本教學課程說明如何使用 Azure Blob 儲存體詳細目錄和 Azure Databricks 來收集容器的相關統計資料。
在本教學課程中,您會了解如何:
- 產生詳細目錄報告
- 建立 Azure Databricks 工作區和筆記本
- 讀取 Blob 詳細目錄檔案
- 取得 Blob、快照集和版本的數目和大小總計
- 依 Blob 類型和內容類型取得 Blob 數目
必要條件
Azure 訂用帳戶:免費建立帳戶
Azure 儲存體帳戶:建立儲存體帳戶
確定您已對使用者身分識別指派儲存體 Blob 資料參與者角色。
產生詳細目錄報告
啟用儲存體帳戶的 Blob 詳細目錄報告。 請參閱啟用 Azure 儲存體 Blob 詳細目錄報告。
使用下列組態設定:
| 設定 | 值 |
|---|---|
| 規則名稱 | blobinventory |
| 容器 | <容器的名稱> |
| 要清查的物件類型 | Blob |
| Blob 類型 | 區塊 Blob、分頁 Blob 及附加 Blob |
| 子類型 | 包含 Blob 版本、包含快照集、包含已刪除的 Blob |
| Blob 詳細目錄欄位 | 全部 |
| 清查頻率 | 每日 |
| 匯出格式 | CSV |
為您的第一份報告啟用詳細目錄報告之後,您可能必須等待最多 24 小時才會產生報告。
Azure Databricks
在本節中,您會建立 Azure Databricks 工作區和筆記本。 在本教學課程稍後,您會將程式碼片段貼到筆記本資料格中,然後執行它們來收集容器統計資料。
建立 Azure Databricks 工作區。 請參閱建立 Azure Databricks 工作區。
建立新的筆記本。 請參閱建立筆記本。
選擇 Python 做為筆記本的預設語言。
讀取 Blob 詳細目錄檔案
將下列程式碼區塊複製並貼到第一個資料格中,但先不要執行此程式碼。
from pyspark.sql.types import StructType, StructField, IntegerType, StringType import pyspark.sql.functions as F storage_account_name = "<storage-account-name>" storage_account_key = "<storage-account-key>" container = "<container-name>" blob_inventory_file = "<blob-inventory-file-name>" hierarchial_namespace_enabled = False if hierarchial_namespace_enabled == False: spark.conf.set("fs.azure.account.key.{0}.blob.core.windows.net".format(storage_account_name), storage_account_key) df = spark.read.csv("wasbs://{0}@{1}.blob.core.windows.net/{2}".format(container, storage_account_name, blob_inventory_file), header='true', inferSchema='true') else: spark.conf.set("fs.azure.account.key.{0}.dfs.core.windows.net".format(storage_account_name), storage_account_key) df = spark.read.csv("abfss://{0}@{1}.dfs.core.windows.net/{2}".format(container, storage_account_name, blob_inventory_file), header='true', inferSchema='true')在此程式碼區塊中,取代下列值:
使用您的儲存體帳戶名稱取代
<storage-account-name>預留位置值。使用您儲存體帳戶的帳戶金鑰取代
<storage-account-key>預留位置值。將
<container-name>預留位置值取代為保留詳細目錄報告的容器。將
<blob-inventory-file-name>預留位置取代為詳細目錄檔案的完整名稱 (例如:2023/02/02/02-16-17/blobinventory/blobinventory_1000000_0.csv)。如果您的帳戶有階層命名空間,請將
hierarchical_namespace_enabled變數設為True。
按 [執行] 按鈕以執行此儲存格中的程式碼。
取得 Blob 計數和大小
在新的資料格中貼上下列程式碼:
print("Number of blobs in the container:", df.count()) print("Number of bytes occupied by blobs in the container:", df.agg({'Content-Length': 'sum'}).first()['sum(Content-Length)'])按 [執行] 按鈕以執行儲存格。
筆記本會顯示容器中的 Blob 數目,以及容器中 Blob 所佔用的位元組數目。

取得快照集計數和大小
在新的資料格中貼上下列程式碼:
from pyspark.sql.functions import * print("Number of snapshots in the container:", df.where(~(col("Snapshot")).like("Null")).count()) dfT = df.where(~(col("Snapshot")).like("Null")) print("Number of bytes occupied by snapshots in the container:", dfT.agg({'Content-Length': 'sum'}).first()['sum(Content-Length)'])按 [執行] 按鈕以執行儲存格。
筆記本會顯示 Blob 快照集所佔用的快照集數目和位元組總數。

取得版本計數和大小
在新的資料格中貼上下列程式碼:
from pyspark.sql.functions import * print("Number of versions in the container:", df.where(~(col("VersionId")).like("Null")).count()) dfT = df.where(~(col("VersionId")).like("Null")) print("Number of bytes occupied by versions in the container:", dfT.agg({'Content-Length': 'sum'}).first()['sum(Content-Length)'])按 SHIFT + ENTER 以執行資料格。
筆記本會顯示 Blob 版本所佔用的 Blob 版本數目和位元組總數。

依 Blob 類型取得 Blob 計數
在新的資料格中貼上下列程式碼:
display(df.groupBy('BlobType').count().withColumnRenamed("count", "Total number of blobs in the container by BlobType"))按 SHIFT + ENTER 以執行資料格。
筆記本會依類型顯示 Blob 類型的數目。

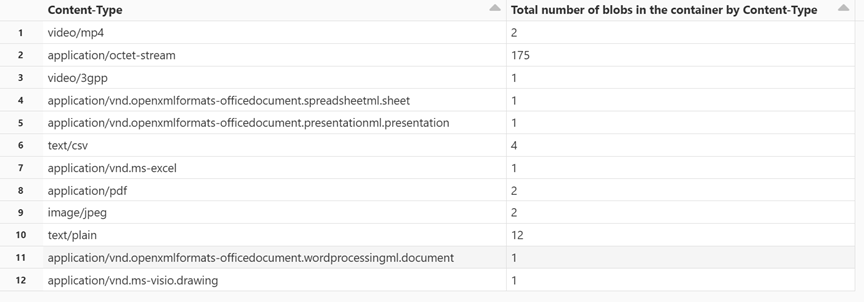
依內容類型取得 Blob 計數
在新的資料格中貼上下列程式碼:
display(df.groupBy('Content-Type').count().withColumnRenamed("count", "Total number of blobs in the container by Content-Type"))按 SHIFT + ENTER 以執行資料格。
筆記本會顯示與每個內容類型相關聯的 Blob 數目。
終止叢集
若要避免不必要的計費,請終止計算資源。 請參閱 終止計算。
下一步
瞭解如何使用 Azure Synapse 來計算每個容器的 Blob 計數和 Blob 總大小。 請參閱使用 Azure 儲存體詳細目錄來計算 Blob 計數和每個容器的大小總計
瞭解如何產生統計資料和以視覺化呈現描述容器和 Blob 的那些資料。 請參閱教學課程:分析 Blob 詳細目錄報告
瞭解如何根據 Blob 和容器的分析來最佳化成本。 請參閱以下文章: