藉由瞭解 Blob 和容器如何儲存、組織及用於實際執行環境,您可以進一步在成本和效能之間取得最合適的取捨。
本教學課程會說明如何產生和呈現統計資料,例如一段時間的資料成長、一段時間內新增的資料、修改的檔案數目、Blob 快照集大小、每個層的存取模式,以及資料目前和經過一段時間的分佈方式 (例如:多個層、檔案類型、容器內和 Blob 類型中的資料)。
在本教學課程中,您會了解如何:
- 產生 Blob 清查報表
- 設定 Synapse 工作區
- 設定 Synapse Studio
- 在 Synapse Studio 中產生分析資料
- 在 Power BI 中將結果視覺化
必要條件
Azure 訂用帳戶:免費建立帳戶
Azure 儲存體帳戶:建立儲存體帳戶
確定您已對使用者身分識別指派儲存體 Blob 資料參與者角色。
產生詳細目錄報告
啟用儲存體帳戶的 Blob 詳細目錄報告。 請參閱啟用 Azure 儲存體 Blob 清查報表。
為您的第一份報表啟用清查報表之後,您可能必須等待最多 24 小時才會產生報表。
設定 Synapse 工作區
建立 Azure Synapse 工作區。 請參閱建立 Azure Synapse 工作區。
注意
在建立工作區時,您將建立具有階層命名空間的儲存體帳戶。 Azure Synapse 會將 Spark 資料表和應用程式記錄檔儲存到此帳戶。 Azure Synapse 會將此帳戶稱為主要儲存體帳戶。 為了避免混淆,本文會使用清查報表帳戶一詞來指涉包含清查報表的帳戶。
在 Synapse 工作區中,將參與者角色指派給使用者身分識別。 請參閱 Azure RBAC:工作區的擁有者角色。
瀏覽您的清查報表帳戶,然後將儲存體 Blob 資料參與者角色指派給工作區的系統受控識別,授與 Synapse 工作區存取儲存體帳戶中清查報表的權限。 請參閱使用 Azure 入口網站指派 Azure 角色。
瀏覽主要儲存體帳戶,並將 Blob 儲存體參與者角色指派給您的使用者身分識別。
設定 Synapse Studio
在 Synapse Studio 中開啟您的 Synapse 工作區。 請參閱開啟 Synapse Studio。
在 Synapse Studio 中,確定您的身分識別已被指派 Synapse 管理員的角色。 請參閱 Synapse RBAC:工作區的 Synapse 管理員角色。
建立 Apache Spark 集區。 請參閱建立無伺服器 Apache Spark 集區。
設定及執行範例筆記本
在本節中,您將產生統計資料,在報表中呈現。 為了簡化本教學課程,本節使用範例組態檔和範例 PySpark 筆記本。 筆記本包含 Azure Synapse Studio 中執行的查詢集合。
修改和上傳範例組態檔
更新該檔案的下列預留位置:
將
storageAccountName設定為您清查報表帳戶的名稱。將
destinationContainer設定為保留清查報表的容器名稱。將
blobInventoryRuleName設定為已產生您要分析之結果的清查報表規則名稱。將
accessKey設定為清查報表帳戶的帳戶金鑰。
針對您在建立 Synapse 工作區時指定的主要儲存體帳戶,將此檔案上傳至其中的容器。
匯入範例 PySpark 筆記本
下載 ReportAnalysis.ipynb 範例筆記本。
注意
請務必使用
.ipynb附檔名來儲存此檔案。在 Synapse Studio 中開啟您的 Synapse 工作區。 請參閱開啟 Synapse Studio。
在 Synapse Studio 中,選取 [開發] 分頁。
選取加號 (+) 來新增項目。
選取 [匯入]、瀏覽至您下載的範例檔案、選取該檔案,然後選取 [開啟]。
[屬性] 對話方塊隨即顯示。
在 [屬性] 對話方塊中,選取 [設定工作階段] 連結。
![[匯入屬性] 對話方塊的螢幕擷取畫面](media/storage-blob-inventory-report-analytics/import-properties-dialog-box.png)
[設定工作階段] 對話方塊隨即開啟。
在 [設定工作階段] 對話方塊的 [附加至] 下拉式清單中,選取您稍早在本文中建立的 Spark 集區。 然後,選取 [套用] 按鈕。
修改 Python 筆記本
在 Python 筆記本的第一個儲存格中,將
storage_account變數的值設定為主要儲存體帳戶的名稱。將
container_name變數的值更新為您建立 Synapse 工作區時所指定帳戶中的容器名稱。選取 [發佈] 按鈕。
執行 PySpark 筆記本
在 PySpark 筆記本中,選取 [全部執行]。
啟動 Spark 工作階段需要幾分鐘的時間,處理清查報表也需要幾分鐘。 如果有許多要處理的清查報表,則第一次執行可能需要一段時間。 後續執行只會處理自上次執行後建立的新清查報表。
注意
如果您在筆記本執行時,對筆記本進行任何變更,請務必使用 [發佈] 按鈕來發佈這些變更。
選取 [資料] 分頁,確認筆記本已成功執行。
名為 [reportdata] 的資料庫應該會出現在 [資料] 窗格的 [工作區] 分頁中。 如果此資料庫並未出現,您可能必須重新整理網頁。
![[資料] 窗格的螢幕擷取畫面,其中顯示 reportdata 資料庫](media/storage-blob-inventory-report-analytics/report-data-database.png)
