Azure 串流分析支援使用自訂欄位或屬性和自定義 DateTime 路徑模式的自訂 Blob 輸出分割。
自訂欄位或屬性
自訂欄位或輸入屬性透過允許更充分掌控輸出,來改進下游資料處理和報告工作流程。
分割鍵選項
用來分割輸入數據的數據分割索引鍵或數據行名稱可能包含 Blob 名稱所接受的任何字元。 除非巢狀欄位與別名一起使用,否則無法使用巢狀字段做為分割區索引鍵。 不過,您可以使用特定字元來建立檔案階層。 例如,若要建立一個結合其他兩列資料以形成唯一分區鍵的資料列,您可以使用下列查詢:
SELECT name, id, CONCAT(name, "/", id) AS nameid
分割區索引鍵必須是 NVARCHAR(MAX)、 BIGINT、 FLOAT或 BIT (1.2 兼容性層級或更高版本)。
DateTime不支援、 Array和 Records 類型,但如果它們轉換成字串,就可以當做分割區索引鍵使用。 如需詳細資訊,請參閱 Azure 串流分析數據類型。
範例
假設工作從連線到外部影片遊戲服務的即時使用者工作階段接收輸入資料,且其中內嵌的資料包含一個資料行client_id,可識別工作階段。 若要依 client_id分割數據,請在建立作業時,將 [Blob 路徑模式 ] 字段設定為在 Blob 輸出屬性中包含分割區令牌 {client_id} 。 當具有各種 client_id 值的數據流經串流分析作業時,輸出數據會根據每個資料夾的單 client_id 一值儲存到個別的資料夾。

同樣地,如果作業輸入是來自數百萬個感測器的感測器數據,其中每個感測器都有 sensor_id,則路徑模式會是 {sensor_id} 將每個感測器數據分割至不同的資料夾。
當您使用 REST API 時,用於該要求的 JSON 檔案輸出區段看起來可能如下圖所示:

作業開始執行之後, clients 容器看起來可能如下所示:

每個資料夾可能包含多個 Blob,其中每個 Blob 都包含一或多個記錄。 在上述範例中,資料夾中有一個 Blob,其標籤 "06000000" 有下列內容:

請注意,Blob 中的每個記錄都有一個與資料夾名稱相符的 client_id 資料欄,因為用來分割輸出路徑的資料欄是 client_id。
限制
路徑模式 Blob 輸出屬性中僅允許一個自定義分割區鍵。 下列所有路徑模式都有效:
cluster1/{date}/{aFieldInMyData}cluster1/{time}/{aFieldInMyData}cluster1/{aFieldInMyData}cluster1/{date}/{time}/{aFieldInMyData}
如果客戶想要使用多個輸入欄位,則可以使用
CONCAT,在查詢 Blob 輸出中的自訂路徑分割區時建立複合索引鍵。 例如select concat (col1, col2) as compositeColumn into blobOutput from input。 然後,他們可以在 Azure Blob 儲存體 中指定compositeColumn為自定義路徑。分割區索引鍵不區分大小寫,因此
John和john之類的分割區索引鍵是相等的。 此外,運算式不能用作分割區索引鍵。 例如,{columnA + columnB}無法運作。當輸入數據流包含數據分割索引鍵基數低於 8,000 的記錄時,記錄會附加至現有的 Blob。 它們只會在必要時建立新的 Blob。 如果基數超過8,000,則不保證會寫入現有的 Blob。 不會針對具有相同分割區索引鍵的任意數目記錄建立新的 Blob。
如果 Blob 輸出設定為不可變,串流分析會在每次傳送資料時建立新的 Blob。
自訂日期時間路徑模式
自定義 DateTime 路徑模式可讓您指定與Hive串流慣例一致的輸出格式,讓串流分析能夠將數據傳送至 Azure HDInsight 和 Azure Databricks 以進行下游處理。 您可以在 Blob 輸出的 路徑前綴 欄位中使用 datetime 關鍵詞和格式規範,輕鬆實作自定義 DateTime 路徑模式。 例如 {datetime:yyyy}。
支援的代幣
下列格式規範標記可以單獨或結合使用,以達到自定義 DateTime 格式。
| 格式指定符 | 描述 | 範例時間 2018-01-02T10:06:08 的結果 |
|---|---|---|
| {datetime:yyyy} | 四位數的年份 | 2018 |
| {datetime:MM} | 從 01 到 12 的月份 | 01 |
| {datetime:M} | 從 1 到 12 的月份 | 1 |
| {datetime:dd} | 從 01 到 31 的日期 | 02 |
| {datetime:d} | 從 1 到 31 的日期 | 2 |
| {datetime:HH} | 使用 24 小時格式的小時,從 00 到 23 | 10 |
| {datetime:mm} | 從 00 到 60 的分鐘數 | 06 |
| {datetime:m} | 從 0 到 60 的分鐘數 | 6 |
| {datetime:ss} | 從 00 到 60 的秒數 | 08 |
如果您不想使用自定義DateTime模式,您可以將{date}和/或{time}標記新增至路徑前置詞欄位,以產生內建DateTime格式的下拉式清單。

擴充性及限制
您可以在路徑模式中使用任意數量的令牌({datetime:<specifier>}),直到達到路徑前綴字元限制為止。 格式指定符不能在超出日期和時間下拉式選單中所列出之組合範圍外的單一權杖中合併。
針對logs/MM/dd的路徑分割區:
| 有效運算式 | 無效運算式 |
|---|---|
logs/{datetime:MM}/{datetime:dd} |
logs/{datetime:MM/dd} |
您可以在路徑前置詞中多次使用相同的格式規範。 權杖必須每次都重複。
Hive 串流規範
Blob 記憶體的自定義路徑模式可以搭配Hive串流慣例使用,其預期資料夾名稱中會加上 column= 標籤。
例如 year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}/hour={datetime:HH}。
自訂輸出消除了更改數據表和手動新增分割區以在 Stream Analytics 與 Hive 之間傳輸數據的麻煩。 相反地,您可以使用以下方法,自動新增許多資料夾:
MSCK REPAIR TABLE while hive.exec.dynamic.partition true
範例
按照串流分析 Azure 入口網站快速入門,建立儲存體帳戶、資源群組、串流分析工作和輸入來源。 請使用與快速入門中相同的範例數據。 GitHub 中也提供範例數據。
以下列設定建立 blob 輸出匯入端:

完整路徑模式為:
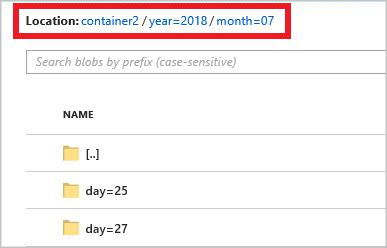
year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}
當您啟動作業時,以路徑模式為基礎的資料夾結構會在 Blob 容器中建立。 您可以向下切入至日層級。