在 SQL Server 巨量資料叢集上建立、匯出及評分 Spark 機器學習模型
重要
Microsoft SQL Server 2019 巨量資料叢集附加元件將會淘汰。 SQL Server 2019 巨量資料叢集的支援將於 2025 年 2 月 28 日結束。 平台上將完全支援含軟體保證 SQL Server 2019 的所有現有使用者,而且軟體將會持續透過 SQL Server 累積更新來維護,直到該時間為止。 如需詳細資訊,請參閱公告部落格文章與 Microsoft SQL Server 平台上的巨量資料選項。
以下範例示範如何使用 Spark ML建立模型、將模型匯出至 MLeap,以及在 SQL Server 中使用其 Java 語言延伸模組為模型評分。 此作業會在 SQL Server 巨量資料叢集的內容中完成。
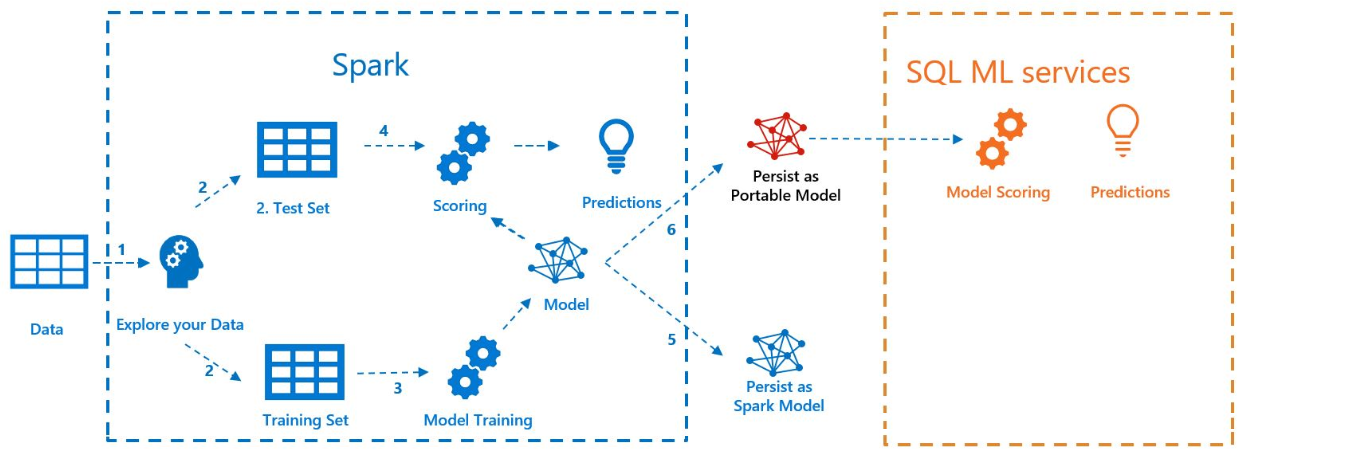
下圖說明此範例中所執行的工作:
必要條件
這個範例的所有檔案都位於 https://github.com/microsoft/sql-server-samples/tree/master/samples/features/sql-big-data-cluster/spark/sparkml \(英文\)。
若要執行範例,您也必須具備下列必要條件:
-
- kubectl
- curl
- Azure Data Studio
使用 Spark ML 將模型定型
此範例會使用普查資料 (AdultCensusIncome.csv) 來建立 Spark ML 管線模型。
使用 mleap_sql_test/setup.sh 檔案從網際網路下載資料集,然後放在您 SQL Server 巨量資料叢集的 HDFS 中。 這可讓 Spark 能夠存取資料集。
然後請下載範例筆記本 train_score_export_ml_models_with_spark.ipynb。 從 PowerShell 或 Bash 命令列,執行下列命令來下載筆記本:
curl -o mssql_spark_connector.ipynb "https://raw.githubusercontent.com/microsoft/sql-server-samples/master/samples/features/sql-big-data-cluster/spark/sparkml/train_score_export_ml_models_with_spark.ipynb"此筆記本包含具有此範例區段之必要命令的儲存格。
在 Azure Data Studio 中開啟筆記本,並執行每個程式碼區塊。 如需使用筆記本的詳細資訊,請參閱如何搭配 SQL Server 使用筆記本。
資料會先讀入 Spark 並分割成定型和測試資料集。 然後程式碼會使用定型資料將管線模型定型。 最後,它會將模型匯出至 MLeap 組合。
提示
您也可以在 mleap_sql_test/mleap_pyspark.py 檔案中,查看或執行與這些步驟有關的 Python 程式碼。
使用 SQL Server 進行模型評分
現在 Spark ML 管線模型已經是通用序列化 MLeap 組合 格式,因此您可以在沒有 Spark 的情況下使用 JAVA 為模型評分。
此範例使用 SQL Server 中的 JAVA 語言延伸模組。 若要為 SQL Server 中的模型評分,您需要先建置可將模型載入到 JAVA 並加以評分的 JAVA 應用程式。 您可以在 mssql-mleap-app folder 中找到此 JAVA 應用程式的範例程式碼。
建置範例之後,您可以使用 Transact-SQL 呼叫 JAVA 應用程式,並搭配資料庫資料表為模型評分。 您可以在 mleap_sql_test/mleap_sql_tests.py 來源檔案中看到此情況。
後續步驟
如需有關巨量資料叢集的詳細資訊,請參閱如何在 Kubernetes 上部署 SQL Server 巨量資料叢集