意模型,只能發佈至 Premium 工作區。
對於發佈至指派給 Premium 容量工作區的模型,如果您認為模型會成長超過 1 GB,您可以改善重新整理作業效能,並藉由啟用大型語意模型儲存格式設定,確保模型不會在服務中執行第一次重新整理作業之前,啟用「大型語意模型」儲存格式設定來達到最大大小限制。 若要深入了解,請參閱 Power BI Premium 中的大型模型。
重要
在 Power BI Desktop 將模型發佈至服務之後,您就無法將 .pbix 下載回來。
Refresh
發佈至 Power BI 服務之後,您將對模型執行初始重新整理作業。 此重新整理應該是個別的 (手動) 重新整理,以便讓您監視進度。 初始重新整理作業可能需要相當長的時間才能完成。 作業必須建立磁碟分割、載入歷史資料、建立或重建關聯性和階層等物件,以及重新計算已計算物件。
因為後續的重新整理作業 (無論是個別或排程) 只會重新整理累加式重新整理磁碟分割,所以都會比初始重新整理更快。 其他處理作業仍必須發生 (例如合併磁碟分割和重新計算),但所需時間通常比初始重新整理要少得多。
自動報表重新整理
針對透過具有累加式重新整理原則的模型,以使用 DirectQuery 即時取得最新資料的報告,最好是以固定間隔或根據變更偵測來啟用自動頁面重新整理,以便讓報表在不出現延遲的情況下包含最新資料。 若要深入了解,請參閱 Power BI 中的自動頁面重新整理 (英文)。
進階累加式重新整理
如果您的模型位於已啟用 XMLA 端點的 Premium 容量上,則可針對進階案例進一步擴充累加式重新整理。 例如,您可以使用 SQL Server Management Studio 來檢視和管理磁碟分割、啟動初始重新整理作業,或重新整理已備份的歷史磁碟分割。 若要深入了解,請參閱使用 XMLA 端點的進階累加式重新整理 (英文)。
社群
Power BI 擁有充滿活力的社群,MVP、BI 專業人員和同行在討論群組、影片、部落格等中分享專長。 瞭解累加式重新整理時,請參閱下列資源: