一對一關聯性指引
本文以您作為使用 Power BI Desktop 的數據模型工具為目標。 它提供使用一對一模型關聯性的指引。 當兩個數據表都包含一般和唯一值的數據行時,可以建立一對一關聯性。
注意
本文未涵蓋模型關聯性的簡介。 如果您不熟悉關聯性、其屬性或設定方式,建議您先閱讀 Power BI Desktop 中的模型關聯性一文。
您也必須瞭解星型架構設計。 如需詳細資訊,請參閱了解星型結構描述及其對 Power BI 的重要性。
有兩個案例牽涉到一對一關聯性:
跨數據表的數據列數據:單一商務實體或主體會載入為兩個(或更多)模型數據表,可能是因為它們的數據源來自不同的數據存放區。 此案例對於維度類型數據表而言可能很常見。 例如,主要產品詳細數據會儲存在營運銷售系統中,而補充產品詳細數據則儲存在不同的來源中。
不過,不尋常的是,您會將兩個事實類型數據表與一對一關聯性建立關聯性。 這是因為這兩個事實類型數據表都需要有相同的維度和粒度。 此外,每個事實類型數據表都需要唯一的數據行,才能建立模型關聯性。
變質維度
當事實類型數據表中的數據行用於篩選或分組時,您可以考慮在個別數據表中提供這些數據行。 如此一來,您會將用於篩選或分組的數據行與用來摘要事實數據列的數據行分開。 此區隔可以:
- 減少儲存空間
- 簡化模型計算
- 參與改善的查詢效能
- 為您的報表作者提供更直覺的 [字段 ] 窗格體驗
請考慮將銷售訂單詳細數據儲存在兩個數據行的來源銷售數據表。
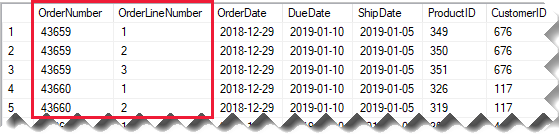
OrderNumber 資料行會儲存訂單號碼,而 OrderLineNumber 資料行會儲存訂單內的一連串行。
在下列模型圖表中,請注意訂單編號和訂單行號數據行數據行尚未載入至 Sales 數據表。 相反地,其值會用來建立名為 SalesOrderLineID 的 Surrogate 索引鍵數據行。 (索引鍵值的計算方式是將訂單編號乘以 1000,然後加入訂單行號。
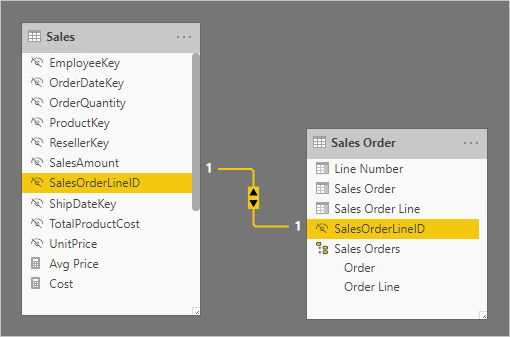
Sales Order 數據表為報表作者提供了豐富的體驗,其中包含三個數據行: Sales Order、 Sales Order Line 和 Line Number。 它也包含階層。 這些數據表資源支援需要篩選、分組或向下切入訂單和訂單行的報表設計。
由於 Sales Order 數據表衍生自銷售數據,因此每個數據表中的數據列數目應該完全相同。 此外,每個 SalesOrderLineID 資料行之間應該有相符的值。
跨數據表的數據列數據
請考慮涉及兩個一對一相關維度類型數據表的範例:Product 和 Product Category。 每個數據表都代表匯入的數據,並具有包含唯一 值的 SKU (存貨單位)數據行。
以下是兩個數據表的部分模型圖表。
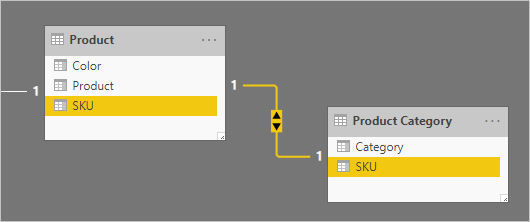
第一個數據表名為 Product,其中包含三個數據行: Color、 Product 和 SKU。 第二個數據表名為 Product Category,其中包含兩個數據行:Category 和 SKU。 一對一關聯性會關聯兩 個 SKU 數據行。 兩個方向的關聯性會篩選,這一律為一對一關聯性的情況。
為了協助描述關聯性篩選傳播的運作方式,已修改模型圖表以顯示數據表數據列。 本文中的所有範例都是以此數據為基礎。
注意
您無法在 Power BI Desktop 模型圖表中顯示資料表資料列。 本文中已完成,可支援具有清楚範例的討論。
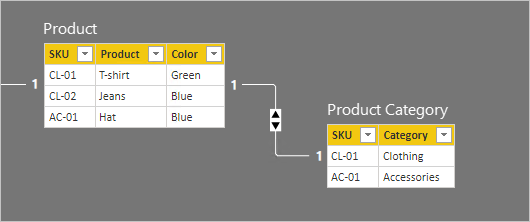
這兩個資料表的數據列詳細資料會在下列點符清單中描述:
- Product 數據表有三個數據列:
- SKU CL-01, 產品 T 恤, 色彩 綠色
- SKU CL-02, 產品 牛仔褲, 色彩 藍色
- SKU AC-01、 Product Hat、 Color Blue
- Product Category 數據表有兩個數據列:
- SKU CL-01, 類別 服裝
- SKU AC-01, 類別 配件
請注意, 產品類別 目錄數據表不包含產品 SKU CL-02 的數據列。 我們將在本文稍後討論此遺漏數據列的後果。
在 [ 欄位 ] 窗格中,報表作者會在兩個數據表中找到產品相關欄位: [產品 ] 和 [產品類別]。
讓我們看看當這兩個數據表的欄位新增至數據表視覺效果時會發生什麼事。 在此範例中 ,SKU 數據行來自 Product 數據表。
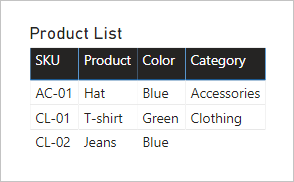
請注意, 產品 SKU CL-02 的 Category 值是 BLANK。 這是因為此產品的產品類別目錄數據表中沒有數據列。
建議
可能的話,建議您避免在數據列數據跨越模型數據表時建立一對一模型關聯性。 這是因為此設計可以:
- 參與欄位窗格雜亂,列出比必要更多的數據表
- 讓報表作者難以尋找相關的欄位,因為它們分散到多個數據表
- 限制建立階層的能力,因為其層級必須以相同數據表中的數據 行為基礎
- 在數據表之間沒有完全相符的數據列時產生非預期的結果
特定建議會根據一對一關係是 來源群組 內部或 跨來源群組而有所不同。 如需關聯性評估的詳細資訊,請參閱 Power BI Desktop 中的模型關聯性(關聯性評估)。
來源群組內一對一關聯性
當數據表之間有一對一 的來源群組 關聯性時,建議將數據合併成單一模型數據表。 其完成方式是合併 Power Query 查詢。
下列步驟提供合併和模型化一對一相關數據的方法:
合併查詢:合併這兩個查詢時,請考慮每個查詢中的數據完整性。 如果一個查詢包含一組完整的數據列(例如主要清單),請將另一個查詢與它合併。 設定合併轉換以使用 左外部聯結,這是預設聯結類型。 此聯結類型可確保您將保留第一個查詢的所有數據列,並以第二個查詢的任何相符數據列加以補充。 將第二個查詢的所有必要數據行展開至第一個查詢。
停用查詢載入:請務必 停用第二個查詢的載入 。 如此一來,它就不會將結果載入為模型數據表。 此組態可減少數據模型儲存大小,並協助將 [ 字段 ] 窗格取消整理。
在我們的範例中,報表作者現在會在 [欄位] 窗格中找到名為 Product 的單一數據表。 其中包含所有產品相關的欄位。
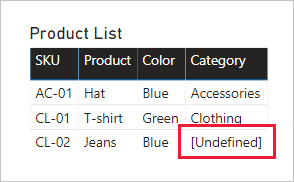
取代遺漏值:如果第二個查詢具有不相符的數據列,NUL 就會出現在其引進的數據行中。 適當時,請考慮使用令牌值取代 NUL。 當報表作者依數據行值篩選或分組時,取代遺漏的值特別重要,因為 BLANK 可能會出現在報表視覺效果中。
在下表視覺效果中,請注意,產品 SKU CL-02 的類別現在會讀取 [未定義]。 在查詢中,Null 類別會取代為此令牌文字值。
建立階層:如果現在合併數據表的數據行之間存在關聯性,請考慮建立階層。 如此一來,報表作者就能快速找出報表視覺鑽研的機會。
在我們的範例中,報表作者現在可以使用具有兩個層級的階層: Category 和 Product。
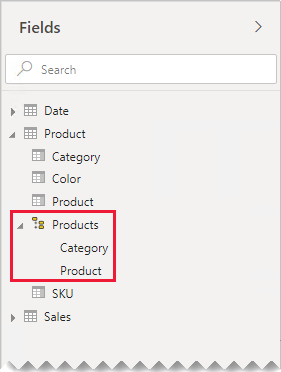
如果您想要個別的數據表如何協助組織字段,我們仍建議合併成單一數據表。 您仍然可以組織欄位,但改為使用 顯示資料夾 。
在我們的範例中,報表作者可以在 Marketing 顯示資料夾中找到 [類別] 字段。
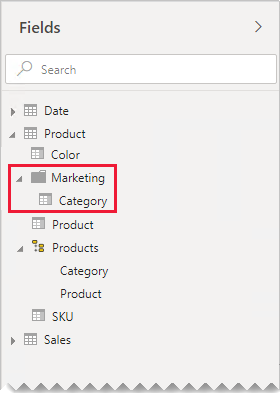
如果您仍然決定在模型中定義一對一的來源群組關聯性,請儘可能確定相關數據表中有相符的數據列。 當一對一來源群組內部關聯性評估為一般 關聯性時,數據完整性問題可能會在報表視覺效果中顯示為 BLANK。 (您可以在本文所呈現的第一個表格視覺效果中看到空白群組的範例。
跨來源群組一對一關聯性
當數據表之間存在一對一 跨來源群組 關聯性時,除非預先合併數據源中的數據,否則沒有替代模型設計。 Power BI 會將一對一模型關聯性評估為 有限的關聯性。 因此,請小心確保相關數據表中有相符的數據列,因為不相符的數據列將會從查詢結果中排除。
讓我們看看當這兩個數據表中的字段新增至數據表視覺效果,而且數據表之間有有限的關聯性時,會發生什麼情況。
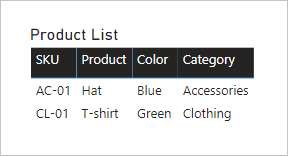
數據表只會顯示兩個數據列。 產品 SKU CL-02 遺失,因為 Product Category 數據表中沒有相符的數據列。
相關內容
如需本文的詳細資訊,請參閱下列資源:
意見反映
即將推出:我們會在 2024 年淘汰 GitHub 問題,並以全新的意見反應系統取代並作為內容意見反應的渠道。 如需更多資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交及檢視以下的意見反映: