適用於:![]() SQL Server 2016 (13.x)及以後版本
SQL Server 2016 (13.x)及以後版本 ![]() Azure SQL Database
Azure SQL Database![]() Azure SQL 受管執行個體
Azure SQL 受管執行個體![]() Azure Synapse 分析
Azure Synapse 分析![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)![]() Microsoft Fabric 中的倉儲
Microsoft Fabric 中的倉儲![]() Microsoft Fabric 中的 SQL 資料庫
Microsoft Fabric 中的 SQL 資料庫
建立外部資料表。
本文提供適用於您所選擇之 SQL 產品的語法、引數、備註、權限和範例。
選取產品
在以下資料列中,選取您感興趣的產品名稱,隨即只會顯示該產品的資訊。
* SQL 伺服器 *
概觀:SQL Server
此命令會建立 PolyBase 的外部資料表來存取儲存在 Hadoop 叢集中的資料,或是參考儲存在 Hadoop 叢集或 Azure Blob 儲存體中資料的 Azure Blob 儲存體 PolyBase 外部資料表。
適用於:SQL Server 2016 (13.x) 和更新版本。
使用具備外部資料來源的外部資料表進行 PolyBase 查詢。 外部資料來源會用來建立連線能力,並支援這些主要使用案例:
- 使用數據虛擬化搭配 SQL Server 中的 PolyBase 進行數據虛擬化和數據載入
- 使用 SQL Server 或 SQL Database 來執行大量載入作業 (使用
BULK INSERT或OPENROWSET)
外部數據表是以 外部數據源為基礎。
語法
-- Create a new external table
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ , ...n ] )
WITH (
LOCATION = 'folder_or_filepath' ,
DATA_SOURCE = external_data_source_name ,
[ FILE_FORMAT = external_file_format_name ]
[ , <reject_options> [ , ...n ] ]
)
[ ; ]
<reject_options> ::=
{
| REJECT_TYPE = { value | percentage }
| REJECT_VALUE = reject_value
| REJECT_SAMPLE_VALUE = reject_sample_value ,
| REJECTED_ROW_LOCATION = '/REJECT_Directory'
}
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
引數
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
要建立之資料表名稱的第一到第三部分。
針對外部資料表,SQL 只會儲存資料表中繼資料,以及 Hadoop 或 Azure Blob 儲存體中所參考檔案或資料夾的基本統計資料。 系統不會在 SQL Server 中移動或儲存任何實際資料。
重要
為了達到最佳效能,如果外部資料來源驅動程式支援三段式名稱,你應該提供三段式名稱。
< > column_definition [ ,...n ]
CREATE EXTERNAL TABLE 支援設定數據行名稱、數據類型、Null 性和定序的功能。 您無法在 DEFAULT CONSTRAINT 外部資料表上使用 。
資料行定義 (包括資料類型及資料行數目) 必須符合外部檔案中的資料。 如果發生不相符的情況,查詢實際數據時會拒絕檔案數據列。
位置 = 'folder_or_filepath'
指定位於 Hadoop 或 Azure Blob 儲存體中之實際資料的資料夾或檔案路徑,以及檔案名稱。 此外,從 SQL Server 2022 (16.x) 開始,支援 S3 相容的物件儲存體。 位置會從根資料夾開始。 根資料夾是在外部資料來源中指定的資料位置。
在 SQL Server 中,如果 CREATE EXTERNAL TABLE 語句不存在,就會建立路徑和資料夾。 接著你可以用 INSERT INTO 它從本地 SQL Server 資料表匯出資料到外部資料來源。 如需詳細資訊,請參閱 PolyBase查詢案例。
如果你指定 LOCATION 為資料夾,從外部資料表中選擇的 PolyBase 查詢會從資料夾及其所有子資料夾取得檔案。 PolyBase 和 Hadoop 相同,並不會傳回隱藏的資料夾。 它也不會回傳檔名以底線_()或句點.()開頭的檔案。
以下圖片範例中,若 LOCATION='/webdata/',PolyBase 查詢會回傳來自 mydata.txt 和 mydata2.txt的列。 它不會回傳 mydata3.txt ,因為它是隱藏子資料夾裡的檔案。 而且它不會回來 _hidden.txt ,因為它是隱藏檔案。
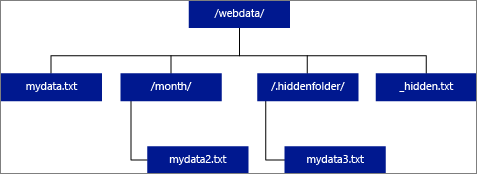
若要變更預設設定並僅從根資料夾讀取,請在 core-site.xml 設定檔中將 <polybase.recursive.traversal> 屬性設為 'false'。 此檔案位於 SQL Server 根目錄底下<SqlBinRoot>\PolyBase\Hadoop\Confbin。 例如: C:\Program Files\Microsoft SQL Server\MSSQL13.XD14\MSSQL\Binn 。
DATA_SOURCE = external_data_source_name
可指定包含外部資料位置的外部資料來源名稱。 此位置是 Hadoop 檔案系統 (HDFS)、Azure Blob 儲存體容器或 Azure Data Lake Store。 若要建立外部資料來源,請使用 CREATE EXTERNAL DATA SOURCE。
FILE_FORMAT = external_file_format_name
可指定外部檔案格式物件的名稱,該物件中儲存了外部資料的檔案類型和壓縮方法。 要建立外部檔案格式,請使用 CREATE EXTERNAL FILE FORMAT。
外部檔案格式可由多個類似的外部檔案重複使用。
REJECT 選項
此選項僅適用於外部資料來源,且 。TYPE = HADOOP
你可以指定拒絕參數,決定 PolyBase 如何處理從外部資料來源取得 的髒 紀錄。 若資料記錄的實際資料類型或資料行數目,與外部資料表的資料行定義不相符,該資料記錄就會被系統視為「已修改」。
當您不指定或變更拒絕值時,PolyBase 就會使用預設值。 當你建立帶有 CREATE EXTERNAL TABLE 陳述的外部資料表時,這些拒絕參數的資訊會作為額外的中繼資料儲存。 當未來 SELECT 的語句 SELECT INTO SELECT 或語句從外部資料表中選擇資料時,PolyBase 會利用拒絕選項來決定在實際查詢失敗前可被拒絕的列數或百分比。 查詢會(部分回傳)結果,直到被超過拒絕閾值為止。 接著它便會失敗並顯示適當的錯誤訊息。
REJECT_TYPE = { 價值 | 百分比 }
釐清選項是否 REJECT_VALUE 指定為常值或百分比。
價值
REJECT_VALUE是常值,而不是百分比。 當被拒絕的列數超過 reject_value 時,查詢會失敗。例如,若
REJECT_VALUE = 5且REJECT_TYPE = value,SELECT則在拒絕五列後查詢即告失敗。百分比
REJECT_VALUE是百分比,而不是常值。 當失敗列的 百分比 超過 reject_value 時,查詢即告失敗。 系統會依據間隔時間計算失敗的資料列所佔百分比。
REJECT_VALUE = reject_value
指定在查詢失敗之前可以拒絕的資料列數目或百分比。
針對 REJECT_TYPE = value, reject_value 必須是介於 0 到 2,147,483,647 之間的整數。
針對 REJECT_TYPE = percentage, reject_value 必須是介於 0 到 100 之間的浮點數。
REJECT_SAMPLE_VALUE = reject_sample_value
當您指定 REJECT_TYPE = percentage時,需要這個屬性。 它會決定在 PolyBase 重新計算被拒絕資料列的百分比之前,應嘗試擷取的資料列數目。
reject_sample_value 參數必須是介於 0 和 2,147,483,647 的整數。
例如,如果 REJECT_SAMPLE_VALUE = 1000,PolyBase 會計算在嘗試從外部資料檔匯入 1,000 列後,失敗列的百分比。 如果失敗的數據列百分比小於 reject_value,PolyBase 會嘗試擷取另一個 1,000 個數據列。 它會在嘗試匯入每個額外的 1,000 個數據列之後,繼續重新計算失敗數據列的百分比。
注意
由於 PolyBase 會不時計算失敗的資料列百分比,因此實際的失敗資料列百分比可能超出 reject_value。
範例
這個例子展示了這三個 REJECT 選項之間的互動。 例如,如果 REJECT_TYPE = percentage、 REJECT_VALUE = 30和 REJECT_SAMPLE_VALUE = 100,可能會發生下列案例:
- PolyBase 會嘗試擷取前 100 個資料列;其中有 25 個失敗,75 個成功。
- 失敗資料列的百分比會計算為 25%,低於拒絕值 30%。 因此,PolyBase 會繼續從外部數據源擷取數據。
- PolyBase 會嘗試載入接下來的 100 個資料列;這次有 25 個資料列成功,75 個資料列失敗。
- 失敗資料列的百分比在重新計算後為 50%。 失敗資料列的百分比已超出 30% 的拒絕值。
- PolyBase 查詢在嘗試傳回前 200 個資料列後,會因被拒絕的資料列達 50% 而失敗。 在 PolyBase 查詢偵測到拒絕閾值超過之前,會回傳匹配的列。
REJECTED_ROW_LOCATION = 目錄位置
適用於:SQL Server 2019(15.x)CU 6 及以上版本,以及 Azure Synapse Analytics。
指定外部資料來源中,已拒絕資料列和相應錯誤檔案應寫入的目錄。
如果指定的路徑不存在,PolyBase 會代表您建立一個路徑。 系統會建立名稱為 _rejectedrows 的子目錄。
_ 字元可確保該目錄從其他資料處理逸出,除非已明確在位置參數中指名。 在此目錄中,有一個資料夾是根據載入提交 YearMonthDay -HourMinuteSecond 格式建立的資料夾(例如,20230330-173205)。 在此資料中寫入了兩種類型的檔案,分別是 _reason 檔案與資料檔案。 此選項只能與外部數據源搭配使用,其中 TYPE = HADOOP 和使用 DELIMITEDTEXTFORMAT_TYPE的外部數據表。 如需詳細資訊,請參閱 CREATE EXTERNAL DATA SOURCE 和 CREATE EXTERNAL FILE FORMAT。
原因檔案和數據檔都有與 CTAS 語句相關聯的 queryID。 因為資料與原因檔案在不同的檔案中,所以對應的檔案會具有相符尾碼。
權限
需要下列使用者權限:
CREATE TABLEALTER ANY SCHEMAALTER ANY EXTERNAL DATA SOURCE-
ALTER ANY EXTERNAL FILE FORMAT(僅適用於 Hadoop 和 Azure 儲存體 的外部資料來源) -
CONTROL DATABASE(僅適用於 Hadoop 和 Azure 儲存體 的外部資料來源)
指令中指定的DATABASE SCOPED CREDENTIALCREATE EXTERNAL TABLE遠端登入必須對參數中指定的外部資料來源路徑/資料表/集合擁有LOCATION權限。 如果你打算用它 EXTERNAL TABLE 把資料匯出到 Hadoop 或 Azure 儲存體 的外部資料來源,那麼指定的登入必須有寫入權限,路徑在 LOCATION。 SQL Server 2022(16.x)不支援 Hadoop。
針對 Azure Blob 儲存體,在 Azure 入口網站、Azure Blob 儲存體或 ADLS Gen2 儲存體帳戶中設定存取金鑰和共用存取簽章 (SAS) 時,請設定 [允許的權限] 以至少授與讀取和寫入權限。 在跨資料夾搜尋時,可能也需要列出權限。 您也必須選取 [容器] 和 [物件] 作為允許的資源類型。
重要
此 ALTER ANY EXTERNAL DATA SOURCE 權限賦予任何主體建立及修改任何外部資料來源物件的能力,因此也授權存取資料庫上所有具有資料庫範圍的憑證。 必須將此權限視為具高度權限,因此必須僅授與系統中受信任的主體。
錯誤處理
在執行 CREATE EXTERNAL TABLE 語句時,PolyBase 會嘗試連線到外部數據源。 如果嘗試連接失敗,該語句也會失敗,外部資料表也不會被建立。 由於 PolyBase 在查詢失敗之前會多次嘗試連線,因此可能需要一分鐘或更久的時間,命令才會失敗。
備註
在臨機作查詢案例中,例如 SELECT FROM EXTERNAL TABLE,PolyBase 會將從外部數據源擷取的數據列儲存在臨時表中。 在查詢完成之後,PolyBase 便會移除並刪除該暫存資料表。 SQL 資料表中不會永久存放資料。 相較之下,在匯入情境中,例如 SELECT INTO FROM EXTERNAL TABLE,PolyBase 會將從外部資料來源擷取的列作為永久資料存放在 SQL 資料表中。 新的資料表會在查詢執行期間,當 PolyBase 擷取外部資料時建立。
