讓數據分析管線運作
數據管線 幾乎有許多數據分析解決方案。 如其名所示,數據管線會視需要擷取原始數據、清理和重新調整,然後通常會在儲存已處理的數據之前執行計算或匯總。 用戶端、報表或 API 會取用已處理的數據。 數據管線必須根據排程或由新數據觸發時提供可重複的結果。
本文說明如何使用在 HDInsight Hadoop 叢集上執行的 Oozie,讓您的資料管線運作,以重複使用性。 此範例案例會逐步引導您完成數據管線,以準備及處理航空公司航班時間序列數據。
在下列案例中,輸入數據是一般檔案,其中包含一個月的正式發行前小眾測試版數據批次。 此航班數據報括來源和目的地機場、飛行里程、出發和抵達時間等資訊。 此管道的目標是總結每日航空公司的表現,其中每個航空公司每天都有一個數據列,平均起飛和抵達延誤以分鐘為單位,以及當天飛行的總里程數。
| YEAR | MONTH | DAY_OF_MONTH | 載體 | AVG_DEP_DELAY | AVG_ARR_DELAY | TOTAL_DISTANCE |
|---|---|---|---|---|---|---|
| 2017 | 1 | 3 | AA | 10.142229 | 7.862926 | 2644539 |
| 2017 | 1 | 3 | AS | 9.435449 | 5.482143 | 572289 |
| 2017 | 1 | 3 | DL | 6.935409 | -2.1893024 | 1909696 |
範例管線會等候到新的時段正式發行前小眾測試版數據送達,然後將詳細的正式發行前小眾測試資訊儲存到 Apache Hive 數據倉儲中,以進行長期分析。 管線也會建立較小的數據集,只摘要每日航班數據。 此每日正式發行前小眾測試版摘要數據會傳送至 SQL 資料庫,以提供報告,例如網站。
下圖說明範例管線。

Apache Oozie 解決方案概觀
此管線會使用在 HDInsight Hadoop 叢集上執行的 Apache Oozie。
Oozie 會以動作、工作流程和協調器的方式描述其管線。 動作會決定要執行的實際工作,例如執行Hive查詢。 工作流程會定義動作順序。 協調器會定義工作流程執行時的排程。 協調器也可以等候新數據的可用性,再啟動工作流程的實例。
下圖顯示此範例 Oozie 管線的高階設計。

佈建 Azure 資源
此管線需要位於相同位置的 Azure SQL 資料庫 和 HDInsight Hadoop 叢集。 Azure SQL 資料庫 會儲存管線和 Oozie 元數據存放區所產生的摘要數據。
布建 Azure SQL 資料庫
建立 Azure SQL 資料庫。 請參閱在 Azure 入口網站 中建立 Azure SQL 資料庫。
若要確定 HDInsight 叢集可以存取連線的 Azure SQL 資料庫,請設定 Azure SQL 資料庫 防火牆規則,以允許 Azure 服務和資源存取伺服器。 您可以在 Azure 入口網站 中啟用此選項,方法是選取 [設定伺服器防火牆],然後在 [允許 Azure 服務和資源存取 Azure SQL 資料庫 的伺服器上] 下方選取 [開啟]。 如需詳細資訊,請參閱建立和管理 IP 防火牆規則。
使用 查詢編輯器 執行下列 SQL 語句,以建立
dailyflights資料表,以儲存管線每個回合的摘要數據。CREATE TABLE dailyflights ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, CARRIER CHAR(2), AVG_DEP_DELAY FLOAT, AVG_ARR_DELAY FLOAT, TOTAL_DISTANCE FLOAT ) GO CREATE CLUSTERED INDEX dailyflights_clustered_index on dailyflights(YEAR,MONTH,DAY_OF_MONTH,CARRIER) GO
您的 Azure SQL 資料庫 現已就緒。
布建 Apache Hadoop 叢集
使用自定義中繼存放區建立 Apache Hadoop 叢集。 從入口網站建立叢集期間,請從 [儲存體] 索引卷標,確定您在 [中繼存放區設定] 下選取您的 SQL 資料庫。 如需選取中繼存放區的詳細資訊,請參閱 在叢集建立期間選取自定義中繼存放區。 如需叢集建立的詳細資訊,請參閱 開始使用Linux上的HDInsight。
確認 SSH 通道設定
若要使用 Oozie Web 控制台來檢視協調器和工作流程實例的狀態,請設定 HDInsight 叢集的 SSH 通道。 如需詳細資訊,請參閱 SSH 通道。
注意
您也可以使用 Chrome 搭配 Foxy Proxy 擴充功能,在 SSH 通道中瀏覽叢集的 Web 資源。 將它設定為透過通道埠 9876 上的主機 localhost 來 Proxy 所有要求。 此方法與 Windows 子系統 Linux 版 相容,也稱為 Windows 10 上的 Bash。
執行下列命令以開啟叢集的 SSH 通道,其中
CLUSTERNAME是叢集的名稱:ssh -C2qTnNf -D 9876 sshuser@CLUSTERNAME-ssh.azurehdinsight.net藉由流覽至下列專案,藉由流覽至您的前端節點上的Ambari,確認通道是否正常運作:
http://headnodehost:8080若要從Ambari記憶體取 Oozie Web 控制台,請流覽至 Oozie>快速連結> [Active 伺服器] >Oozie Web UI。
設定Hive
上傳資料
下載包含一個月正式發行前小眾測試版數據的範例 CSV 檔案。 從 HDInsight GitHub 存放庫下載其 ZIP 檔案
2017-01-FlightData.zip,並將其解壓縮至 CSV 檔案2017-01-FlightData.csv。將此 CSV 檔案複製到連結至 HDInsight 叢集的 Azure 儲存體 帳戶,
/example/data/flights並將它放在資料夾中。使用 SCP 將檔案從本機計算機複製到 HDInsight 叢集前端節點的本機記憶體。
scp ./2017-01-FlightData.csv sshuser@CLUSTERNAME-ssh.azurehdinsight.net:2017-01-FlightData.csv使用 ssh 命令來連線到您的叢集。 編輯以下命令並將
CLUSTERNAME取代為您叢集的名稱,然後輸入命令:ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.net從 ssh 工作階段,使用 HDFS 命令,將檔案從前端節點本機記憶體複製到 Azure 儲存體。
hadoop fs -mkdir /example/data/flights hdfs dfs -put ./2017-01-FlightData.csv /example/data/flights/2017-01-FlightData.csv
建立表格
範例數據現已可供使用。 不過,管線需要兩個 Hive 數據表進行處理,一個用於傳入數據 (rawFlights), 另一個用於摘要數據 (flights)。 在Ambari中建立這些數據表,如下所示。
流覽至
http://headnodehost:8080以登入Ambari。從服務清單中,選取 [Hive]。
選取 [Hive 檢視 2.0] 標籤旁的 [移至檢視 ]。

在查詢文字區域中,貼上下列語句以建立
rawFlights數據表。 數據表rawFlights會針對 Azure 儲存體資料夾中的/example/data/flightsCSV 檔案提供架構讀取。CREATE EXTERNAL TABLE IF NOT EXISTS rawflights ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, FL_DATE STRING, CARRIER STRING, FL_NUM STRING, ORIGIN STRING, DEST STRING, DEP_DELAY FLOAT, ARR_DELAY FLOAT, ACTUAL_ELAPSED_TIME FLOAT, DISTANCE FLOAT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "\"" ) LOCATION '/example/data/flights'選取 [ 執行 ] 以建立數據表。
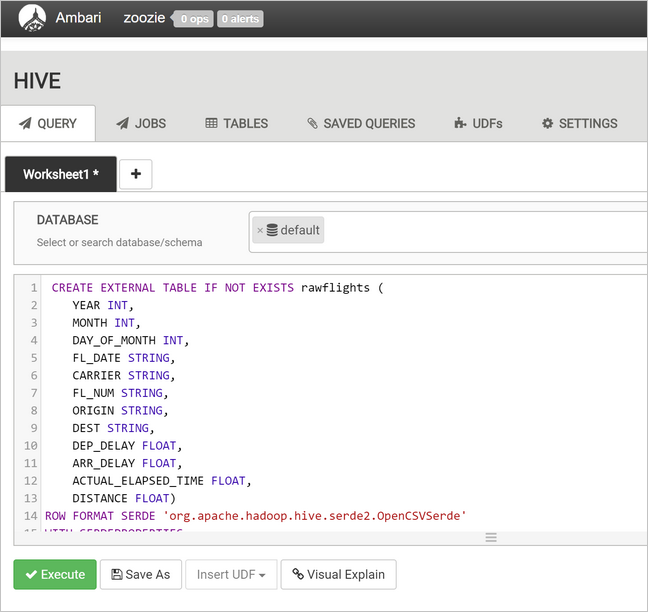
若要建立
flights數據表,請將查詢文字區域中的文字取代為下列語句。 數據表flights是Hive管理的數據表,可依月份、月和日分割載入的數據。 此數據表會包含所有歷程記錄正式發行前小眾測試版數據,每個正式發行前小眾測試版的源數據中有一個數據列的最低粒度。SET hive.exec.dynamic.partition.mode=nonstrict; CREATE TABLE flights ( FL_DATE STRING, CARRIER STRING, FL_NUM STRING, ORIGIN STRING, DEST STRING, DEP_DELAY FLOAT, ARR_DELAY FLOAT, ACTUAL_ELAPSED_TIME FLOAT, DISTANCE FLOAT ) PARTITIONED BY (YEAR INT, MONTH INT, DAY_OF_MONTH INT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "\"" );選取 [ 執行 ] 以建立數據表。
建立 Oozie 工作流程
管線通常會依指定的時間間隔分批處理數據。 在此情況下,管線會每日處理正式發行前小眾測試版數據。 此方法可讓輸入 CSV 檔案每日、每周、每月或每年送達。
範例工作流程會以三個主要步驟處理正式發行前小眾測試版數據:
- 執行Hive查詢,從數據表所
rawFlights代表的來源 CSV 檔案擷取當天日期範圍的數據,並將數據插入數據表中flights。 - 執行Hive查詢以動態方式在Hive中建立當天的臨時表,其中包含依日期和貨運公司摘要的航班數據複本。
- 使用 Apache Sqoop 將 Hive 中每日臨時表的所有數據複製到 Azure SQL 資料庫 中的目的地
dailyflights數據表。 Sqoop 會從位於 Azure 儲存體 的 Hive 數據表後方數據讀取源數據列,並使用 JDBC 連線將它們載入 SQL 資料庫。
這三個步驟是由 Oozie 工作流程協調。
從本機工作站建立名為
job.properties的檔案。 使用下列文字作為檔案的起始內容。 然後更新特定環境的值。 下表摘要說明每個屬性,並指出您可以在何處找到您自己的環境值。nameNode=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net jobTracker=[ACTIVERESOURCEMANAGER]:8050 queueName=default oozie.use.system.libpath=true appBase=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie oozie.wf.application.path=${appBase}/load_flights_by_day hiveScriptLoadPartition=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-load-flights-partition.hql hiveScriptCreateDailyTable=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-create-daily-summary-table.hql hiveDailyTableName=dailyflights${year}${month}${day} hiveDataFolder=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/day/${year}/${month}/${day} sqlDatabaseConnectionString="jdbc:sqlserver://[SERVERNAME].database.windows.net;user=[USERNAME];password=[PASSWORD];database=[DATABASENAME]" sqlDatabaseTableName=dailyflights year=2017 month=01 day=03屬性 值來源 nameNode 連結至 HDInsight 叢集之 Azure 儲存體 容器的完整路徑。 jobTracker 作用中叢集 YARN 前端節點的內部主機名。 在Ambari首頁上,從服務清單中選取YARN,然後選擇 [使用中資源管理員]。 主機名 URI 會顯示在頁面頂端。 附加埠 8050。 queueName 排程 Hive 動作時所使用的 YARN 佇列名稱。 保留為預設值。 oozie.use.system.libpath 保留為 true。 appBase Azure 儲存體 中部署 Oozie 工作流程和支援檔案之子資料夾的路徑。 oozie.wf.application.path 要執行的 Oozie 工作流程 workflow.xml位置。hiveScriptLoadPartition Hive 查詢檔案 hive-load-flights-partition.hql中 Azure 儲存體 的路徑。hiveScriptCreateDailyTable Hive 查詢檔案 hive-create-daily-summary-table.hql中 Azure 儲存體 的路徑。hiveDailyTableName 要用於臨時表的動態產生名稱。 hiveDataFolder 臨時表所包含之數據的路徑 Azure 儲存體。 sqlDatabase 連線 ionString Azure SQL 資料庫 的 JDBC 語法 連接字串。 sqlDatabaseTableName Azure 中資料表的名稱 SQL 資料庫 插入摘要數據列。 保留為 dailyflights。year 計算航班摘要當天的年份元件。 保持原狀。 個月 計算正式發行前小眾測試版摘要之日期的月份元件。 保持原狀。 天 計算正式發行前小眾測試版摘要當天的月份元件。 保持原狀。 從本機工作站建立名為
hive-load-flights-partition.hql的檔案。 使用下列程式代碼作為檔案的內容。SET hive.exec.dynamic.partition.mode=nonstrict; INSERT OVERWRITE TABLE flights PARTITION (YEAR, MONTH, DAY_OF_MONTH) SELECT FL_DATE, CARRIER, FL_NUM, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, ACTUAL_ELAPSED_TIME, DISTANCE, YEAR, MONTH, DAY_OF_MONTH FROM rawflights WHERE year = ${year} AND month = ${month} AND day_of_month = ${day};Oozie 變數會使用 語法
${variableName}。 這些變數會在檔案中job.properties設定。 Oozie 會在運行時間取代實際值。從本機工作站建立名為
hive-create-daily-summary-table.hql的檔案。 使用下列程式代碼作為檔案的內容。DROP TABLE ${hiveTableName}; CREATE EXTERNAL TABLE ${hiveTableName} ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, CARRIER STRING, AVG_DEP_DELAY FLOAT, AVG_ARR_DELAY FLOAT, TOTAL_DISTANCE FLOAT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '${hiveDataFolder}'; INSERT OVERWRITE TABLE ${hiveTableName} SELECT year, month, day_of_month, carrier, avg(dep_delay) avg_dep_delay, avg(arr_delay) avg_arr_delay, sum(distance) total_distance FROM flights GROUP BY year, month, day_of_month, carrier HAVING year = ${year} AND month = ${month} AND day_of_month = ${day};此查詢會建立一個臨時表,該臨時表只會儲存一天的摘要數據,請記下 SELECT 語句,以計算貨運公司每天流動的平均延遲和距離總計。 插入此數據表的數據儲存在已知位置(hiveDataFolder 變數所指示的路徑),以便在下一個步驟中作為 Sqoop 的來源。
從本機工作站建立名為
workflow.xml的檔案。 使用下列程式代碼作為檔案的內容。 上述步驟會以 Oozie 工作流程檔案中的個別動作表示。<workflow-app name="loadflightstable" xmlns="uri:oozie:workflow:0.5"> <start to = "RunHiveLoadFlightsScript"/> <action name="RunHiveLoadFlightsScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScriptLoadPartition}</script> <param>year=${year}</param> <param>month=${month}</param> <param>day=${day}</param> </hive> <ok to="RunHiveCreateDailyFlightTableScript"/> <error to="fail"/> </action> <action name="RunHiveCreateDailyFlightTableScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScriptCreateDailyTable}</script> <param>hiveTableName=${hiveDailyTableName}</param> <param>year=${year}</param> <param>month=${month}</param> <param>day=${day}</param> <param>hiveDataFolder=${hiveDataFolder}/${year}/${month}/${day}</param> </hive> <ok to="RunSqoopExport"/> <error to="fail"/> </action> <action name="RunSqoopExport"> <sqoop xmlns="uri:oozie:sqoop-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.compress.map.output</name> <value>true</value> </property> </configuration> <arg>export</arg> <arg>--connect</arg> <arg>${sqlDatabaseConnectionString}</arg> <arg>--table</arg> <arg>${sqlDatabaseTableName}</arg> <arg>--export-dir</arg> <arg>${hiveDataFolder}/${year}/${month}/${day}</arg> <arg>-m</arg> <arg>1</arg> <arg>--input-fields-terminated-by</arg> <arg>"\t"</arg> <archive>mssql-jdbc-7.0.0.jre8.jar</archive> </sqoop> <ok to="end"/> <error to="fail"/> </action> <kill name="fail"> <message>Job failed, error message[${wf:errorMessage(wf:lastErrorNode())}] </message> </kill> <end name="end"/> </workflow-app>
這兩個Hive查詢會透過其在 Azure 儲存體中的路徑來存取,而其餘的變數值則由 job.properties 檔案提供。 此檔案會將工作流程設定為在 2017 年 1 月 3 日執行的日期。
部署並執行 Oozie 工作流程
從 bash 工作階段使用 SCP 來部署 Oozie 工作流程 (workflow.xml)、Hive 查詢 (hive-load-flights-partition.hql 和 hive-create-daily-summary-table.hql), 以及作業組態 (job.properties)。 在 Oozie 中 job.properties ,只有檔案可以存在於前端節點的本機記憶體上。 所有其他檔案都必須儲存在 HDFS 中,在此情況下 Azure 儲存體。 工作流程所使用的 Sqoop 動作取決於 JDBC 驅動程式,以便與 SQL 資料庫 通訊,而此驅動程式必須從前端節點複製到 HDFS。
在
load_flights_by_day前端節點的本機記憶體中,於用戶路徑下方建立子資料夾。 從開啟的 ssh 工作階段中,執行下列命令:mkdir load_flights_by_day將目前目錄中的所有檔案 (
workflow.xml和job.properties檔案) 複製到load_flights_by_day子資料夾。 從本機工作站執行下列命令:scp ./* sshuser@CLUSTERNAME-ssh.azurehdinsight.net:load_flights_by_day將工作流程檔案複製到 HDFS。 從開啟的 SSH 工作階段中,執行下列命令:
cd load_flights_by_day hadoop fs -mkdir -p /oozie/load_flights_by_day hdfs dfs -put ./* /oozie/load_flights_by_day從本機前端節點複製到
mssql-jdbc-7.0.0.jre8.jarHDFS 中的工作流程資料夾。 如果您的叢集包含不同的 jar 檔案,請視需要修改命令。 視需要修訂workflow.xml以反映不同的 jar 檔案。 從開啟的 ssh 工作階段中,執行下列命令:hdfs dfs -put /usr/share/java/sqljdbc_7.0/enu/mssql-jdbc*.jar /oozie/load_flights_by_day執行工作流程。 從開啟的 ssh 工作階段中,執行下列命令:
oozie job -config job.properties -run使用 Oozie Web 控制台觀察狀態。 從Ambari中,選取 [Oozie]、[快速連結],然後選取 [Oozie Web 控制台]。 在 [ 工作流程作業] 索引標籤下,選取 [ 所有作業]。
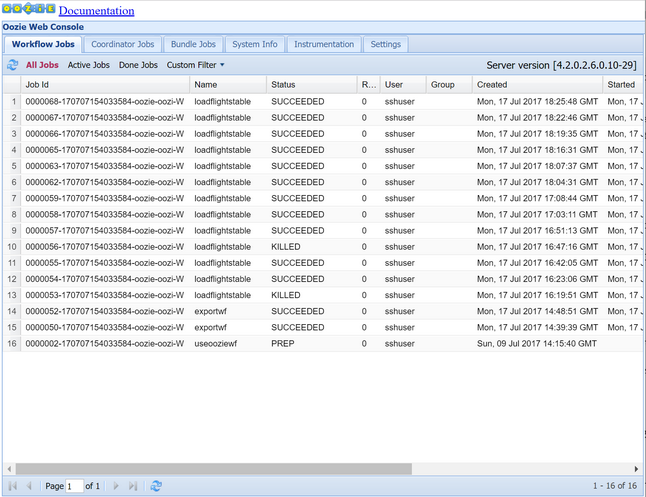
當狀態為 SUCCEEDED 時,請查詢 SQL 資料庫 數據表來檢視插入的數據列。 使用 Azure 入口網站,流覽至 SQL 資料庫 的窗格,選取 [工具],然後開啟 查詢編輯器。
SELECT * FROM dailyflights
現在工作流程正在針對單一測試日執行,您可以將此工作流程包裝成協調器來排程工作流程,以便每天執行。
使用協調器執行工作流程
若要排程此工作流程,讓它每天執行(或日期範圍內的所有天數),您可以使用協調器。 協調器是由 XML 檔案所定義,例如 coordinator.xml:
<coordinator-app name="daily_export" start="2017-01-01T00:00Z" end="2017-01-05T00:00Z" frequency="${coord:days(1)}" timezone="UTC" xmlns="uri:oozie:coordinator:0.4">
<datasets>
<dataset name="ds_input1" frequency="${coord:days(1)}" initial-instance="2016-12-31T00:00Z" timezone="UTC">
<uri-template>${sourceDataFolder}${YEAR}-${MONTH}-FlightData.csv</uri-template>
<done-flag></done-flag>
</dataset>
</datasets>
<input-events>
<data-in name="event_input1" dataset="ds_input1">
<instance>${coord:current(0)}</instance>
</data-in>
</input-events>
<action>
<workflow>
<app-path>${appBase}/load_flights_by_day</app-path>
<configuration>
<property>
<name>year</name>
<value>${coord:formatTime(coord:nominalTime(), 'yyyy')}</value>
</property>
<property>
<name>month</name>
<value>${coord:formatTime(coord:nominalTime(), 'MM')}</value>
</property>
<property>
<name>day</name>
<value>${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>hiveScriptLoadPartition</name>
<value>${hiveScriptLoadPartition}</value>
</property>
<property>
<name>hiveScriptCreateDailyTable</name>
<value>${hiveScriptCreateDailyTable}</value>
</property>
<property>
<name>hiveDailyTableNamePrefix</name>
<value>${hiveDailyTableNamePrefix}</value>
</property>
<property>
<name>hiveDailyTableName</name>
<value>${hiveDailyTableNamePrefix}${coord:formatTime(coord:nominalTime(), 'yyyy')}${coord:formatTime(coord:nominalTime(), 'MM')}${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>hiveDataFolderPrefix</name>
<value>${hiveDataFolderPrefix}</value>
</property>
<property>
<name>hiveDataFolder</name>
<value>${hiveDataFolderPrefix}${coord:formatTime(coord:nominalTime(), 'yyyy')}/${coord:formatTime(coord:nominalTime(), 'MM')}/${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>sqlDatabaseConnectionString</name>
<value>${sqlDatabaseConnectionString}</value>
</property>
<property>
<name>sqlDatabaseTableName</name>
<value>${sqlDatabaseTableName}</value>
</property>
</configuration>
</workflow>
</action>
</coordinator-app>
如您所見,大部分協調器只是將組態信息傳遞至工作流程實例。 不過,有一些要標註的重要專案。
第 1 點:元素
start本身的coordinator-app和end屬性會控制協調器執行的時間間隔。<coordinator-app ... start="2017-01-01T00:00Z" end="2017-01-05T00:00Z" frequency="${coord:days(1)}" ...>協調器負責根據 屬性所
frequency指定的間隔,在 和end日期範圍內排程動作start。 每個排程的動作會依設定執行工作流程。 在上述協調器定義中,協調器會設定為從 2017 年 1 月 1 日到 2017 年 1 月 5 日執行動作。 頻率由 Oozie 運算式語言頻率表示式${coord:days(1)}設定為一天。 這會導致協調器每天排程動作(因此工作流程)一次。 針對過去日期範圍,如此範例所示,動作會排程為不延遲執行。 排程執行動作的開始日期稱為 名義時間。 例如,若要處理 2017 年 1 月 1 日的數據,協調器會以 2017-01-01T00:00:00 GMT 的名義時間排程動作。第 2 點:在工作流程的日期範圍內,
dataset元素會指定要在 HDFS 中尋找特定日期範圍數據的位置,並設定 Oozie 如何判斷數據是否尚未可供處理。<dataset name="ds_input1" frequency="${coord:days(1)}" initial-instance="2016-12-31T00:00Z" timezone="UTC"> <uri-template>${sourceDataFolder}${YEAR}-${MONTH}-FlightData.csv</uri-template> <done-flag></done-flag> </dataset>HDFS 中數據的路徑會根據 元素中
uri-template提供的表示式動態建置。 在此協調器中,一天的頻率也會與數據集搭配使用。 當排程動作時,協調器元素控件的開始和結束日期(並定義其名義時間),initial-instance而數據集上的 則frequency控制用於建構uri-template的日期計算。 在此情況下,請將初始實例設定為協調器開始前一天,以確保它會挑選第一天的 (2017 年 1 月 1 日) 數據。 數據集的日期計算會從initial-instance(2016/12/31/2016) 的值向前推進,以數據集頻率(一天)遞增,直到找到未通過協調器所設定名義時間的最近日期(2017-01-01T00:00:00 GMT 進行第一個動作)。空白
done-flag元素表示當 Oozie 檢查指定時間是否有輸入資料時,Oozie 會判斷是否有目錄或檔案可用的數據。 在此情況下,這是 csv 檔案的存在。 如果 CSV 檔案存在,Oozie 會假設數據已就緒,並啟動工作流程實例來處理檔案。 如果沒有 csv 檔案存在,Oozie 會假設數據尚未就緒,且工作流程的執行會進入等候狀態。第3點:元素
data-in會指定取代相關聯數據集中uri-template值時,要當做名義時間使用的特定時間戳。<data-in name="event_input1" dataset="ds_input1"> <instance>${coord:current(0)}</instance> </data-in>在此情況下,請將 實例設定為 表達式 ,此表達式
${coord:current(0)}會轉譯為使用協調器原本排程的動作名義時間。 換句話說,當協調器排程以 01/01/2017 的名義時間執行動作時,則 01/01/2017 是用來取代 URI 範本中 YEAR (2017) 和 MONTH (01) 變數的內容。 計算此實例的 URI 範本之後,Oozie 會檢查預期的目錄或檔案是否可用,並據此排程工作流程的下一次執行。
上述三點結合,以產生協調器會以每日方式排程處理源數據的情況。
第 1 點:協調器從 2017-01-01 名義日期開始。
第 2 點:Oozie 會尋找 中
sourceDataFolder/2017-01-FlightData.csv可用的數據。第 3 點:當 Oozie 找到該檔案時,它會排程將處理 2017 年 1 月 1 日數據的工作流程實例。 Oozie 接著會繼續處理 2017-01-02。 此評估最多重複,但不包括 2017-01-05。
如同工作流程,協調器組態是在檔案中 job.properties 定義,該檔案具有工作流程所使用的設定超集。
nameNode=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net
jobTracker=[ACTIVERESOURCEMANAGER]:8050
queueName=default
oozie.use.system.libpath=true
appBase=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie
oozie.coord.application.path=${appBase}
sourceDataFolder=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/
hiveScriptLoadPartition=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-load-flights-partition.hql
hiveScriptCreateDailyTable=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-create-daily-summary-table.hql
hiveDailyTableNamePrefix=dailyflights
hiveDataFolderPrefix=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/day/
sqlDatabaseConnectionString="jdbc:sqlserver://[SERVERNAME].database.windows.net;user=[USERNAME];password=[PASSWORD];database=[DATABASENAME]"
sqlDatabaseTableName=dailyflights
此 job.properties 檔案中引進的唯一新屬性如下:
| 屬性 | 值來源 |
|---|---|
| oozie.coord.application.path | 指出包含要執行之 Oozie 協調器之檔案的位置 coordinator.xml 。 |
| hiveDailyTableNamePrefix | 動態建立臨時表之數據表名稱時所使用的前置詞。 |
| hiveDataFolderPrefix | 將儲存所有臨時表之路徑的前置詞。 |
部署並執行 Oozie 協調器
若要使用協調器執行管線,請以與工作流程類似的方式繼續,但您從包含工作流程的資料夾上方的資料夾工作一層除外。 此資料夾慣例會將協調器與磁碟上的工作流程分開,因此您可以將一個協調器與不同的子工作流程產生關聯。
從本機電腦使用 SCP,將協調器檔案複製到叢集前端節點的本機記憶體。
scp ./* sshuser@CLUSTERNAME-ssh.azurehdinsight.net:~透過 SSH 連線到您的前端節點。
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.net將協調器檔案複製到 HDFS。
hdfs dfs -put ./* /oozie/執行協調器。
oozie job -config job.properties -run使用 Oozie Web 控制台確認狀態,這次選取 [協調器作業] 索引標籤,然後選取 [所有作業]。

選取協調器實例以顯示排程的動作清單。 在此情況下,您應該會看到從 2017 年 1 月 1 日到 2017 年 1 月 4 日,名義時間的四個動作。

此清單中的每個動作都會對應至工作流程的實例,該工作流程會處理一天的數據,其中該日期的開始會以名義時間表示。