針對 Service Fabric 的常見案例進行診斷
本文說明使用者在 Service Fabric 的監視和診斷領域所經常遇到的案例。 所提供的案例涵蓋了服務網狀架構的所有 (共 3 個) 層級:應用程式、叢集和基礎結構。 每個解決方案都使用 Application Insights 和 Azure 監視器記錄 (Azure 監視工具) 來解決每個案例。 每個解決方案中的步驟都會向使用者介紹,如何在 Service Fabric 的範圍內使用 Application Insights 和 Azure 監視器記錄。
先決條件和建議
本文中的解決方案會使用下列工具。 建議您安裝並設定好這些工具:
- Application Insights 搭配 Service Fabric
- 在叢集上啟用 Azure 診斷
- 設定 Log Analytics 工作區
- 用來追蹤效能計數器的 Log Analytics 代理程式
如何查看應用程式中的未處理例外狀況?
瀏覽至用來設定應用程式的 Application Insights 資源。
選取左上方的 [搜尋]。 然後在下一個面板上選取篩選條件。
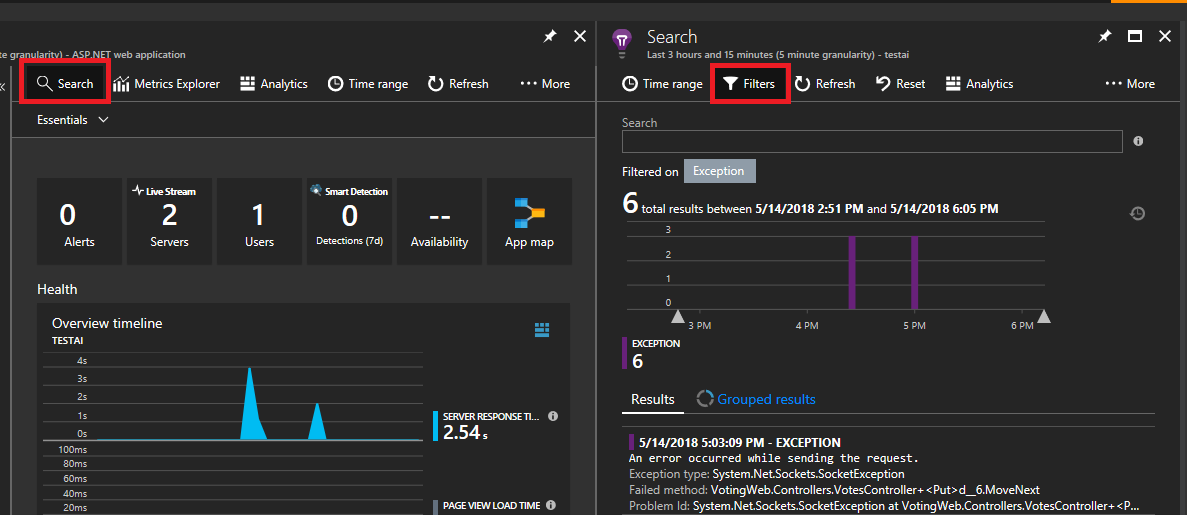
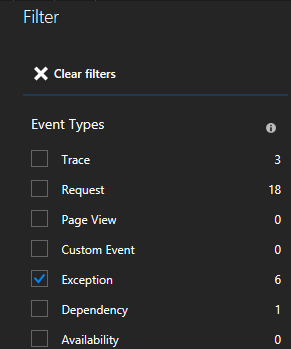
您會看到許多類型的事件 (追蹤、要求、自訂事件)。 選擇 [例外狀況] 作為您的篩選條件。
按一下清單中的例外狀況,即可查看更多詳細資料,包括服務內容 (如果您使用 Service Fabric Application Insights SDK 的話)。

如何檢視服務中所使用的 HTTP 呼叫?
在同一個 Application Insights 資源中,您可以篩選「要求」而非例外狀況,然後檢視所提出的所有要求
如果您使用 Service Fabric Application Insights SDK,您會看到服務彼此連線的視覺呈現,以及已成功和已失敗的要求數目。 在左側,選取 [應用程式對應]


如需應用程式對應的詳細資訊,請瀏覽應用程式對應文件
如何在節點故障時建立警示
Service Fabric 叢集會追蹤節點事件。 請瀏覽至名為 ServiceFabric(NameofResourceGroup) 的 Service Fabric 分析解決方案資源
選取刀鋒視窗底部標題為「摘要」的圖形

這裡有許多圖形和圖格,並顯示各種計量。 對其中一個圖形選取,您就會前往 [記錄搜尋]。 您可以在此查詢任何叢集事件或效能計數器。
輸入下列查詢。 這些事件識別碼位於節點事件參考中
ServiceFabricOperationalEvent | where EventID >= 25622 and EventID <= 25626選取頂端的 [新增警示規則],現在,每當有根據這項查詢的事件抵達時,您就會在所選擇的通訊方法中收到警示。

如何收到應用程式升級復原的警示?
在和前面相同的 [記錄搜尋] 視窗上,輸入下列升級復原查詢。 這些事件識別碼位於應用程式事件參考中
ServiceFabricOperationalEvent | where EventID == 29623 or EventID == 29624選取頂端的 [新增警示規則],現在,每當有根據這項查詢的事件抵達時,您就會收到警示。
如何查看容器計量?
在具有所有圖形的相同檢視中,您會看到一些顯示出容器效能的圖格。 您必須有 Log Analytics 代理程式和容器監視解決方案,這些圖格才會填入資料。

注意
若要從容器內部檢測遙測,您必須新增適用於容器的 Application Insights Nuget 套件。
如何監視效能計數器?
在叢集中新增 Log Analytics 代理程式後,您必須新增所要追蹤的特定效能計數器。請瀏覽至入口網站中的 [Log Analytics 工作區] 頁面 – 從解決方案的頁面來看,[工作區] 索引標籤位於左功能表中。

到達工作區頁面後,在同一個左側功能表中選取 [進階設定]。

選取 [資料] > [Windows 效能計數器] (如果是 Linux 機器,則按一下 [資料] > [Linux 效能計數器]),以透過 Log Analytics 代理程式開始收集節點的特定計數器。 要新增的計數器格式範例如下
.NET CLR Memory(<ProcessNameHere>)\\# Total committed BytesProcessor(_Total)\\% Processor Time在本快速入門中,所使用的程序名稱為 VotingData 和 VotingWeb,因此追蹤這些計數器看起來會像
.NET CLR Memory(VotingData)\\# Total committed Bytes.NET CLR Memory(VotingWeb)\\# Total committed Bytes
這能讓您看到基礎結構處理工作負載的情形,並設定根據資源使用量的相關警示。 例如,您可以設定「如果處理器總使用率高於 90% 或低於 5%」的警示。 對此,您所使用的計數器名稱會是「% Processor Time」。 若要這麼做,您可以對下列查詢建立警示規則:
Perf | where CounterName == "% Processor Time" and InstanceName == "_Total" | where CounterValue >= 90 or CounterValue <= 5.
如何追蹤 Reliable Services 和 Reliable Actors 的效能?
若要追蹤應用程式中的 Reliable Services 或 Reliable Actors 效能,也請新增Service Fabric Actor、Actor Method、Service 和 Service Method 計數器。 以下是要收集的可靠服務和執行者效能計數器範例
注意
Log Analytics 代理程式目前無法收集 Service Fabric 效能計數器,但可以由其他診斷解決方案收集
Service Fabric Service(*)\\Average milliseconds per requestService Fabric Service Method(*)\\Invocations/SecService Fabric Actor(*)\\Average milliseconds per requestService Fabric Actor Method(*)\\Invocations/Sec
如需 Reliable Services 和 Actors 效能計數器的完整清單,請查看這些連結
下一步
- 查詢常見的程式碼套件啟用錯誤
- 在 AI 中設定警示以收到效能或使用方式的變更通知
- Application Insights 的智慧偵測會對傳送至 AI 的遙測資料執行主動式分析,對可能的效能問題提出警告。
- 深入了解 Azure 監視器記錄警示,以協助偵測和診斷。
- 針對內部部署叢集,Azure 監視器記錄提供閘道 (HTTP 正向 Proxy),可用於將資料傳送至 Azure 監視器記錄。 如需詳細資訊,請參閱使用 Log Analytics 閘道將未連上網際網路的電腦連線到 Azure 監視器記錄
- 熟悉 Azure 監視器記錄中提供的記錄搜尋和查詢功能
- 若要更深入了解 Azure 監視器記錄及其提供的功能,請參閱 什麼是 Azure 監視器記錄? (部分機器翻譯)