建立自訂影像分析模型 (預覽)
影像分析 4.0 可讓您使用自己的訓練影像來訓練自訂模型。 藉由手動標記影像,您可以訓練模型,將自訂標籤套用至影像 (影像分類) 或偵測自訂物件 (物件偵測)。 影像分析 4.0 模型在小樣本學習時特別有效,因此您可以使用較少的訓練資料取得精確的模型。
本指南說明如何建立及訓練自訂影像分類模型。 並指出訓練影像分類模型和物件偵測模型之間的差異。
必要條件
- Azure 訂用帳戶 - 建立免費帳戶
- 擁有 Azure 訂用帳戶之後,在 Azure 入口網站中建立視覺資源,以取得您的金鑰和端點。 如果您使用 Vision Studio 遵循本指南,則必須在美國東部區域建立資源。 在其部署後,選取 [前往資源]。 將金鑰和端點複製到暫存位置,以便稍後使用。
- Azure 儲存體資源 - 建立一個
- 用於定型分類模型的一組影像。 您可以使用 GitHub 上的範例影像集合。 您也可以使用自己的影像。 每個類別只需要大約 3-5 個影像。
注意
我們不建議您將自訂模型用於業務關鍵環境,因為潛在的高延遲。 當客戶在 Vision Studio 中訓練自訂模型時,這些自訂模型屬於其訓練來源的視覺資源,且客戶可以使用分析影像 API 呼叫這些模型。 當其進行這些呼叫時,自訂模型會載入記憶體中,並初始化預測基礎結構。 發生此情況時,客戶在接收預測結果時可能會遇到高於預期的延遲。
建立新的自訂模型
首先移至 Vision Studio,然後選取 [影像分析] 索引標籤。然後選取 [自訂模型] 圖格。
![[自訂] 模型圖格的螢幕擷取畫面。](../media/customization/customization-tile.png)
然後,使用您的 Azure 帳戶登入,並選取您的視覺資源。 如果您沒有帳戶,可以在此畫面免費建立一個。
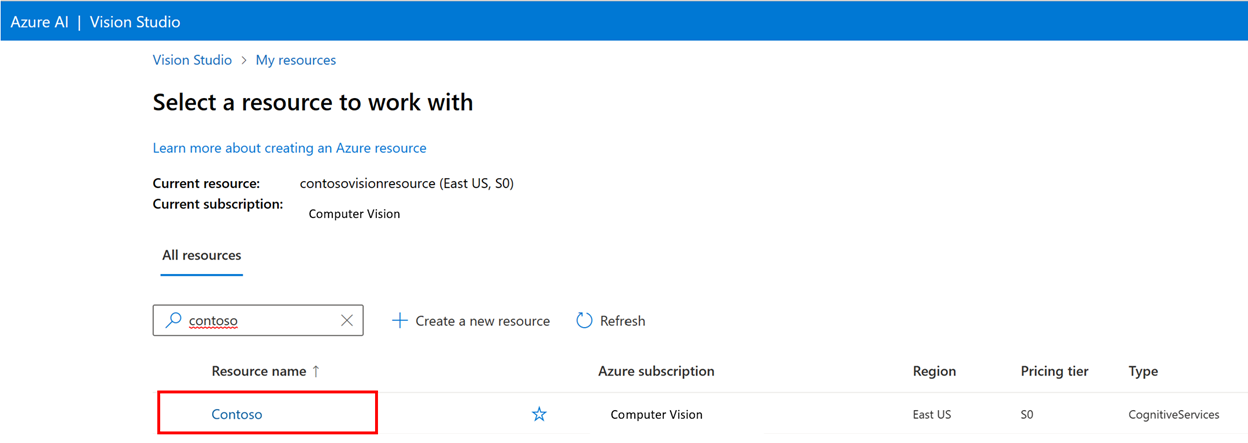
準備訓練影像
您必須將訓練影像上傳至 Azure Blob 儲存體容器。 移至 Azure 入口網站中的儲存體資源,然後瀏覽至 [儲存體瀏覽器] 索引標籤。您可以在這裡建立 Blob 容器並上傳您的影像。 將影像全部放在容器的根目錄。
新增資料集
若要訓練自訂模型,您必須將它與 資料集 產生關聯,您可以在其中提供影像及其標籤資訊作為訓練資料。 在 Vision Studio 中,選取 [資料集] 索引標籤以檢視您的資料集。
若要建立新的資料集,請選取 [新增資料集]。 在彈出視窗中,輸入名稱,然後為您的使用案例選取資料集類型。 影像分類模型會將內容標籤套用至整個影像,而物件偵測模型會將物件標籤套用至影像中的特定位置。 產品辨識模型是針對偵測零售產品最佳化的物件偵測模型的子類別。
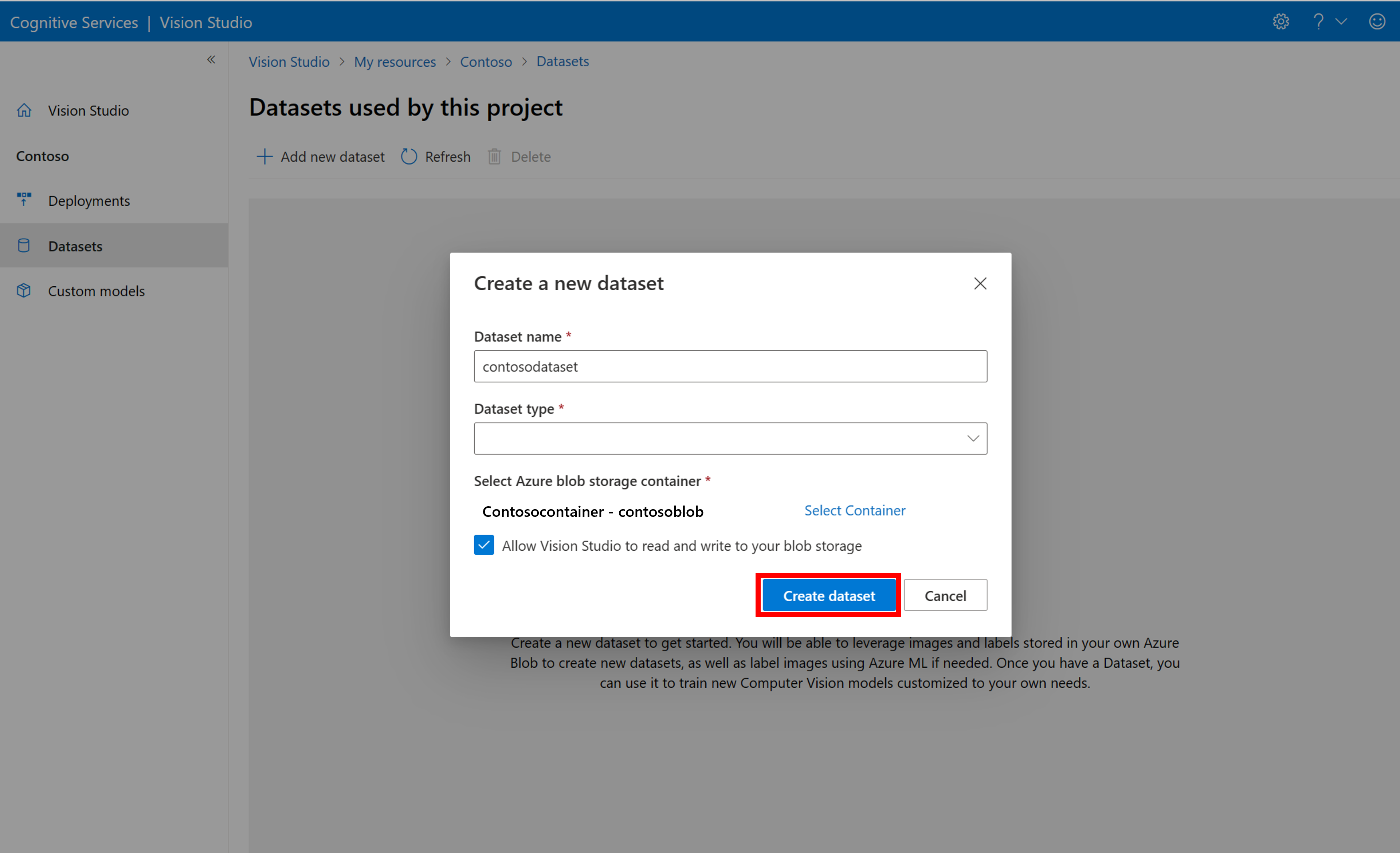
然後,從您儲存訓練影像的 Azure Blob 儲存體帳戶中選取容器。 勾選核取方塊,以允許 Vision Studio 讀取及寫入 Blob 儲存體容器。 這是匯入已標記資料的必要步驟。 建立資料集。
建立 Azure Machine Learning 標記專案
您需要 COCO 檔案來傳達標記資訊。 產生 COCO 檔案的簡單方式是建立 Azure Machine Learning 專案,其中包含資料標記工作流程。
在資料集詳細資料頁面中,選取 [新增資料標記專案]。 為其命名,並選取 [建立新的工作區]。 這會開啟新的 Azure 入口網站索引標籤,您可以在其中建立 Azure Machine Learning 專案。
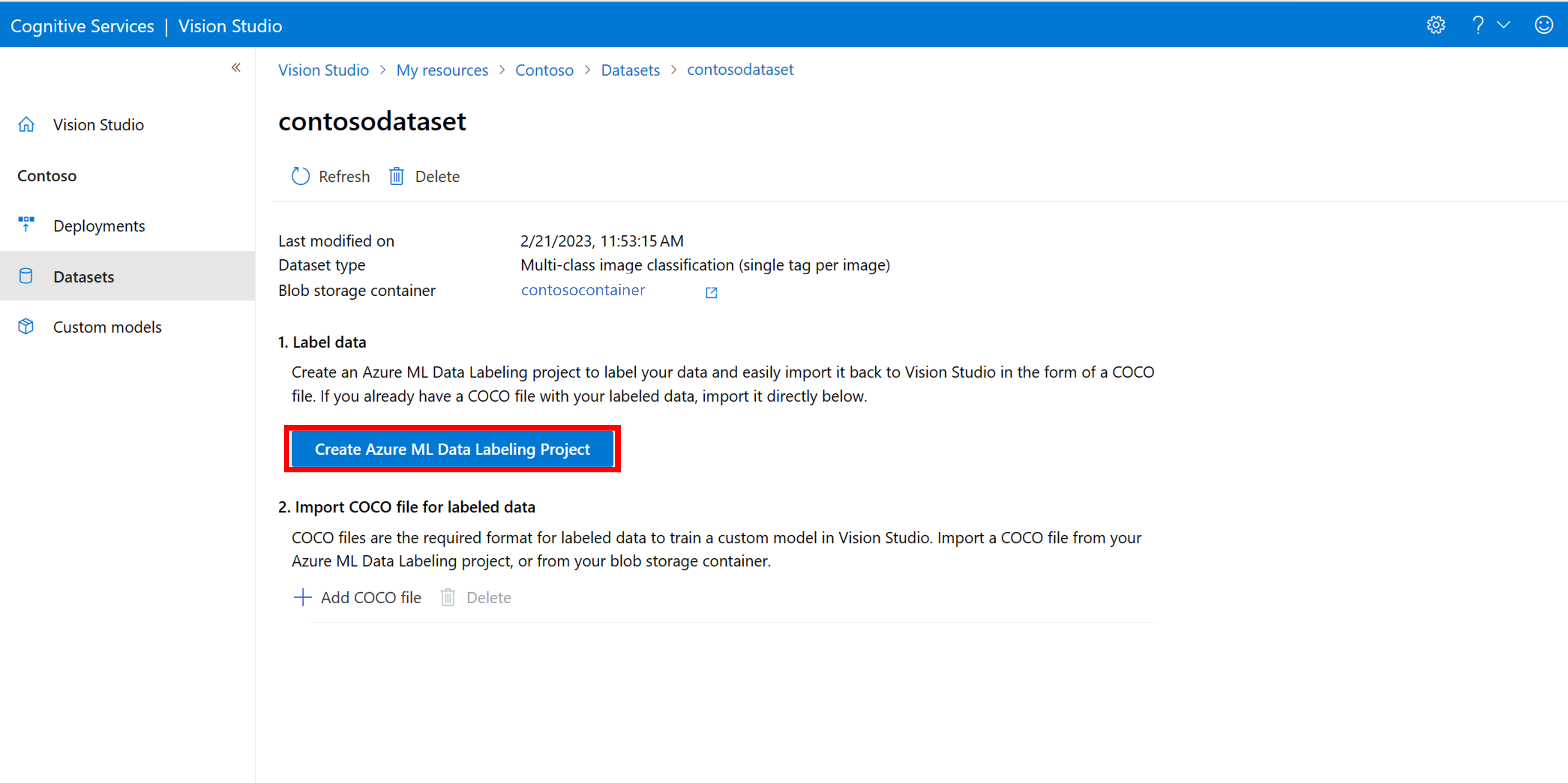
建立 Azure Machine Learning 專案之後,返回 [Vision Studio] 索引標籤,然後在 [工作區] 底下選取專案。 Azure Machine Learning 入口網站接著會在新的瀏覽器索引標籤中開啟。
Azure Machine Learning:建立標籤
若要開始標記,請遵循 [請新增標籤類別] 提示來新增標籤類別。
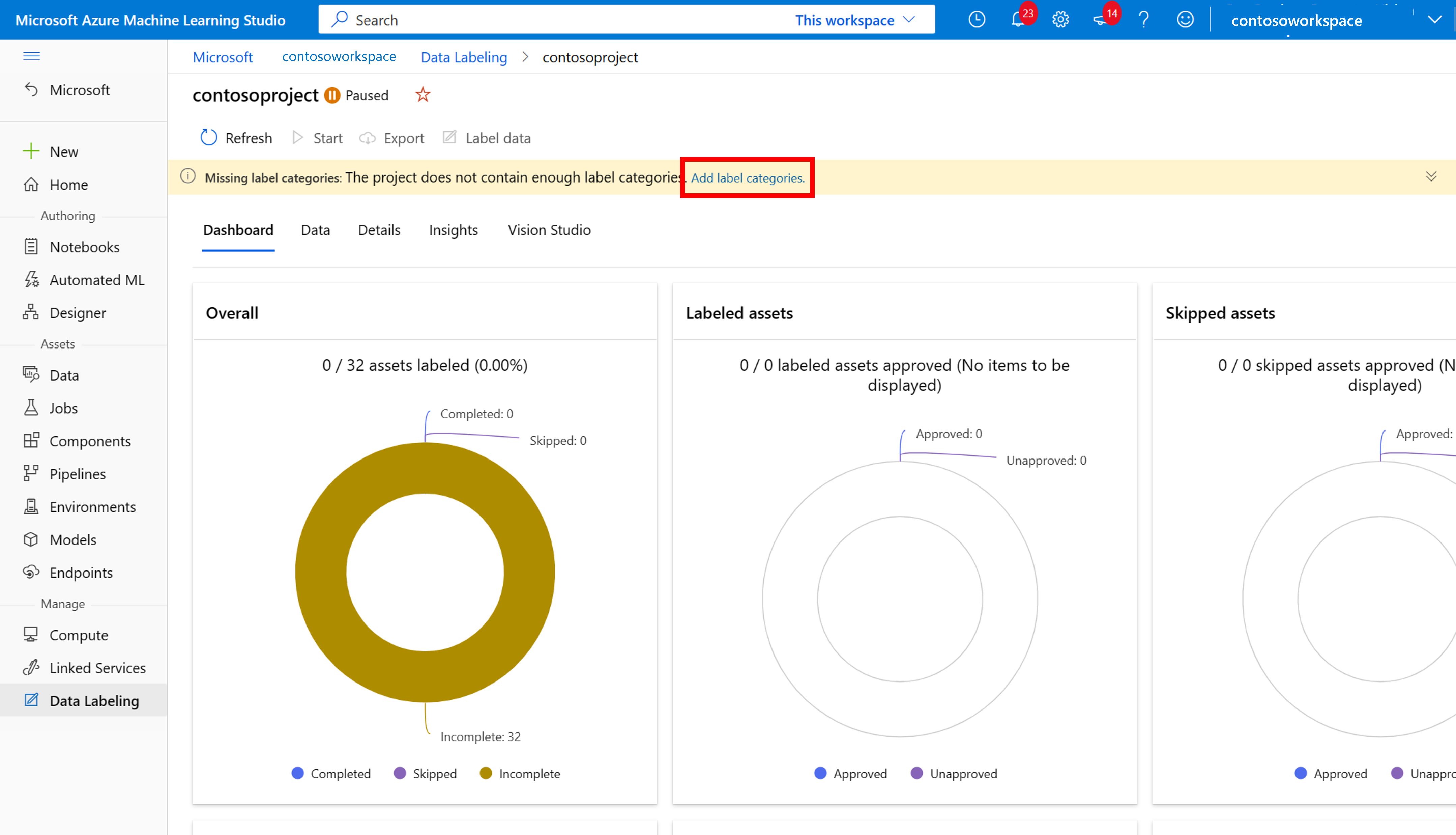
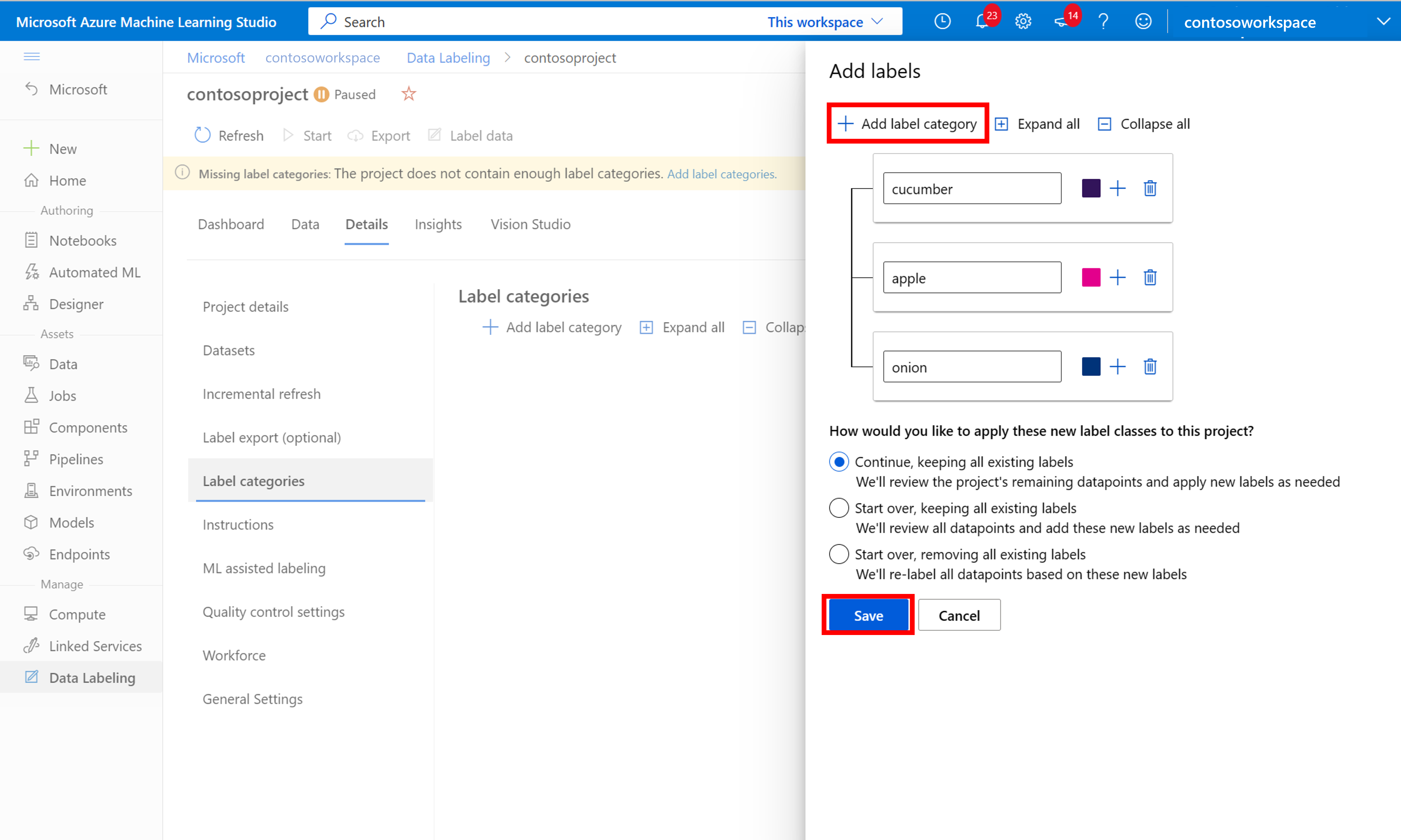
新增所有類別標籤後,請加以儲存,然後選取專案上的 [開始],然後選取頂端的 [標籤資料]。
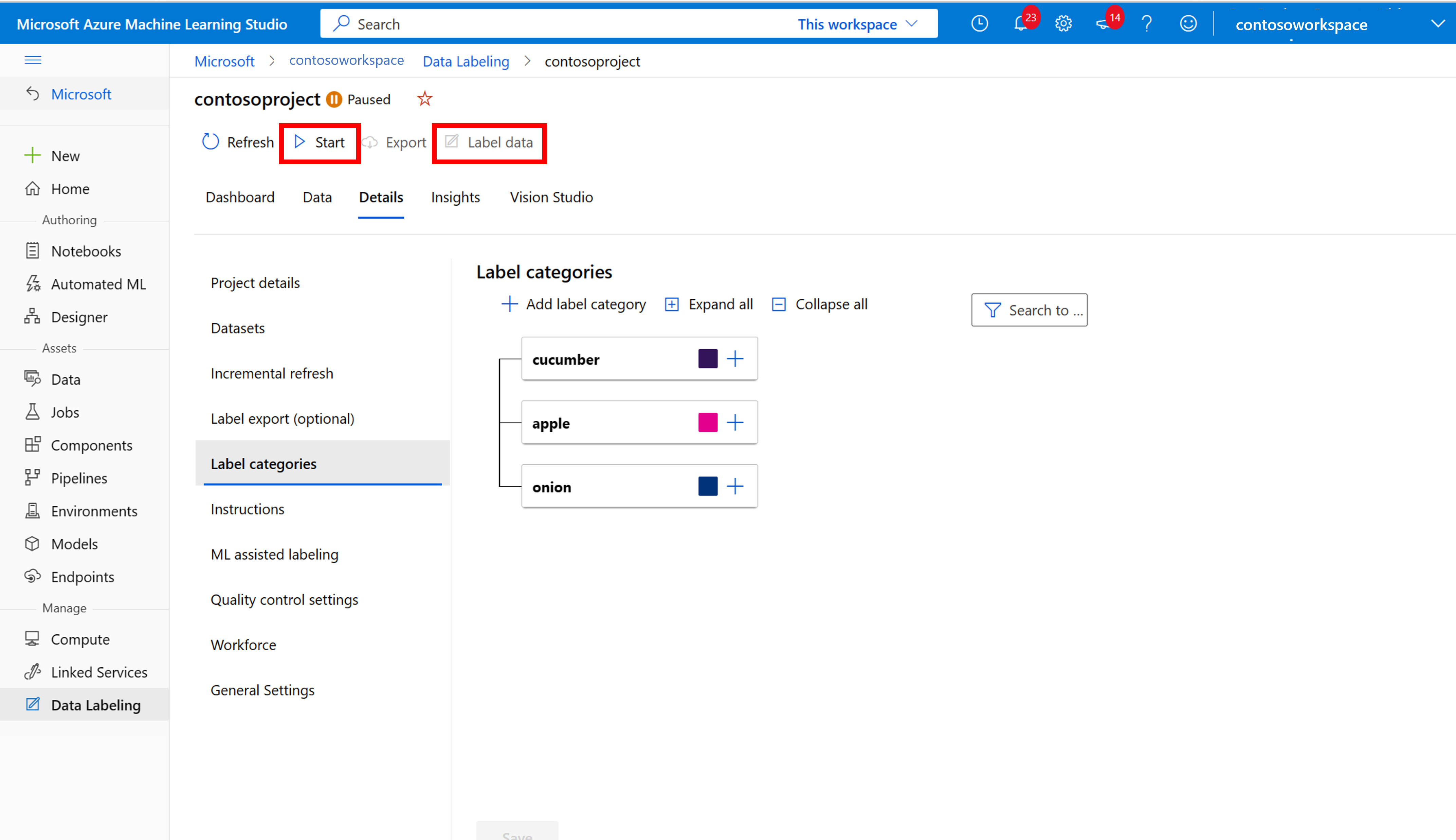
Azure Machine Learning:手動標記訓練資料
選擇 [開始標記],然後遵循提示來標記所有影像。 完成時,請返回瀏覽器中的 [Vision Studio] 索引標籤。
現在選取 [新增 COCO 檔案],然後選取 [從 Azure ML 資料標記專案匯入 COCO 檔案]。 這會從 Azure Machine Learning 匯入標記資料。
您剛才建立的 COCO 檔案現在會儲存在連結至此專案的 Azure 儲存體容器中。 您現在可以將其匯入模型自訂工作流程。 從下拉式清單中加以選取。 將 COCO 檔案匯入資料集之後,資料集就可以用於訓練模型。
注意
從其他地方匯入 COCO 檔案
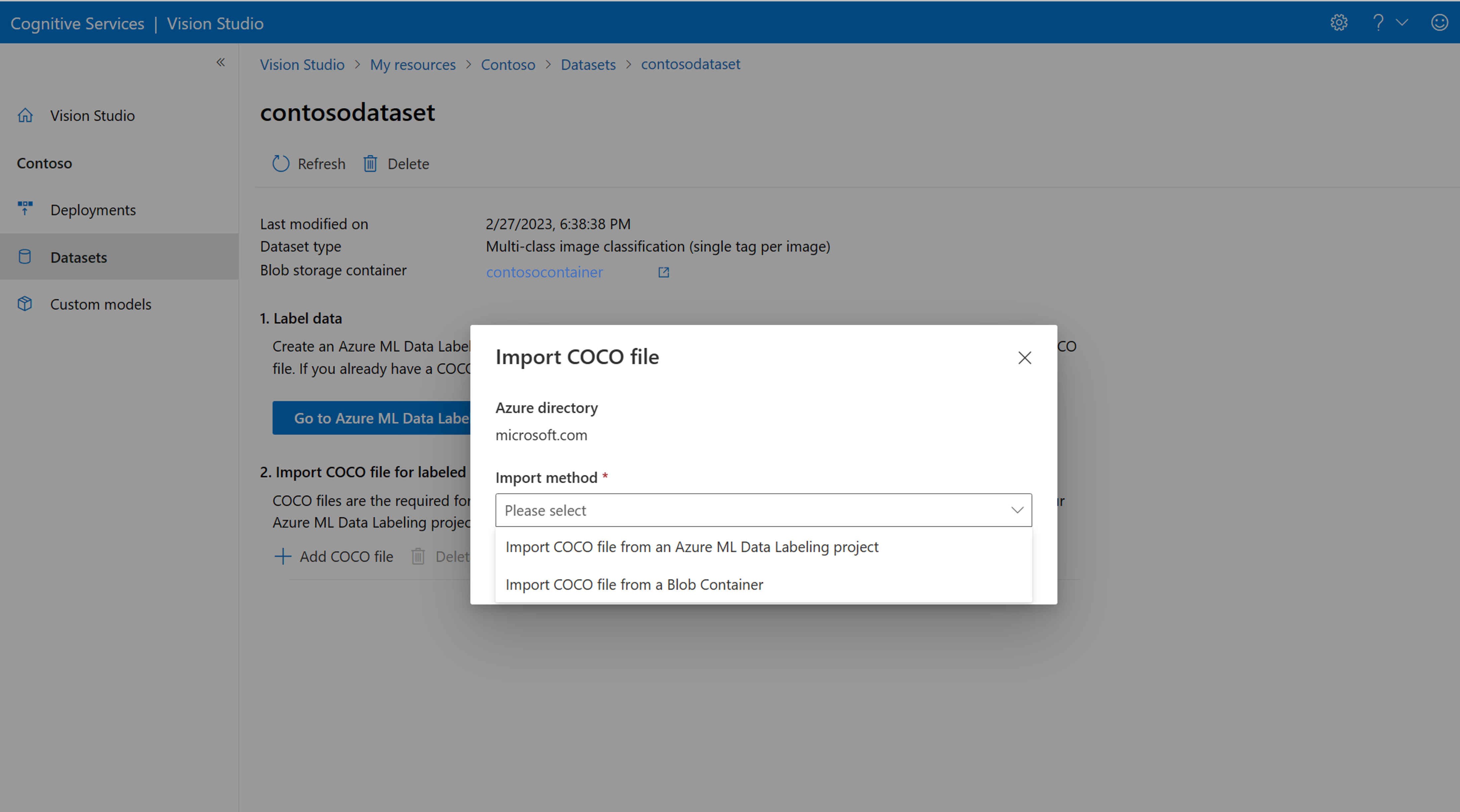
如果您有想要匯入的現成 COCO 檔案,請移至 [資料集] 索引標籤,然後選取 Add COCO files to this dataset。 您可以選擇從 Blob 儲存體帳戶新增特定的 COCO 檔案,或從 Azure Machine Learning 標記專案匯入。
目前,Microsoft 正在解決在 Vision Studio 中起始時,導致 COCO 檔案匯入因大型資料集而失敗的問題。 若要使用大型資料集來訓練,建議您改用 REST API。
關於 COCO 檔案
COCO 檔案是具有特定必要欄位的 JSON 檔案:"images"、"annotations" 和 "categories"。 範例 COCO 檔案看起來會像這樣:
{
"images": [
{
"id": 1,
"width": 500,
"height": 828,
"file_name": "0.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/0.jpg"
},
{
"id": 2,
"width": 754,
"height": 832,
"file_name": "1.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/1.jpg"
},
...
],
"annotations": [
{
"id": 1,
"category_id": 7,
"image_id": 1,
"area": 0.407,
"bbox": [
0.02663142641129032,
0.40691584277841153,
0.9524163571731749,
0.42766634515266866
]
},
{
"id": 2,
"category_id": 9,
"image_id": 2,
"area": 0.27,
"bbox": [
0.11803319477782331,
0.41586723392402375,
0.7765206955096307,
0.3483334397217212
]
},
...
],
"categories": [
{
"id": 1,
"name": "vegall original mixed vegetables"
},
{
"id": 2,
"name": "Amy's organic soups lentil vegetable"
},
{
"id": 3,
"name": "Arrowhead 8oz"
},
...
]
}
COCO 檔案欄位參考
如果您要從頭開始產生自己的 COCO 檔案,請確定所有必要的欄位都已填入正確的詳細資料。 下表描述 COCO 檔案中的每個欄位:
"images"
| 機碼 | 類型 | 描述 | 是必要的嗎? |
|---|---|---|---|
id |
整數 | 唯一影像識別碼,從 1 開始 | Yes |
width |
整數 | 以像素為單位的影像寬度 | Yes |
height |
整數 | 以像素為單位的影像高度 | Yes |
file_name |
string | 影像的唯一名稱 | Yes |
absolute_url 或 coco_url |
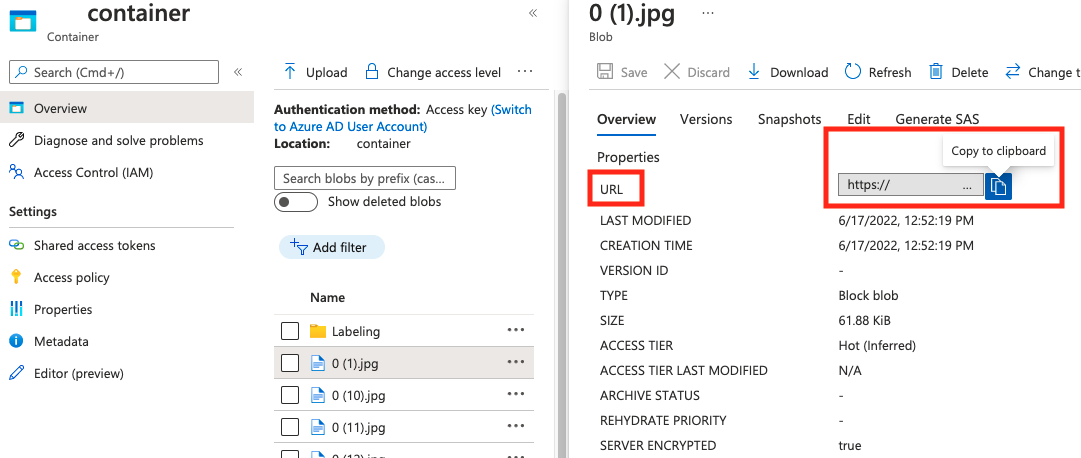
string | 作為 Blob 容器中 Blob 絕對 URI 的影像路徑。 視覺資源必須具有讀取註釋檔案和所有參考影像檔案的權限。 | Yes |
absolute_url 的值可以在 Blob 容器的屬性中找到:
"annotations"
| 機碼 | 類型 | 描述 | 是必要的嗎? |
|---|---|---|---|
id |
整數 | 註釋的識別碼 | Yes |
category_id |
整數 | categories 區段中定義的類別識別碼 |
Yes |
image_id |
整數 | 影像的識別碼 | Yes |
area |
