快速入門:用於健康醫療領域的自訂文字分析
使用本文開始建立用於健康醫療領域的自訂文字分析專案,您可以在健康醫療領域文字分析的基礎上為自訂模型定型,以進行自訂實體辨識。 模型是經過定型以執行特定工作的人工智慧軟體。 在此系統中,模型會擷取與健康醫療相關的具名實體,並從已標記的資料中學習以進行定型。
在本文中,我們會使用 Language Studio 來示範用於健康醫療領域的自訂文字分析的重要概念。 例如,我們將建置用於健康醫療領域的自訂文字分析模型,以從簡短的出院記錄中擷取設施或治療地點。
必要條件
- Azure 訂用帳戶 - 免費建立一個訂用帳戶
建立新的 Azure AI 語言資源和 Azure 儲存體帳戶
在您能使用用於健康醫療領域的自訂文字分析之前,您必須建立 Azure AI 語言資源,以提供建立專案和開始將模型定型所需的認證。 您也需要有 Azure 儲存體帳戶,然後在此帳戶上傳用來建置模型的資料集。
重要
若要快速開始使用,建議您使用本文中提供的步驟來建立新的 Azure AI 語言資源。 使用本文中的步驟,可讓您同時建立語言資源和記憶體帳戶,這比稍後執行更容易。
如果您有想要使用的現有資源,則必須將它連線到記憶體帳戶。 如需詳細資訊,請參閱關於使用既有資源的指引 (部分機器翻譯)。
從 Azure 入口網站 建立新的資源
登入 Azure 入口網站以建立新的 Azure AI 語言資源。
在出現的視窗中,從自定義功能選取 [自定義文字分類與自定義具名實體辨識 ]。 選取畫面底部的 [繼續建立您的資源]。
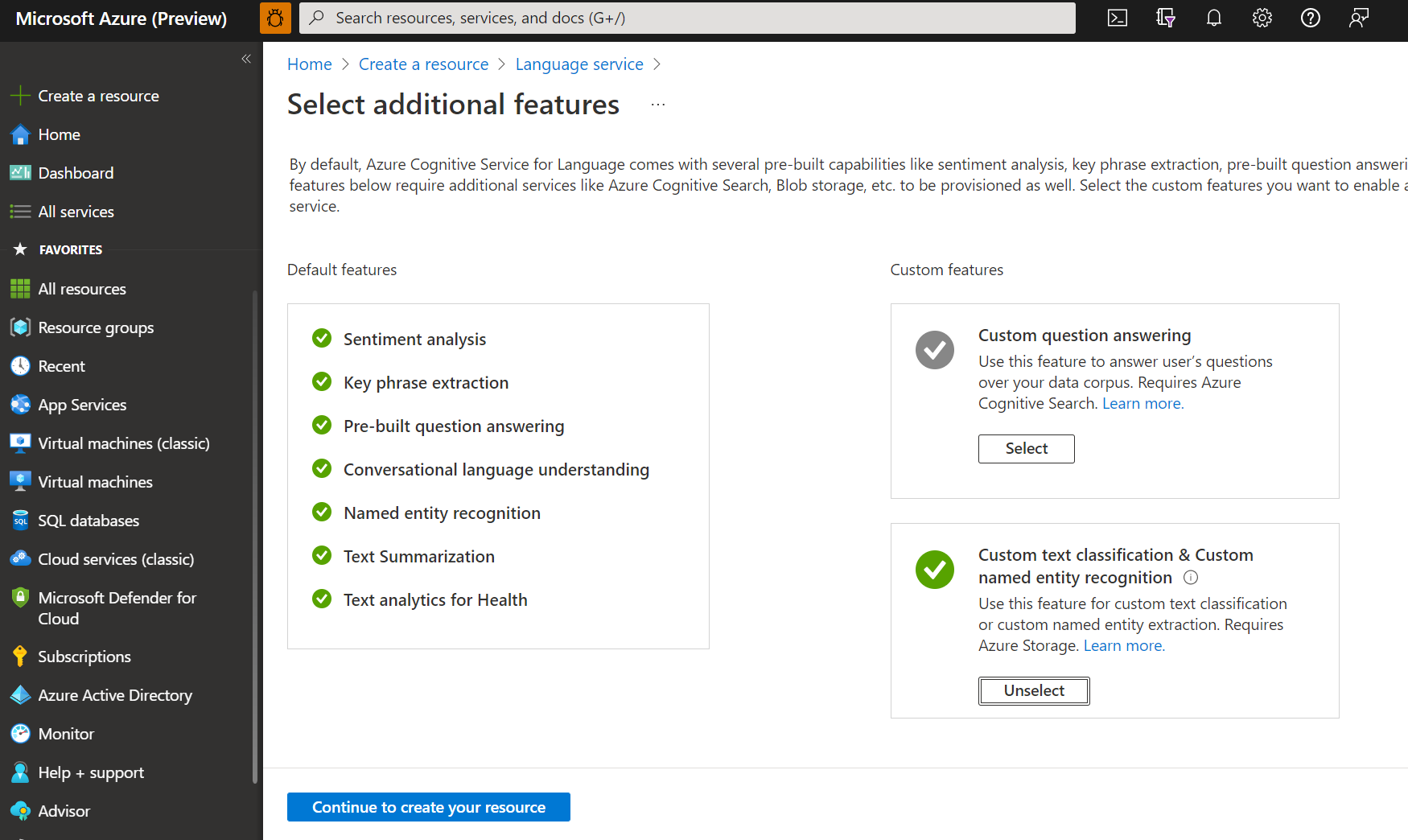
使用下列詳細數據建立語言資源。
名稱 描述 訂用帳戶 您的 Azure 訂閱。 資源群組 將包含您資源的資源群組。 您可以使用現有的 ,或建立新的。 區域 語言資源的區域。 例如,「美國西部 2」。 名稱 資源的名稱。 定價層 語言資源的定價層。 您可以使用免費 (F0) 層來嘗試服務。 注意
如果您收到一則訊息,指出「您的登入帳戶不是所選記憶體帳戶資源群組的擁有者」,您的帳戶必須先在資源群組上指派擁有者角色,才能建立語言資源。 請連絡您的 Azure 訂用帳戶擁有者以取得協助。
在 [ 自定義文字分類與自定義具名實體辨識 ] 區段中,選取現有的記憶體帳戶,或選取 [ 新增記憶體帳戶]。 這些值可協助您開始使用,而不一定 是您想要在生產環境中使用的記憶體帳戶值 。 若要避免在建置項目時延遲,請連線到與語言資源位於相同區域中的記憶體帳戶。
儲存體 帳戶值 建議值 儲存體帳戶名稱 任何名稱 Storage account type 標準 LRS 請確定 已核取負責任 AI 通知 。 選取頁面底部的 [ 檢閱 + 建立 ],然後選取 [ 建立]。

將範例數據上傳至 Blob 容器
建立 Azure 記憶體帳戶並將其連線到您的語言資源之後,您必須將檔從範例數據集上傳至容器的根目錄。 這些檔稍後將用來定型模型。
開啟 .zip 檔案,並解壓縮包含文件的資料夾。
在 Azure 入口網站 中,流覽至您所建立的記憶體帳戶,然後加以選取。
在您的儲存體帳戶中,從左側功能表中 [資料儲存體] 的下方選取 [容器]。 在出現的畫面中,選取 [+ 容器]。 提供容器名稱 example-data ,並保留預設 的公用存取層級。
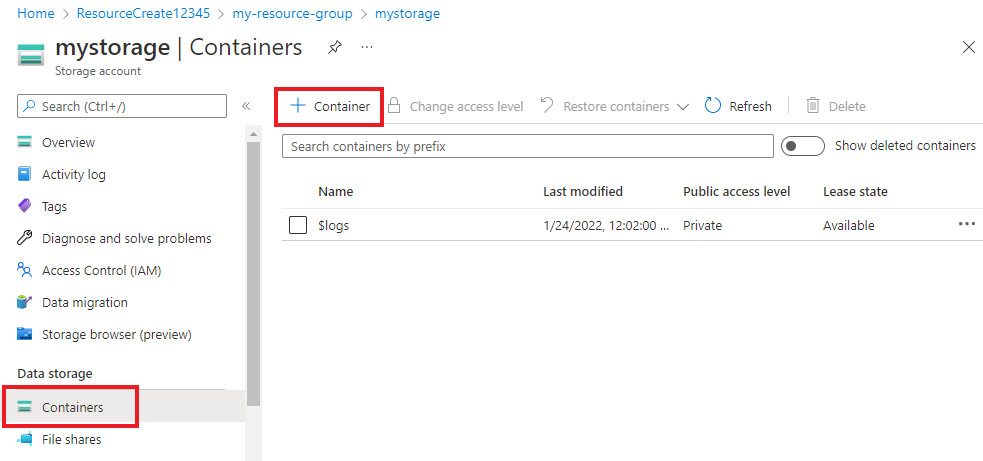
建立容器之後,請加以選取。 然後選取 [上傳] 按鈕,以選取您稍早下載的
.txt和.json檔案。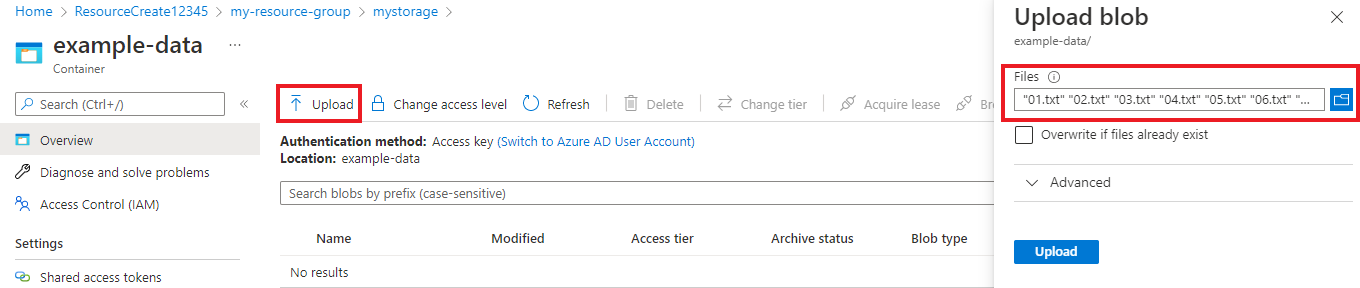


提供的範例資料集包含 12 份臨床記錄。 每份臨床記錄都包含數個醫療實體和治療地點。 我們將使用預先建置的實體來擷取醫療實體,並訓練自訂模型使用該實體的已學習和清單元件來擷取治療位置。
建立用於健康醫療領域的自訂文字分析專案
設定了資源和儲存體帳戶之後,請建立新的「用於健康醫療領域的自訂文字分析」專案。 專案是一個工作區域,可根據您的數據建置自定義ML模型。 您的專案只能由您和其他人存取所使用之語言資源。
登入 Language Studio。 隨即會出現一個視窗,讓您選取您的訂用帳戶和語言資源。 選取您在上述步驟中建立的語言資源。
在 Language Studio 的 [擷取資訊] 區段下,選取 [用於健康醫療領域的自訂文字分析]。
從項目頁面的頂端功能表中選取 [建立新專案 ]。 建立專案可讓您標示資料、定型、評估、改善以及部署模型。

輸入項目資訊,包括專案中檔案的名稱、描述和語言。 如果您使用 範例數據集,請選取 [英文]。 您之後無法變更專案名稱。 選取下一個
提示
您的數據集不需要完全使用相同的語言。 您可以有多個檔,每個檔都有不同的支持語言。 如果您的資料集包含不同語言的檔,或當您在運行時間預期來自不同語言的文字時,請在輸入專案的基本資訊時選取 [啟用多語系數據集 ] 選項。 此選項稍後可從 [項目設定] 頁面啟用。
選取 [建立新專案] 之後,隨即會出現一個視窗,讓您連線您的儲存體帳戶。 如果您已連線記憶體帳戶,您會看到已連線的記憶體帳戶。 如果沒有,請從出現的下拉式清單中選擇儲存體帳戶,然後選取 [連線儲存體帳戶];這會為您的儲存體帳戶設定必要角色。 如果您未在記憶體帳戶上指派為 擁有者 ,此步驟可能會傳回錯誤。
注意
- 您只需要針對您使用的每個新資源執行此步驟一次。
- 如果您將記憶體帳戶連線到您的語言資源,稍後就無法中斷連線,此程式將無法復原。
- 您只能將語言資源連線到一個記憶體帳戶。
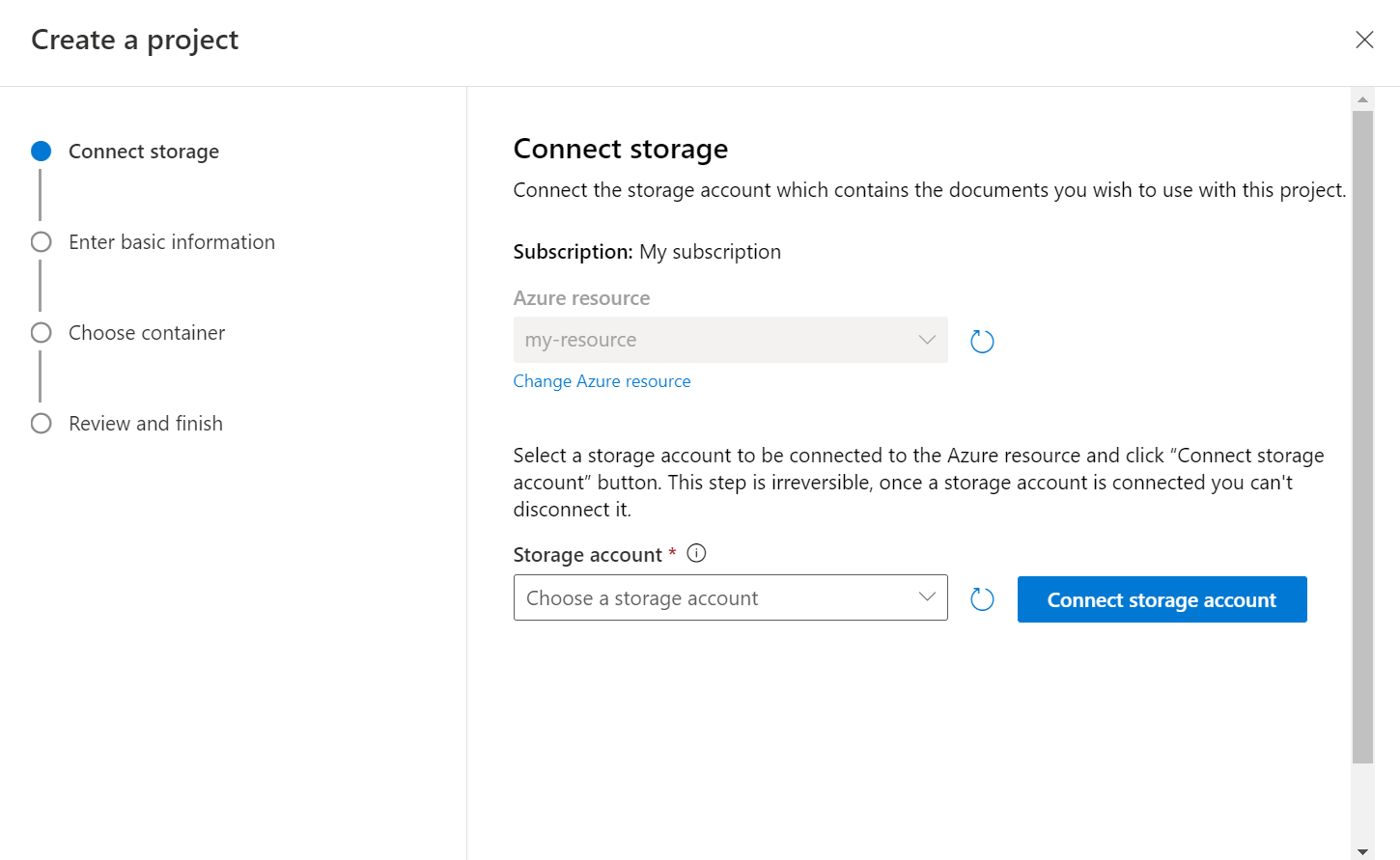
選取您已上傳數據集的容器。
如果您已經標示資料,請確定其遵循支援的格式,然後選取 [是,我的檔案已加上標籤,而且我已設定 JSON 標籤檔案的格式],然後從下拉式功能表中選取標籤檔案。 選取 [下一步]。 如果您使用快速入門中的資料集,則不需要檢閱 JSON 標籤檔案的格式設定。
檢閱您輸入的數據,然後選取 [ 建立專案]。


定型您的模型
一般而言,在您建立項目之後,請繼續開始標記您在容器中已連線至專案的檔。 在本快速入門中,您已匯入範例標記資料集,並使用範例 JSON 標籤檔案將專案初始化,因此不需要新增其他標籤。
若要從 Language Studio 內開始訓練您的模型:
從左側功能表中選取 [訓練作業 ]。
從頂端功能表中選取 [啟動訓練作業 ]。
選取 [定型新的模型 ],然後在文本框中輸入模型名稱。 您也可以 選取此選項並選擇您想要從下拉功能表覆寫的模型,以覆寫現有的模型 。 覆寫已定型的模型是不可復原的,但在您部署新模型之前,不會影響已部署的模型。
選取數據分割方法。 您可以選擇 [從定型數據 自動分割測試集],其中系統會根據指定的百分比,在定型集與測試集之間分割已標記的數據。 或者,您可以使用手動分割定型和測試資料,此選項只有在已將文件新增至測試集時才會啟用。 如需資料分割的相關資訊,請參閱資料標記 (部分機器翻譯) 以及如何將模型定型 (部分機器翻譯)。
選取 [ 訓練] 按鈕。
如果您從清單中選取 [定型作業識別碼],則會顯示側邊窗格,您可以在其中檢查此作業的 [定型進度]、[作業狀態] 和其他詳細資料。
注意
- 只有成功完成的定型作業才會產生模型。
- 訓練可能需要幾分鐘到數小時的時間,視卷標的資料大小而定。
- 您一次只能執行一個定型作業。 除非執行中的作業完成,否則無法在同一個專案內啟動其他定型作業。

部署模型
一般來說,在定型模型之後,您可以檢閱其評估詳細資料,並視需要加以改善。 在本快速入門中,您只會部署模型,並讓它可供您在 Language Studio 中試用,或者您可以呼叫 預測 API。
若要從 Language Studio 內部署模型:
從左側功能表中選取 [部署模型 ]。
選取 [新增部署] 以啟動新的部署作業。
選取 [建立新的部署] 以建立新的部署 ,並從下方的下拉式清單中指派定型的模型。 您也可以 選取此選項,然後從下列下拉式清單中選取要指派給它的定型模型,以覆寫現有的部署 。
注意
覆寫現有的部署不需要變更預測 API 呼叫,但您取得的結果會以新指派的模型為基礎。
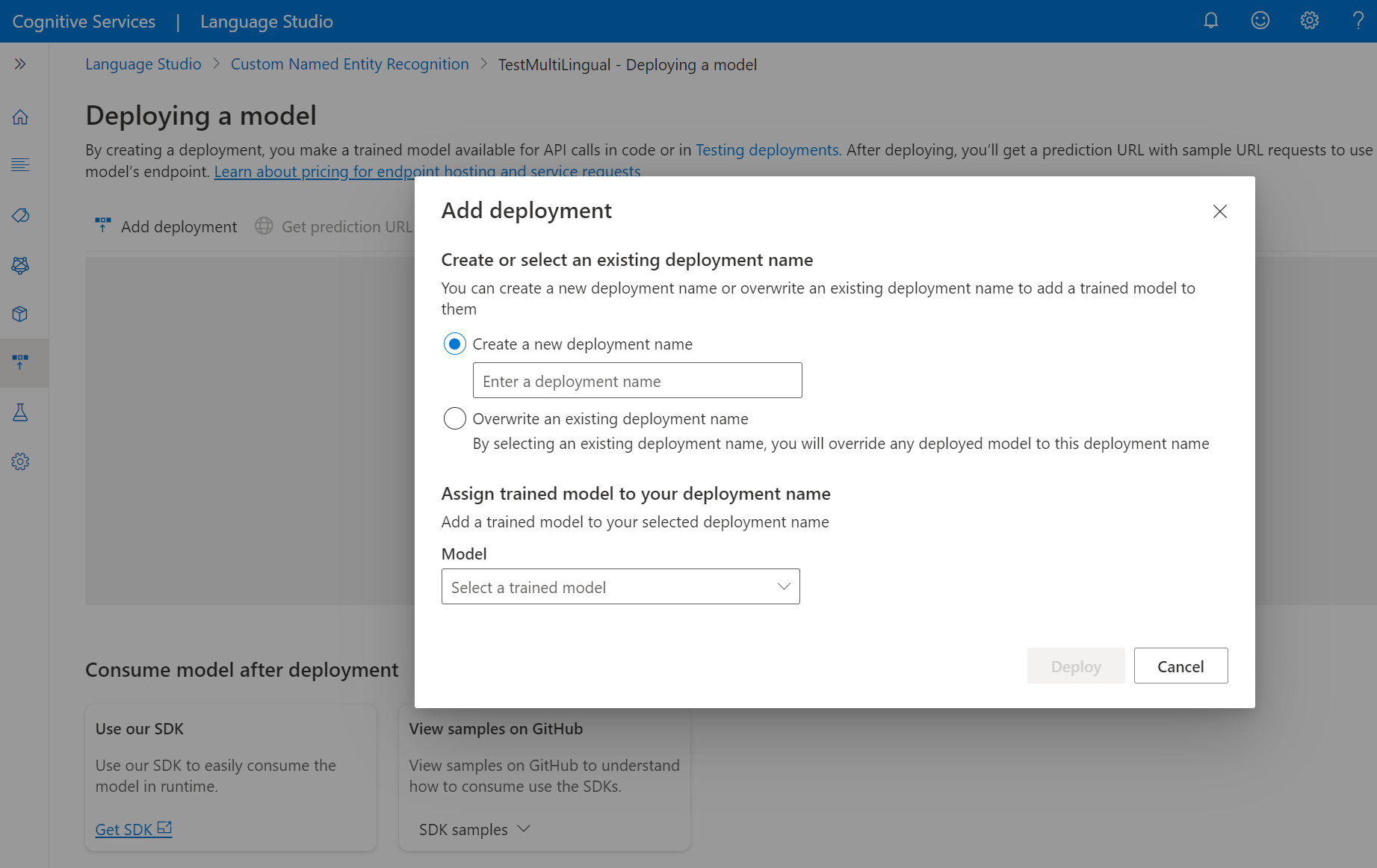
選取 [部署] 以啟動部署作業。
部署成功之後,到期日會出現在它旁邊。 部署到期 是當部署的模型無法用於預測時,通常發生在 定型組態到期后的 12 個月。


測試您的模型
部署模型之後,您就可以開始透過預測 API 從文字中擷取實體。 在本快速入門中,您將使用 Language Studio (英文) 提交用於健康醫療領域的自訂文字分析預測工作,並將結果視覺化。 在稍早下載的範例數據集中,您可以找到一些可在此步驟中使用的測試檔。
若要從 Language Studio 內測試已部署的模型:
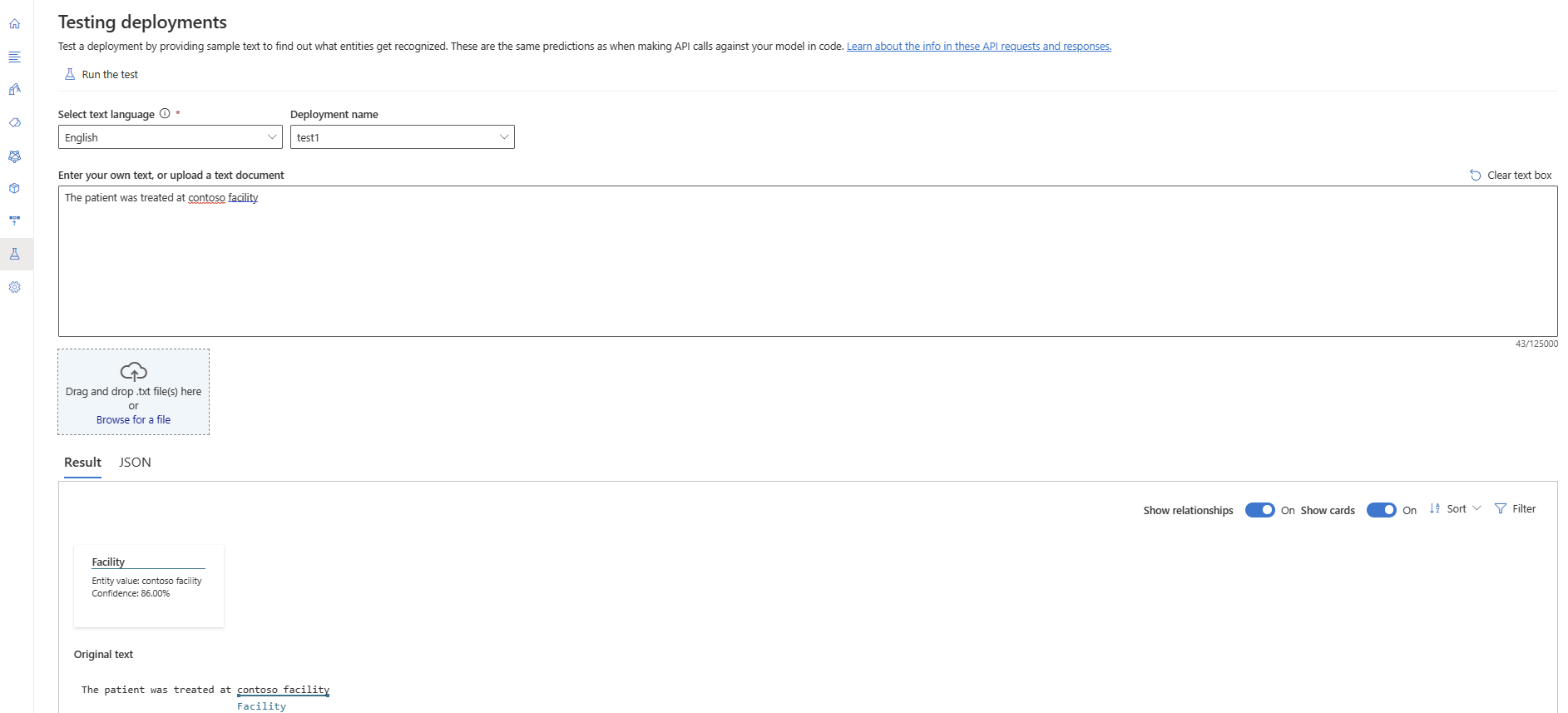
從左側功能表中選取 [測試部署 ]。
選取您要測試的部署。 您只能測試指派給部署的模型。
從下拉式清單中選取您想要查詢/測試的部署。
您可以輸入要提交至要求的文字,或上傳
.txt要使用的檔案。選取頂端功能表中的 [執行測試]。
在 [ 結果] 索引標籤中,您可以看到從文字及其類型擷取的實體。 您也可以在 [JSON] 索引標籤下檢視 JSON 回應。

清除資源
當您不再需要專案時,可以使用 Language Studio 刪除專案。
- 在頁面頂端選取您使用的語言服務功能,
- 選取您要刪除的專案
- 從頂端功能表選取 Delete。
必要條件
- Azure 訂用帳戶 - 免費建立一個訂用帳戶
建立新的 Azure AI 語言資源和 Azure 儲存體帳戶
在您能使用用於健康醫療領域的自訂文字分析之前,您將需要建立 Azure AI 語言資源,以提供建立專案和開始將模型定型所需的認證。 您也需要 Azure 記憶體帳戶,您可以在其中上傳將用於建置模型的數據集。
重要
若要快速開始使用,建議您使用本文提供的步驟來建立新的 Azure AI 語言資源,這可讓您建立語言資源,同時建立及/或連接儲存體帳戶,此做法會比稍後執行更容易。
如果您有想要使用的現有資源,則必須將它連線到記憶體帳戶。 如需詳細資訊,請參閱建立專案 (部分機器翻譯)。
從 Azure 入口網站 建立新的資源
登入 Azure 入口網站以建立新的 Azure AI 語言資源。
在出現的視窗中,從自定義功能選取 [自定義文字分類與自定義具名實體辨識 ]。 選取畫面底部的 [繼續建立您的資源]。
使用下列詳細數據建立語言資源。
名稱 描述 訂用帳戶 您的 Azure 訂閱。 資源群組 將包含您資源的資源群組。 您可以使用現有的 ,或建立新的。 區域 語言資源的區域。 例如,「美國西部 2」。 名稱 資源的名稱。 定價層 語言資源的定價層。 您可以使用免費 (F0) 層來嘗試服務。 注意
如果您收到一則訊息,指出「您的登入帳戶不是所選記憶體帳戶資源群組的擁有者」,您的帳戶必須先在資源群組上指派擁有者角色,才能建立語言資源。 請連絡您的 Azure 訂用帳戶擁有者以取得協助。
在 [ 自定義文字分類與自定義具名實體辨識 ] 區段中,選取現有的記憶體帳戶,或選取 [ 新增記憶體帳戶]。 這些值可協助您開始使用,而不一定 是您想要在生產環境中使用的記憶體帳戶值 。 若要避免在建置項目時延遲,請連線到與語言資源位於相同區域中的記憶體帳戶。
儲存體 帳戶值 建議值 儲存體帳戶名稱 任何名稱 Storage account type 標準 LRS 請確定 已核取負責任 AI 通知 。 選取頁面底部的 [ 檢閱 + 建立 ],然後選取 [ 建立]。
將範例數據上傳至 Blob 容器
建立 Azure 記憶體帳戶並將其連線到您的語言資源之後,您必須將檔從範例數據集上傳至容器的根目錄。 這些檔稍後將用來定型模型。
開啟 .zip 檔案,並解壓縮包含文件的資料夾。
在 Azure 入口網站 中,流覽至您所建立的記憶體帳戶,然後加以選取。
在您的儲存體帳戶中,從左側功能表中 [資料儲存體] 的下方選取 [容器]。 在出現的畫面中,選取 [+ 容器]。 提供容器名稱 example-data ,並保留預設 的公用存取層級。
建立容器之後,請加以選取。 然後選取 [上傳] 按鈕,以選取您稍早下載的
.txt和.json檔案。
提供的範例資料集包含 12 份臨床記錄。 每份臨床記錄都包含數個醫療實體和治療地點。 我們將使用預先建置的實體來擷取醫療實體,並訓練自訂模型使用該實體的已學習和清單元件來擷取治療位置。
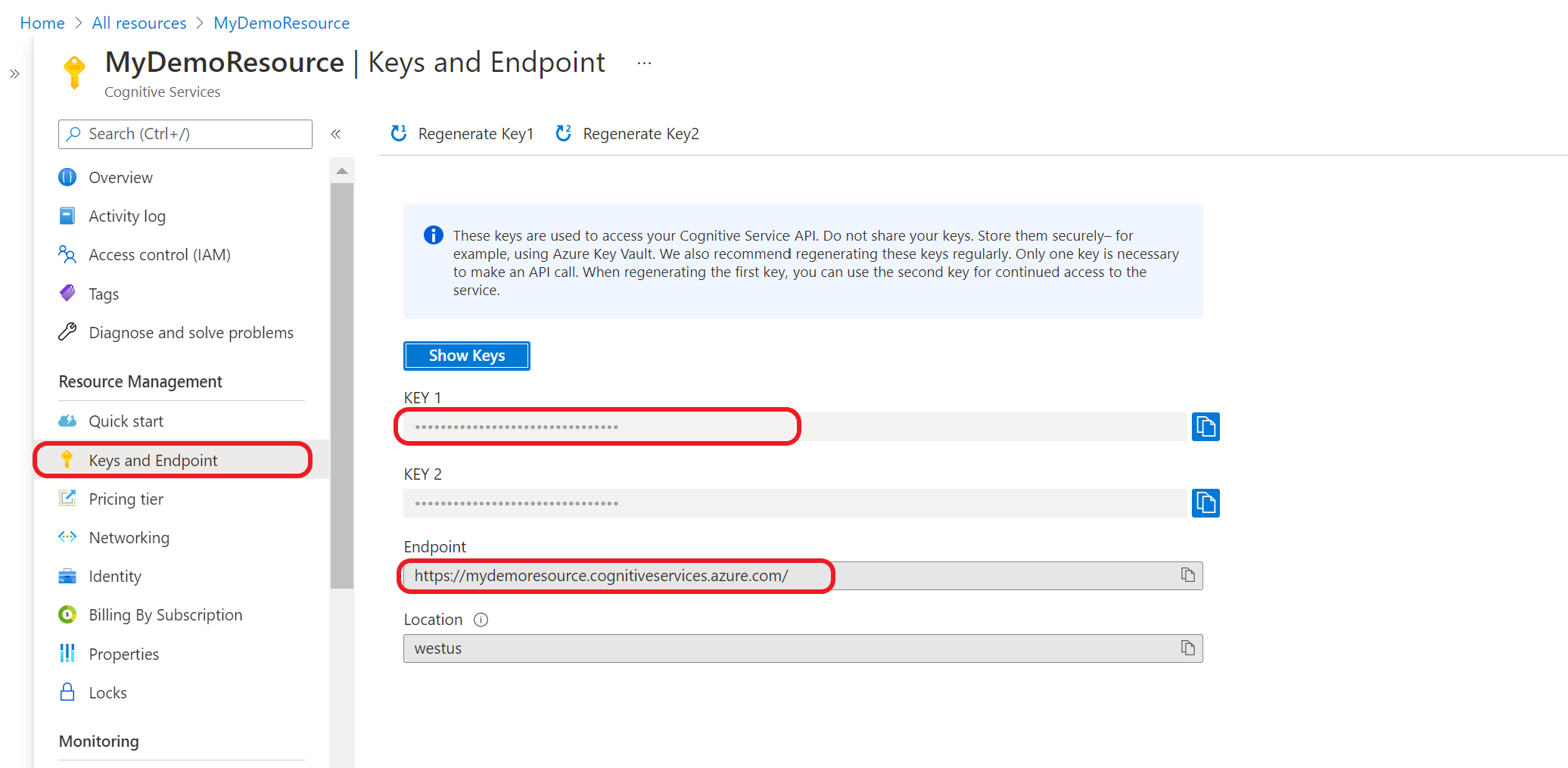
取得您的資源金鑰和端點
移至 Azure 入口網站 中的資源概觀頁面
從左側的功能表中,選取 [金鑰] 和 [ 端點]。 您將使用此端點和金鑰來提出 API 要求

建立用於健康醫療領域的自訂文字分析專案
設定了資源和儲存體帳戶之後,請建立新的「用於健康醫療領域的自訂文字分析」專案。 專案是一個工作區域,可根據您的數據建置自定義ML模型。 您的專案只能由您和其他人存取所使用之語言資源。
使用您在上一個步驟中從範例資料下載的標籤檔案,並將其新增至下列要求的本文中。
觸發匯入專案作業
使用下列 URL、標頭和 JSON 主體提交 POST 要求,以匯入您的卷標檔案。 請確定您的標籤檔案遵循 接受的格式。
如果具有相同名稱的項目已經存在,則會取代該專案的數據。
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/:import?api-version={API-VERSION}
| 預留位置 | 值 | 範例 |
|---|---|---|
{ENDPOINT} |
用於驗證 API 要求的端點。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
專案名稱。 此值區分大小寫。 | myProject |
{API-VERSION} |
您正在呼叫的 API 版本。 此處參考的值適用於發行的最新版本。 若要深入瞭解其他可用的 API 版本,請參閱 模型生命週期 。 | 2022-05-01 |
標頭
使用下列標頭來驗證您的要求。
| 機碼 | 值 |
|---|---|
Ocp-Apim-Subscription-Key |
資源的索引鍵。 用於驗證 API 要求。 |
本文
在您的要求中使用下列 JSON。 以您自己的值取代下方的佔位元值。
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectName": "{PROJECT-NAME}",
"projectKind": "CustomHealthcare",
"description": "Trying out custom Text Analytics for health",
"language": "{LANGUAGE-CODE}",
"multilingual": true,
"storageInputContainerName": "{CONTAINER-NAME}",
"settings": {}
},
"assets": {
"projectKind": "CustomHealthcare",
"entities": [
{
"category": "Entity1",
"compositionSetting": "{COMPOSITION-SETTING}",
"list": {
"sublists": [
{
"listKey": "One",
"synonyms": [
{
"language": "en",
"values": [
"EntityNumberOne",
"FirstEntity"
]
}
]
}
]
}
},
{
"category": "Entity2"
},
{
"category": "MedicationName",
"list": {
"sublists": [
{
"listKey": "research drugs",
"synonyms": [
{
"language": "en",
"values": [
"rdrug a",
"rdrug b"
]
}
]
}
]
}
"prebuilts": "MedicationName"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"entities": [
{
"regionOffset": 0,
"regionLength": 500,
"labels": [
{
"category": "Entity1",
"offset": 25,
"length": 10
},
{
"category": "Entity2",
"offset": 120,
"length": 8
}
]
}
]
},
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"entities": [
{
"regionOffset": 0,
"regionLength": 100,
"labels": [
{
"category": "Entity2",
"offset": 20,
"length": 5
}
]
}
]
}
]
}
}
| 索引鍵 | 預留位置 | 值 | 範例 |
|---|---|---|---|
multilingual |
true |
布爾值,可讓您在數據集中具有多種語言的檔,而且當您的模型部署時,您可以使用任何支援的語言查詢模型(不一定包含在定型檔中)。 若要深入瞭解多語系支援,請參閱 語言支援 。 | true |
projectName |
{PROJECT-NAME} |
專案名稱 | myproject |
storageInputContainerName |
{CONTAINER-NAME} |
容器名稱 | mycontainer |
entities |
數位,其中包含您在專案中擁有的所有實體類型。 這些是從您的檔擷取到的實體類型。 | ||
category |
實體類型的名稱,可以是針對新實體定義的使用者定義名稱,或是針對預建實體的預先定義名稱。 | ||
compositionSetting |
{COMPOSITION-SETTING} |
定義如何在實體中管理多個元件的規則。 選項為 combineComponents 或 separateComponents。 |
combineComponents |
list |
包含專案中特定實體所有子清單的陣列。 您可以將清單新增至預建實體或具有已學習元件的新實體。 | ||
sublists |
[] |
包含子清單的陣列。 每個子清單都是索引鍵及其相關聯的值。 | [] |
listKey |
One |
要對應回預測中同義字清單的標準化值。 | One |
synonyms |
[] |
包含所有同義字的陣列 | 同義字 |
language |
{LANGUAGE-CODE} |
指定子清單中同義字語言代碼的字串。 如果您的專案是多語系專案,而且您想要支援專案中所有語言的同義字清單,則必須明確地將同義字新增至每個語言。 如需支援語言代碼的詳細資訊,請參閱 語言支援 。 | en |
values |
"EntityNumberone", "FirstEntity" |
將完全符合擷取並對應至清單索引鍵的逗號分隔字串清單。 | "EntityNumberone", "FirstEntity" |
prebuilts |
MedicationName |
填入預建實體的預建元件名稱。 系統預設會自動將預建實體載入到您的專案,但您可以使用標籤檔案中的清單元件加以擴充。 | MedicationName |
documents |
數位,其中包含專案中的所有檔,以及每個檔內加上標籤的實體清單。 | [] | |
location |
{DOCUMENT-NAME} |
記憶體容器中檔的位置。 由於所有檔都在容器的根目錄中,因此這應該是檔名稱。 | doc1.txt |
dataset |
{DATASET} |
此檔案在定型前分割時將會移至的測試集。 此欄位Train的可能值為 與 。 Test |
Train |
regionOffset |
文字開頭的內含字元位置。 | 0 |
|
regionLength |
UTF16 字元的周框方塊長度。 定型只會考慮此區域中的數據。 | 500 |
|
category |
與指定之文字範圍相關聯的實體類型。 | Entity1 |
|
offset |
實體文字的開始位置。 | 25 |
|
length |
以UTF16字元為單位的實體長度。 | 20 |
|
language |
{LANGUAGE-CODE} |
字串,指定專案中所用文件的語言代碼。 如果您的專案是多語系專案,請選擇大部分文件的語言代碼。 如需支援語言代碼的詳細資訊,請參閱 語言支援 。 | en |
傳送 API 要求之後,您會收到 202 回應,指出作業已正確提交。 在響應標頭中,擷 operation-location 取值。 格式如下:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} 是用來識別您的要求,因為這項作業是異步的。 您將使用此網址來取得匯入作業狀態。
此要求可能發生的錯誤案例:
- 選取的資源沒有 記憶體帳戶的適當許可權 。
- 指定的
storageInputContainerName不存在。 - 使用無效的語言程式代碼,或者如果語言代碼類型不是字串,則為 。
multilingualvalue 是字串,而不是布爾值。
取得匯入作業狀態
使用下列 GET 要求來取得匯入項目的狀態。 以您自己的值取代下方的佔位元值。
要求 URL
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
| 預留位置 | 值 | 範例 |
|---|---|---|
{ENDPOINT} |
用於驗證 API 要求的端點。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
項目的名稱。 此值區分大小寫。 | myProject |
{JOB-ID} |
用來尋找模型定型狀態的標識碼。 此值位於 location 您在上一個步驟中收到的標頭值。 |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
您正在呼叫的 API 版本。 此處參考的值適用於發行的最新版本。 若要深入瞭解其他可用的 API 版本,請參閱 模型生命週期 。 | 2022-05-01 |
標頭
使用下列標頭來驗證您的要求。
| 機碼 | 值 |
|---|---|
Ocp-Apim-Subscription-Key |
資源的索引鍵。 用於驗證 API 要求。 |
定型您的模型
一般而言,在您建立項目之後,請繼續開始標記您在容器中已連線至專案的檔。 在本快速入門中,您已匯入範例標記數據集,並使用範例 JSON 卷標檔案初始化專案。
開始訓練作業
匯入項目之後,您就可以開始定型模型。
使用下列 URL、標頭和 JSON 主體提交 POST 要求,以提交定型作業。 將佔位元值取代為您自己的值。
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| 預留位置 | 值 | 範例 |
|---|---|---|
{ENDPOINT} |
用於驗證 API 要求的端點。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
項目的名稱。 此值區分大小寫。 | myProject |
{API-VERSION} |
您要呼叫的 API 版本。 此處參考的值適用於發行的最新版本。 若要深入瞭解其他可用的 API 版本,請參閱 模型生命週期 。 | 2022-05-01 |
標頭
使用下列標頭來驗證您的要求。
| 機碼 | 值 |
|---|---|
Ocp-Apim-Subscription-Key |
資源的索引鍵。 用於驗證 API 要求。 |
要求本文
在您的要求本文中使用下列 JSON。 定型完成之後,該模型會取得 {MODEL-NAME}。 只有成功的定型作業才會產生模型。
{
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"trainingSplitPercentage": 80,
"testingSplitPercentage": 20
}
}
| 索引鍵 | 預留位置 | 值 | 範例 |
|---|---|---|---|
| modelLabel | {MODEL-NAME} |
在成功定型之後指派給模型的模型名稱。 | myModel |
| trainingConfigVersion | {CONFIG-VERSION} |
這是用來將模型定型的模型版本。 | 2022-05-01 |
| evaluationOptions | 在定型和測試集之間分割數據的選項。 | {} |
|
| kind | percentage |
分割方法。 可能的值為 percentage 或 manual。 如需詳細資訊,請參閱 如何定型模型 。 |
percentage |
| trainingSplitPercentage | 80 |
要包含在定型集中的標記數據百分比。 建議值為 80。 |
80 |
| testingSplitPercentage | 20 |
要包含在測試集中的標記數據百分比。 建議值為 20。 |
20 |
注意
trainingSplitPercentage只有在 設定為 percentage 且這兩個百分比的總和應等於 100 時Kind,才需要 和 testingSplitPercentage 。
傳送 API 要求之後,您會收到 202 回應,指出作業已正確提交。 在響應標頭中,擷 location 取值。 其格式如下所示:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} 是用來識別您的要求,因為這項作業是異步的。 您可以使用此網址來取得定型狀態。
取得訓練作業狀態
此範例數據集的定型可能需要 10 到 30 分鐘的時間。 您可以使用下列要求持續輪詢定型作業的狀態,直到成功完成為止。
使用下列 GET 要求來取得模型定型進度的狀態。 以您自己的值取代下方的佔位元值。
要求 URL
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| 預留位置 | 值 | 範例 |
|---|---|---|
{ENDPOINT} |
用於驗證 API 要求的端點。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
項目的名稱。 此值區分大小寫。 | myProject |
{JOB-ID} |
用來尋找模型定型狀態的標識碼。 此值位於 location 您在上一個步驟中收到的標頭值。 |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
您要呼叫的 API 版本。 此處參考的值適用於發行的最新版本。 若要深入瞭解其他可用的 API 版本,請參閱 模型生命週期 。 | 2022-05-01 |
標頭
使用下列標頭來驗證您的要求。
| 機碼 | 值 |
|---|---|
Ocp-Apim-Subscription-Key |
資源的索引鍵。 用於驗證 API 要求。 |
回應本文
傳送要求之後,您會收到下列回應。
{
"result": {
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "{JOB-ID}",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
部署模型
一般來說,在定型模型之後,您可以檢閱其評估詳細資料,並視需要加以改善。 在本快速入門中,您只會部署模型,並讓它可供您在 Language Studio 中試用,或者您可以呼叫 預測 API。
啟動部署作業
使用下列 URL、標頭和 JSON 主體提交 PUT 要求,以提交部署作業。 以您自己的值取代下方的佔位元值。
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/deployments/{deploymentName}?api-version={API-VERSION}
| 預留位置 | 值 | 範例 |
|---|---|---|
{ENDPOINT} |
用於驗證 API 要求的端點。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
項目的名稱。 此值區分大小寫。 | myProject |
{DEPLOYMENT-NAME} |
部署的名稱。 此值區分大小寫。 | staging |
{API-VERSION} |
您要呼叫的 API 版本。 此處參考的值適用於發行的最新版本。 若要深入瞭解其他可用的 API 版本,請參閱 模型生命週期 。 | 2022-05-01 |
標頭
使用下列標頭來驗證您的要求。
| 機碼 | 值 |
|---|---|
Ocp-Apim-Subscription-Key |
資源的索引鍵。 用於驗證 API 要求。 |
要求本文
在要求的主體中使用下列 JSON。 使用您要指派給部署的模型名稱。
{
"trainedModelLabel": "{MODEL-NAME}"
}
| 索引鍵 | 預留位置 | 值 | 範例 |
|---|---|---|---|
| trainedModelLabel | {MODEL-NAME} |
模型名稱會指派給您的部署。 您只能指派已成功定型的模型。 此值區分大小寫。 | myModel |
傳送 API 要求之後,您會收到 202 回應,指出作業已正確提交。 在響應標頭中,擷 operation-location 取值。 格式如下:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} 是用來識別您的要求,因為這項作業是異步的。 您可以使用此網址來取得部署狀態。
取得部署作業狀態
使用下列 GET 要求來查詢部署作業的狀態。 您可以使用您從上一個步驟收到的 URL,或將下列佔位元值取代為您自己的值。
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
| 預留位置 | 值 | 範例 |
|---|---|---|
{ENDPOINT} |
用於驗證 API 要求的端點。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
項目的名稱。 此值區分大小寫。 | myProject |
{DEPLOYMENT-NAME} |
部署的名稱。 此值區分大小寫。 | staging |
{JOB-ID} |
用來尋找模型定型狀態的標識碼。 這是您在 location 上一個步驟中收到的標頭值。 |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
您要呼叫的 API 版本。 此處參考的值適用於發行的最新版本。 若要深入瞭解其他可用的 API 版本,請參閱 模型生命週期 。 | 2022-05-01 |
標頭
使用下列標頭來驗證您的要求。
| 機碼 | 值 |
|---|---|
Ocp-Apim-Subscription-Key |
資源的索引鍵。 用於驗證 API 要求。 |
回應本文
當您傳送要求時,您會收到下列要求。 請持續輪詢此端點, 直到狀態 參數變更為「成功」為止。 您應該會取得程序 200 代碼,以指出要求是否成功。
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
使用已定型的模型進行預測
部署模型之後,您就可以開始使用模型,使用 預測 API 從文字擷取實體。 在稍早下載的範例數據集中,您可以找到一些可在此步驟中使用的測試檔。
提交用於健康醫療領域的自訂文字分析工作
使用此 POST 要求來啟動用於健康醫療領域的自訂文字分析擷取工作。
{ENDPOINT}/language/analyze-text/jobs?api-version={API-VERSION}
| 預留位置 | 值 | 範例 |
|---|---|---|
{ENDPOINT} |
用於驗證 API 要求的端點。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
您正在呼叫的 API 版本。 此處參考的值適用於發行的最新版本。 若要深入瞭解其他可用的 API 版本,請參閱 模型生命週期 。 | 2022-05-01 |
標頭
| 機碼 | 數值 |
|---|---|
| Ocp-Apim-Subscription-Key | 提供此 API 存取權的金鑰。 |
本文
{
"displayName": "Extracting entities",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "{LANGUAGE-CODE}",
"text": "Text1"
},
{
"id": "2",
"language": "{LANGUAGE-CODE}",
"text": "Text2"
}
]
},
"tasks": [
{
"kind": "CustomHealthcare",
"taskName": "Custom TextAnalytics for Health Test",
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}"
}
}
]
}
| 索引鍵 | 預留位置 | 值 | 範例 |
|---|---|---|---|
displayName |
{JOB-NAME} |
您的作業名稱。 | MyJobName |
documents |
[{},{}] | 要執行工作的檔案清單。 | [{},{}] |
id |
{DOC-ID} |
檔名稱或識別碼。 | doc1 |
language |
{LANGUAGE-CODE} |
指定檔案語言代碼的字串。 如果未指定此金鑰,服務會假設專案建立期間選取的專案默認語言。 如需支援的語言代碼清單,請參閱 語言支援 。 | en-us |
text |
{DOC-TEXT} |
要執行工作的檔工作。 | Lorem ipsum dolor sit amet |
tasks |
我們想要執行的工作清單。 | [] |
|
taskName |
Custom Text Analytics for Health Test |
工作名稱 | Custom Text Analytics for Health Test |
kind |
CustomHealthcare |
我們正在嘗試執行的專案或工作種類 | CustomHealthcare |
parameters |
要傳遞至工作的參數清單。 | ||
project-name |
{PROJECT-NAME} |
專案名稱。 此值區分大小寫。 | myProject |
deployment-name |
{DEPLOYMENT-NAME} |
部署的名稱。 此值區分大小寫。 | prod |
回應
您會收到 202 回應,指出您的工作已成功提交。 在回應 標頭中,擷取 operation-location。
operation-location 格式如下:
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
您可以使用此 URL 來查詢工作完成狀態,並在工作完成時取得結果。
取得工作結果
使用下列 GET 要求來查詢自定義實體辨識工作的狀態/結果。
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
| 預留位置 | 值 | 範例 |
|---|---|---|
{ENDPOINT} |
用於驗證 API 要求的端點。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
您要呼叫的 API 版本。 此處參考的值適用於發行的最新版本。 若要深入瞭解其他可用的 API 版本,請參閱 模型生命週期 。 | 2022-05-01 |
標頭
| 機碼 | 數值 |
|---|---|
| Ocp-Apim-Subscription-Key | 提供此 API 存取權的金鑰。 |
回應本文
回應會是具有下列參數的 JSON 文件
{
"createdDateTime": "2021-05-19T14:32:25.578Z",
"displayName": "MyJobName",
"expirationDateTime": "2021-05-19T14:32:25.578Z",
"jobId": "xxxx-xxxx-xxxxx-xxxxx",
"lastUpdateDateTime": "2021-05-19T14:32:25.578Z",
"status": "succeeded",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "CustomHealthcareLROResults",
"taskName": "Custom Text Analytics for Health Test",
"lastUpdateDateTime": "2020-10-01T15:01:03Z",
"status": "succeeded",
"results": {
"documents": [
{
"entities": [
{
"entityComponentInformation": [
{
"entityComponentKind": "learnedComponent"
}
],
"offset": 0,
"length": 11,
"text": "first entity",
"category": "Entity1",
"confidenceScore": 0.98
},
{
"entityComponentInformation": [
{
"entityComponentKind": "listComponent"
}
],
"offset": 0,
"length": 11,
"text": "first entity",
"category": "Entity1.Dictionary",
"confidenceScore": 1.0
},
{
"entityComponentInformation": [
{
"entityComponentKind": "learnedComponent"
}
],
"offset": 16,
"length": 9,
"text": "entity two",
"category": "Entity2",
"confidenceScore": 1.0
},
{
"entityComponentInformation": [
{
"entityComponentKind": "prebuiltComponent"
}
],
"offset": 37,
"length": 9,
"text": "ibuprofen",
"category": "MedicationName",
"confidenceScore": 1,
"assertion": {
"certainty": "negative"
},
"name": "ibuprofen",
"links": [
{
"dataSource": "UMLS",
"id": "C0020740"
},
{
"dataSource": "AOD",
"id": "0000019879"
},
{
"dataSource": "ATC",
"id": "M01AE01"
},
{
"dataSource": "CCPSS",
"id": "0046165"
},
{
"dataSource": "CHV",
"id": "0000006519"
},
{
"dataSource": "CSP",
"id": "2270-2077"
},
{
"dataSource": "DRUGBANK",
"id": "DB01050"
},
{
"dataSource": "GS",
"id": "1611"
},
{
"dataSource": "LCH_NW",
"id": "sh97005926"
},
{
"dataSource": "LNC",
"id": "LP16165-0"
},
{
"dataSource": "MEDCIN",
"id": "40458"
},
{
"dataSource": "MMSL",
"id": "d00015"
},
{
"dataSource": "MSH",
"id": "D007052"
},
{
"dataSource": "MTHSPL",
"id": "WK2XYI10QM"
},
{
"dataSource": "NCI",
"id": "C561"
},
{
"dataSource": "NCI_CTRP",
"id": "C561"
},
{
"dataSource": "NCI_DCP",
"id": "00803"
},
{
"dataSource": "NCI_DTP",
"id": "NSC0256857"
},
{
"dataSource": "NCI_FDA",
"id": "WK2XYI10QM"
},
{
"dataSource": "NCI_NCI-GLOSS",
"id": "CDR0000613511"
},
{
"dataSource": "NDDF",
"id": "002377"
},
{
"dataSource": "PDQ",
"id": "CDR0000040475"
},
{
"dataSource": "RCD",
"id": "x02MO"
},
{
"dataSource": "RXNORM",
"id": "5640"
},
{
"dataSource": "SNM",
"id": "E-7772"
},
{
"dataSource": "SNMI",
"id": "C-603C0"
},
{
"dataSource": "SNOMEDCT_US",
"id": "387207008"
},
{
"dataSource": "USP",
"id": "m39860"
},
{
"dataSource": "USPMG",
"id": "MTHU000060"
},
{
"dataSource": "VANDF",
"id": "4017840"
}
]
},
{
"entityComponentInformation": [
{
"entityComponentKind": "prebuiltComponent"
}
],
"offset": 30,
"length": 6,
"text": "100 mg",
"category": "Dosage",
"confidenceScore": 0.98
}
],
"relations": [
{
"confidenceScore": 1,
"relationType": "DosageOfMedication",
"entities": [
{
"ref": "#/documents/0/entities/1",
"role": "Dosage"
},
{
"ref": "#/documents/0/entities/0",
"role": "Medication"
}
]
}
],
"id": "1",
"warnings": []
}
],
"errors": [],
"modelVersion": "2020-04-01"
}
}
]
}
}
| 索引鍵 | 範例值 | 描述 |
|---|---|---|
| 實體 | [] | 包含所有已擷取之實體的陣列。 |
| entityComponentKind | prebuiltComponent |
一個用來指出哪個元件傳回特定實體的變數。 可能的值:prebuiltComponent、、 learnedComponentlistComponent |
| offset | 0 |
一個藉由編制字元索引來表示已擷取實體之起點的數字 |
| length | 10 |
一個以字元數表示已擷取實體之長度的數字。 |
| text | first entity |
針對特定實體擷取的文字。 |
| category | MedicationName |
對應於已擷取之文字的實體類型或類別名稱。 |
| confidenceScore | 0.9 |
一個用來表示已擷取實體之模型確定程度的數字,範圍從 0 到 1,數字愈大表示確定程度愈高。 |
| assertion | certainty |
與已擷取實體相關聯的判斷提示。 只有預先建置的用於健康醫療領域的文字分析才支援判斷提示。 |
| NAME | Ibuprofen |
與已擷取實體相關聯的實體連結標準化名稱。 只有預先建置的用於健康醫療領域的文字分析才支援實體連結。 |
| 連結 | [] | 一個包含所有與擷取實體相關聯之實體連結結果的陣列。 只有預先建置的用於健康醫療領域的文字分析才支援實體連結。 |
| dataSource | UMLS |
與已擷取實體相關聯之實體連結所產生的參考標準。 只有預先建置的用於健康醫療領域的文字分析才支援實體連結。 |
| 識別碼 | C0020740 |
與屬於已擷取資料來源之已擷取實體相關聯的實體連結所產生的參考程式碼。 只有預先建置的用於健康醫療領域的文字分析才支援實體連結。 |
| 關係 | [] | 包含所有已擷取之關聯性的陣列。 只有預先建置的用於健康醫療領域的文字分析實體才支援關聯性擷取。 |
| relationType | DosageOfMedication |
已擷取關聯性的類別。 只有預先建置的用於健康醫療領域的文字分析實體才支援關聯性擷取。 |
| 實體 | "Dosage", "Medication" |
與已擷取之關聯性有所關聯的實體。 只有預先建置的用於健康醫療領域的文字分析實體才支援關聯性擷取。 |
清除資源
當您不再需要專案時,可以使用下列 DELETE 要求加以刪除。 將佔位元值取代為您自己的值。
{Endpoint}/language/authoring/analyze-text/projects/{projectName}?api-version={API-VERSION}
| 預留位置 | 值 | 範例 |
|---|---|---|
{ENDPOINT} |
用於驗證 API 要求的端點。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
專案名稱。 此值區分大小寫。 | myProject |
{API-VERSION} |
您正在呼叫的 API 版本。 此處參考的值適用於發行的最新版本。 若要深入瞭解其他可用的 API 版本,請參閱 模型生命週期 。 | 2022-05-01 |
標頭
使用下列標頭來驗證您的要求。
| 機碼 | 數值 |
|---|---|
| Ocp-Apim-Subscription-Key | 資源的索引鍵。 用於驗證 API 要求。 |
傳送 API 要求之後,您會收到 202 指出成功的回應,這表示您的專案已刪除。 成功呼叫結果,其中包含用來檢查作業狀態的 Operation-Location 標頭。
下一步
- 用於健康醫療領域的文字分析概觀 (部分機器翻譯)
建立實體擷取模型之後,您可以:
當您開始建立用於健康醫療領域的自訂文字分析專案時,請使用「操作說明」文章,以進一步了解有關資料標記、定型和使用模型的詳細資訊:
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應