將資料從 Amazon S3 移轉至 Azure Data Lake Storage Gen2
適用於: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
提示
試用 Microsoft Fabric 中的 Data Factory (部分機器翻譯),這是適用於企業的全方位分析解決方案。 Microsoft Fabric (部分機器翻譯) 涵蓋從資料移動到資料科學、即時分析、商業智慧和報告的所有項目。 了解如何免費開始新的試用 (部分機器翻譯)!
使用範本,將由上億個檔案所組成的數 PB 資料從 Amazon S3 移轉至 Azure Data Lake Storage Gen2。
注意
若您想要將小型資料磁碟區從 AWS S3 複製到 Azure (例如:少於 10 TB),則使用 Azure Data Factory 複製資料工具會更有效率且更容易。 本文中描述的範本超過您需要的內容。
關於解決方案範本
尤其是在移轉超過 10 TB 的資料時,建議您使用資料分割區。 若要分割資料,請利用「前置詞」設定,依名稱篩選 Amazon S3 中的資料夾與檔案,然後每個 ADF 複製作業即可一次複製一個分割區。 您可同時執行多個 ADF 複製作業,以達到更佳的輸送量。
資料移轉通常需要單次歷程記錄資料移轉,以及定期將變更從 AWS S3 同步處理至 Azure。 以下有兩個範本,其中一個範本涵蓋單次歷程記錄資料移轉,另一個範本涵蓋將變更從 AWS S3 同步處理至 Azure。
將歷程記錄資料從 Amazon S3 移轉至 Azure Data Lake Storage Gen2 的範本
此範本 (範本名稱:將歷程記錄資料從 AWS S3 移轉至 Azure Data Lake Storage Gen2) 假設您已在 Azure SQL Database 的外部控制資料表中撰寫分割區清單。 因此,其會使用「查閱」活動從外部控制資料表中擷取分割區清單、逐一查看每個分割區,並讓每個 ADF 複製作業一次複製一個分割區。 任何複製作業完成之後,其會使用「預存程序」活動來更新複製控制資料表中每個分割區的狀態。
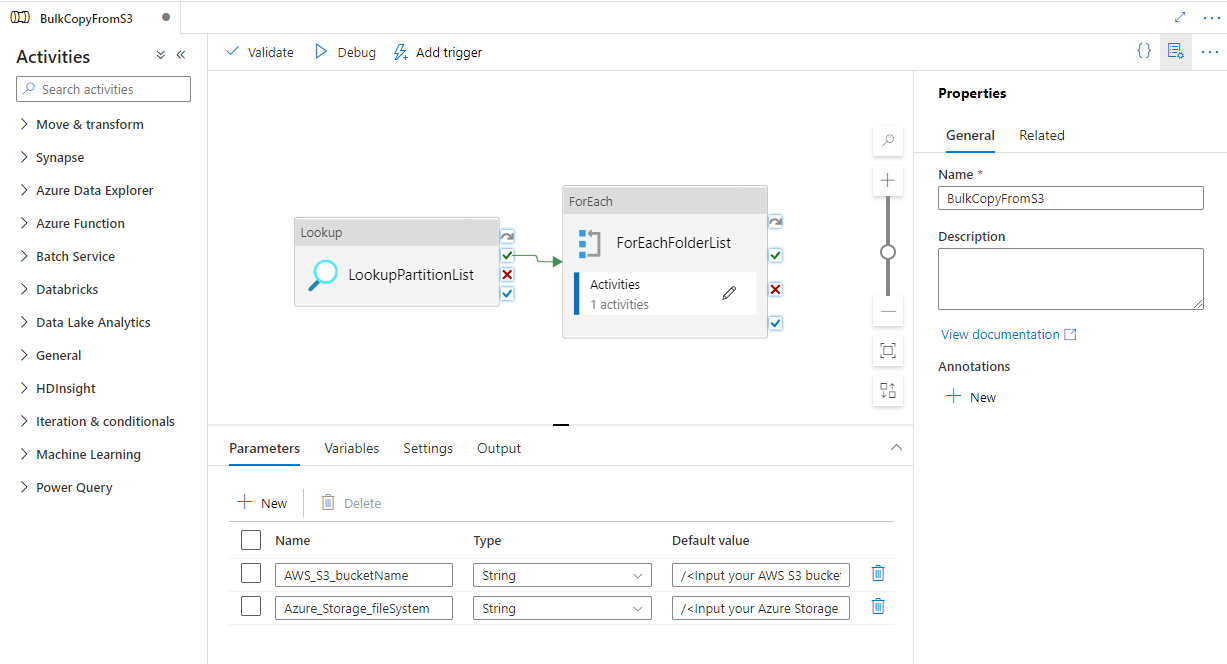
該範本包含四個活動:
- 查閱會從外部控制資料表擷取尚未複製到 Azure Data Lake Storage Gen2 的分割區。 資料表名稱為 s3_partition_control_table,而從資料表載入資料的查詢為 "SELECT PartitionPrefix FROM s3_partition_control_table WHERE SuccessOrFailure = 0"。
- ForEach 會從「查閱」活動中取得分割區清單,並針對 TriggerCopy 活動逐一查看每個分割區。 您可以設定 batchCount 以同時執行多個 ADF 複製作業。 我們已在此範本中設定 2。
- ExecutePipeline 會執行 CopyFolderPartitionFromS3 管線。 我們建立另一個管線讓每個複製作業複製分割區的原因是,可讓您輕鬆重新執行失敗的複製作業,再次從 AWS S3 重新載入該特定分割區。 所有其他正在載入其他分割的複製作業都不會受到影響。
- 複製將每個分割區從 AWS S3 複製到 Azure Data Lake Storage Gen2。
- SqlServerStoredProcedure 會更新複製控制資料表中每個分割區的狀態。
該範本包含兩個參數:
- AWS_S3_bucketName 是您要從其中移轉資料之 AWS S3 上的貯體名稱。 若要從 AWS S3 上的多個貯體移轉資料,可以在外部控制資料表中另外新增一個資料行,以儲存每個分割區的貯體名稱,並更新管線以從該對應資料行中擷取資料。
- Azure_Storage_fileSystem 是您要將資料移轉至其中之 Azure Data Lake Storage Gen2 上的檔案系統名稱。
只將變更的檔案從 Amazon S3 複製到 Azure Data Lake Storage Gen2 的範本
此範本 (範本名稱:將差異資料從 AWS S3 複製到 Azure Data Lake Storage Gen2) 使用每個檔案的 LastModifiedTime,只將新檔案或已更新檔案從 AWS S3 複製到 Azure。 請注意,若您的檔案或資料夾已使用作為 AWS S3 上檔案或資料夾名稱一部分的 TimeSlice 資訊 (例如 /yyyy/mm/dd/file.csv) 進行時間分割,則可以前往此教學課程,取得增量載入新檔案時效能更佳的方法。 此範本假設您已在 Azure SQL Database 的外部控制資料表中撰寫分割區清單。 因此,其會使用「查閱」活動從外部控制資料表中擷取分割區清單、逐一查看每個分割區,並讓每個 ADF 複製作業一次複製一個分割區。 當每個複製作業開始從 AWS S3 複製檔案時,其依賴 LastModifiedTime 屬性來僅識別及複製新檔案或已更新檔案。 任何複製作業完成之後,其會使用「預存程序」活動來更新複製控制資料表中每個分割區的狀態。
該範本包含七個活動:
- 查閱會從外部控制資料表中擷取分割區。 資料表名稱為 s3_partition_control_table,而從資料表載入資料的查詢為 "select distinct PartitionPrefix from s3_partition_delta_control_table"。
- ForEach 會從「查閱」活動中取得分割區清單,並針對 TriggerDeltaCopy 活動逐一查看每個分割區。 您可以設定 batchCount 以同時執行多個 ADF 複製作業。 我們已在此範本中設定 2。
- ExecutePipeline 會執行 DeltaCopyFolderPartitionFromS3 管線。 我們建立另一個管線讓每個複製作業複製分割區的原因是,可讓您輕鬆重新執行失敗的複製作業,再次從 AWS S3 重新載入該特定分割區。 所有其他正在載入其他分割的複製作業都不會受到影響。
- 查閱會從外部控制資料表中擷取上次複製工作執行時間,以便透過 LastModifiedTime 識別新檔案或已更新檔案。 資料表名稱為 s3_partition_delta_control_table,而從資料表載入資料的查詢是 "select max(JobRunTime) as LastModifiedTime from s3_partition_delta_control_table where PartitionPrefix = '@{pipeline().parameters.prefixStr}' and SuccessOrFailure = 1"。
- 複製只會將每個分割區的新檔案或變更的檔案從 AWS S3 複製到 Azure Data Lake Storage Gen2。 modifiedDatetimeStart 的屬性會設定為上次複製工作執行時間。 modifiedDatetimeEnd 的屬性會設定為目前的複製工作執行時間。 請注意,該時間已套用至 UTC 時區。
- SqlServerStoredProcedure 會更新複製每個分割區的狀態,並在成功時複製控制資料表中的執行時間。 SuccessOrFailure 的資料行會設定為 1。
- SqlServerStoredProcedure 會更新複製每個分割區的狀態,並在失敗時複製控制資料表中的執行時間。 SuccessOrFailure 的資料行會設定為 0。
該範本包含兩個參數:
- AWS_S3_bucketName 是您要從其中移轉資料之 AWS S3 上的貯體名稱。 若要從 AWS S3 上的多個貯體移轉資料,可以在外部控制資料表中另外新增一個資料行,以儲存每個分割區的貯體名稱,並更新管線以從該對應資料行中擷取資料。
- Azure_Storage_fileSystem 是您要將資料移轉至其中之 Azure Data Lake Storage Gen2 上的檔案系統名稱。
如何使用這兩個解決方案範本
將歷程記錄資料從 Amazon S3 移轉至 Azure Data Lake Storage Gen2 的範本
建立 Azure SQL Database 中的控制資料表,以儲存 AWS S3 的分割區清單。
注意
資料表名稱為 s3_partition_control_table。 控制資料表的結構描述是 PartitionPrefix 與 SuccessOrFailure,其中 PartitionPrefix 是 S3 中的前置詞設定,依名稱篩選 Amazon S3 中的資料夾與檔案;而 SuccessOrFailure 是複製每個分割區的狀態:0 表示此分割區尚未複製到 Azure,1 表示此分割區已成功複製到 Azure。 控制資料表中定義了 5 個分割區,而複製每個分割區的預設狀態為 0。
CREATE TABLE [dbo].[s3_partition_control_table]( [PartitionPrefix] [varchar](255) NULL, [SuccessOrFailure] [bit] NULL ) INSERT INTO s3_partition_control_table (PartitionPrefix, SuccessOrFailure) VALUES ('a', 0), ('b', 0), ('c', 0), ('d', 0), ('e', 0);在控制資料表的相同 Azure SQL Database 上建立預存程序。
注意
預存程序的名稱為 sp_update_partition_success。 其會由 ADF 管線中的 SqlServerStoredProcedure 活動叫用。
CREATE PROCEDURE [dbo].[sp_update_partition_success] @PartPrefix varchar(255) AS BEGIN UPDATE s3_partition_control_table SET [SuccessOrFailure] = 1 WHERE [PartitionPrefix] = @PartPrefix END GO前往將歷程記錄資料從 AWS S3 移轉至 Azure Data Lake Storage Gen2 範本。 輸入外部控制資料表的連線,以 AWS S3 作為資料來源存放區,以及 Azure Data Lake Storage Gen2 作為目的地存放區。 請注意,外部控制資料表與預存程序會參考相同的連線。
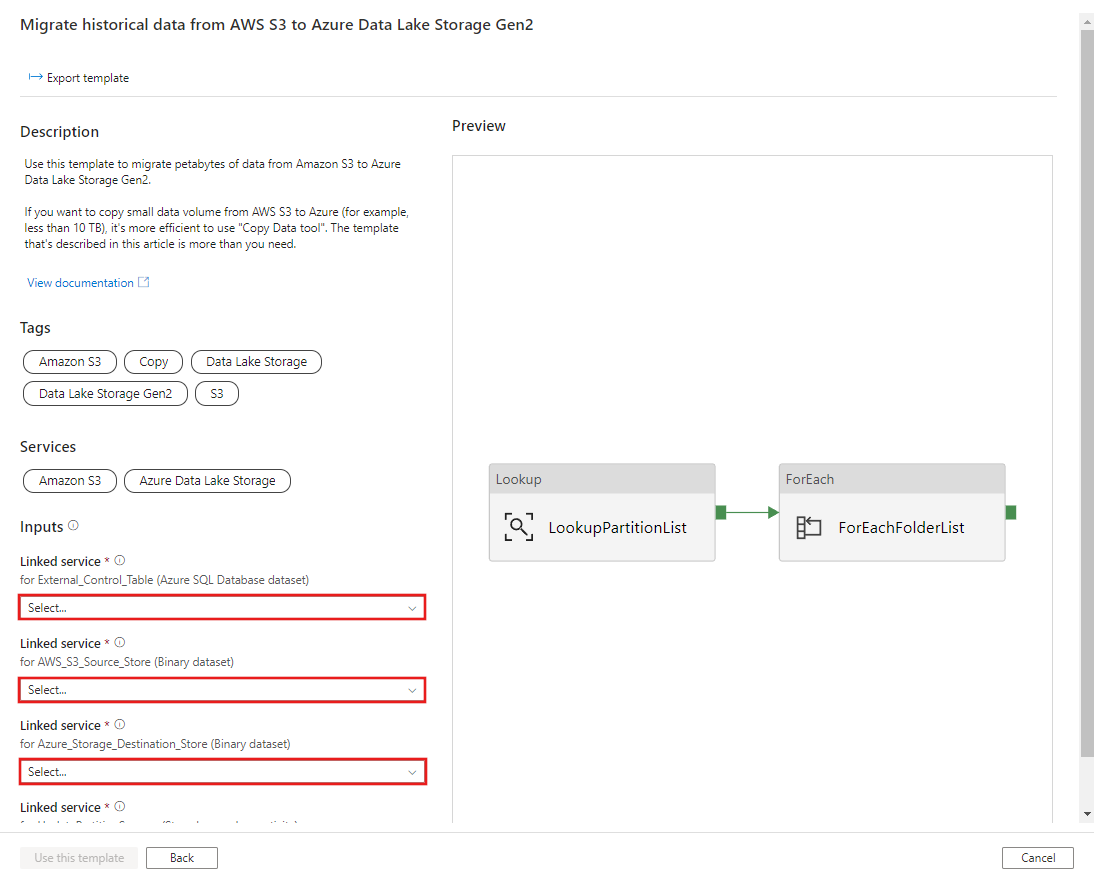
選取使用此範本。
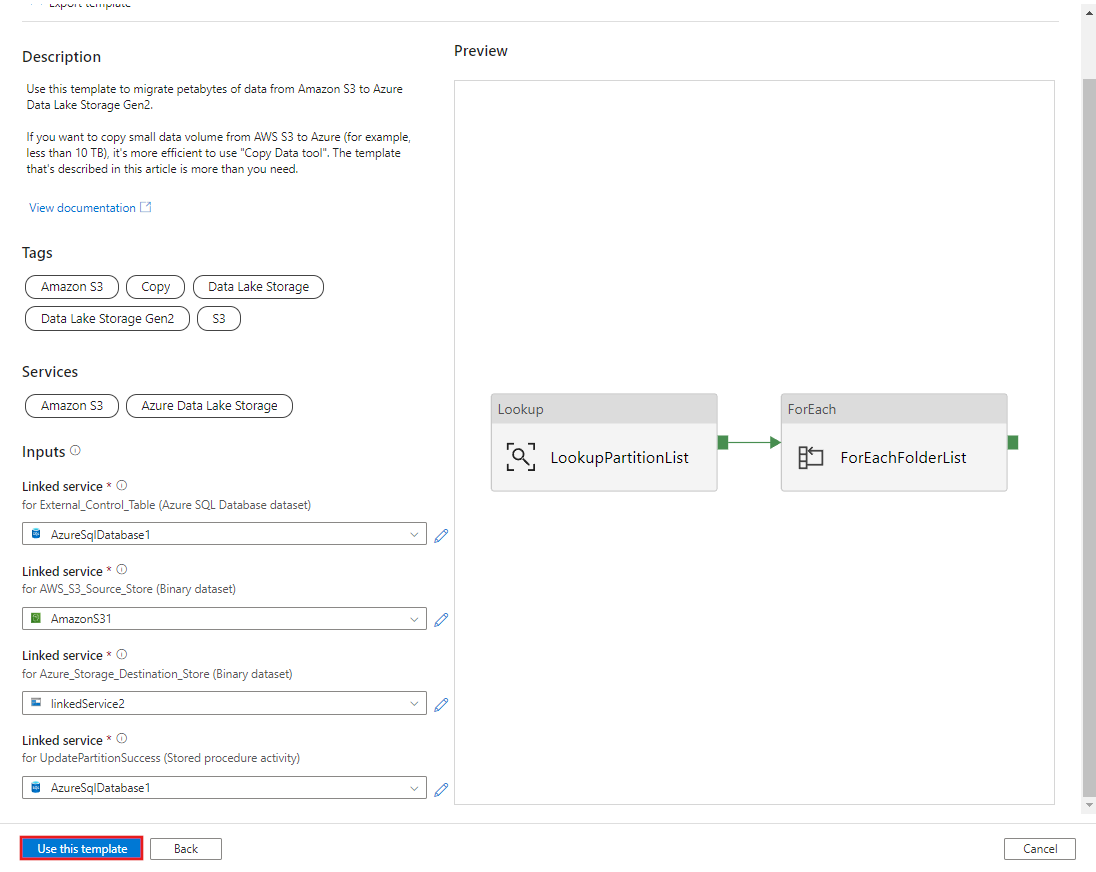
您會看到已建立的 2 個管線與 3 個資料集,如下列範例所示:
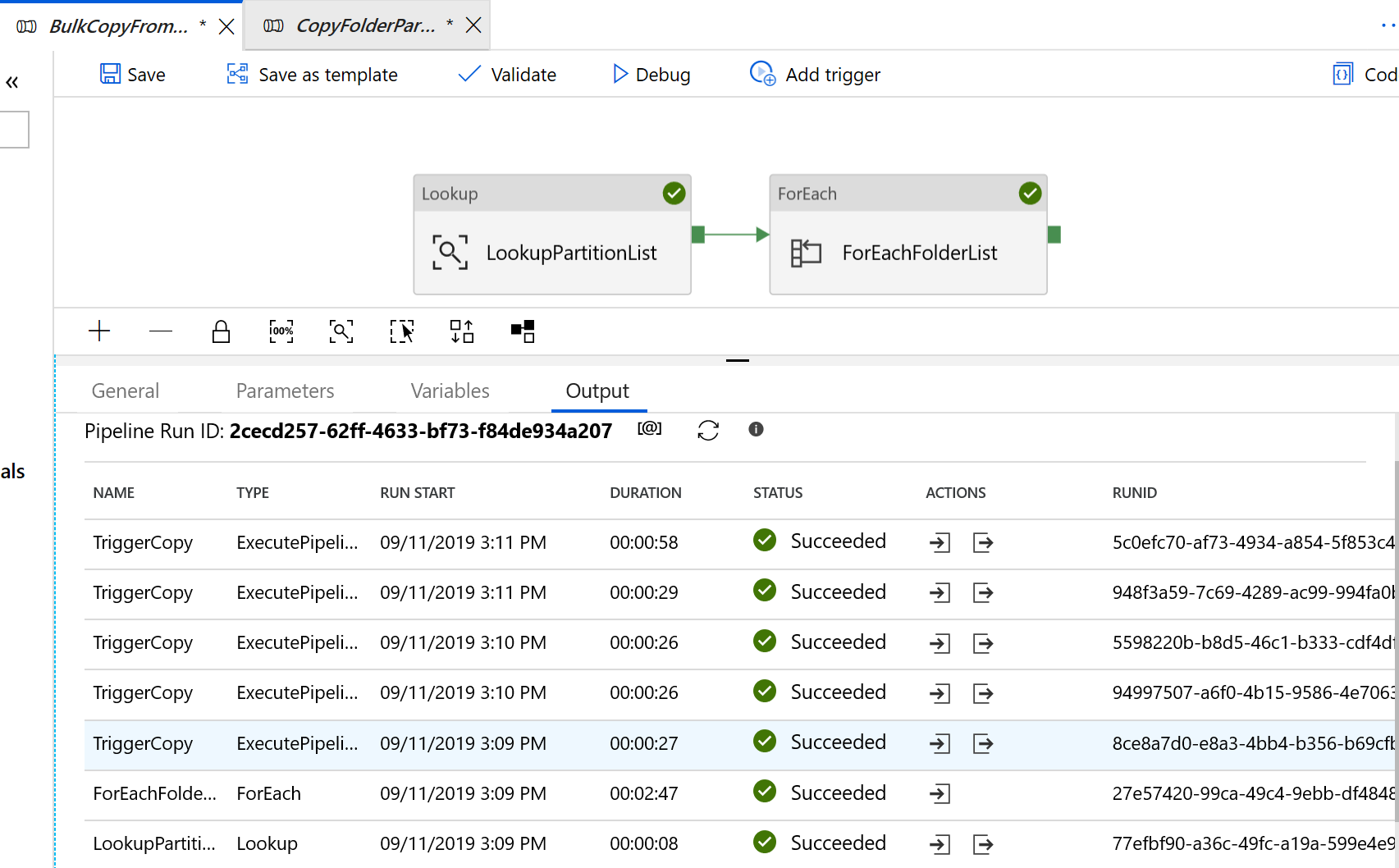
前往 "BulkCopyFromS3" 管線,然後選取 [偵錯],並輸入 [參數]。 然後,選取 [完成]。
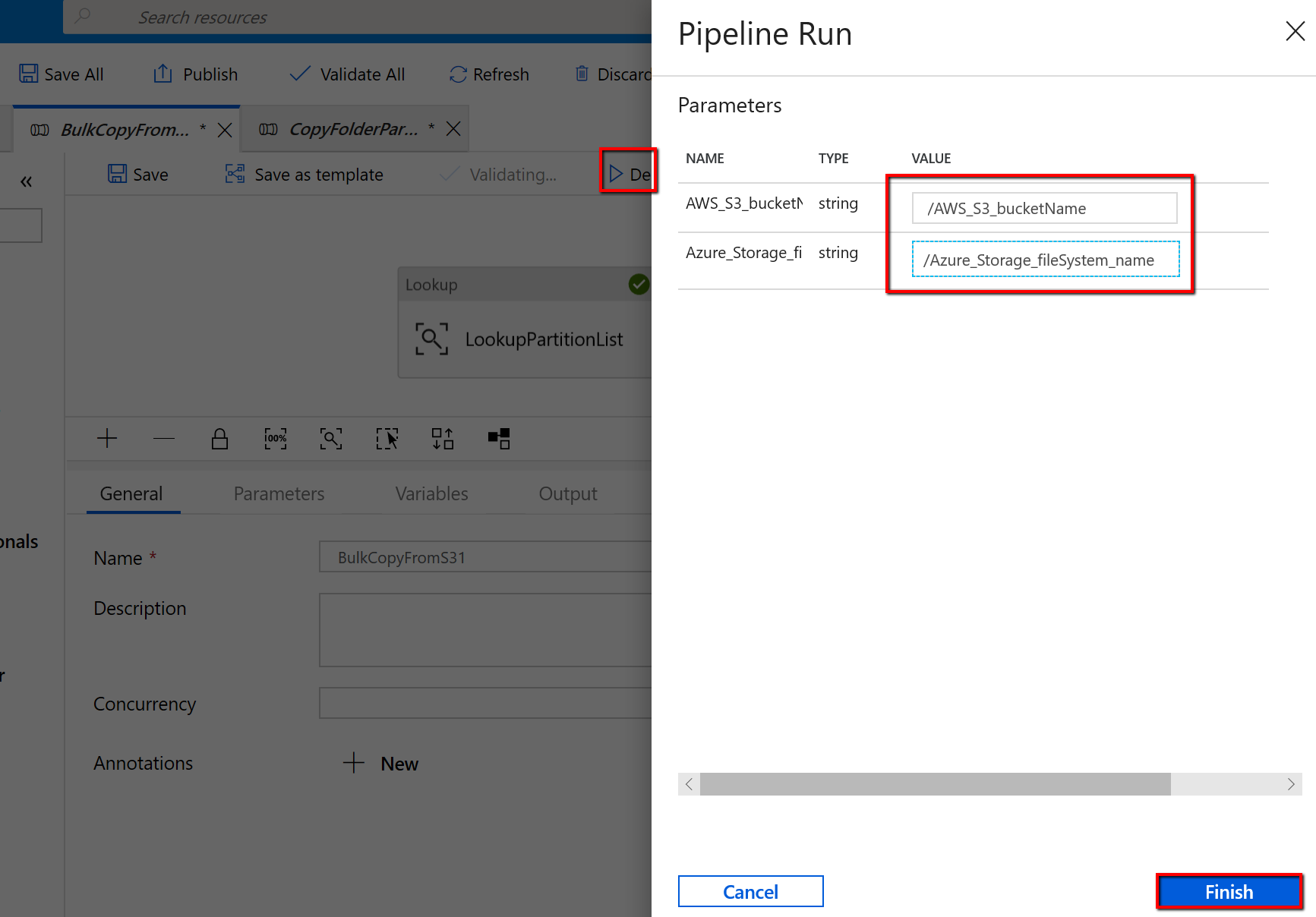
您會看到類似下列範例的結果:
只將變更的檔案從 Amazon S3 複製到 Azure Data Lake Storage Gen2 的範本
建立 Azure SQL Database 中的控制資料表,以儲存 AWS S3 的分割區清單。
注意
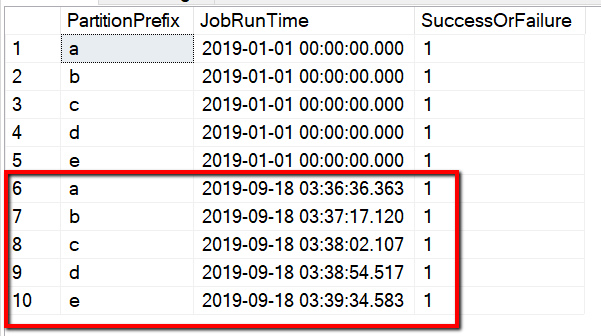
資料表名稱為 s3_partition_delta_control_table。 控制資料表的結構描述是 PartitionPrefix、JobRunTime 與 SuccessOrFailure,其中 PartitionPrefix 是 S3 中的前置詞設定,依名稱篩選 Amazon S3 中的資料夾與檔案;JobRunTime 是複製工作執行時的日期時間值;而 SuccessOrFailure 是複製每個分割區的狀態:0 表示此分割區尚未複製到 Azure,1 表示此分割區已成功複製到 Azure。 控制資料表中定義了 5 個分割區。 JobRunTime 的預設值可以是單次歷程記錄資料移轉啟動時的時間。 ADF 複製活動會複製 AWS S3 上的檔案,該檔案在該時間之後為最後一次修改。 複製每個分割區的預設狀態為 1。
CREATE TABLE [dbo].[s3_partition_delta_control_table]( [PartitionPrefix] [varchar](255) NULL, [JobRunTime] [datetime] NULL, [SuccessOrFailure] [bit] NULL ) INSERT INTO s3_partition_delta_control_table (PartitionPrefix, JobRunTime, SuccessOrFailure) VALUES ('a','1/1/2019 12:00:00 AM',1), ('b','1/1/2019 12:00:00 AM',1), ('c','1/1/2019 12:00:00 AM',1), ('d','1/1/2019 12:00:00 AM',1), ('e','1/1/2019 12:00:00 AM',1);在控制資料表的相同 Azure SQL Database 上建立預存程序。
注意
預存程序的名稱為 sp_insert_partition_JobRunTime_success。 其會由 ADF 管線中的 SqlServerStoredProcedure 活動叫用。
CREATE PROCEDURE [dbo].[sp_insert_partition_JobRunTime_success] @PartPrefix varchar(255), @JobRunTime datetime, @SuccessOrFailure bit AS BEGIN INSERT INTO s3_partition_delta_control_table (PartitionPrefix, JobRunTime, SuccessOrFailure) VALUES (@PartPrefix,@JobRunTime,@SuccessOrFailure) END GO前往將差異資料從 AWS S3 複製到 Azure Data Lake Storage Gen2 範本。 輸入外部控制資料表的連線,以 AWS S3 作為資料來源存放區,以及 Azure Data Lake Storage Gen2 作為目的地存放區。 請注意,外部控制資料表與預存程序會參考相同的連線。
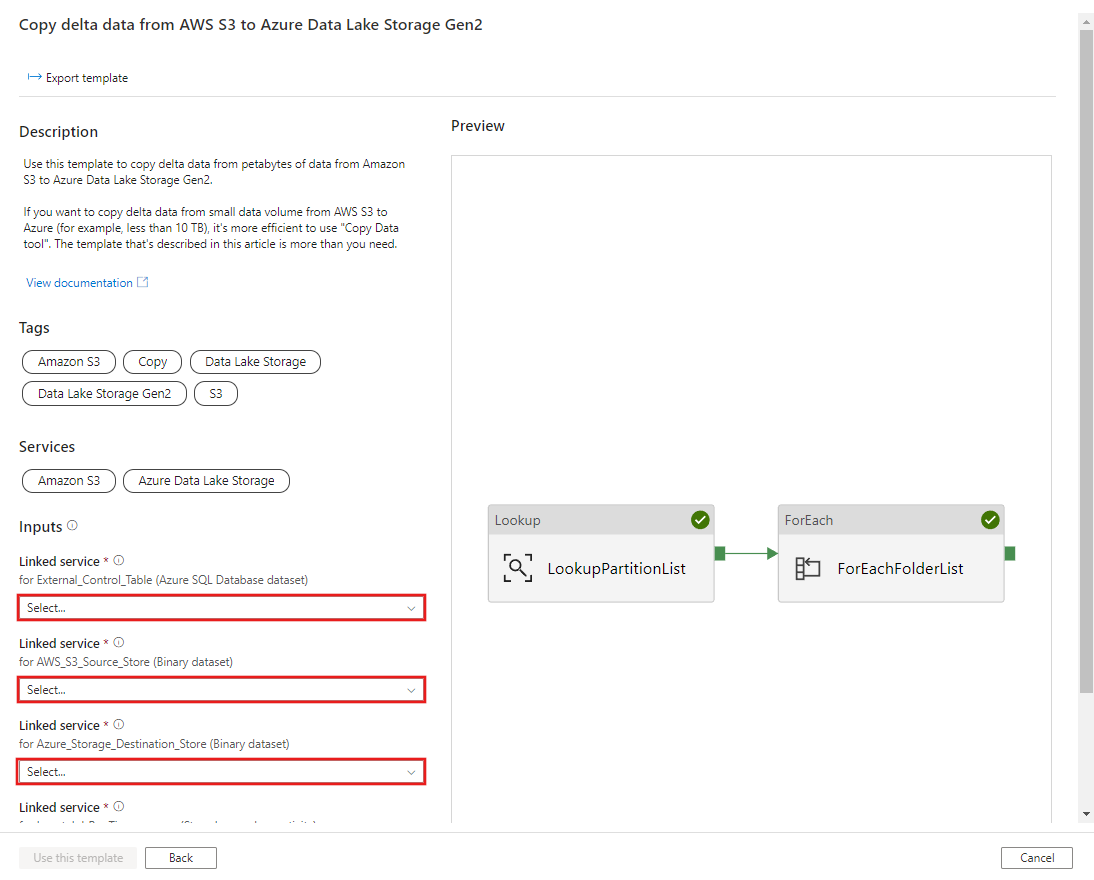
選取使用此範本。
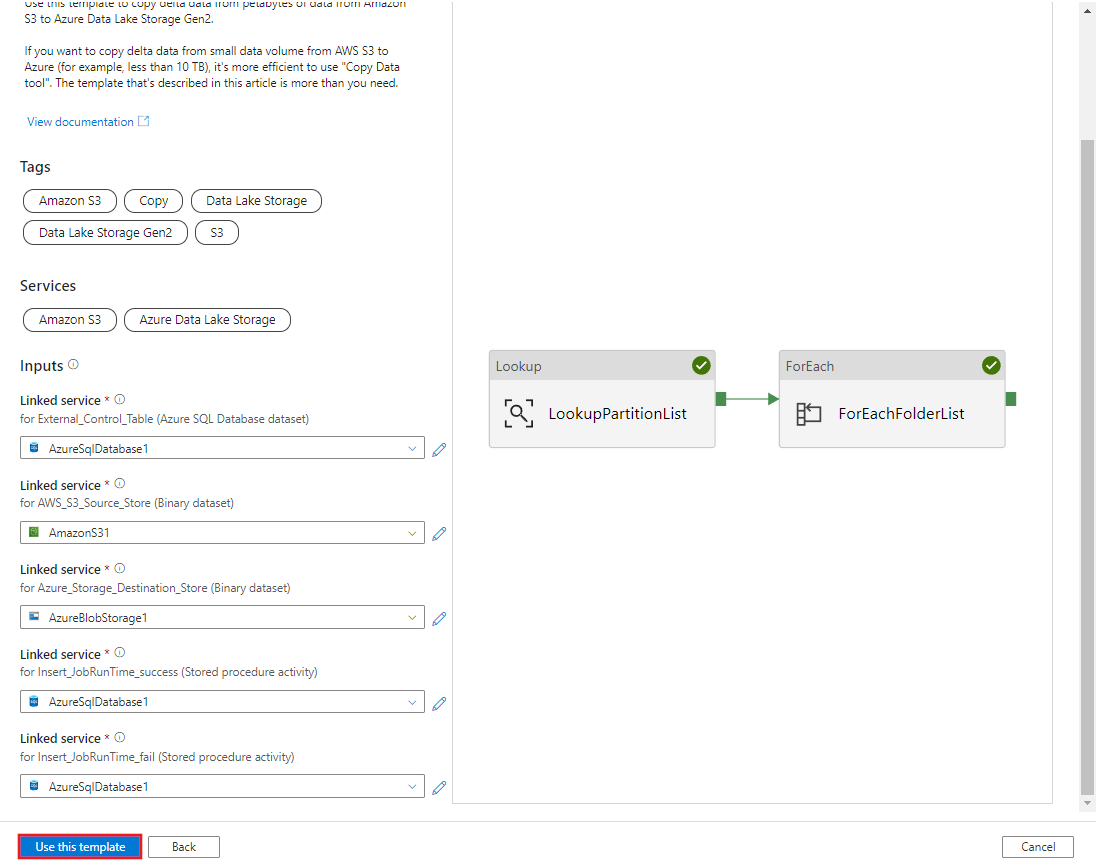
您會看到已建立的 2 個管線與 3 個資料集,如下列範例所示:
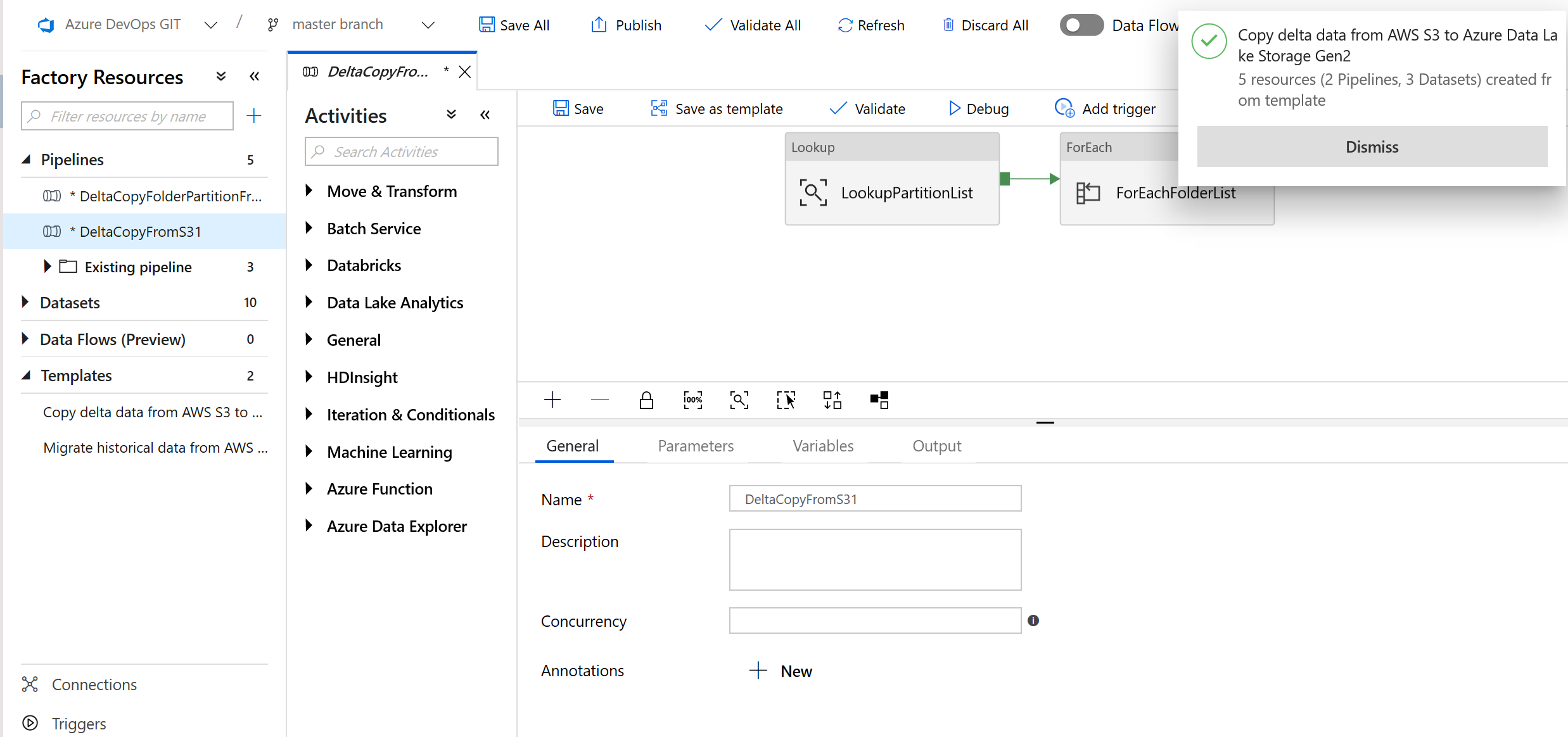
前往 "DeltaCopyFromS3" 管線,並選取 [偵錯],然後輸入 [參數]。 然後,選取 [完成]。
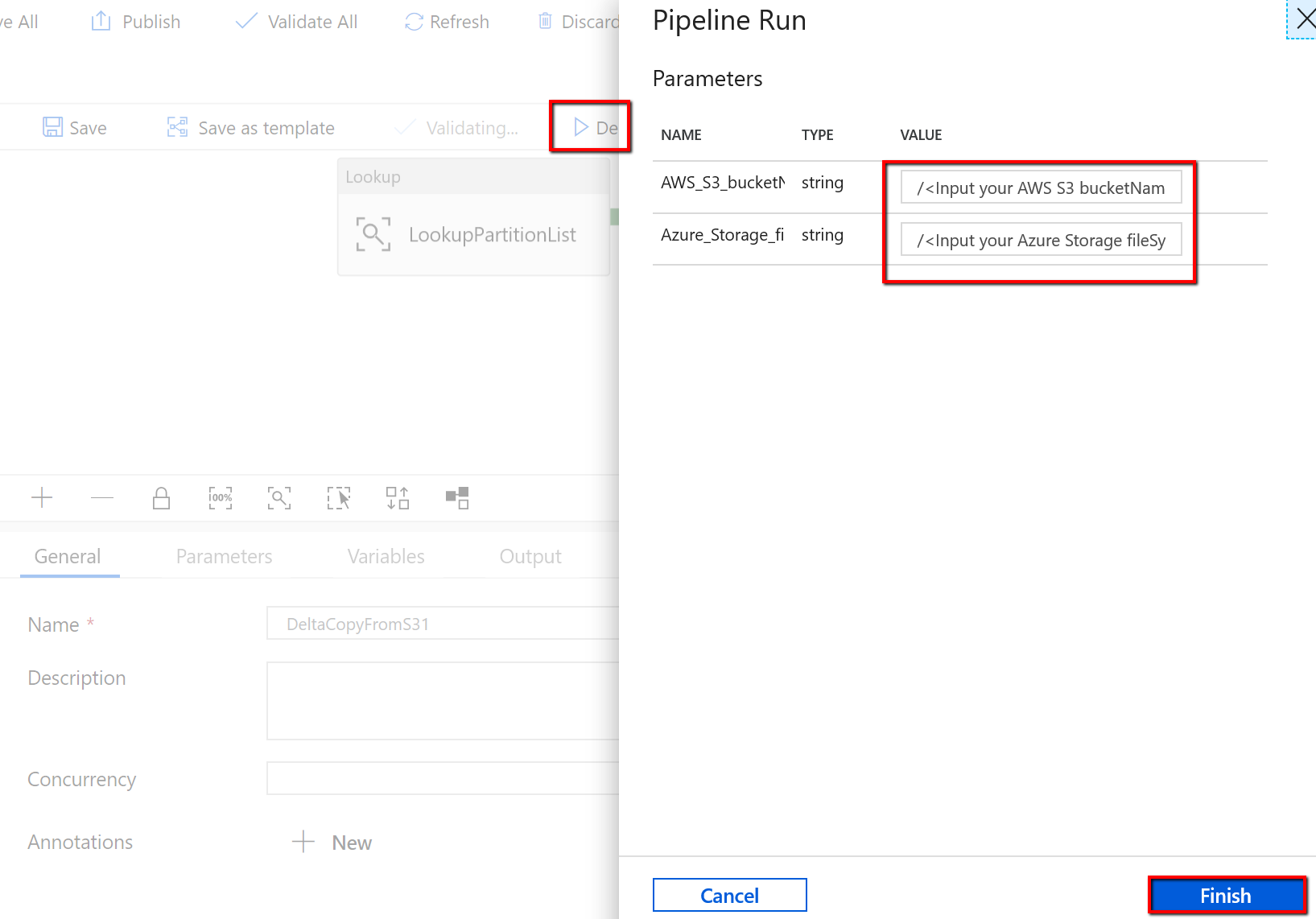
您會看到類似下列範例的結果:
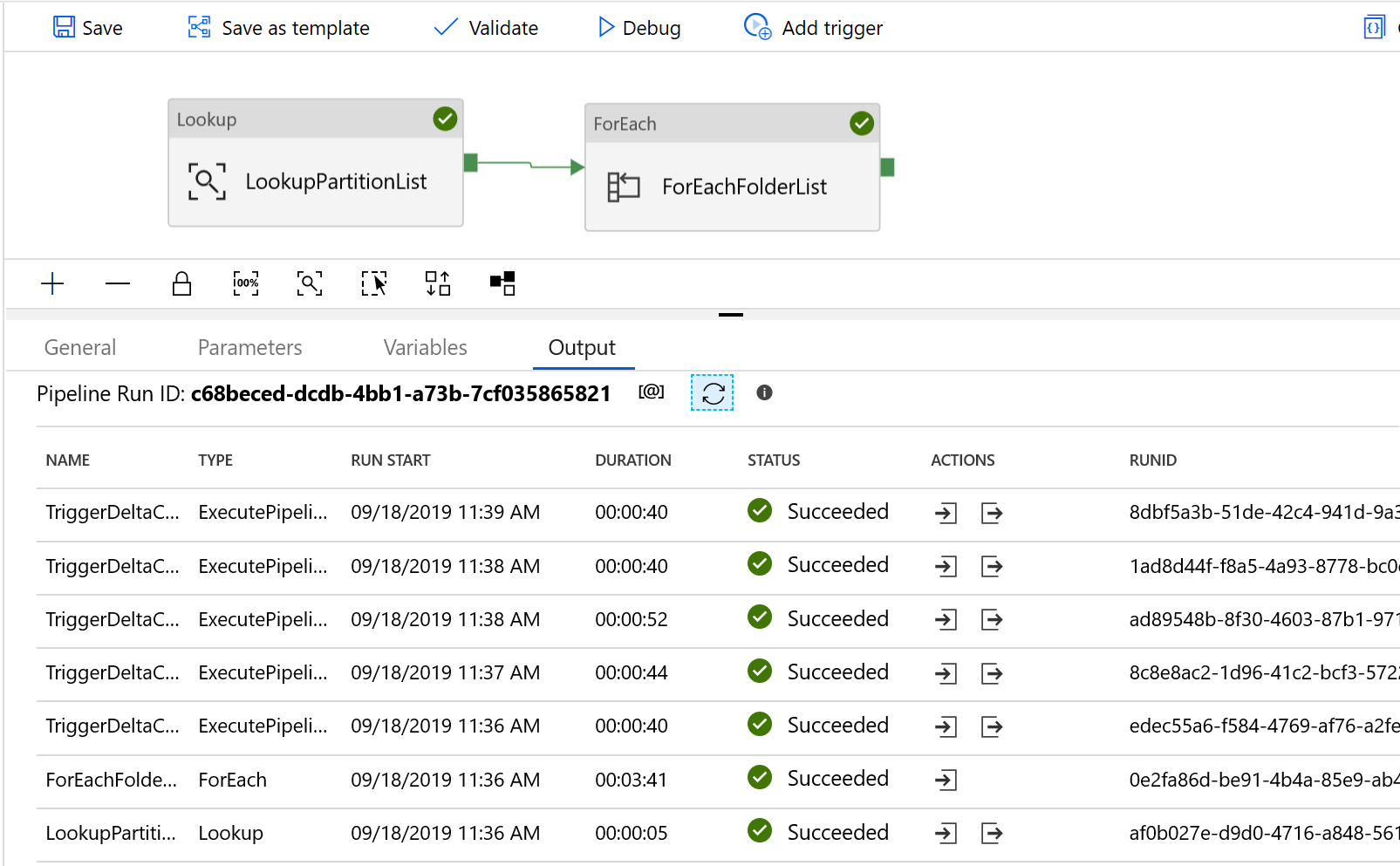
您也可以藉由查詢 "select * from s3_partition_delta_control_table" 來檢查控制資料表的結果,且您將會看到類似下列範例的輸出:
相關內容
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應