Hadoop 格式僅支援於 SQL Server 2016(13.x)、SQL Server 2017(14.x)及 SQL Server 2019(15.x)。
PolyBase 可以將部分的查詢計算推送至 Hadoop 以改善查詢效能。 此動作稱為謂詞推下。 要啟用它,請在 中 CREATE EXTERNAL DATA SOURCE指定 Hadoop 資源管理器的位置選項。
您可以建立許多參考相同或不同外部資料來源的外部資料表。
局限性
由於外部資料表的資料不受 SQL Server 直接管理,因此可隨時被外部程序更改或移除。 因此,針對外部資料表的查詢結果並不保證具有確定性。 相同的查詢在每次針對外部資料表執行時,都有可能傳回不同的結果。 同樣地,在移動或移除外部資料的情況下,查詢也有可能會失敗。
您可以建立多個參考不同外部資料來源的外部資料表。 如果您同時針對不同的 Hadoop 資料來源執行查詢,則每個 Hadoop 來源都必須使用相同的「Hadoop 連線能力」伺服器組態設定。 例如,您不能同時針對 Cloudera Hadoop 叢集和 Hortonworks Hadoop 叢集執行查詢,因為這些叢集是使用不同的組態設定。 關於設定設定及支援組合,請參見 PolyBase 連接性配置。
當外部數據表使用 DELIMITEDTEXT、 CSV、 PARQUET或 DELTA 做為資料類型時,外部數據表僅支援每個 CREATE STATISTICS 命令一個數據行的統計數據。
外部資料表上僅允許使用下列資料定義語言 (DDL) 陳述式:
-
CREATE TABLE和DROP TABLE -
CREATE STATISTICS和DROP STATISTICS -
CREATE VIEW和DROP VIEW
不支援的建構和作業:
-
DEFAULT外部數據表數據行的條件約束 - 刪除、插入及更新的資料操作語言 (DML) 作業
查詢限制
執行 32 個並行的 PolyBase 查詢時,PolyBase 每個資料夾可取用的檔案數目上限為 33000 個檔案。 這個上限數同時包含了每個 HDFS 資料夾中的檔案和子資料夾。 如果並行程度小於 32,使用者就可以針對 HDFS 中內含超過 33000 個檔案的資料夾執行 PolyBase 查詢。 我們建議您使用簡短的外部檔案路徑,且所使用的每個 HDFS 資料夾檔案數目不要超過 30000 個檔案。 參考太多檔案時,可能會發生 Java 虛擬機器 (JVM) 記憶體不足的例外狀況。
資料表寬度限制
在 SQL Server 2016(13.x)中,PolyBase 的列寬度限制為 32 KB,這是根據資料表定義單一有效資料列的最大大小。 若資料行結構描述的總和超過 32 KB,PolyBase 將無法查詢資料。
資料類型限制
以下資料型別無法用於 PolyBase 外部資料表:
- 地理位置
- 幾何
- 層次識別碼(hierarchyid)
- 映像
- 文字
- 內容
- xml
- 任何使用者定義的類型
資料來源特定限制
Oracle公司
搭配使用 PolyBase 時,不支援 Oracle 同義字。
包含陣列之 MongoDB 集合的外部資料表
使用 sp_data_source_objects 偵測包含陣列的 MongoDB 集合的集合結構(欄位),並手動建立外部資料表。
sp_data_source_table_columns 預存程序也會透過 PolyBase ODBC Driver for MongoDB 驅動程式自動執行壓平合併。
鎖定
共用鎖定物件 SCHEMARESOLUTION 。
安全性
外部資料表的資料檔案會儲存在 Hadoop 或 Azure Blob 儲存體中。 這些資料檔案是由您自己的處理程序所建立及管理。 管理外部資料的安全是你的責任。
範例
A。 建立具有文字分隔格式資料的外部資料表
此範例會示範建立將資料儲存為文字分隔檔案之外部資料表的所有步驟。 它會定義外部資料來源 mydatasource 和外部檔案格式 myfileformat。 這些資料庫層級物件接著會在 CREATE EXTERNAL TABLE 語句中參考。 如需詳細資訊,請參閱 CREATE EXTERNAL DATA SOURCE 和 CREATE EXTERNAL FILE FORMAT。
CREATE EXTERNAL DATA SOURCE mydatasource
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
);
GO
CREATE EXTERNAL FILE FORMAT myfileformat
WITH (
FORMAT_TYPE = DELIMITEDTEXT,
FORMAT_OPTIONS (FIELD_TERMINATOR = '|')
);
GO
CREATE EXTERNAL TABLE ClickStream
(
url VARCHAR (50),
event_date DATE,
user_IP VARCHAR (50)
)
WITH (
DATA_SOURCE = mydatasource,
LOCATION = '/webdata/employee.tbl',
FILE_FORMAT = myfileformat
);
B. 建立具有 RCFile 格式資料的外部資料表
此範例會示範建立將資料格式化為 RCFile 之外部資料表的所有步驟。 它會定義外部資料來源 mydatasource_rc 和外部檔案格式 myfileformat_rc。 這些資料庫層級物件接著會在 CREATE EXTERNAL TABLE 語句中參考。 如需詳細資訊,請參閱 CREATE EXTERNAL DATA SOURCE 和 CREATE EXTERNAL FILE FORMAT。
CREATE EXTERNAL DATA SOURCE mydatasource_rc
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
);
GO
CREATE EXTERNAL FILE FORMAT myfileformat_rc
WITH (
FORMAT_TYPE = RCFILE,
SERDE_METHOD = 'org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe'
);
GO
CREATE EXTERNAL TABLE ClickStream_rc
(
url VARCHAR (50),
event_date DATE,
user_ip VARCHAR (50)
)
WITH (
DATA_SOURCE = mydatasource_rc,
LOCATION = '/webdata/employee_rc.tbl',
FILE_FORMAT = myfileformat_rc
);
C. 建立具有 ORC 格式資料的外部資料表
此範例會示範建立將資料格式化為 ORC 檔案之外部資料表的所有步驟。 其會定義外部資料來源 mydatasource_orc,以及外部檔案格式 myfileformat_orc。 這些資料庫層級物件接著會在 CREATE EXTERNAL TABLE 語句中參考。 如需詳細資訊,請參閱 CREATE EXTERNAL DATA SOURCE 和 CREATE EXTERNAL FILE FORMAT。
CREATE EXTERNAL DATA SOURCE mydatasource_orc
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
);
GO
CREATE EXTERNAL FILE FORMAT myfileformat_orc
WITH (
FORMAT = ORC,
COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
);
GO
CREATE EXTERNAL TABLE ClickStream_orc (
url VARCHAR (50),
event_date DATE,
user_ip VARCHAR (50)
)
WITH (
LOCATION='/webdata/',
DATA_SOURCE = mydatasource_orc,
FILE_FORMAT = myfileformat_orc
);
D. 查詢 Hadoop 資料
ClickStream 為能夠連線至 Hadoop 叢集上 employee.tbl 分隔符號文字檔案的外部資料表。 下列查詢看起來像是針對標準資料表的查詢。 不過,此查詢會從 Hadoop 擷取資料,然後計算結果。
SELECT TOP 10 (url)
FROM ClickStream
WHERE user_ip = 'xxx.xxx.xxx.xxx';
E. 將 Hadoop 資料與 SQL 資料聯結
這個查詢看起來就像兩個 SQL 資料表上的標準 JOIN 查詢。 差異在於,PolyBase 會從 Hadoop 擷取 clickstream 資料,然後將它聯結至 UrlDescription 資料表。 其中一個資料表是外部資料表,另一個則是標準 SQL 資料表。
SELECT url.description
FROM ClickStream AS cs
INNER JOIN UrlDescription AS url
ON cs.url = url.name
WHERE cs.url = 'msdn.microsoft.com';
F. 將資料從 Hadoop 匯入至 SQL 資料表
此範例會建立新的 SQL 資料表 ms_user,其能永久儲存標準 SQL 資料表 user 及外部資料表 ClickStream 之間的聯結結果。
SELECT DISTINCT user.FirstName, user.LastName
INTO ms_user
FROM user INNER JOIN (
SELECT * FROM ClickStream WHERE cs.url = 'www.microsoft.com'
) AS ms
ON user.user_ip = ms.user_ip;
G. 建立 SQL Server 的外部資料表
在您建立資料庫範圍認證之前,使用者資料庫必須具有保護認證的主要金鑰。 如需詳細資訊,請參閱 CREATE MASTER KEY 和 CREATE DATABASE SCOPED CREDENTIAL。
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<password>';
GO
/* specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL SqlServerCredentials
WITH
IDENTITY = '<username>',
SECRET = '<password>';
建立名為 SQLServerInstance 的新外部資料來源,以及名為 sqlserver.customer 的外部資料表:
/* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE SQLServerInstance
WITH (
LOCATION = 'sqlserver://SqlServer',
-- PUSHDOWN = ON | OFF,
CREDENTIAL = SQLServerCredentials
);
GO
CREATE SCHEMA sqlserver;
/* LOCATION: sql server table/view in 'database_name.schema_name.object_name' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE sqlserver.customer (
C_CUSTKEY INT NOT NULL,
C_NAME VARCHAR(25) NOT NULL,
C_ADDRESS VARCHAR(40) NOT NULL,
C_NATIONKEY INT NOT NULL,
C_PHONE CHAR(15) NOT NULL,
C_ACCTBAL DECIMAL(15,2) NOT NULL,
C_MKTSEGMENT CHAR(10) NOT NULL,
C_COMMENT VARCHAR(117) NOT NULL
)
WITH (
LOCATION='tpch_10.dbo.customer',
DATA_SOURCE=SqlServerInstance
);
一. 建立 Oracle 的外部資料表
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<password>';
GO
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH
IDENTITY = '<username>',
SECRET = '<password>';
GO
/*
* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = 'oracle://<server address>[:<port>]',
-- PUSHDOWN = ON | OFF,CREDENTIAL = credential_name
);
/*
* LOCATION: Oracle table/view in '<database_name>.<schema_name>.<object_name>' format. This may be case sensitive in the Oracle database.
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customers
(
[O_ORDERKEY] DECIMAL (38) NOT NULL,
[O_CUSTKEY] DECIMAL (38) NOT NULL,
[O_ORDERSTATUS] CHAR COLLATE Latin1_General_BIN NOT NULL,
[O_TOTALPRICE] DECIMAL (15, 2) NOT NULL,
[O_ORDERDATE] DATETIME2 (0) NOT NULL,
[O_ORDERPRIORITY] CHAR (15) COLLATE Latin1_General_BIN NOT NULL,
[O_CLERK] CHAR (15) COLLATE Latin1_General_BIN NOT NULL,
[O_SHIPPRIORITY] DECIMAL (38) NOT NULL,
[O_COMMENT] VARCHAR (79) COLLATE Latin1_General_BIN NOT NULL
)
WITH (
DATA_SOURCE = external_data_source_name,
LOCATION = 'DB1.mySchema.customer'
);
J. 建立 Teradata 的外部資料表
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<password>';
GO
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH
IDENTITY = '<username>',
SECRET = '<password>';
GO
/* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = teradata://<server address>[:<port>],
-- PUSHDOWN = ON | OFF,
CREDENTIAL =credential_name
);
GO
/* LOCATION: Teradata table/view in '<database_name>.<object_name>' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customer(
L_ORDERKEY INT NOT NULL,
L_PARTKEY INT NOT NULL,
L_SUPPKEY INT NOT NULL,
L_LINENUMBER INT NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR NOT NULL,
L_LINESTATUS CHAR NOT NULL,
L_SHIPDATE DATE NOT NULL,
L_COMMITDATE DATE NOT NULL,
L_RECEIPTDATE DATE NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL
)
WITH (
LOCATION='customer',
DATA_SOURCE= external_data_source_name
);
K. 建立 MongoDB 的外部資料表
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<password>';
GO
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH
IDENTITY = '<username>',
SECRET = '<password>';
GO
/* LOCATION: Location string should be of format '<type>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = mongodb://<server>[:<port>],
-- PUSHDOWN = ON | OFF,
CREDENTIAL = credential_name
);
/* LOCATION: MongoDB table/view in '<database_name>.<schema_name>.<object_name>' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customers(
[O_ORDERKEY] DECIMAL(38) NOT NULL,
[O_CUSTKEY] DECIMAL(38) NOT NULL,
[O_ORDERSTATUS] CHAR COLLATE Latin1_General_BIN NOT NULL,
[O_TOTALPRICE] DECIMAL(15,2) NOT NULL,
[O_ORDERDATE] DATETIME2(0) NOT NULL,
[O_COMMENT] VARCHAR(79) COLLATE Latin1_General_BIN NOT NULL
)
WITH (
LOCATION='customer',
DATA_SOURCE= external_data_source_name
);
L. 透過外部資料表查詢 S3 相容的物件儲存體
適用於:SQL Server 2022 (16.x) 和更新版本。
下列範例示範如何使用 T-SQL,透過查詢外部資料表來查詢儲存在 S3 相容物件儲存體中的 parquet 檔案。 此範例會使用外部資料來源內的相對路徑。
CREATE EXTERNAL DATA SOURCE s3_ds
WITH
( LOCATION = 's3://<ip_address>:<port>/',
CREDENTIAL = s3_dc
);
GO
CREATE EXTERNAL FILE FORMAT ParquetFileFormat
WITH(
FORMAT_TYPE = PARQUET
);
GO
CREATE EXTERNAL TABLE Region (
r_regionkey BIGINT,
r_name CHAR(25),
r_comment VARCHAR(152)
)
WITH (
LOCATION = '/region/',
DATA_SOURCE = 's3_ds',
FILE_FORMAT = ParquetFileFormat
);
相關內容
* Azure SQL 資料庫 *
概觀:Azure SQL Database
建立外部資料表,用於:
請參閱 CREATE EXTERNAL DATA SOURCE。
語法
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ , ...n ] )
WITH (
LOCATION = 'filepath' ,
DATA_SOURCE = external_data_source_name ,
FILE_FORMAT = external_file_format_name
)
[ ; ]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
-- Create a table for use with elastic query
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ , ...n ] )
WITH ( <sharded_external_table_options> )
[ ; ]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<sharded_external_table_options> ::=
DATA_SOURCE = external_data_source_name ,
SCHEMA_NAME = N'nonescaped_schema_name' ,
OBJECT_NAME = N'nonescaped_object_name' ,
[ DISTRIBUTION = SHARDED(sharding_column_name) | REPLICATED | ROUND_ROBIN ] ]
)
[ ; ]
引數
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
要建立之資料表名稱的第一到第三部分。
針對外部資料表,SQL 只會儲存資料表中繼資料,以及 Azure SQL Database 中所參考檔案或資料夾的基本統計資料。 建立外部數據表時,不會移動或儲存在 Azure SQL Database 中的實際數據。
重要
為了達到最佳效能,如果外部資料來源驅動程式支援三段式名稱,你應該提供三段式名稱。
< > column_definition [ ,...n ]
CREATE EXTERNAL TABLE 支援設定數據行名稱、數據類型、Null 性和定序的功能。 您無法在 DEFAULT CONSTRAINT 外部資料表上使用 。 這些資料型別不支援 Azure SQL 資料庫外部資料表中的欄位:
- 地理位置
- 幾何
- 層次識別碼(hierarchyid)
- 映像
- 文字
- 內容
- xml
- json
- 任何使用者定義的類型
資料行定義 (包括資料類型及資料行數目) 必須符合外部檔案中的資料。 如果發生不相符的情況,查詢實際數據時會拒絕檔案數據列。
分區外部資料表選項
針對彈性查詢指定外部資料來源 (非 SQL Server 資料來源) 及發佈方法。
位置 = 'folder_or_filepath'
指定 Azure Data Lake Gen2 或 Azure Blob 記憶體中實際資料的資料夾或檔案路徑和檔案名。 位置會從根資料夾開始。 根資料夾是在外部資料來源中指定的資料位置。
CREATE EXTERNAL TABLE 則不會建立路徑和資料夾。
如果你指定 LOCATION 為資料夾,從外部資料表中選擇的查詢會從資料夾中取得檔案,但不會取得所有子資料夾。
Azure SQL 管理實例無法在子資料夾或隱藏資料夾中找到檔案。 它也不會回傳檔名以底線_()或句點.()開頭的檔案。
以下圖片範例中,若 LOCATION='/webdata/',查詢回傳來自 mydata.txt的列。 它不回傳mydata2.txt是因為它在子資料夾裡,不回傳是因為它在隱藏資料夾裡,也不會回傳mydata3.txt_hidden.txt是因為它是隱藏檔案。
DATA_SOURCE
DATA_SOURCE指定包含外部資料位置的外部數據源名稱。 若要建立外部資料來源,請使用 CREATE EXTERNAL DATA SOURCE。 如需彈性查詢中的範例, DATA_SOURCE 是分區對應,請參閱 建立外部數據表。
FILE_FORMAT = external_file_format_name
可指定外部檔案格式物件的名稱,該物件中儲存了外部資料的檔案類型和壓縮方法。 要建立外部檔案格式,請使用 CREATE EXTERNAL FILE FORMAT。
SCHEMA_NAME 和 OBJECT_NAME
僅適用於彈性查詢。
SCHEMA_NAME and OBJECT_NAME 子句將外部資料表定義映射到不同結構中的資料表。 若省略,則假設遠端物件的結構為 dbo,且其名稱與定義的外部資料表名稱相同。 如果您的遠端資料表名稱已存在於您要建立外部資料表的資料庫中,這會很有用。 例如,您想要定義外部資料表以取得相應放大的資料層上目錄檢視或 DMV 的彙總檢視。 由於目錄檢視和 DMV 已經存在於本地,你無法用它們的名稱來定義外部資料表。 相反地,請使用不同名稱,並在 and/or SCHEMA_NAME 子句中使用目錄檢視或 DMV 的名稱OBJECT_NAME。 如需範例,請參閱建立外部資料表。
分配
僅適用於彈性查詢。
選擇性。 只有類型的 SHARD_MAP_MANAGER資料庫才需要這個自變數。 這個引數能控制資料表是否會被視為分區資料表或複寫資料表。 使用 SHARDED (<column name>) 數據表時,來自不同數據表的數據不會重疊。
REPLICATED 指定數據表在每個分區上具有相同的數據。
ROUND_ROBIN 表示使用應用程式特定的方法來散發數據。
指定此數據表使用的數據分配。 查詢處理器利用子 DISTRIBUTION 句中提供的資訊來建立最有效率的查詢計畫。
-
SHARDED表示數據在資料庫之間進行水平分割。 用於資料散發的分割索引鍵是sharding_column_name參數。 -
REPLICATED表示每個資料庫上都有數據表的相同複本。 你有責任確保各資料庫的副本完全相同。 -
ROUND_ROBIN表示數據表使用應用程式相依的分配方法進行水平分區。
權限
可存取外部資料表的使用者可以在外部資料來源定義中所提供的認證下,自動取得基礎遠端資料表的存取權。 避免透過外部資料來源認證提高不想提高的權限。 使用 GRANT 或 REVOKE 作為外部表格,就像一般表格一樣。 一旦您已定義外部資料來源和外部資料表,現在您可以對外部資料表使用完整的 T-SQL。
CREATE EXTERNAL TABLE 需要這些用戶權力:
CREATE TABLEALTER ANY SCHEMAALTER ANY EXTERNAL DATA SOURCEALTER ANY EXTERNAL FILE FORMAT-
CONTROL DATABASE僅需權限才能建立主金鑰、資料庫範圍的憑證及外部資料來源。
建立外部資料來源的登入者必須擁有讀取與寫入外部資料來源的權限,該資料來源位於 Hadoop 或 Azure Blob 儲存體。
重要
此 ALTER ANY EXTERNAL DATA SOURCE 權限賦予任何主體建立及修改任何外部資料來源物件的能力,因此也授權存取資料庫上所有具有資料庫範圍的憑證。 必須將此權限視為具高度權限,因此必須僅授與系統中受信任的主體。
鎖定
共用鎖定物件 SCHEMARESOLUTION 。
備註
在臨機作查詢案例中,例如 SELECT FROM EXTERNAL TABLE,從外部數據源擷取的數據列會儲存在臨時表中。 查詢完成之後,系統會移除資料列,並刪除暫存資料表。 SQL 資料表中不會永久存放資料。
相反地,在匯入案例中,例如 SELECT INTO FROM EXTERNAL TABLE,從外部數據源擷取的數據列會儲存為 SQL 數據表中的永久數據。 新的資料表會在查詢執行期間擷取外部資料時建立。
目前,使用 Azure SQL Database 的數據虛擬化是唯讀的。
您可以建立許多參考相同或不同外部資料來源的外部資料表。
資料表寬度限制
1 MB 的資料列寬度限制以依資料表定義的單一有效資料列大小上限為基礎。 若欄位結構的總和大於 1 MB,資料虛擬化查詢即失敗。
錯誤處理
CREATE EXTERNAL TABLE執行該陳述式時,如果連接嘗試失敗,則陳述式失敗,外部資料表也不會被建立。 由於 SQL Database 在查詢失敗之前會多次嘗試連線,因此可能需要一分鐘或更久的時間,命令才會失敗。
局限性
由於外部資料表的資料不受資料庫引擎或 Azure SQL 資料庫的直接管理,因此它可以隨時被外部程序更改或移除。 因此,針對外部資料表的查詢結果並不保證具有確定性。 相同的查詢在每次針對外部資料表執行時,都有可能傳回不同的結果。 同樣地,在移動或移除外部資料的情況下,查詢也有可能會失敗。
您可以建立多個參考不同外部資料來源的外部資料表。
外部資料表上僅允許使用下列資料定義語言 (DDL) 陳述式:
-
CREATE TABLE和DROP TABLE -
CREATE STATISTICS和DROP STATISTICS -
CREATE VIEW和DROP VIEW
不支援的建構和作業:
- 外部
DEFAULT數據表數據行的條件約束。 - 刪除、插入及更新的資料操作語言 (DML) 作業。
彈性查詢的限制
隔離語意:透過外部數據表存取數據不會遵守 SQL Server 內的隔離語意。 這表示查詢外部數據表不會強加任何鎖定或快照集隔離。 因此,如果外部數據源中的數據正在變更,則數據傳回可能會變更。 相同的查詢在每次針對外部資料表執行時,都有可能傳回不同的結果。 同樣地,在移動或移除外部資料的情況下,查詢也有可能會失敗。
不支援建構和作業:
- 外部
DEFAULT數據表數據行的條件約束。 - 刪除、插入及更新的資料操作語言 (DML) 作業。
- 外部數據表數據行上的動態數據遮罩。
- Azure SQL 資料庫中外部資料表不支援游標。
- 外部
只有常值述詞:查詢中定義的常值述詞只能向下推送至外部數據源。 這與鏈接的伺服器和存取可在查詢執行期間判斷述詞的位置不同,也就是說,在查詢計劃中搭配巢狀迴圈使用時。 這常導致整個外部資料表被本地複製後再合併。
在下列範例中,如果
External.Orders是外部數據表,而且Customer是本機數據表,則查詢會在本機複製整個外部數據表,因為編譯時期並不知道所需的述詞。SELECT Orders.OrderId, Orders.OrderTotal FROM External.Orders WHERE CustomerId IN ( SELECT TOP 1 CustomerId FROM Customer WHERE CustomerName = 'MyCompany' );沒有平行處理原則:使用外部數據表可防止在查詢計劃中使用平行處理原則。
執行為遠端查詢:外部數據表會實作為遠端查詢,因此傳回的數據列估計數目一般為 1000。 根據用來篩選外部數據表的述詞類型,還有其他規則。 它們是以規則為基礎的估計值,而不是根據外部資料表中的實際資料進行評估。 最佳化工具不會存取遠端資料源來取得更精確的估計值。
不支援私有端點:當連接遠端資料表為私有端點時,不支援外部資料表查詢。
範例
更多範例請參見 CREATE EXTERNAL DATA SOURCEAzure SQL Database 的資料虛擬化。
A。 建立彈性查詢的外部數據表
CREATE EXTERNAL TABLE [dbo].[CustomerInformation]
(
[CustomerID] INT NOT NULL,
[CustomerName] VARCHAR (50) NOT NULL,
[Company] VARCHAR (50) NOT NULL
)
WITH (
DATA_SOURCE = MyElasticDBQueryDataSrc
);
B. 針對分區資料來源建立外部資料表
此範例利用 and SCHEMA_NAME 子句將遠端 DMV 重新映射到外部資料表OBJECT_NAME。
CREATE EXTERNAL TABLE [dbo].[all_dm_exec_requests]
(
[session_id] SMALLINT NOT NULL,
[request_id] INT NOT NULL,
[start_time] DATETIME NOT NULL,
[status] NVARCHAR (30) NOT NULL,
[command] NVARCHAR (32) NOT NULL,
[sql_handle] VARBINARY (64),
[statement_start_offset] INT,
[statement_end_offset] INT,
[cpu_time] INT NOT NULL
)
WITH (
DATA_SOURCE = MyExtSrc,
SCHEMA_NAME = 'sys',
OBJECT_NAME = 'dm_exec_requests',
DISTRIBUTION = ROUND_ROBIN
);
C. 使用外部數據表查詢 Azure SQL Database 的外部數據
要在 Azure SQL 資料庫建立資料庫範圍驗證,必須先建立 資料庫主金鑰(如果還沒有的話)。 當認證需要
SECRET時,需要資料庫主要密鑰。-- Create MASTER KEY if it doesn't exist in the database: CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<password>';使用 SAS 權杖建立資料庫範圍認證。 您也可以使用受控識別。
CREATE DATABASE SCOPED CREDENTIAL MyCredential WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = '<KEY>'; --Removing leading '?'使用認證建立外部資料來源。
--Create external data source pointing to the file path, and referencing database-scoped credential: CREATE EXTERNAL DATA SOURCE MyPrivateExternalDataSource WITH ( LOCATION = 'abs://public@pandemicdatalake.blob.core.windows.net/curated/covid-19/bing_covid-19_data/latest' CREDENTIAL = [MyCredential] );建立一個
EXTERNAL FILE FORMAT和EXTERNAL TABLE一個 ,讓資料像查詢本地資料表一樣。-- Or, create an EXTERNAL FILE FORMAT and an EXTERNAL TABLE --Create external file format CREATE EXTERNAL FILE FORMAT DemoFileFormat WITH ( FORMAT_TYPE = PARQUET ); --Create external table: CREATE EXTERNAL TABLE tbl_TaxiRides ( vendorID VARCHAR (100) COLLATE Latin1_General_BIN2, tpepPickupDateTime DATETIME2, tpepDropoffDateTime DATETIME2, passengerCount INT, tripDistance FLOAT, puLocationId VARCHAR (8000), doLocationId VARCHAR (8000), startLon FLOAT, startLat FLOAT, endLon FLOAT, endLat FLOAT, rateCodeId SMALLINT, storeAndFwdFlag VARCHAR (8000), paymentType VARCHAR (8000), fareAmount FLOAT, extra FLOAT, mtaTax FLOAT, improvementSurcharge VARCHAR (8000), tipAmount FLOAT, tollsAmount FLOAT, totalAmount FLOAT ) WITH ( DATA_SOURCE = NYCTaxiExternalDataSource, LOCATION = 'yellow/puYear = */puMonth = */*.parquet', FILE_FORMAT = MyFileFormat ); --Then, query the data via an external table with T-SQL: SELECT TOP 10 * FROM tbl_TaxiRides;
相關內容
* Azure Synapse
分析學*
概觀:Azure Synapse Analytics
小提示
Microsoft Fabric Data Warehouse 是一個企業規模的關聯式倉庫,建立在資料湖基礎上,具備未來準備架構、內建 AI 及新功能。 如果你是資料倉儲新手,建議先從Fabric Data Warehouse開始。 現有的 專用 SQL 工作負載可升級至 Fabric,以取得資料科學、即時分析與報告等多項新功能。
使用外部資料表來:
- 專用 SQL 集區可以從 Hadoop、Azure Blob 儲存體和 Azure Data Lake Storage Gen1 和 Gen2 查詢、匯入和儲存資料。
- 無伺服器 SQL 池可以查詢、匯入並儲存 Azure Blob 儲存體 以及 Azure Data Lake Storage Gen1 和 Gen2 的資料。 無伺服器不支援
TYPE=Hadoop。
請參閱 CREATE EXTERNAL DATA SOURCE 與 DROP EXTERNAL TABLE。
欲了解更多關於使用 Azure Synapse 使用外部資料表的資訊與範例,請參閱「 在 Synapse SQL 中使用外部資料表」。
語法
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'hdfs_folder_or_filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
[ , <reject_options> [ ,...n ] ]
)
[ ; ]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<reject_options> ::=
{
| REJECT_TYPE = { value | percentage },
| REJECT_VALUE = reject_value,
| REJECT_SAMPLE_VALUE = reject_sample_value,
| REJECTED_ROW_LOCATION = '/REJECT_Directory'
}
引數
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
要建立之資料表名稱的第一到第三部分。
針對外部資料表,只有資料表中繼資料,以及 Azure Data Lake、Hadoop 或 Azure Blob 儲存體中所參考檔案或資料夾的基本統計資料。 建立外部資料表時,不會移動或儲存實際資料。
重要
為了達到最佳效能,如果外部資料來源驅動程式支援三段式名稱,你應該提供三段式名稱。
< > column_definition [ ,...n ]
CREATE EXTERNAL TABLE 支援設定數據行名稱、數據類型、Null 性和定序的功能。 您無法在 DEFAULT CONSTRAINT 外部資料表上使用 。
注意
Text、ntext 和 xml 這三個資料型別在 Synapse Analytics 外部資料表欄位中不被支援。
- 讀取分隔檔案時,資料行定義 (包括資料類型及資料行數目) 必須符合外部檔案中的資料。 如果發生不相符的情況,查詢實際數據時會拒絕檔案數據列。
- 從 Parquet 檔案讀取時,您只能指定要讀取的資料行,並略過其餘部分。
位置 = 'folder_or_filepath'
指定位於 Azure Data Lake、Hadoop 或 Azure Blob 儲存體中之實際資料的資料夾或檔案路徑,以及檔案名稱。 位置會從根資料夾開始。 根資料夾是在外部資料來源中指定的資料位置。 如果路徑和資料夾不存在,則用 CREATE EXTERNAL TABLE AS SELECT (CETAS) 陳述來建立它。
CREATE EXTERNAL TABLE 則不會建立路徑和資料夾。
如果你指定 LOCATION 為資料夾,從外部資料表中選擇的 PolyBase 查詢會從資料夾及其所有子資料夾取得檔案。 PolyBase 和 Hadoop 相同,並不會傳回隱藏的資料夾。 它也不會回傳檔名以底線_()或句點.()開頭的檔案。
以下圖片範例中,若 LOCATION='/webdata/',PolyBase 查詢會回傳來自 mydata.txt 和 mydata2.txt的列。 它不會回傳 mydata3.txt 是因為它在隱藏資料夾的子資料夾裡,也因為是隱藏檔案才不會回傳 _hidden.txt 。
與 Hadoop 外部資料表不同的是,除非您在路徑結尾指定 /**,否則原生外部資料表不會傳回子資料夾。 在此範例中,若 LOCATION='/webdata/',無伺服器 SQL 池查詢會回傳來自 mydata.txt的列。 它不會回傳 mydata2.txt ,而且 mydata3.txt 因為它們都放在子資料夾裡。 Hadoop 表格會回傳任何子資料夾內的所有檔案。
Hadoop 與原生外部資料表皆跳過以底線_()或句點.()開頭的檔案。
DATA_SOURCE = external_data_source_name
可指定包含外部資料位置的外部資料來源名稱。 此位置位於 Azure Data Lake 中。 若要建立外部資料來源,請使用 CREATE EXTERNAL DATA SOURCE。
FILE_FORMAT = external_file_format_name
可指定外部檔案格式物件的名稱,該物件中儲存了外部資料的檔案類型和壓縮方法。 要建立外部檔案格式,請使用 CREATE EXTERNAL FILE FORMAT。
表格選項
指定一組選項,描述如何讀取基礎檔案。 目前唯一可用的 {"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}是 ,它指示外部資料表忽略底層檔案的更新,即使這可能導致讀取操作不一致。 請在您經常附加檔案的特殊情況下,才使用此選項。 此選項適用於 CSV 格式的無伺服器 SQL 集區。
REJECT 選項
Reject 選項在 Azure Synapse Analytics 中處於無伺服器 SQL 集區的預覽狀態。
此選項僅適用於外部資料來源,且 。TYPE = HADOOP
你可以指定拒絕參數,決定 PolyBase 如何處理從外部資料來源取得 的髒 紀錄。 若資料記錄的實際資料類型或資料行數目,與外部資料表的資料行定義不相符,該資料記錄就會被系統視為「已修改」。
當您不指定或變更拒絕值時,PolyBase 就會使用預設值。 當你建立帶有 CREATE EXTERNAL TABLE 陳述的外部資料表時,這些拒絕參數的資訊會作為額外的中繼資料儲存。 當未來 SELECT 的語句 SELECT INTO SELECT 或語句從外部資料表中選擇資料時,PolyBase 會利用拒絕選項來決定在實際查詢失敗前可被拒絕的列數或百分比。 查詢會(部分回傳)結果,直到被超過拒絕閾值為止。 接著它便會失敗並顯示適當的錯誤訊息。
格式 PARSER_VERSION 選項僅支援於無伺服器的 SQL 池。
REJECT_TYPE = { 價值 | 百分比 }
釐清選項是否 REJECT_VALUE 指定為常值或百分比。
價值
REJECT_VALUE是常值,而不是百分比。 當被拒絕的列數超過 reject_value 時,PolyBase 查詢會失敗。當被拒絕的列數超過 reject_value 時,查詢會失敗。 例如,若
REJECT_VALUE = 5且REJECT_TYPE = value,則 PolyBaseSELECT查詢在被拒絕五列後即告失敗。百分比
REJECT_VALUE是百分比,而不是常值。 當失敗列的 比例 超過 reject_value 時,PolyBase 查詢會失敗。 系統會依據間隔時間計算失敗的資料列所佔百分比。- 針對
REJECT_TYPE = value, reject_value 必須是介於 0 到 2,147,483,647 之間的整數。 - 針對
REJECT_TYPE = percentage, reject_value 必須是介於 0 到 100 之間的浮點數。 百分比僅對於TYPE = HADOOP的專用 SQL 集區有效。
- 針對
REJECT_SAMPLE_VALUE = reject_sample_value
當您指定 REJECT_TYPE = percentage時,需要這個屬性。 它會決定在 PolyBase 重新計算被拒絕資料列的百分比之前,應嘗試擷取的資料列數目。
reject_sample_value 參數必須是介於 0 和 2,147,483,647 的整數。
例如,如果 REJECT_SAMPLE_VALUE = 1000,PolyBase 會計算在嘗試從外部資料檔匯入 1,000 列後,失敗列的百分比。 如果失敗的數據列百分比小於 reject_value,PolyBase 會嘗試擷取另一個 1,000 個數據列。 它會在嘗試匯入每個額外的 1,000 個數據列之後,繼續重新計算失敗數據列的百分比。
注意
由於 PolyBase 會不時計算失敗的資料列百分比,因此實際的失敗資料列百分比可能超出 reject_value。
範例
這個例子展示了這三個 REJECT 選項之間的互動。 例如,如果 REJECT_TYPE = percentage、 REJECT_VALUE = 30和 REJECT_SAMPLE_VALUE = 100,可能會發生下列案例:
- PolyBase 會嘗試擷取前 100 個資料列;其中有 25 個失敗,75 個成功。
- 失敗資料列的百分比會計算為 25%,低於拒絕值 30%。 因此,PolyBase 會繼續從外部數據源擷取數據。
- PolyBase 會嘗試載入接下來的 100 個資料列;這次有 25 個資料列成功,75 個資料列失敗。
- 失敗資料列的百分比在重新計算後為 50%。 失敗資料列的百分比已超出 30% 的拒絕值。
- PolyBase 查詢在嘗試傳回前 200 個資料列後,會因被拒絕的資料列達 50% 而失敗。 在 PolyBase 查詢偵測到拒絕閾值超過之前,會回傳匹配的列。
REJECTED_ROW_LOCATION = 目錄位置
指定外部資料來源中,已拒絕資料列和相應錯誤檔案應寫入的目錄。
如果指定的路徑不存在,它就會被創造出來。 系統會建立名稱為 _rejectedrows 的子目錄。
_ 字元可確保該目錄從其他資料處理逸出,除非已明確在位置參數中指名。
- 在無伺服器 SQL 集區中,路徑為
YearMonthDay_HourMinuteSecond_StatementID。 您可以使用statementID,將資料夾與產生的查詢相互關聯。 - 在專用 SQL 集區中,建立的路徑是以載入提交的時間為基礎,而格式為
YearMonthDay -HourMinuteSecond,例如20180330-173205。
在此資料中寫入了兩種類型的檔案,分別是 _reason 檔案與資料檔案。
如需詳細資訊,請參閱CREATE EXTERNAL DATA SOURCE。
原因檔案與資料檔案均具有與 CTAS 陳述式相關的 queryID。 因為資料與原因檔案在不同的檔案中,所以對應的檔案會具有相符尾碼。
在無伺服器 SQL 集區中,error.json 檔案包含發生與拒絕資料列相關錯誤的 JSON 陣列。 代表錯誤的元素都包含下列屬性:
| 屬性 | 描述 |
|---|---|
Error |
資料列被拒絕的原因。 |
Row |
檔案中的拒絕資料列序數。 |
Column |
拒絕資料行序數。 |
Value |
拒絕資料行值。 如果值大於 100 個字元,則只會顯示前 100 個字元。 |
File |
資料列所屬的檔案路徑。 |
權限
需要下列使用者權限:
CREATE TABLEALTER ANY SCHEMAALTER ANY EXTERNAL DATA SOURCEALTER ANY EXTERNAL FILE FORMAT-
CONTROL DATABASE僅需權限才能建立主金鑰、資料庫範圍的憑證及外部資料來源。
指令中使用的遠端登入DATABASE SCOPED CREDENTIALCREATE EXTERNAL TABLE必須對參數中指定的路徑擁有LOCATION權限。 如果你打算用這個外部資料表匯出資料到Azure Blob 儲存體或Azure Data Lake Storage,登入也必須在同一路徑上擁有
重要
此 ALTER ANY EXTERNAL DATA SOURCE 權限賦予任何主體建立及修改任何外部資料來源物件的能力,因此也授權存取資料庫上所有具有資料庫範圍的憑證。 必須將此權限視為具高度權限,因此必須僅授與系統中受信任的主體。
錯誤處理
在執行 CREATE EXTERNAL TABLE 語句時,PolyBase 會嘗試連線到外部數據源。 如果嘗試連接失敗,該語句也會失敗,外部資料表也不會被建立。 由於 PolyBase 在查詢失敗之前會多次嘗試連線,因此可能需要一分鐘或更久的時間,命令才會失敗。
備註
在臨機作查詢案例中,例如 SELECT FROM EXTERNAL TABLE,PolyBase 會將從外部數據源擷取的數據列儲存在臨時表中。 在查詢完成之後,PolyBase 便會移除並刪除該暫存資料表。 SQL 資料表中不會永久存放資料。
相較之下,在匯入情境中,例如 SELECT INTO FROM EXTERNAL TABLE,PolyBase 會將從外部資料來源擷取的列作為永久資料存放在 SQL 資料表中。 新的資料表會在查詢執行期間,當 PolyBase 擷取外部資料時建立。
PolyBase 可以將部分的查詢計算推送至 Hadoop 以改善查詢效能。 此動作稱為謂詞推下。 要啟用它,請在 中 CREATE EXTERNAL DATA SOURCE指定 Hadoop 資源管理器的位置選項。
您可以建立許多參考相同或不同外部資料來源的外部資料表。
Azure Synapse Analytics 中的無伺服器和專用 SQL 集區會使用不同的程式碼基底來進行資料虛擬化。 無伺服器 SQL 集區支援原生資料虛擬化技術。 專用 SQL 集區同時支援原生和 PolyBase 資料虛擬化。 PolyBase EXTERNAL DATA SOURCETYPE=HADOOP資料虛擬化用於建立 。
局限性
由於外部資料表的資料不受 Azure Synapse 直接管理,因此可隨時由外部程序更改或移除。 因此,針對外部資料表的查詢結果並不保證具有確定性。 相同的查詢在每次針對外部資料表執行時,都有可能傳回不同的結果。 同樣地,在移動或移除外部資料的情況下,查詢也有可能會失敗。
外部資料表不支援帶有 UTF-8 整合的來源資料。 如果你的來源資料使用 UTF-8 排序,你必須明確為語句中的 CREATE EXTERNAL TABLE 每個 UTF-8 欄位指派非 UTF-8 排序。 無法這麼做會導致類似下列輸出的錯誤訊息:
Msg 105105, Level 16, State 1, Line 22
105105;No column collation was specified in external table definition and the collation of current database 'Latin1_General_100_CI_AS_SC_UTF8' is not supported for external tables of type 'HADOOP'. Please specify a supported collation in the column definition.
如果外部數據表的資料庫定序為UTF-8,除非以非UTF-8定序明確定義每個資料行,否則數據表建立會失敗(例如 , [UTF8_column] VARCHAR(128) COLLATE LATIN1_GENERAL_100_CI_AS_KS_WS NOT NULL。
您可以建立多個參考不同外部資料來源的外部資料表。
外部資料表上僅允許使用下列資料定義語言 (DDL) 陳述式:
-
CREATE TABLE和DROP TABLE -
CREATE STATISTICS和DROP STATISTICS -
CREATE VIEW和DROP VIEW
不支援的建構和作業:
-
DEFAULT外部數據表數據行的條件約束 - 刪除、插入及更新的資料操作語言 (DML) 作業
- 外部數據表數據行上的動態數據遮罩
查詢限制
建議每個資料夾檔案數量不要超過 3 萬。 參考太多檔案時,可能會發生 Java 虛擬機 (JVM) 記憶體不足的例外狀況,或效能可能會降低。
資料表寬度限制
Azure 資料倉儲中 PolyBase 具有 1 MB 的資料列寬度限制,這是以依資料表定義的單一有效資料列大小上限為基礎。 若資料行結構描述的總和超過 1 MB,PolyBase 便無法查詢資料。
資料類型限制
以下資料型別無法用於 PolyBase 外部資料表:
- 地理位置
- 幾何
- 層次識別碼(hierarchyid)
- 映像
- 文字
- 內容
- xml
- 任何使用者定義的類型
鎖定
共用鎖定物件 SCHEMARESOLUTION 。
範例
A。 將資料從 ADLS Gen 2 匯入至 Azure Synapse Analytics
以 Gen ADLS Gen 1 為例,請參閱建立外部資料來源。
-- These values come from your Azure Active Directory Application used to authenticate to ADLS Gen 2.
CREATE DATABASE SCOPED CREDENTIAL ADLUser
WITH
IDENTITY = '<clientID>@\<OAuth2.0TokenEndPoint>',
SECRET = '<KEY>';
GO
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH (
TYPE = HADOOP,
LOCATION = 'abfss://data@pbasetr.azuredatalakestore.net'
);
GO
CREATE EXTERNAL FILE FORMAT TextFileFormat
WITH (
FORMAT_TYPE = DELIMITEDTEXT,
FORMAT_OPTIONS (
FIELD_TERMINATOR = '|',
STRING_DELIMITER = '',
DATE_FORMAT = 'yyyy-MM-dd HH:mm:ss.fff',
USE_TYPE_DEFAULT = FALSE
)
);
GO
CREATE EXTERNAL TABLE [dbo].[DimProduct_external]
(
[ProductKey] INT NOT NULL,
[ProductLabel] NVARCHAR NULL,
[ProductName] NVARCHAR NULL
)
WITH (
DATA_SOURCE = AzureDataLakeStore,
LOCATION = '/DimProduct/',
FILE_FORMAT = TextFileFormat,
REJECT_TYPE = value,
REJECT_VALUE = 0
);
GO
CREATE TABLE [dbo].[DimProduct]
WITH (DISTRIBUTION = HASH([ProductKey])) AS
GO
SELECT *
FROM [dbo].[DimProduct_external];
B. 將資料從 Parquet 匯入至 Azure Synapse Analytics
下列範例會建立外部資料表, 接著會傳回第一個資料列:
CREATE EXTERNAL TABLE census_external_table
(
decennialTime VARCHAR (20),
stateName VARCHAR (100),
countyName VARCHAR (100),
population INT,
race VARCHAR (50),
sex VARCHAR (10),
minAge INT,
maxAge INT
)
WITH (
DATA_SOURCE = population_ds,
LOCATION = '/parquet/',
FILE_FORMAT = census_file_format
);
GO
SELECT TOP 1 *
FROM census_external_table;
相關內容
*分析學
平台系統 (PDW) *
概觀:分析平台系統
使用外部資料表來:
- 搭配 Transact-SQL 查詢 Hadoop 或 Azure Blob 儲存體資料。
- 從 Hadoop 或 Azure Blob 儲存體將資料匯入並儲存至 Analytics Platform System。
請參閱 CREATE EXTERNAL DATA SOURCE 與 DROP EXTERNAL TABLE。
語法
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ , ...n ] )
WITH (
LOCATION = 'hdfs_folder_or_filepath' ,
DATA_SOURCE = external_data_source_name ,
FILE_FORMAT = external_file_format_name
[ , <reject_options> [ , ...n ] ]
)
[ ; ]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<reject_options> ::=
{
| REJECT_TYPE = { value | percentage },
| REJECT_VALUE = reject_value ,
| REJECT_SAMPLE_VALUE = reject_sample_value ,
}
引數
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
要建立之資料表名稱的第一到第三部分。
針對外部資料表,Analytics Platform System 只會儲存資料表中繼資料,以及 Hadoop 或 Azure Blob 儲存體中所參考檔案或資料夾的基本統計資料。 不會在 Analytics Platform System 中移動或儲存任何實際資料。
重要
為了達到最佳效能,如果外部資料來源驅動程式支援三段式名稱,你應該提供三段式名稱。
< > column_definition [ ,...n ]
CREATE EXTERNAL TABLE 支援設定數據行名稱、數據類型、Null 性和定序的功能。 您無法在 DEFAULT CONSTRAINT 外部資料表上使用 。
資料行定義 (包括資料類型及資料行數目) 必須符合外部檔案中的資料。 如果發生不相符的情況,查詢實際數據時會拒絕檔案數據列。
位置 = 'folder_or_filepath'
指定位於 Hadoop 或 Azure Blob 儲存體中之實際資料的資料夾或檔案路徑,以及檔案名稱。 位置會從根資料夾開始。 根資料夾是在外部資料來源中指定的資料位置。
在分析平台系統中,如果路徑和資料夾不存在,則用 CREATE EXTERNAL TABLE AS SELECT (CETAS) 陳述來建立。
CREATE EXTERNAL TABLE 則不會建立路徑和資料夾。
如果你指定 LOCATION 為資料夾,從外部資料表中選擇的 PolyBase 查詢會從資料夾及其所有子資料夾取得檔案。 PolyBase 和 Hadoop 相同,並不會傳回隱藏的資料夾。 它也不會回傳檔名以底線_()或句點.()開頭的檔案。
以下圖片範例中,若 LOCATION='/webdata/',PolyBase 查詢會回傳來自 mydata.txt 和 mydata2.txt的列。 它不會回傳 mydata3.txt 是因為它在隱藏資料夾的子資料夾裡,也因為是隱藏檔案才不會回傳 _hidden.txt 。
若要變更預設設定並僅從根資料夾讀取,請在 <polybase.recursive.traversal> 設定檔中將 core-site.xml 屬性設為 'false'。 此檔案位於 SQL Server 根目錄底下<SqlBinRoot>\PolyBase\Hadoop\Conf\bin。 例如: C:\Program Files\Microsoft SQL Server\MSSQL13.XD14\MSSQL\Binn\ 。
DATA_SOURCE = external_data_source_name
可指定包含外部資料位置的外部資料來源名稱。 此位置可為 Hadoop 或 Azure Blob 儲存體。 若要建立外部資料來源,請使用 CREATE EXTERNAL DATA SOURCE。
FILE_FORMAT = external_file_format_name
可指定外部檔案格式物件的名稱,該物件中儲存了外部資料的檔案類型和壓縮方法。 要建立外部檔案格式,請使用 CREATE EXTERNAL FILE FORMAT。
REJECT 選項
此選項僅適用於外部資料來源,且 。TYPE = HADOOP
你可以指定拒絕參數,決定 PolyBase 如何處理從外部資料來源取得 的髒 紀錄。 若資料記錄的實際資料類型或資料行數目,與外部資料表的資料行定義不相符,該資料記錄就會被系統視為「已修改」。
當您不指定或變更拒絕值時,PolyBase 就會使用預設值。 當你建立帶有 CREATE EXTERNAL TABLE 陳述的外部資料表時,這些拒絕參數的資訊會作為額外的中繼資料儲存。 當未來 SELECT 的語句 SELECT INTO SELECT 或語句從外部資料表中選擇資料時,PolyBase 會利用拒絕選項來決定在實際查詢失敗前可被拒絕的列數或百分比。 查詢會(部分回傳)結果,直到被超過拒絕閾值為止。 接著它便會失敗並顯示適當的錯誤訊息。
REJECT_TYPE = { 價值 | 百分比 }
釐清選項是否 REJECT_VALUE 指定為常值或百分比。
價值
REJECT_VALUE是常值,而不是百分比。 當被拒絕的列數超過 reject_value 時,PolyBase 查詢會失敗。例如,若
REJECT_VALUE = 5且REJECT_TYPE = value,則 PolyBaseSELECT查詢在被拒絕五列後即告失敗。百分比
REJECT_VALUE是百分比,而不是常值。 當失敗列的 比例 超過 reject_value 時,PolyBase 查詢會失敗。 系統會依據間隔時間計算失敗的資料列所佔百分比。
REJECT_VALUE = reject_value
指定在查詢失敗之前可以拒絕的資料列數目或百分比。
針對 REJECT_TYPE = value, reject_value 必須是介於 0 到 2,147,483,647 之間的整數。
針對 REJECT_TYPE = percentage, reject_value 必須是介於 0 到 100 之間的浮點數。
REJECT_SAMPLE_VALUE = reject_sample_value
當您指定 REJECT_TYPE = percentage時,需要這個屬性。 它會決定在 PolyBase 重新計算被拒絕資料列的百分比之前,應嘗試擷取的資料列數目。
reject_sample_value 參數必須是介於 0 和 2,147,483,647 的整數。
例如,如果 REJECT_SAMPLE_VALUE = 1000,PolyBase 會計算在嘗試從外部資料檔匯入 1,000 列後,失敗列的百分比。 如果失敗的數據列百分比小於 reject_value,PolyBase 會嘗試擷取另一個 1,000 個數據列。 它會在嘗試匯入每個額外的 1,000 個數據列之後,繼續重新計算失敗數據列的百分比。
注意
由於 PolyBase 會不時計算失敗的資料列百分比,因此實際的失敗資料列百分比可能超出 reject_value。
範例
這個例子展示了這三個 REJECT 選項之間的互動。 例如,如果 REJECT_TYPE = percentage、 REJECT_VALUE = 30和 REJECT_SAMPLE_VALUE = 100,可能會發生下列案例:
- PolyBase 會嘗試擷取前 100 個資料列;其中有 25 個失敗,75 個成功。
- 失敗資料列的百分比會計算為 25%,低於拒絕值 30%。 因此,PolyBase 會繼續從外部數據源擷取數據。
- PolyBase 會嘗試載入接下來的 100 個資料列;這次有 25 個資料列成功,75 個資料列失敗。
- 失敗資料列的百分比在重新計算後為 50%。 失敗資料列的百分比已超出 30% 的拒絕值。
- PolyBase 查詢在嘗試傳回前 200 個資料列後,會因被拒絕的資料列達 50% 而失敗。 在 PolyBase 查詢偵測到拒絕閾值超過之前,會回傳匹配的列。
權限
需要下列使用者權限:
CREATE TABLEALTER ANY SCHEMAALTER ANY EXTERNAL DATA SOURCEALTER ANY EXTERNAL FILE FORMATCONTROL DATABASE
建立外部資料來源的登入者必須擁有讀取與寫入外部資料來源的權限,該資料來源位於 Hadoop 或 Azure Blob 儲存體。
重要
此 ALTER ANY EXTERNAL DATA SOURCE 權限賦予任何主體建立及修改任何外部資料來源物件的能力,因此也授權存取資料庫上所有具有資料庫範圍的憑證。 必須將此權限視為具高度權限,因此必須僅授與系統中受信任的主體。
錯誤處理
在執行 CREATE EXTERNAL TABLE 語句時,PolyBase 會嘗試連線到外部數據源。 如果嘗試連接失敗,該語句也會失敗,外部資料表也不會被建立。 由於 PolyBase 在查詢失敗之前會多次嘗試連線,因此可能需要一分鐘或更久的時間,命令才會失敗。
備註
在臨機作查詢案例中,例如 SELECT FROM EXTERNAL TABLE,PolyBase 會將從外部數據源擷取的數據列儲存在臨時表中。 在查詢完成之後,PolyBase 便會移除並刪除該暫存資料表。 SQL 資料表中不會永久存放資料。
相較之下,在匯入情境中,例如 SELECT INTO FROM EXTERNAL TABLE,PolyBase 會將從外部資料來源擷取的列作為永久資料存放在 SQL 資料表中。 新的資料表會在查詢執行期間,當 PolyBase 擷取外部資料時建立。
PolyBase 可以將部分的查詢計算推送至 Hadoop 以改善查詢效能。 此動作稱為謂詞推下。 要啟用它,請在 中 CREATE EXTERNAL DATA SOURCE指定 Hadoop 資源管理器的位置選項。
您可以建立許多參考相同或不同外部資料來源的外部資料表。
局限性
由於外部資料表的資料不受設備直接管理,外部程序隨時可能更改或移除資料。 因此,針對外部資料表的查詢結果並不保證具有確定性。 相同的查詢在每次針對外部資料表執行時,都有可能傳回不同的結果。 同樣地,在移動或移除外部資料的情況下,查詢也有可能會失敗。
您可以建立多個參考不同外部資料來源的外部資料表。 如果您同時針對不同的 Hadoop 資料來源執行查詢,則每個 Hadoop 來源都必須使用相同的「Hadoop 連線能力」伺服器組態設定。 例如,您不能同時針對 Cloudera Hadoop 叢集和 Hortonworks Hadoop 叢集執行查詢,因為這些叢集是使用不同的組態設定。 關於設定設定及支援組合,請參見 PolyBase 連接性配置。
外部資料表上僅允許使用下列資料定義語言 (DDL) 陳述式:
-
CREATE TABLE和DROP TABLE -
CREATE STATISTICS和DROP STATISTICS -
CREATE VIEW和DROP VIEW
不支援的建構和作業:
-
DEFAULT外部數據表數據行的條件約束 - 刪除、插入及更新的資料操作語言 (DML) 作業
- 外部數據表數據行上的動態數據遮罩
查詢限制
執行 32 個並行的 PolyBase 查詢時,PolyBase 每個資料夾可取用的檔案數目上限為 33000 個檔案。 這個上限數同時包含了每個 HDFS 資料夾中的檔案和子資料夾。 如果並行程度小於 32,使用者就可以針對 HDFS 中內含超過 33000 個檔案的資料夾執行 PolyBase 查詢。 我們建議您使用簡短的外部檔案路徑,且所使用的每個 HDFS 資料夾檔案數目不要超過 30000 個檔案。 參考太多檔案時,可能會發生 Java 虛擬機器 (JVM) 記憶體不足的例外狀況。
資料表寬度限制
在 SQL Server 2016(13.x)中,PolyBase 的列寬度限制為 32 KB,這是根據資料表定義單一有效資料列的最大大小。 若資料行結構描述的總和超過 32 KB,PolyBase 將無法查詢資料。
在 Azure Synapse Analytics 中,這項限制已提高至 1 MB。
資料類型限制
以下資料型別無法用於 PolyBase 外部資料表:
- 地理位置
- 幾何
- 層次識別碼(hierarchyid)
- 映像
- 文字
- 內容
- xml
- 任何使用者定義的類型
鎖定
共用鎖定物件 SCHEMARESOLUTION 。
安全性
外部資料表的資料檔案會儲存在 Hadoop 或 Azure Blob 儲存體中。 這些資料檔案是由您自己的處理程序所建立及管理。 管理外部資料的安全是你的責任。
範例
A。 聯結 HDFS 資料及 Analytics Platform System 資料
SELECT cs.user_ip
FROM ClickStream AS cs
INNER JOIN [User] AS u
ON cs.user_ip = u.user_ip
WHERE cs.url = 'www.microsoft.com';
B. 從 HDFS 將資料列資料匯入至分散式 Analytics Platform System 資料表
CREATE TABLE ClickStream_PDW
WITH (DISTRIBUTION = HASH(url)) AS
SELECT url,
event_date,
user_ip
FROM ClickStream;
C. 從 HDFS 將資料列資料匯入至複寫 Analytics Platform System 資料表
CREATE TABLE ClickStream_PDW
WITH (DISTRIBUTION = REPLICATE) AS
SELECT url,
event_date,
user_ip
FROM ClickStream;
相關內容
* Azure SQL 受控執行個體 *
概觀:Azure SQL 受控執行個體
在 Azure SQL 受控執行個體中建立外部資料表。 如需完整資訊,請參閱具有 Azure SQL 受控執行個體的資料虛擬化。
Azure SQL 管理實例中的資料虛擬化提供多種檔案格式的外部資料存取,如 Azure Data Lake Storage Gen2 或 Azure Blob 儲存體,並可用 T-SQL 語句查詢,甚至透過 joins 將資料與本地儲存的關聯資料結合。
請參閱 CREATE EXTERNAL DATA SOURCE 與 DROP EXTERNAL TABLE。
語法
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ , ...n ] )
WITH (
LOCATION = 'filepath' ,
DATA_SOURCE = external_data_source_name ,
FILE_FORMAT = external_file_format_name
)
[ ; ]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
引數
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
要建立之資料表名稱的第一到第三部分。
針對外部資料表,只有資料表中繼資料,以及 Azure Data Lake 或 Azure Blob 儲存體中所參考檔案或資料夾的基本統計資料。 建立外部資料表時,不會移動或儲存實際資料。
重要
為了達到最佳效能,如果外部資料來源驅動程式支援三段式名稱,你應該提供三段式名稱。
< > column_definition [ ,...n ]
CREATE EXTERNAL TABLE 支援設定數據行名稱、數據類型、Null 性和定序的功能。 您無法在 DEFAULT CONSTRAINT 外部資料表上使用 。
資料行定義 (包括資料類型及資料行數目) 必須符合外部檔案中的資料。 如果發生不相符的情況,查詢實際數據時會拒絕檔案數據列。
位置 = 'folder_or_filepath'
指定位於 Azure Data Lake 或 Azure Blob 儲存體中實際資料的資料夾或檔案路徑,以及檔案名稱。 位置會從根資料夾開始。 根資料夾是在外部資料來源中指定的資料位置。
CREATE EXTERNAL TABLE 則不會建立路徑和資料夾。
如果你指定 LOCATION 為資料夾,Azure SQL 管理實例從外部資料表中選取的查詢會從資料夾取得檔案,但不會取得所有子資料夾的檔案。
Azure SQL 管理實例無法在子資料夾或隱藏資料夾中找到檔案。 它也不會回傳檔名以底線_()或句點.()開頭的檔案。
以下圖片範例中,若 LOCATION='/webdata/',查詢回傳來自 mydata.txt的列。 它不回傳mydata2.txt是因為它在子資料夾裡,不回傳是因為它在隱藏資料夾裡,也不會回傳mydata3.txt_hidden.txt是因為它是隱藏檔案。
DATA_SOURCE = external_data_source_name
可指定包含外部資料位置的外部資料來源名稱。 此位置位於 Azure Data Lake 中。 若要建立外部資料來源,請使用 CREATE EXTERNAL DATA SOURCE。
FILE_FORMAT = external_file_format_name
可指定外部檔案格式物件的名稱,該物件中儲存了外部資料的檔案類型和壓縮方法。 要建立外部檔案格式,請使用 CREATE EXTERNAL FILE FORMAT。
權限
需要下列使用者權限:
CREATE TABLEALTER ANY SCHEMAALTER ANY EXTERNAL DATA SOURCEALTER ANY EXTERNAL FILE FORMAT-
CONTROL DATABASE僅需權限才能建立主金鑰、資料庫範圍的憑證及外部資料來源。
建立外部資料來源的登入者必須擁有讀取與寫入外部資料來源的權限,該資料來源位於 Hadoop 或 Azure Blob 儲存體。
重要
此 ALTER ANY EXTERNAL DATA SOURCE 權限賦予任何主體建立及修改任何外部資料來源物件的能力,因此也授權存取資料庫上所有具有資料庫範圍的憑證。 必須將此權限視為具高度權限,因此必須僅授與系統中受信任的主體。
備註
在臨機作查詢案例中,例如 SELECT FROM EXTERNAL TABLE,從外部數據源擷取的數據列會儲存在臨時表中。 查詢完成之後,系統會移除資料列,並刪除暫存資料表。 SQL 資料表中不會永久存放資料。
相反地,在匯入案例中,例如 SELECT INTO FROM EXTERNAL TABLE,從外部數據源擷取的數據列會儲存為 SQL 數據表中的永久數據。 新的資料表會在查詢執行期間擷取外部資料時建立。
目前,具有 Azure SQL 受控執行個體的資料虛擬化是唯讀的。
您可以建立許多參考相同或不同外部資料來源的外部資料表。
局限性
由於外部資料表的資料不受 Azure SQL 管理實例的直接管理,因此它可以隨時被外部程序更改或移除。 因此,針對外部資料表的查詢結果並不保證具有確定性。 相同的查詢在每次針對外部資料表執行時,都有可能傳回不同的結果。 同樣地,在移動或移除外部資料的情況下,查詢也有可能會失敗。
您可以建立多個參考不同外部資料來源的外部資料表。
外部資料表上僅允許使用下列資料定義語言 (DDL) 陳述式:
-
CREATE TABLE和DROP TABLE -
CREATE STATISTICS和DROP STATISTICS -
CREATE VIEW和DROP VIEW
不支援的建構和作業:
- 外部
DEFAULT數據表數據行的條件約束 - 刪除、插入及更新的資料操作語言 (DML) 作業
資料表寬度限制
1 MB 的資料列寬度限制以依資料表定義的單一有效資料列大小上限為基礎。 若欄位結構的總和大於 1 MB,資料虛擬化查詢即失敗。
資料類型限制
以下資料型別無法用於 Azure SQL 管理實例的外部資料表:
- 地理位置
- 幾何
- 層次識別碼(hierarchyid)
- 映像
- 文字
- 內容
- xml
- json
- 任何使用者定義的類型
鎖定
共用鎖定物件 SCHEMARESOLUTION 。
範例
A。 使用外部資料表從 Azure SQL 受控執行個體查詢外部資料
更多範例請參見 CREATE EXTERNAL DATA SOURCEAzure SQL 受控執行個體 的資料虛擬化。
如果資料庫主要金鑰不存在,請建立資料庫主要金鑰。
-- Optional: Create MASTER KEY if it doesn't exist in the database: CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<password>';使用 SAS 權杖建立資料庫範圍認證。 您也可以使用受控識別。
CREATE DATABASE SCOPED CREDENTIAL MyCredential WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = '<KEY>'; --Removing leading '?'使用認證建立外部資料來源。
--Create external data source pointing to the file path, and referencing database-scoped credential: CREATE EXTERNAL DATA SOURCE MyPrivateExternalDataSource WITH ( LOCATION = 'abs://public@pandemicdatalake.blob.core.windows.net/curated/covid-19/bing_covid-19_data/latest' CREDENTIAL = [MyCredential] );建立一個
EXTERNAL FILE FORMAT和EXTERNAL TABLE一個,讓資料像查詢本地資料表一樣。-- Or, create an EXTERNAL FILE FORMAT and an EXTERNAL TABLE --Create external file format CREATE EXTERNAL FILE FORMAT DemoFileFormat WITH ( FORMAT_TYPE = PARQUET ); --Create external table: CREATE EXTERNAL TABLE tbl_TaxiRides ( vendorID VARCHAR (100) COLLATE Latin1_General_BIN2, tpepPickupDateTime DATETIME2, tpepDropoffDateTime DATETIME2, passengerCount INT, tripDistance FLOAT, puLocationId VARCHAR (8000), doLocationId VARCHAR (8000), startLon FLOAT, startLat FLOAT, endLon FLOAT, endLat FLOAT, rateCodeId SMALLINT, storeAndFwdFlag VARCHAR (8000), paymentType VARCHAR (8000), fareAmount FLOAT, extra FLOAT, mtaTax FLOAT, improvementSurcharge VARCHAR (8000), tipAmount FLOAT, tollsAmount FLOAT, totalAmount FLOAT ) WITH ( DATA_SOURCE = NYCTaxiExternalDataSource, LOCATION = 'yellow/puYear = */puMonth = */*.parquet', FILE_FORMAT = MyFileFormat ); --Then, query the data via an external table with T-SQL: SELECT TOP 10 * FROM tbl_TaxiRides;
相關內容
在下列文章中深入了解外部資料表與相關概念:
概觀:Microsoft網狀架構
適用於:Microsoft Fabric Data Warehouse
如需 Fabric 數據倉儲中的詳細資訊和範例 OPENROWSET ,請參閱:
* Fabric SQL 資料庫 *
概述:Microsoft Fabric 中的 SQL 資料庫
建立外部資料表。
語法
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ , ...n ] )
WITH (
LOCATION = 'filepath' ,
DATA_SOURCE = external_data_source_name ,
FILE_FORMAT = external_file_format_name
)
[ ; ]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
引數
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
要建立之資料表名稱的第一到第三部分。
對於外部資料表,SQL 僅儲存資料表的元資料以及關於檔案或資料夾的基本統計資料。 當建立外部資料表時,Fabric 的 SQL 資料庫中不會移動或儲存實際資料。
重要
為了達到最佳效能,如果外部資料來源驅動程式支援三段式名稱,你應該提供三段式名稱。
< > column_definition [ ,...n ]
CREATE EXTERNAL TABLE 支援設定數據行名稱、數據類型、Null 性和定序的功能。 您無法在 DEFAULT CONSTRAINT 外部資料表上使用 。 以下資料型態不支援外部資料表中的欄位:
- 地理位置
- 幾何
- 層次識別碼(hierarchyid)
- 映像
- 文字
- 內容
- xml
- json
- 任何使用者定義的類型
資料行定義 (包括資料類型及資料行數目) 必須符合外部檔案中的資料。 如果發生不相符的情況,查詢實際數據時會拒絕檔案數據列。
位置 = 'folder_or_filepath'
指定 OneLake 中 Microsoft Fabric 中實際資料的資料夾或檔案路徑及檔案名稱。
DATA_SOURCE
DATA_SOURCE指定包含外部資料位置的外部數據源名稱。 若要建立外部資料來源,請使用 CREATE EXTERNAL DATA SOURCE。
FILE_FORMAT = external_file_format_name
可指定外部檔案格式物件的名稱,該物件中儲存了外部資料的檔案類型和壓縮方法。 要建立外部檔案格式,請使用 CREATE EXTERNAL FILE FORMAT。
權限
可存取外部資料表的使用者可以在外部資料來源定義中所提供的認證下,自動取得基礎遠端資料表的存取權。 避免透過外部資料來源認證提高不想提高的權限。 使用 GRANT 或 REVOKE 作為外部表格,就像一般表格一樣。 一旦您已定義外部資料來源和外部資料表,現在您可以對外部資料表使用完整的 T-SQL。
CREATE EXTERNAL TABLE 需要這些用戶權力:
CREATE TABLEALTER ANY SCHEMAALTER ANY EXTERNAL DATA SOURCEALTER ANY EXTERNAL FILE FORMAT-
CONTROL DATABASE僅需權限才能建立主金鑰、資料庫範圍的憑證及外部資料來源。
建立外部資料來源的登入者必須擁有讀取與寫入外部資料來源的權限,該資料來源位於 Hadoop 或 Azure Blob 儲存體。
重要
此 ALTER ANY EXTERNAL DATA SOURCE 權限賦予任何主體建立及修改任何外部資料來源物件的能力,因此也授權存取資料庫上所有具有資料庫範圍的憑證。 必須將此權限視為具高度權限,因此必須僅授與系統中受信任的主體。
鎖定
共用鎖定物件 SCHEMARESOLUTION 。
備註
在臨機作查詢案例中,例如 SELECT FROM EXTERNAL TABLE,從外部數據源擷取的數據列會儲存在臨時表中。 查詢完成之後,系統會移除資料列,並刪除暫存資料表。 SQL 資料表中不會永久存放資料。
相反地,在匯入案例中,例如 SELECT INTO FROM EXTERNAL TABLE,從外部數據源擷取的數據列會儲存為 SQL 數據表中的永久數據。 新的資料表會在查詢執行期間擷取外部資料時建立。
Fabric SQL 資料庫僅支援 Microsoft Fabric 中的 OneLake 作為資料來源。
您可以建立許多參考相同或不同外部資料來源的外部資料表。
資料表寬度限制
1 MB 的資料列寬度限制以依資料表定義的單一有效資料列大小上限為基礎。 若欄位結構的總和大於 1 MB,資料虛擬化查詢即失敗。
錯誤處理
CREATE EXTERNAL TABLE執行該陳述式時,如果連接嘗試失敗,則陳述式失敗,外部資料表也不會被建立。 由於 SQL Database 在查詢失敗之前會多次嘗試連線,因此可能需要一分鐘或更久的時間,命令才會失敗。
局限性
目前在 Fabric SQL 資料庫中建立指向 CSV 檔案的外部資料表時,必須提供資料表結構,例如: SELECT * FROM [schema].[table_name]。 否則,會顯示以下錯誤訊息:
Msg 208, Level 16, State 160, Line 1: Invalid object name 'SQLdatabase-id'
由於外部資料表的資料不受資料庫引擎直接管理,外部程序隨時可能更改或移除資料。 因此,針對外部資料表的查詢結果並不保證具有確定性。 相同的查詢在每次針對外部資料表執行時,都有可能傳回不同的結果。 同樣地,在移動或移除外部資料的情況下,查詢也有可能會失敗。
您可以建立多個參考不同外部資料來源的外部資料表。
外部資料表上僅允許使用下列資料定義語言 (DDL) 陳述式:
-
CREATE TABLE和DROP TABLE -
CREATE STATISTICS和DROP STATISTICS -
CREATE VIEW和DROP VIEW
不支援的建構和作業:
- 外部
DEFAULT數據表數據行的條件約束。 - 刪除、插入及更新的資料操作語言 (DML) 作業。
範例
A。 建立一個外部資料表,針對 Microsoft Fabric 中 OneLake 上的 Parquet 檔案
CREATE EXTERNAL DATA SOURCE [MainLakeHouse]
WITH (
LOCATION = 'abfss://<WorkspaceID>@<tenant>.dfs.fabric.microsoft.com/<Lakehouse_id'
);
GO
CREATE EXTERNAL FILE FORMAT [Parquetff]
WITH (
FORMAT_TYPE = PARQUET
);
GO
CREATE EXTERNAL TABLE Customer_parquet
(
CustomerKey INT,
GeoAreaKey INT,
StartDT DATETIME2,
EndDT DATETIME2,
Continent NVARCHAR (50),
Gender NVARCHAR (10),
Title NVARCHAR (10),
GivenName NVARCHAR (100),
MiddleInitial VARCHAR (2),
Surname NVARCHAR (100),
StreetAddress NVARCHAR (200),
City NVARCHAR (100),
State NVARCHAR (100),
StateFull NVARCHAR (100),
ZipCode NVARCHAR (20),
Country_Region NCHAR (2),
CountryFull NVARCHAR (100),
Birthday DATETIME2,
Age INT,
Occupation NVARCHAR (100),
Company NVARCHAR (100),
Vehicle NVARCHAR (100),
Latitude DECIMAL (10, 6),
Longitude DECIMAL (10, 6)
)
WITH (
DATA_SOURCE = MainLakeHouse,
LOCATION = '/Files/parquet/customer.parquet',
FILE_FORMAT = [parquetff]
);
GO
SELECT *
FROM Customer_parquet;