使用 MLflow 和 Azure Machine Learning 追蹤 Azure Synapse Analytics ML 實驗
在本文中,了解如何讓 MLflow 連線到 Azure Machine Learning,同時在 Azure Synapse Analytics 工作區中工作。 您可以利用此設定進行追蹤、模型管理和模型部署。
MLflow 是一個開放原始碼程式庫,可用於管理機器學習實驗的生命週期。 MLFlow 追蹤是 MLflow 的元件,可記錄和追蹤您的定型執行計量和模型成品。 深入了解 MLflow。
如果您有 MLflow 專案要使用 Azure Machine Learning 進行定型,請參閱使用 MLflow 專案和 Azure Machine Learning (預覽) 來定型 ML 模型。
必要條件
安裝程式庫
若要在 Azure Synapse Analytics 的專用叢集上安裝程式庫:
建立包含您實驗所需套件的
requirements.txt檔案,但請確定其中也包含下列套件:requirements.txt
mlflow azureml-mlflow azure-ai-ml瀏覽至 Azure Analytics 工作區入口網站。
瀏覽至 [管理] 索引標籤,然後選取 [Apache Spark 集區]。
按一下叢集名稱旁的三個點,然後選取 [套件]。

在 [需求檔案] 區段上,按一下 [上傳]。
上傳
requirements.txt檔案。等候您的叢集重新啟動。
使用 MLflow 追蹤實驗
您可以設定 Azure Synapse Analytics,使用連線到 Azure Machine Learning 工作區的 MLflow 來追蹤實驗。 Azure Machine Learning 提供集中式存放庫來管理實驗、模型和部署的整個生命週期。 它也具有使用 Azure Machine Learning 部署選項啟用較簡單部署路徑的優點。
設定筆記本以使用連線到 Azure Machine Learning 的 MLflow
若要使用 Azure Machine Learning 作為實驗的集中式存放庫,您可以利用 MLflow。 在您正在使用的每個筆記本上,您必須設定追蹤 URI 以指向將使用的工作區。 下列範例示範可以如何執行此作業:
設定追蹤 URI
取得工作區的追蹤 URI:
登入和設定您的工作區:
az account set --subscription <subscription> az configure --defaults workspace=<workspace> group=<resource-group> location=<location>您可以使用
az ml workspace命令來取得追蹤 URI:az ml workspace show --query mlflow_tracking_uri
設定追蹤 URI:
然後,此方法
set_tracking_uri()會將 MLflow 追蹤 URI 指向該 URI。import mlflow mlflow.set_tracking_uri(mlflow_tracking_uri)提示
使用共用環境時,例如 Azure Databricks 叢集、Azure Synapse Analytics 叢集或類似環境,最好在叢集層級設定環境變數
MLFLOW_TRACKING_URI,以自動設定 MLflow 追蹤 URI,針對叢集中執行的所有工作階段指向 Azure Machine Learning,而不是針對每個工作階段執行。

設定驗證
設定追蹤之後,您也必須設定如何對相關聯工作區執行驗證。 根據預設,MLflow 的 Azure Machine Learning 外掛程式會開啟預設瀏覽器來提示輸入認證,以執行互動式驗證。 請參閱設定 Azure Machine Learning 的 MLflow:設定驗證為 Azure Machine Learning 工作區中的 MLflow 設定驗證的其他方式。
對於有使用者連線到工作階段的互動式作業,您可以依賴互動式驗證,因此不需要採取進一步的動作。
警告
互動式瀏覽器驗證會在提示輸入認證時,封鎖程式碼執行。 這個方法不適合在自動環境裡進行驗證,例如定型作業。 建議您設定不同的驗證模式。
對於需要自動執行的案例,您必須設定服務主體,以與 Azure Machine Learning 通訊。
import os
os.environ["AZURE_TENANT_ID"] = "<AZURE_TENANT_ID>"
os.environ["AZURE_CLIENT_ID"] = "<AZURE_CLIENT_ID>"
os.environ["AZURE_CLIENT_SECRET"] = "<AZURE_CLIENT_SECRET>"
提示
在共用環境上工作時,我們建議您在計算中設定這些環境變數。 最佳做法是將其作為 Azure Key Vault 執行個體中的祕密加以管理。
例如在 Azure Databricks 中,您可以在環境變數中使用祕密,如下的叢集設定所示:AZURE_CLIENT_SECRET={{secrets/<scope-name>/<secret-name>}}。 如需在 Azure Databricks 中實作此方法的詳細資訊,請參閱 參考環境變數中的秘密 或參考您平台的文件。
Azure Machine Learning 中的實驗名稱
根據預設,Azure Machine Learning 追蹤會在稱為 Default 的預設實驗中執行。 設定您將要進行的實驗通常是個不錯的主意。 使用下列語法來設定實驗的名稱:
mlflow.set_experiment(experiment_name="experiment-name")
追蹤參數、計量和成品
然後,您可以透過慣用的相同方式,在 Azure Synapse Analytics 中使用 MLflow。 如需詳細資料,請參閱記錄和檢視計量與記錄檔。
使用 MLflow 在登錄中註冊模型
您可以在 Azure Machine Learning 工作區中註冊模型,以提供集中式存放庫來管理其生命週期。 下列範例會記錄使用 Spark MLLib 定型的模型,並在登錄中註冊模型。
mlflow.spark.log_model(model,
artifact_path = "model",
registered_model_name = "model_name")
如果具有該名稱的已註冊模型不存在,則此方法會註冊新的模型、建立第 1 版,並傳回 ModelVersion MLflow 物件。
如果具有該名稱的已註冊模型已存在,則此方法會建立新的模型版本,並傳回版本物件。
您可以使用 MLflow 管理 Azure Machine Learning 中已註冊的模型。 如需詳細資料,請檢視使用 MLflow 管理 Azure Machine Learning 中的模型登錄。
部署和取用 Azure Machine Learning 中已註冊的模型
Azure Machine Learning 服務中使用 MLflow 的已註冊模型可用作:
Azure Machine Learning 端點 (即時和批次):此部署可讓您利用 Azure Machine Learning 部署功能,在 Azure 容器執行個體 (ACI)、Azure Kubernetes (AKS) 或受控端點中進行即時和批次推斷。
MLFlow 模型物件或 Pandas UDF,可用於串流或批次管線中的 Azure Synapse Analytics 筆記本。
將模型部署到 Azure Machine Learning 端點
您可以利用 azureml-mlflow 外掛程式,將模型部署到您的 Azure Machine Learning 工作區。 如需如何將模型部署到不同目標的完整詳細資料,請參閱如何部署 MLflow 模型頁面。
重要
模型必須在 Azure Machine Learning 登錄中註冊,才能加以部署。 Azure Machine Learning 不支援部署未註冊的模型。
使用 UDF 部署模型以進行批次計分
您可以選擇用於批次計分的 Azure Synapse Analytics 叢集。 MLFlow 模型會載入並用做 Spark Pandas UDF 來對新資料進行計分。
from pyspark.sql.types import ArrayType, FloatType
model_uri = "runs:/"+last_run_id+ {model_path}
#Create a Spark UDF for the MLFlow model
pyfunc_udf = mlflow.pyfunc.spark_udf(spark, model_uri)
#Load Scoring Data into Spark Dataframe
scoreDf = spark.table({table_name}).where({required_conditions})
#Make Prediction
preds = (scoreDf
.withColumn('target_column_name', pyfunc_udf('Input_column1', 'Input_column2', ' Input_column3', …))
)
display(preds)
清除資源
如果您想要保留 Azure Synapse Analytics 工作區,但不再需要 Azure Machine Learning 工作區,您可以刪除 Azure Machine Learning 工作區。 如果您不打算在工作區使用已記錄的計量和成品,則目前無法個別刪除這些項目。 請改以刪除包含儲存體帳戶和工作區的資源群組,以免產生任何費用:
在 Azure 入口網站中,選取最左邊的 [資源群組]。
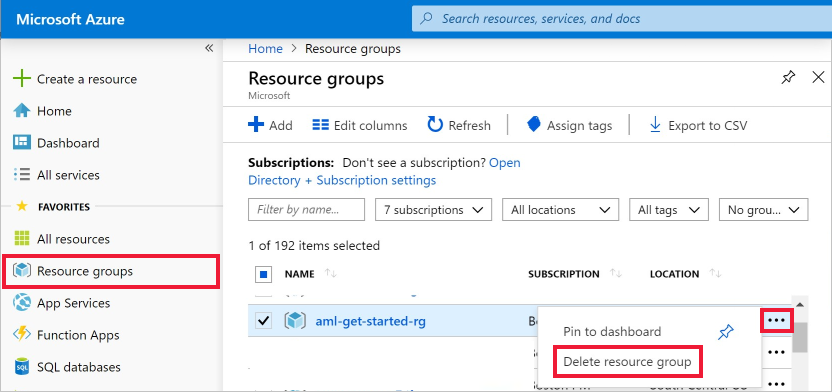
在清單中,選取您所建立的資源群組。
選取 [刪除資源群組]。
輸入資源群組名稱。 接著選取刪除。