整數 | 'Width' x 'Height' 的值 (bbox 的第三和第四個值) |
No |
bbox |
list[float] | 周框方塊的相對座標 (0 到 1),順序為 'Left'、'Top'、'Width'、'Height' | Yes |
"categories"
| 機碼 | 類型 | 描述 | 是必要的嗎? |
|---|---|---|---|
id |
整數 | 每個類別的唯一識別碼 (標籤類別)。 這些應該會出現在 annotations 區段中。 |
Yes |
name |
string | 類別的名稱 (標籤類別) | Yes |
COCO 檔案驗證
您可以使用我們的 Python 範例程式碼來檢查 COCO 檔案的格式。
訓練自訂模型
若要使用 COCO 檔案開始訓練模型,請移至 [自訂模型] 索引標籤,然後選取 [新增模型]。 輸入模型的名稱,然後選取 Image classification 或 Object detection 作為模型類型。
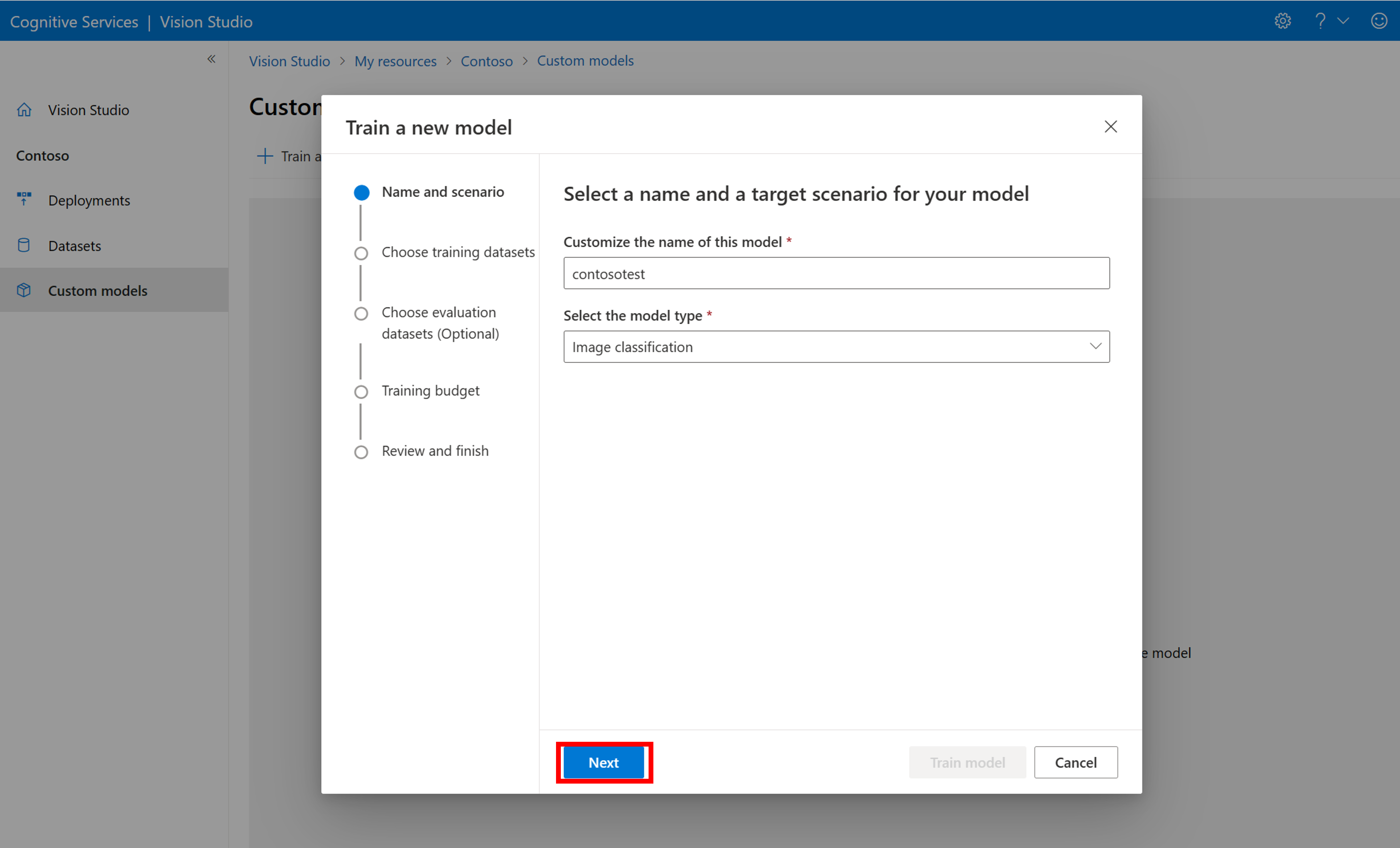
選取您的資料集,其現在與包含標記資訊的 COCO 檔案相關聯。
然後選取時間預算並訓練模型。 針對小型範例,您可以使用 1 hour 預算。
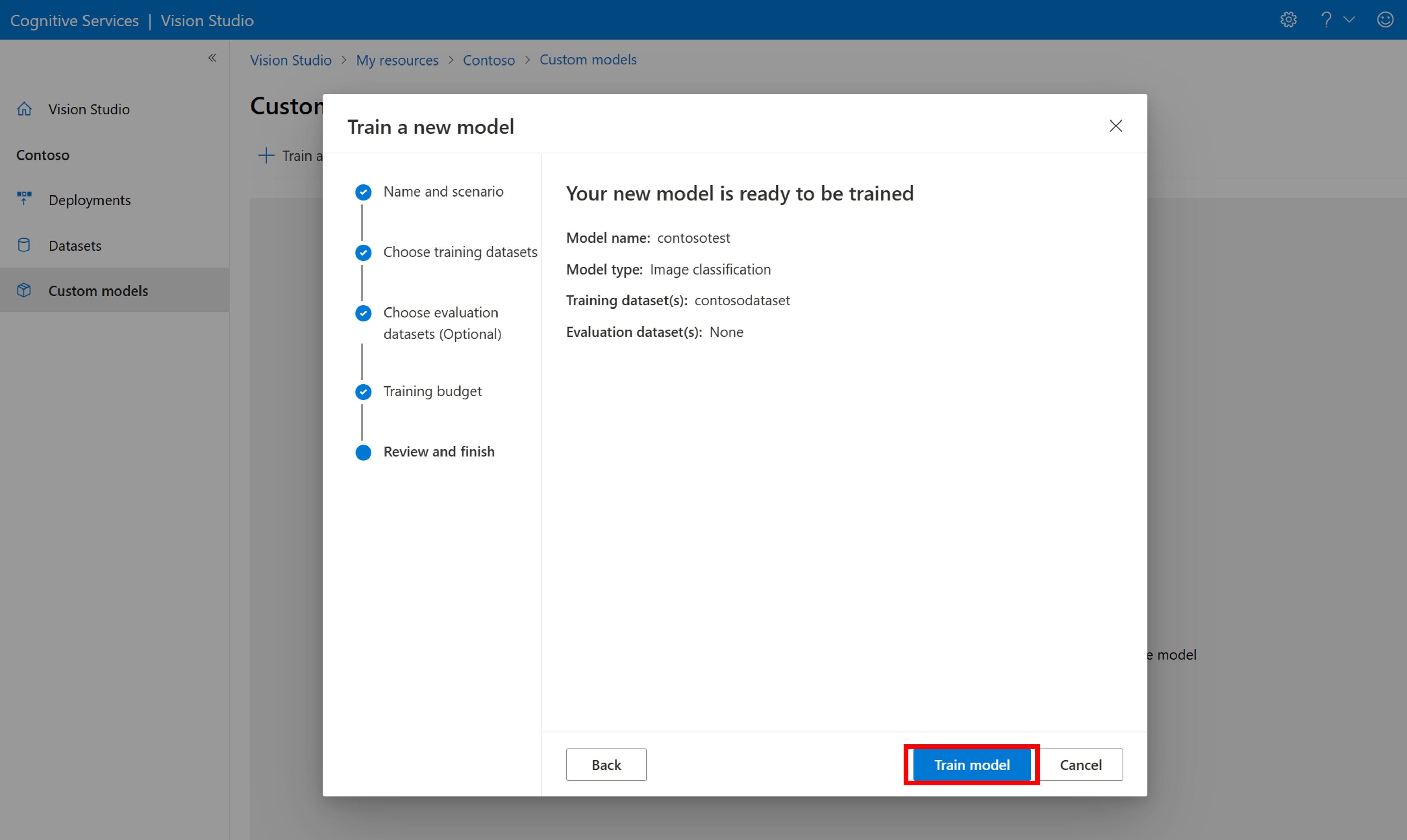
訓練需要一些時間來完成。 影像分析 4.0 模型只需使用一組少量的訓練資料即可保持精確,但訓練時間比先前的模型要長。