資料庫包含一組資料表。 每個資料表都包含從 PySpark 筆記本執行查詢所取得的資訊。
若要檢查資料表的內容,請展開 [reportdata] 資料庫的 [資料表] 資料夾。 然後,以滑鼠右鍵按一下資料表,選取 [選取 SQL 指令碼],然後選取 [選取前 100 個資料列]。
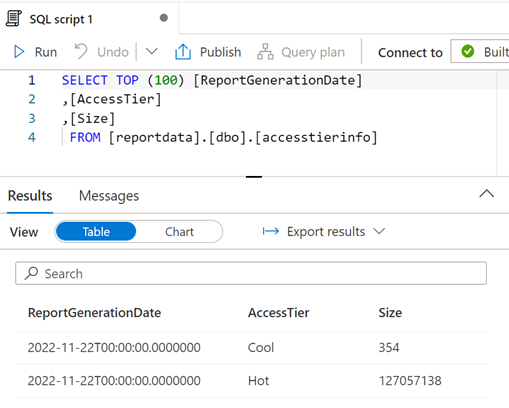
您可以視需要修改查詢,然後選取 [執行],以檢視結果。
將資料視覺化
下載 ReportAnalysis.pbit 範例報表檔案。
開啟 Power BI Desktop。 如需安裝指引,請參閱取得 Power BI Desktop。
在 Power BI 中,選取 [檔案]、[開啟報表],以及 [瀏覽報表]。
在 [開啟] 對話方塊中,將檔類型變更為 [Power BI 範本檔案 (*.pbit)]。
![顯示在 [開啟] 對話方塊中的 Power BI 範本檔案類型螢幕擷取畫面](media/storage-blob-inventory-report-analytics/file-type-setting.png)
瀏覽至您下載 ReportAnalysis.pbit 檔案的位置,然後選取 [開啟]。
對話方塊隨即顯示,要求您提供 Synapse 工作區的名稱和資料庫名稱。
在對話方塊中,將 [synapse_workspace_name] 欄位設定為工作區名稱,並將 [database_name] 欄位設定為
reportdata。 然後,選取 [載入] 按鈕。![[報告設定] 對話方塊的螢幕擷取畫面](media/storage-blob-inventory-report-analytics/report-configuration-dialog-box.png)
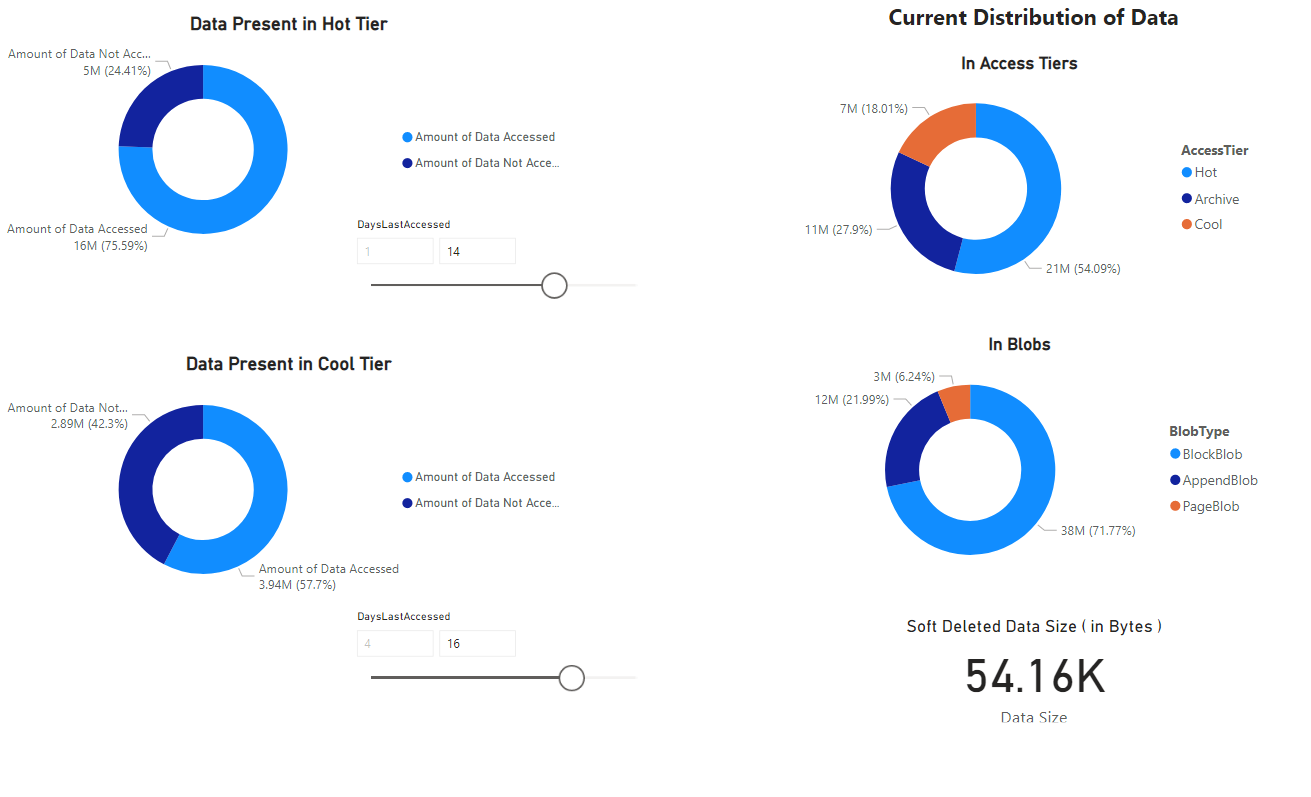
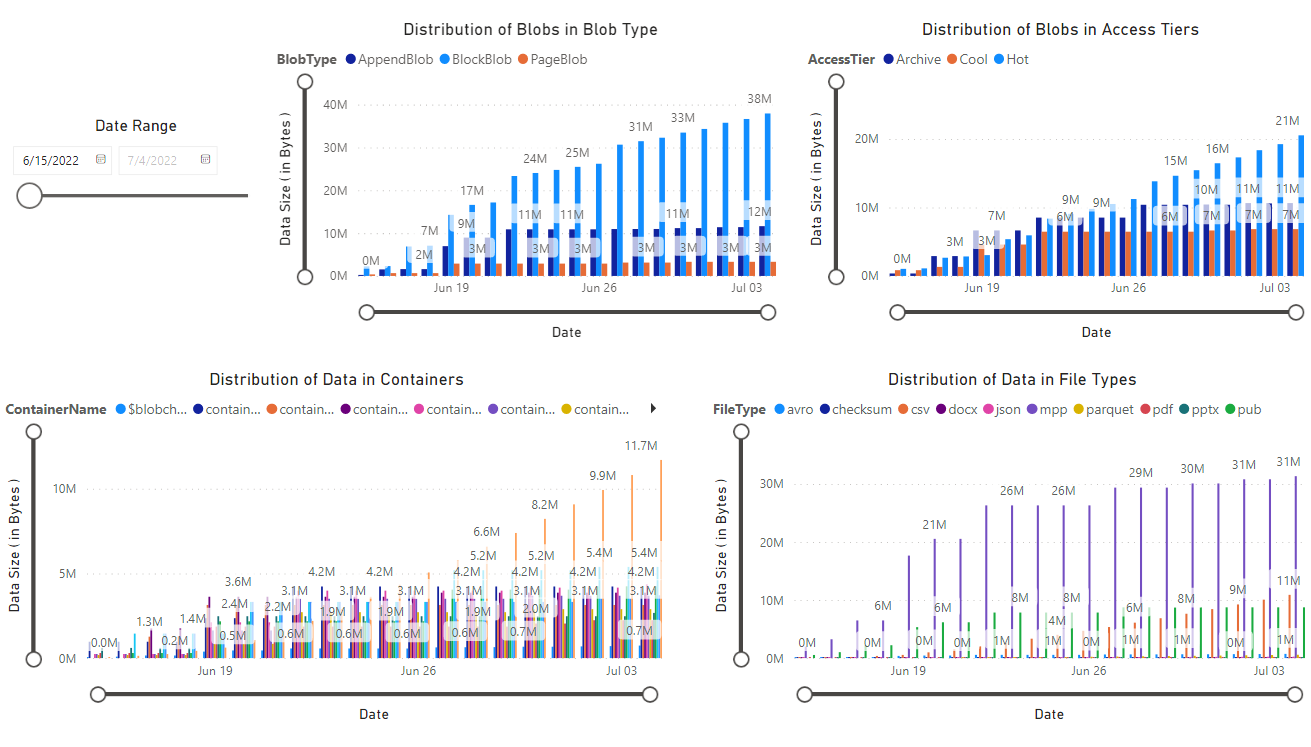
報表隨即出現,提供筆記本所擷取的資料呈現。 下列圖片會顯示此報表中出現的圖表和圖形類型。
![報告 [概觀] 索引標籤的螢幕擷取畫面](media/storage-blob-inventory-report-analytics/power-bi-report-overview.png)
下一步
設定 Azure Synapse 管線,以定期持續執行筆記本。 如此一來,您就可以在建立新的清查報表時進行處理。 初始執行之後,後續每個回合會分析累加資料,然後使用該分析的結果來更新資料表。 如需指引,請參閱與管線整合。
瞭解如何分析儲存體帳戶中的個別容器。 請參閱以下文章:
瞭解如何根據 Blob 和容器的分析來最佳化成本。 請參閱以下文章: