Azure Kubernetes Service (AKS) 的部署和叢集可靠性最佳做法
本文提供針對 Azure Kubernetes Service (AKS) 工作負載在部署和叢集層級實作的叢集可靠性最佳做法。 本文適用於負責在 AKS 中部署及管理應用程式的叢集操作員和開發人員。
本文中的最佳做法會組織成下列類別:
| 類別 | 最佳作法 |
|---|---|
| 部署層級最佳做法 | • 中斷預算 (PDB) • Pod CPU 和記憶體限制 • 預先停止勾點 • maxUnavailable • Pod 拓撲散佈條件約束 • 整備度、活躍度和啟動探查 • 多複本應用程式 |
| 叢集和節點集區層級最佳做法 | • 可用性區域 • 叢集自動調整 • Standard Load Balancer • 系統節點集區 • 加速網路 • 映像版本 • 適用於動態 IP 配置的 Azure CNI • v5 SKU VM • 請勿使用 B 系列 VM • 進階磁碟 • 容器深入解析 • Azure 原則 |
部署層級最佳做法
下列部署層級最佳做法可協助確保 AKS 工作負載的高可用性和可靠性。 這些最佳做法是在 POD 和部署的 YAML 檔案中實作的本機設定。
注意
請務必在每次將更新部署至應用程式時實作這些最佳做法。 若未如此,您可能會遇到應用程式可用性和可靠性的問題,例如非預期的應用程式停機。
Pod 中斷預算 (PDB)
最佳做法指導
使用 Pod 中斷預算 (PDB) 以確保在自願中斷期間,仍可使用最少的 Pod 數目,例如升級作業或意外刪除 Pod。
Pod 中斷預算 (PDB) 可讓您定義部署或複本集在自願中斷期間的回應方式,例如升級作業或意外刪除 Pod。 您可以使用 PDB 來定義最少或最大無法使用的資源計數。 PDB 只會影響收回 API 進行自願中斷。
例如,假設您需要執行叢集升級,並已定義 PDB。 在執行叢集升級之前,Kubernetes 排程器可確保 PDB 中定義的 Pod 數目最小值可供使用。 如果升級會導致可用的 Pod 數目低於 PDB 中定義的最小值,排程器就會先排程其他節點上的額外 Pod 後,再讓升級繼續進行。 如果您未設定 PDB,則排程器不會對升級期間無法使用的 Pod 數目有任何限制,這可能會導致資源不足且可能發生叢集中斷。
在下列範例 PDB 定義檔案中,minAvailable 欄位會設定在自願中斷期間必須維持可用的最低 Pod 數目。 此值可能為絕對數字 (例如 3) 或所需 Pod 數目的百分比 (例如 10%)。
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: mypdb
spec:
minAvailable: 3 # Minimum number of pods that must remain available during voluntary disruptions
selector:
matchLabels:
app: myapp
如需詳細資訊,請參閱使用 PDB 規劃可用性,以及指定應用程式的中斷預算 (英文)。
Pod CPU 和記憶體限制
最佳做法指導
設定所有 Pod 的 Pod CPU 和記憶體限制,以確保 Pod 不會耗用節點上的所有資源,並在服務威脅 (例如 DDoS 攻擊) 期間提供保護。
Pod CPU 和記憶體限制會定義 Pod 可使用的最大 CPU 和記憶體數量。 當 Pod 超過其定義的限制時,會標示為移除。 如需詳細資訊,請參閱 Kubernetes 中的 CPU 資源單位 (英文) 和 Kubernetes 中的記憶體資源單位 (英文)。
設定 CPU 和記憶體限制可協助您維護節點健康情況,並將對節點上其他 Pod 的影響降到最低。 避免設定的 Pod 限制高於節點所能支援的容量。 每個 AKS 節點都會保留一定數量的 CPU 和記憶體供核心 Kubernetes 元件使用。 如果您設定了高於節點可支援的 Pod 限制,您的應用程式可能會嘗試耗用過多資源,並在節點上對其他 Pod 造成負面影響。 叢集管理員必須在命名空間上設定資源配額,以要求設定資源要求和限制。 如需詳細資訊,請參閱在 AKS 中實施資源配額。
在下列範例 Pod 定義檔案中,resources 區段會設定 Pod 的 CPU 和記憶體限制:
kind: Pod
apiVersion: v1
metadata:
name: mypod
spec:
containers:
- name: mypod
image: mcr.microsoft.com/oss/nginx/nginx:1.15.5-alpine
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 250m
memory: 256Mi
提示
您可以使用 kubectl describe node 命令來檢視節點的 CPU 和記憶體容量,如下列範例中所示:
kubectl describe node <node-name>
# Example output
Capacity:
cpu: 8
ephemeral-storage: 129886128Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 32863116Ki
pods: 110
Allocatable:
cpu: 7820m
ephemeral-storage: 119703055367
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 28362636Ki
pods: 110
如需詳細資訊,請參閱將 CPU 資源指派給容器和 Pod (英文),以及將記憶體資源指派給容器和 Pod (英文)。
預先停止勾點
最佳做法指導
適用時,請使用預先停止勾點來確保容器正常終止。
在容器因 API 要求或管理事件而終止之前,會立即呼叫 PreStop 勾點,例如先佔、資源爭用或活躍度/啟動探查失敗。 如果容器已處於終止或完成狀態,且勾點必須在傳送停止容器的 TERM 訊號之前完成,則對 PreStop 勾點的呼叫會失敗。 Pod 的終止寬限期倒數會在 PreStop 勾點執行之前開始,因此容器最終會在終止寬限期內終止。
下列範例 Pod 定義檔示範如何使用 PreStop 勾點來確保容器的正常終止:
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-demo
spec:
containers:
- name: lifecycle-demo-container
image: nginx
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/message"]
preStop:
exec:
command: ["/bin/sh","-c","nginx -s quit; while killall -0 nginx; do sleep 1; done"]
如需詳細資訊,請參閱容器生命週期勾點 (英文) 和 Pod 終止 (英文)。
maxUnavailable
最佳做法指導
使用部署中的
maxUnavailable欄位,定義在輪流更新期間可能無法使用的 Pod 數目上限,以確保在升級期間仍可使用最少的 Pod 數目。
maxUnavailable 欄位會指定更新程序期間無法使用的 Pod 數目上限。 此值可能為絕對數字 (例如 3) 或所需 Pod 數目的百分比 (例如 10%)。 maxUnavailable 與在輪流更新期間使用的刪除 API 有關。
下列範例部署資訊清單會使用 maxAvailable 欄位來設定更新程序期間無法使用的 Pod 數目上限:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1 # Maximum number of pods that can be unavailable during the upgrade
如需詳細資訊,請參閱無法使用上限 (英文)。
Pod 拓撲散佈條件約束
最佳做法指導
使用 Pod 拓撲散佈條件約束,以確保 Pod 會分散到不同的節點或區域,改善可用性和可靠性。
您可以使用 Pod 拓撲散佈條件約束來控制 Pod 如何根據節點的拓撲散佈到叢集,並將 Pod 散佈到不同的節點或區域,以改善可用性和可靠性。
下列範例 Pod 定義檔示範如何使用 topologySpreadConstraints 欄位,將 Pod 散佈到不同的節點:
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
# Configure a topology spread constraint
topologySpreadConstraints:
- maxSkew: <integer>
minDomains: <integer> # optional
topologyKey: <string>
whenUnsatisfiable: <string>
labelSelector: <object>
matchLabelKeys: <list> # optional
nodeAffinityPolicy: [Honor|Ignore] # optional
nodeTaintsPolicy: [Honor|Ignore] # optional
如需詳細資訊,請參閱 Pod 拓撲散佈條件約束 (英文)。
整備度、活躍度和啟動探查
最佳做法指導
在適用於改善高負載和較低容器重新啟動的復原能力時,設定整備度、活躍度和啟動探查。
整備度探查
在 Kubernetes 中,kubelet 會使用整備度探查來得知容器何時就緒可開始接受流量。 當 Pod 的所有容器都就緒時,Pod 就會被視為就緒。 當 Pod 尚未就緒時,會從服務負載平衡器中移除。 如需詳細資訊,請參閱 Kubernetes 中的整備度探查 (英文)。
下列範例 Pod 定義檔會顯示整備度探查組態:
readinessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
如需詳細資訊,請參閱設定整備度探查。
活躍度探查
在 Kubernetes 中,kubelet 會使用活躍度探查來得知何時重新啟動容器。 如果容器的活躍度探查失敗,則會重新啟動容器。 如需詳細資訊,請參閱 Kubernetes 中的活躍度探查 (英文)。
下列範例 Pod 定義檔會顯示活躍度探查組態:
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
另一種活躍度探查會使用 HTTP GET 要求。 下列範例 Pod 定義檔顯示 HTTP GET 要求活躍度探查組態:
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- name: liveness
image: registry.k8s.io/liveness
args:
- /server
livenessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3
如需詳細資訊,請參閱設定活躍度探查 (英文) 和定義活躍度 HTTP 要求 (英文)。
啟動探查
在 Kubernetes 中,kubelet 會使用啟動探查來得知容器應用程式何時啟動。 當您設定啟動探查時,在啟動探查成功之前,整備度和活躍度探查不會啟動,確保整備度和活躍度探查不會干擾應用程式啟動。 如需詳細資訊,請參閱 Kubernetes 中的啟動探查 (英文)。
下列範例 Pod 定義檔會顯示啟動探查組態:
startupProbe:
httpGet:
path: /healthz
port: 8080
failureThreshold: 30
periodSeconds: 10
多複本應用程式
最佳做法指導
至少部署應用程式的兩個復本,以確保節點關閉案例中的高可用性和復原能力。
在 Kubernetes 中,您可以使用部署中的 replicas 欄位來指定您要執行的 Pod 數目。 執行應用程式的多個執行個體有助於確保節點關閉案例中的高可用性和復原能力。 如果您已啟用可用性區域,可以使用 replicas 欄位來指定您要跨多個可用性區域執行的 Pod 數目。
下列範例 Pod 定義檔示範如何使用 replicas 欄位來指定您要執行的 Pod 數目:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
如需詳細資訊,請參閱 AKS 建議的主動/主動高可用性解決方案概觀和部署規格中的複本 (英文)。
叢集和節點集區層級最佳做法
下列叢集和節點集區層級最佳做法可協助您確保 AKS 叢集的高可用性和可靠性。 您可以在建立或更新 AKS 叢集時,實作這些最佳做法。
可用性區域
最佳做法指導
建立 AKS 叢集時,請使用多個可用性區域,以確保區域關閉案例中的高可用性。 請記住,您在建立叢集之後無法變更可用性區域設定。
可用性區域是區域內資料中心的分隔群組。 這些區域夠接近彼此的低延遲連線,但相距甚遠,以減少多個區域受到本機中斷或天氣影響的可能性。 使用可用性區域可協助您的資料在區域關閉案例中保持同步且可存取。 如需詳細資訊,請參閱在多個區域中執行 (英文)。
叢集自動調整
最佳做法指導
使用叢集自動調整來確保叢集可以處理增加的負載,並在低負載期間降低成本。
為了符合 AKS 中的應用程式需求,您可能需要調整執行工作負載的節點數目。 叢集自動調整程式元件可以監看叢集中由於資源限制而無法調度的 Pod。 叢集自動調整程式偵測到問題時,這會擴大節點集區中的節點數目,以符合應用程式需求。 也會定期檢查節點是否缺少執行的 Pod,然後視需要減少節點的數目。 如需詳細資訊,請參閱 AKS 中的叢集自動調整。
您在建立 AKS 叢集時,可以使用 --enable-cluster-autoscaler 參數來啟用叢集自動調整程式,如下列範例所示:
az aks create \
--resource-group myResourceGroup \
--name myAKSCluster \
--node-count 2 \
--vm-set-type VirtualMachineScaleSets \
--load-balancer-sku standard \
--enable-cluster-autoscaler \
--min-count 1 \
--max-count 3 \
--generate-ssh-keys
您也可以在現有的節點集區上啟用叢集自動調整程式,並變更整個叢集的自動調整程式設定檔的預設值,以此方式設定叢集自動調整程式的細部詳細資料。
如需詳細資訊,請參閱在 AKS 中使用叢集自動調整程式。
標準負載平衡器
最佳做法指導
使用 Standard Load Balancer 來提供更高的可靠性和資源、支援多個可用性區域、HTTP 探查,以及跨多個資料中心的功能。
在 Azure 中,Standard Load Balancer SKU 旨在需要高效能和低延遲時,為網路層流量進行負載平衡。 Standard Load Balancer 可在區域內以及跨區域路由傳送流量,以及將流量路由傳送到可用性區域,以獲得高復原能力。 標準 SKU 是建立 AKS 叢集時建議的預設 SKU。
重要
Basic Load Balancer 將於 2025 年 9 月 30 日淘汰。 如需詳細資訊,請參閱官方公告。 建議您使用 Standard Load Balancer 進行新的部署,並將現有的部署升級至 Standard Load Balancer。 如需詳細資訊,請參閱從基本 Load Balancer 升級。
下列範例顯示使用 Standard Load Balancer 的 LoadBalancer 服務資訊清單:
apiVersion: v1
kind: Service
metadata:
annotations:
service.beta.kubernetes.io/azure-load-balancer-ipv4 # Service annotation for an IPv4 address
name: azure-load-balancer
spec:
type: LoadBalancer
ports:
- port: 80
selector:
app: azure-load-balancer
如需詳細資訊,請參閱在 AKS 中使用標準負載平衡器。
系統節點集區
使用專用的系統節點集區
最佳做法指導
使用系統節點集區來確保其他使用者應用程式不會在相同的節點上執行,這可能會導致資源短缺並影響系統 Pod。
使用專用的系統節點集區來確保其他使用者應用程式不會在同一個節點上執行,這可能會因為競爭狀況而造成資源短缺和潛在的叢集中斷。 若要使用專用的系統節點集區,您可以使用系統節點集區上的 CriticalAddonsOnly 污點。 如需詳細資訊,請參閱在 AKS 中使用系統節點集區。
系統節點集區自動調整
最佳做法指導
設定系統節點集區的自動調整程式,以設定節點集區的最小和最大調整限制。
使用節點集區上的自動調整程式來設定節點集區的最小和最大調整限制。 系統節點集區應該一律能夠調整以符合系統 Pod 的需求。 如果系統節點集區無法調整,叢集就會用盡資源,以協助管理排程、調整和負載平衡,這可能會導致叢集沒有回應。
如需詳細資訊,請參閱在節點集區上使用叢集自動縮放程式。
每個系統節點集區至少有三個節點
最佳做法指導
確定系統節點集區至少有三個節點,以確保針對凍結/升級案例的復原能力,這可能會導致節點重新啟動或關閉。
系統節點集區可用來執行系統 Pod,例如 kube-proxy、coredns 和 Azure CNI 外掛程式。 建議您確定系統節點集區至少有三個節點,以確保針對凍結/升級案例的復原能力,這可能會導致節點重新啟動或關閉。 如需詳細資訊,請參閱在 AKS 中管理系統節點集區。
加速網路
最佳做法指導
使用加速網路來提供較低延遲、降低抖動,以及減少 VM 上的 CPU 使用率。
加速網路可在支援的 VM 類型上啟用單一根目錄 I/O 虛擬化 (SR-IOV),大幅改善網路效能。
下圖說明兩個 VM 如何在有與沒有加速網路的情況下通訊:
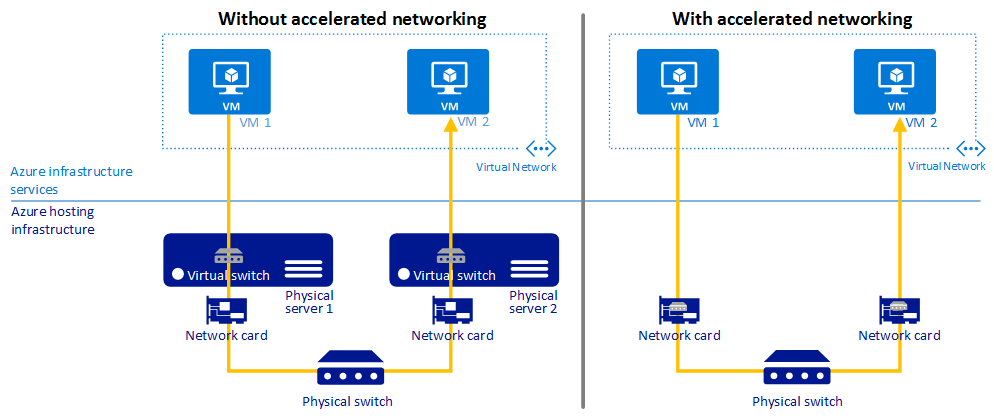
如需詳細資訊,請參閱加速網路概觀。
映像版本
最佳做法指導
映像不應該使用
latest標籤。
容器映像標籤
使用容器映像 (英文) 的 latest 標籤可能會導致無法預期的行為,且難以追蹤叢集中執行的映像版本。 您可以在建置和執行時間整合及執行容器中的掃描和補救工具,以將風險降至最低。 如需詳細資訊,請參閱 AKS 中容器映像管理的最佳做法。
節點映像升級
AKS 提供多個節點 OS 映像升級的自動升級通道。 您可以使用這些通道來控制升級的時間。 建議您加入這些自動升級通道,以確保您的節點在執行最新的安全性修補程式和更新。 如需詳細資訊,請參閱 AKS 中的自動升級節點 OS 映像。
生產工作負載的標準層
最佳做法指導
針對產品工作負載使用標準層,以取得更高的叢集可靠性和資源、支援叢集中最多 5,000 個節點,以及預設啟用的可用時間 SLA。 如果您需要 LTS,請考慮使用進階層。
Azure Kubernetes Service (AKS) 的標準層會為您的生產工作負載提供財務支援的 99.9% 可用時間服務等級協定 (SLA) (英文)。 標準層也提供更高的叢集可靠性和資源、支援叢集中最多 5,000 個節點,以及預設啟用的可用時間 SLA。 如需詳細資訊,請參閱 AKS 叢集管理定價層。
適用於動態 IP 配置的 Azure CNI
最佳做法指導
為動態 IP 配置設定 Azure CNI,以提升 IP 使用率,並防止 AKS 叢集的 IP 耗盡。
Azure CNI 中的動態 IP 配置功能可從獨立於託管 AKS 叢集子網路的子網路配置 Pod IP,並提供下列優點:
- 更有效地利用 IP:IP 會從 Pod 子網路動態分配給叢集 Pod。 相較於傳統 CNI 解決方案,此方式可更有效地利用叢集中的 IP。
