模型自訂 (4.0 版預覽版)
重要
這項功能現在已被取代。 在 2025 年 1 月 10 日,Azure AI 影像分析 4.0 自定義影像分類、自定義物件偵測和產品辨識預覽 API 將會淘汰。 在此日期之後,對這些服務的 API 呼叫將會失敗。
若要維持模型的順暢作業,請轉換至現已正式推出的 Azure AI 自訂視覺。 自訂視覺提供與這些淘汰功能類似的功能。
模型自訂可讓您針對自己的使用案例定型特殊化影像分析模型。 自訂模型可以執行影像分類 (標籤套用至整個影像) 或物件偵測 (標籤套用至影像的特定區域)。 建立並定型自訂模型之後,模型即屬於您的視覺資源,而且您可以使用分析影像 API 來呼叫它。
遵循快速入門,快速又輕鬆地實作模型自訂:
重要
您可以使用自訂視覺服務或具有模型自訂的影像分析 4.0 服務來定型自訂模型。 下表提供這兩種服務的比較。
| 區域 | 自訂視覺服務 | 影像分析 4.0 服務 | ||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 工作 | 影像分類 物件偵測 |
影像分類 物件偵測 |
||||||||||||||||||||||||||||||||||||
| 基本模型 | CNN | 轉換器模型 | ||||||||||||||||||||||||||||||||||||
| 標記 | Customvision.ai | AML Studio | ||||||||||||||||||||||||||||||||||||
| 入口網站 | Customvision.ai | Vision Studio | ||||||||||||||||||||||||||||||||||||
| 程式庫 | REST,SDK | REST,Python 範例 | ||||||||||||||||||||||||||||||||||||
| 所需的最小定型資料 | 每個類別 15 個影像 | 每個類別 2-5 個影像 | ||||||||||||||||||||||||||||||||||||
| 訓練資料儲存體 | 上傳至服務 | 客戶的 Blob 儲存體帳戶 | ||||||||||||||||||||||||||||||||||||
| 模型裝載 | 雲端和邊緣 | 僅限雲端裝載、邊緣容器裝載即將推出 | ||||||||||||||||||||||||||||||||||||
| AI 品質 |
|
|
||||||||||||||||||||||||||||||||||||
| 定價 | 自訂視覺定價 | 影像分析價格 |
情節元件
模型自訂系統的主要元件是定型影像、COCO 檔案、資料集物件和模型物件。
定型影像
您的一組定型影像應該包含您想要偵測的每個標籤範例。 您也會想要收集一些額外的影像,來測試已定型的模型。 影像必須儲存在 Azure 儲存體容器中,才能供模型存取。
若要有效地定型您的模型,可使用有不同視覺效果的影像。 選取有下列各種變化的影像:
- 攝影機角度
- 光源
- 背景
- 視覺效果樣式
- 單一/群組對象
- size
- type
此外,請確定所有的訓練映像符合下列準則:
- 影像必須以 JPEG、PNG、GIF、BMP、WEBP、ICO、TIFF 或 MPO 格式呈現。
- 影像的檔案大小必須小於 20 MB。
- 影像的維度必須大於 50 x 50 像素,且小於 16,000 x 16,000 像素。
COCO 檔案
COCO 檔案會參考所有定型影像,並將其與其標籤資訊建立關聯。 在物件偵測的情況下,其會指定每個影像上每個標籤的周框方塊座標。 此檔案必須是 COCO 格式,這是 JSON 檔案的特定類型。 COCO 檔案應該儲存在與定型影像相同的 Azure 儲存體容器中。
提示
關於 COCO 檔案
COCO 檔案是具有特定必要欄位的 JSON 檔案:"images"、"annotations" 和 "categories"。 範例 COCO 檔案看起來會像這樣:
{
"images": [
{
"id": 1,
"width": 500,
"height": 828,
"file_name": "0.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/0.jpg"
},
{
"id": 2,
"width": 754,
"height": 832,
"file_name": "1.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/1.jpg"
},
...
],
"annotations": [
{
"id": 1,
"category_id": 7,
"image_id": 1,
"area": 0.407,
"bbox": [
0.02663142641129032,
0.40691584277841153,
0.9524163571731749,
0.42766634515266866
]
},
{
"id": 2,
"category_id": 9,
"image_id": 2,
"area": 0.27,
"bbox": [
0.11803319477782331,
0.41586723392402375,
0.7765206955096307,
0.3483334397217212
]
},
...
],
"categories": [
{
"id": 1,
"name": "vegall original mixed vegetables"
},
{
"id": 2,
"name": "Amy's organic soups lentil vegetable"
},
{
"id": 3,
"name": "Arrowhead 8oz"
},
...
]
}
COCO 檔案欄位參考
如果您要從頭開始產生自己的 COCO 檔案,請確定所有必要的欄位都已填入正確的詳細資料。 下表描述 COCO 檔案中的每個欄位:
"images"
| 機碼 | 類型 | 描述 | 是必要的嗎? |
|---|---|---|---|
id |
整數 | 唯一影像識別碼,從 1 開始 | Yes |
width |
整數 | 以像素為單位的影像寬度 | Yes |
height |
整數 | 以像素為單位的影像高度 | Yes |
file_name |
string | 影像的唯一名稱 | Yes |
absolute_url 或 coco_url |
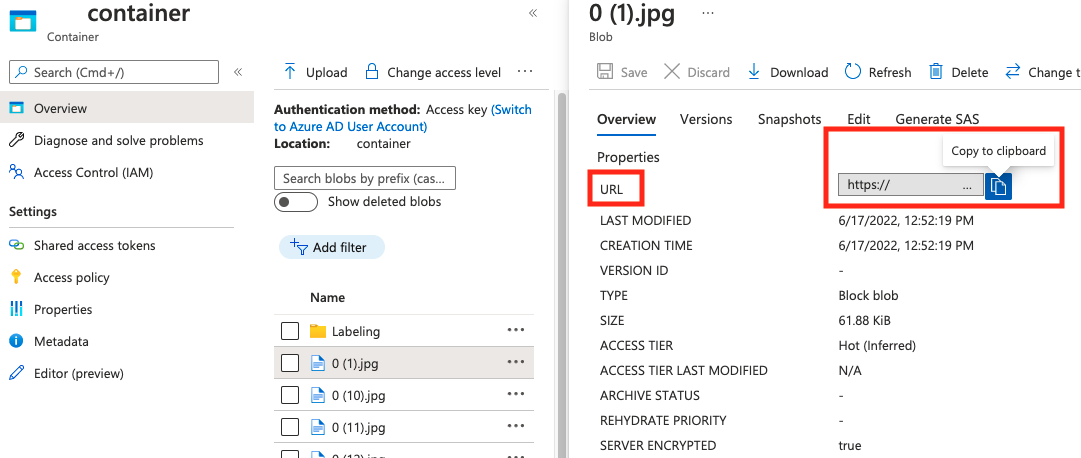
string | 作為 Blob 容器中 Blob 絕對 URI 的影像路徑。 視覺資源必須具有讀取註釋檔案和所有參考影像檔案的權限。 | Yes |
absolute_url 的值可以在 Blob 容器的屬性中找到:
"annotations"
| 機碼 | 類型 | 描述 | 是必要的嗎? |
|---|---|---|---|
id |
整數 | 註釋的識別碼 | Yes |
category_id |
整數 | categories 區段中定義的類別識別碼 |
Yes |
image_id |
整數 | 影像的識別碼 | Yes |
area |
整數 | 'Width' x 'Height' 的值 (bbox 的第三和第四個值) |
No |
bbox |
list[float] | 周框方塊的相對座標 (0 到 1),順序為 'Left'、'Top'、'Width'、'Height' | Yes |
"categories"
| 機碼 | 類型 | 描述 | 是必要的嗎? |
|---|---|---|---|
id |
整數 | 每個類別的唯一識別碼 (標籤類別)。 這些應該會出現在 annotations 區段中。 |
Yes |
name |
string | 類別的名稱 (標籤類別) | Yes |
COCO 檔案驗證
您可以使用我們的 Python 範例程式碼來檢查 COCO 檔案的格式。
資料集物件
資料集物件是由影像分析服務所儲存的資料結構,會參考關聯檔案。 您必須先建立資料集物件才能建立和定型模型。
模型物件
模型物件是影像分析服務所儲存的資料結構,代表自訂模型。 其必須與資料集相關聯才能進行初始定型。 定型之後,您可以在分析影像 API 呼叫的 model-name 查詢參數中輸入模型的名稱來查詢模型。
配額限制
下表說明自訂模型專案的規模限制。
| 類別 | 泛型影像分類器 | 泛型物件偵測器 |
|---|---|---|
| 最大定型時數 | 288 (12 天) | 288 (12 天) |
| 最大定型影像數 | 1,000,000 | 200,000 |
| 最大評估影像數 | 100,000 | 100,000 |
| 最小每個類別的定型影像數 | 2 | 2 |
| 最大每個影像的標籤數 | 1 | N/A |
| 每個影像的最大區域數 | N/A | 1,000 |
| 最大類別數 | 2,500 | 1,000 |
| 最小類別數 | 2 | 1 |
| 最大影像大小 (定型) | 20 MB | 20 MB |
| 最大影像大小 (預測) | 同步處理:6 MB、批次:20 MB | 同步處理:6 MB、批次:20 MB |
| 最大影像寬度/高度 (定型) | 10,240 | 10,240 |
| 最小影像寬度/高度 (預測) | 50 | 50 |
| 可用區域 | 美國西部 2、美國東部、西歐 | 美國西部 2、美國東部、西歐 |
| 接受的影像類型 | jpg、png、bmp、gif、jpeg | jpg、png、bmp、gif、jpeg |
常見問題集
為什麼從 Blob 儲存體匯入時,我的 COCO 檔案匯入失敗?
目前,Microsoft 正在解決在 Vision Studio 中起始時,導致 COCO 檔案匯入因大型資料集而失敗的問題。 若要使用大型資料集來訓練,建議您改用 REST API。
為什麼定型需要的時間比我指定的預算更長/更短?
指定的定型預算是校正的計算時間,而不是時鐘時間。 一些差異的常見原因列出如下:
超過指定的預算:
- 影像分析遇到高定型流量,而 GPU 資源可能吃緊。 您的作業可能會在佇列中等候,或在定型期間保留。
- 後端定型程序發生非預期的失敗,導致重試邏輯。 失敗的執行不會耗用您的預算,但這可能會導致定型時間通常較長。
- 您的資料會儲存在與您視覺資源不同的區域中,這會導致資料傳輸時間更長。
比指定的預算更短:下列因素可加速定型,但代價是在特定時鐘時間內使用更多預算。
- 影像分析有時會根據您的資料使用多個 GPU 進行定型。
- 影像分析有時會同時在多個 GPU 上定型多個探索試驗。
- 影像分析有時會使用頂級 (更快) GPU SKU 來定型。
為什麼我的定型失敗,以及我應該怎麼做?
以下是定型失敗的一些常見原因:
diverged:定型無法從您的資料學習有意義的內容。 一些常見的原因如下:- 資料不足:提供更多資料應該會有所幫助。
- 資料品質不佳:檢查您的影像是否為低解析度、極端外觀比例,或註釋是否錯誤。
notEnoughBudget:您指定的預算不足以容納您要定型的資料集和模型類型大小。 指定較大的預算。datasetCorrupt:這通常表示您提供的影像無法存取,或註釋檔案的格式不正確。datasetNotFound:找不到資料集unknown:這可能是後端問題。 請連絡支援以進行調查。
哪些計量可用來評估模型?
使用的計量如下:
- 影像分類:平均精確度、最高精確度、精確度前 5 名
- 物件偵測:平均值平均精確度 @ 30,平均值平均精確度 @ 50,平均值平均精確度 @ 75
為什麼我的資料集註冊失敗?
API 回應應該有足夠的資訊。 畫面如下:
DatasetAlreadyExists;已有同名的資料集DatasetInvalidAnnotationUri:「在資料集註冊期間,註釋 URI 中提供了無效 URI。
合理/良好/最佳模型品質需要多少影像?
儘管 Florence 模型具有絕佳的少樣本功能 (在有限的資料可用性下達成優異的模型效能),但一般而言更多的資料可讓定型的模型變得更好且更可靠。 某些案例只需少量資料 (例如分類蘋果與香蕉),但其他案例則需要更多資料 (例如在雨林中偵測 200 種昆蟲)。 因此很難提供單一建議。
如果您的資料標記預算受到限制,我們建議的工作流程是重複下列步驟:
針對每個類別收集
N個影像,其中您可以輕鬆收集N個影像 (例如N=3個)定型模型,並在您的評估集上進行測試。
如果模型效能為:
- 夠好 (效能優於預期或效能接近您先前的實驗,且收集的資料較少):請在這裡停止並使用此模型。
- 不佳 (效能仍低於預期或優於先前的實驗,且以合理邊界收集較少的資料):
- 針對每個類別收集更多影像,一個您可以輕鬆收集到的數字,然後返回步驟 2。
- 如果您注意到效能不會在幾次反覆項目之後進一步改善,則可能是因為:
- 此問題未妥善定義或太困難。 請與我們連絡以進行個案分析。
- 定型資料的品質可能很低:檢查是否有錯誤的註釋或像素非常低的影像。
我應該指定多少定型預算?
您應該指定願意耗用的預算上限。 影像分析會在其後端使用 AutoML 系統來試用不同的模型並定型配方,以找出最適合您使用案例的模型。 指定的預算愈多,找到更好模型的機會就愈高。
如果 AutoML 系統認為不需要再試一次,則也會自動停止,即使仍有剩餘的預算也一樣。 因此,其不一定會耗盡您指定的預算。 您保證不需要支付超過指定預算的費用。
我可以在定型中控制超參數或使用自己的模型嗎?
否,影像分析模型自訂服務會使用低程式碼 AutoML 定型系統,以處理後端中的超參數搜尋和基底模型選取。
我可以在定型之後匯出模型嗎?
預測 API 僅透過雲端服務受到支援。
為什麼我的物件偵測模型評估失敗?
可能的原因如下:
internalServerError:發生未知的錯誤。 請稍後再試一次。modelNotFound:找不到指定的模型。datasetNotFound:找不到指定的資料集。datasetAnnotationsInvalid:嘗試下載或剖析與測試資料集相關聯的基礎事實註釋時發生錯誤。datasetEmpty:測試資料集未包含任何「基礎事實」註釋。
使用自訂模型之預測的預期延遲為何?
我們不建議您將自訂模型用於業務關鍵環境,因為潛在的高延遲。 當客戶在 Vision Studio 中定型自訂模型時,這些自訂模型屬於其定型來源的 Azure AI 視覺資源,且客戶可以使用分析影像 API 呼叫這些模型。 當其進行這些呼叫時,自訂模型會載入記憶體中,並初始化預測基礎結構。 發生此情況時,客戶在接收預測結果時可能會遇到高於預期的延遲。
資料隱私權和安全性
如同所有 Azure AI 服務,使用影像分析模型自訂的開發人員應該了解 Microsoft 對客戶資料的原則。 請參閱 Microsoft 信任中心上的 Azure AI 服務頁面以深入了解。