評估訓練的模型
訓練完成後,您可以檢視模型的效能評估。 使用的計量如下:
- 影像分類:平均精確度、最高精確度、精確度前 5 名
- 物件偵測:平均值平均精確度 @ 30,平均值平均精確度 @ 50,平均值平均精確度 @ 75
如果在訓練模型時未提供評估集,則會根據訓練集的一部分來估計報告的效能。 我們強烈建議您使用評估資料集 (使用與上述相同的流程) 來可靠地估計模型效能。
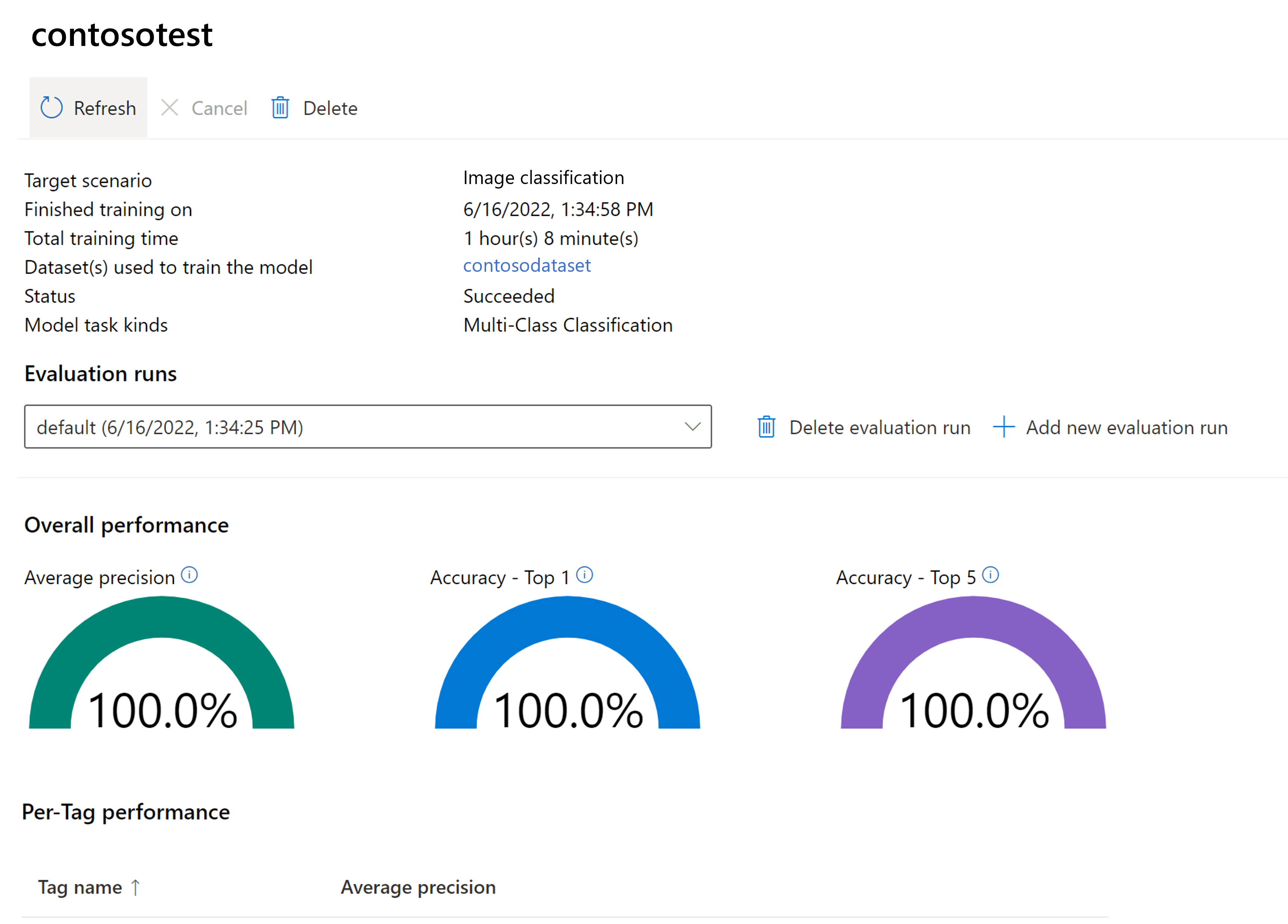
在 Vision Studio 中測試自訂模型
建置自訂模型後,您可以選取模型評估畫面上的 [試做] 按鈕進行測試。
![模型評估畫面的螢幕擷取畫面,其中包括 [試做] 按鈕。](../media/customization/custom-try-it-out.png)
這會帶您前往 [從影像擷取一般標籤] 頁面。 從下拉式功能表中選擇您的自訂模型,並上傳測試影像。
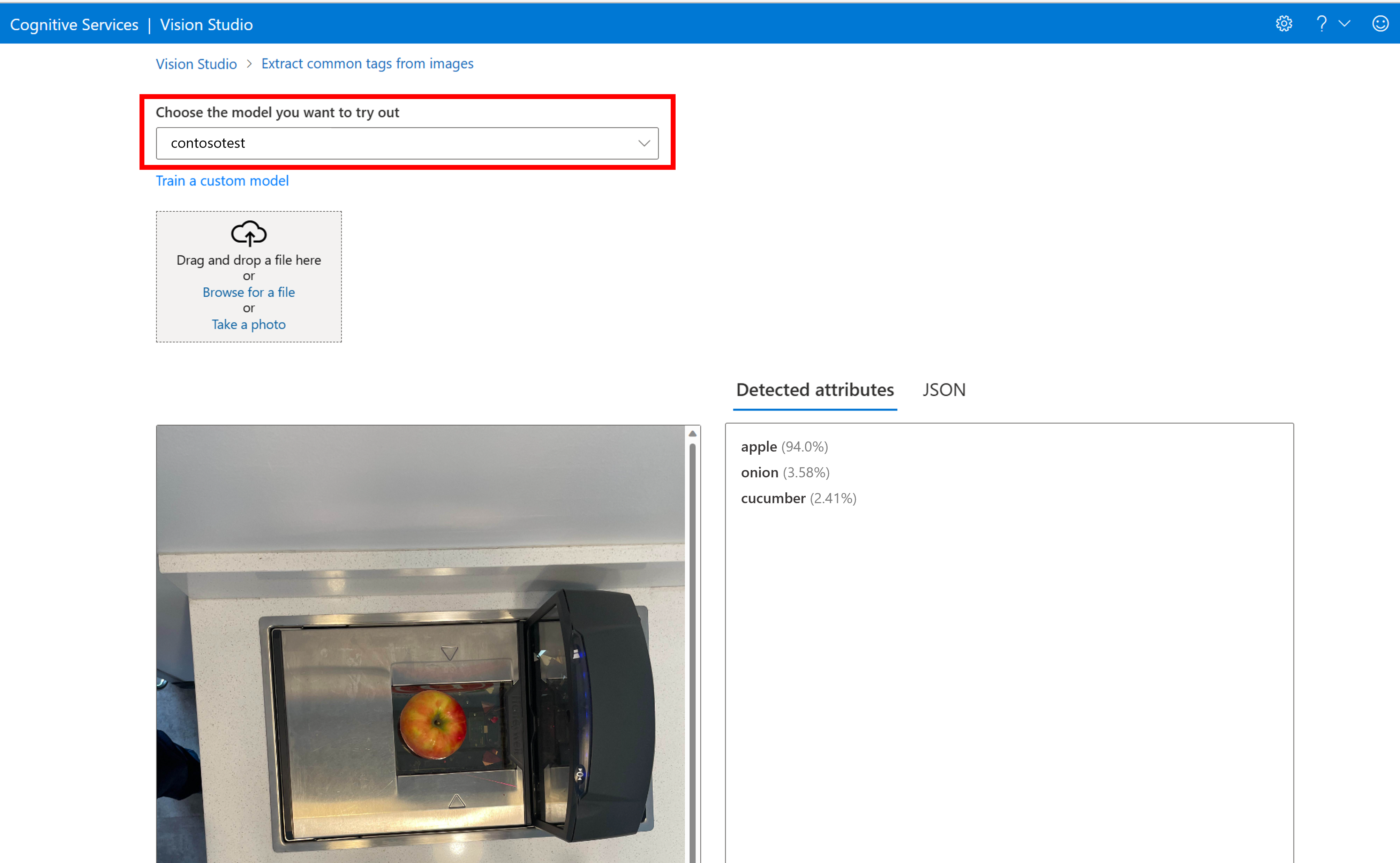
預測結果會出現在右欄中。
下一步
在本指南中,您已使用影像分析建立及訓練自訂影像分類模型。 接下來,深入了解分析影像 4.0 API,以便使用 REST 或程式庫 SDK 從應用程式呼叫自訂模型。
- 如需這項功能的廣泛概觀和常見問題清單,請參閱模型自訂概念指南。
- 呼叫分析影像 API。