- 具備擴充能力與彈性:節點和 Pod 子網路均可獨立擴充。 您可以在叢集的多個節點集區或部署在相同 VNet 中的多個 AKS 叢集中共用單一 Pod 子網路。 此外,您也可以為節點集區設定個別的 Pod 子網路。
- 高效能:由於可為 Pod 指派虛擬網路 IP,因此,它們能夠直接連線至 VNet 中的其他叢集 Pod 和資源。 此解決方案可支援非常大量的叢集,且不會導致效能降低。
- 為 Pod 提供個別 VNet 原則:由於 Pod 具有個別的子網路,因此可為其設定不同於節點原則的個別 VNet 原則。 這可實現許多實用案例,例如,僅針對 Pod 而非節點允許網際網路連線、使用 Azure NAT 閘道修正節點集區中 Pod 的來源 IP,以及使用 NSG 篩選節點集區之間的流量。
- Kubernetes 網路原則:Azure 網路原則和 Calico 均可與這個解決方案搭配使用。
如需詳細資訊,請參閱設定 Azure CNI 網路功能,以動態配置 IP 並增強子網路支援。
v5 SKU VM
最佳做法指導
在更新期間和之後使用 v5 VM SKU 以改善效能、降低整體影響,以及獲得更可靠的應用程式連線。
針對 AKS 中的節點集區,請使用具有暫時 OS 磁碟的 v5 SKU VM,為 kube 系統 Pod 提供足夠的計算資源。 如需詳細資訊,請參閱 AKS 大型工作負載效能和調整的最佳做法。
請勿使用 B 系列 VM
最佳做法指導
請勿針對 AKS 叢集使用 B 系列 VM,因為其效能不彰,且不適用於 AKS。
B 系列 VM 的效能不彰,且不適用於 AKS。 相反地,我們建議使用 v5 SKU VM。
進階磁碟
最佳做法指導
使用進階磁碟在一部虛擬機器 (VM) 中達到 99.9% 的可用性。
Azure 進階磁碟提供一致的一毫秒內磁碟延遲和高 IOPS 以及輸送量。 進階磁碟旨在為 VM 提供低延遲、高效能和一致的磁碟效能。
下列範例 YAML 資訊清單會顯示進階磁碟的儲存類別定義 (英文):
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: premium2-disk-sc
parameters:
cachingMode: None
skuName: PremiumV2_LRS
DiskIOPSReadWrite: "4000"
DiskMBpsReadWrite: "1000"
provisioner: disk.csi.azure.com
reclaimPolicy: Delete
volumeBindingMode: Immediate
allowVolumeExpansion: true
如需詳細資訊,請參閱在 AKS 上使用 Azure 進階 SSD v2 磁碟。
容器深入解析
最佳做法指導
啟用 Container Insights 來監視及診斷容器化應用程式的效能。
容器深入解析是 Azure 監視器的一項功能,可從 AKS 收集並分析容器記錄。 您可以使用檢視和預先建置的活頁簿集合來分析收集的資料。
您可以使用各種方法,在 AKS 叢集上啟用容器深入解析監視。 下列範例示範如何使用 Azure CLI 在現有叢集上啟用容器深入解析監視:
az aks enable-addons -a monitoring --name myAKSCluster --resource-group myResourceGroup
如需詳細資訊,請參閱啟用 Kubernetes 叢集的監視。
Azure 原則
最佳做法指導
使用 Azure 原則為您的 AKS 叢集套用並強制執行安全性與合規性需求。
您可以使用 Azure 原則,在 AKS 叢集上套用和強制執行內建安全性原則。 Azure 原則有助於大規模強制執行組織標準及評定合規性。 在您安裝適用於 AKS 的 Azure 原則附加元件之後,可以將個別的原則定義或稱為「方案」的原則定義群組套用至叢集。
如需詳細資訊,請參閱使用 Azure 原則保護您的 AKS 叢集。
下一步
本文著重於 Azure Kubernetes Service (AKS) 叢集部署和叢集可靠性的最佳做法。 如需更多最佳做法,請參閱下列文章:
