訓練您的專業版語音模型
在本文中,您會了解如何透過 Speech Studio 入口網站定型自訂神經語音。
定型持續時間會根據您要訓練的資料量而有所不同。 平均需要大約 40 個計算時數來定型自訂神經語音。 標準訂閱 (S0) 使用者可同時訓練四個語音。 若達到限制,請等候直到至少其中一個語音模型完成訓練,然後再試一次。
注意
雖然每個 訓練方法 所需的總時數有所不同,但每個方法的單價都相同。 如需詳細資訊,請參閱 自訂類神經定型價格詳細資料。
選擇訓練方法
您的資料檔案經過驗證之後,就可以用於建置自訂神經語音模型。 當您建立自訂神經語音時,您可以選擇使用下列其中一種方法來訓練:
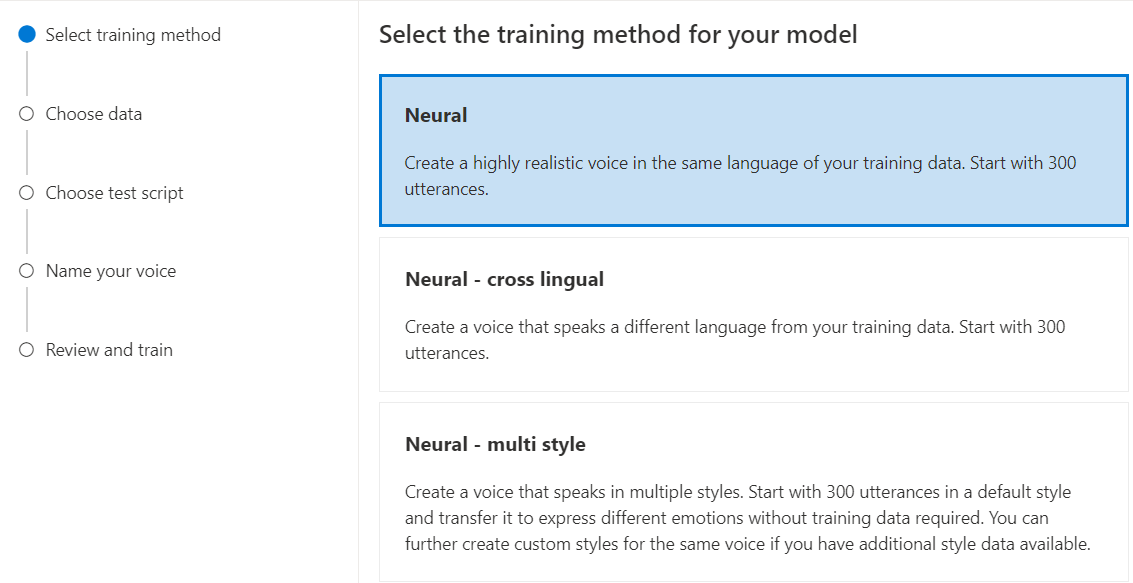
神經:使用與訓練資料相同的語言建立語音。
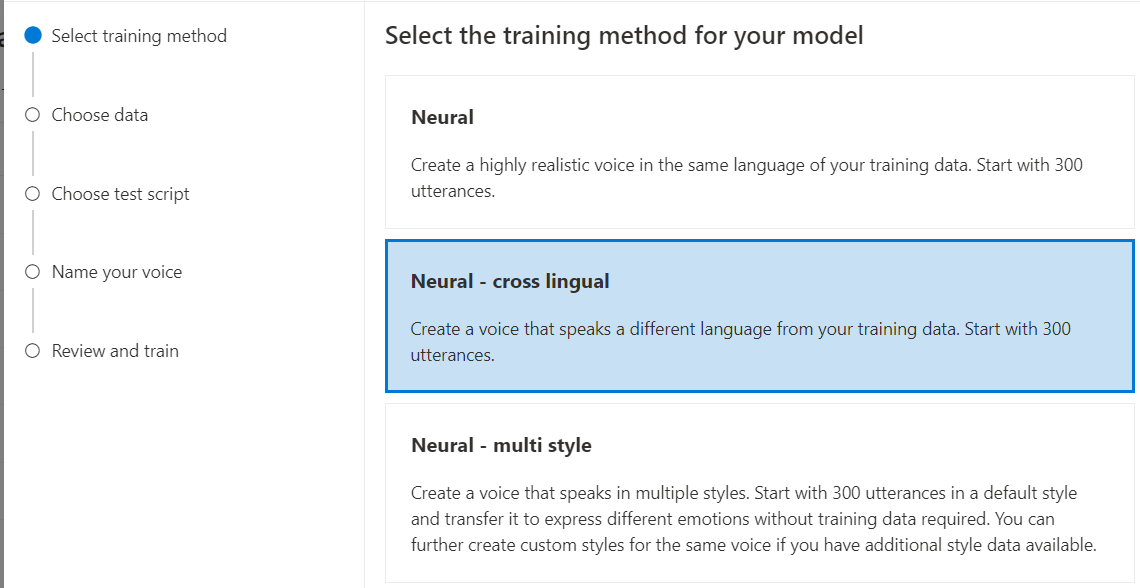
神經 - 交叉語言:建立所說語言與訓練資料不同的語音。 例如,使用
zh-CN訓練資料,您可以建立說en-US的語音。訓練資料和目標語言的語言必須是其中一種對於跨語言語音訓練支援的語言。 您不必以目標語言準備訓練資料,但您的測試指令碼必須是目標語言。
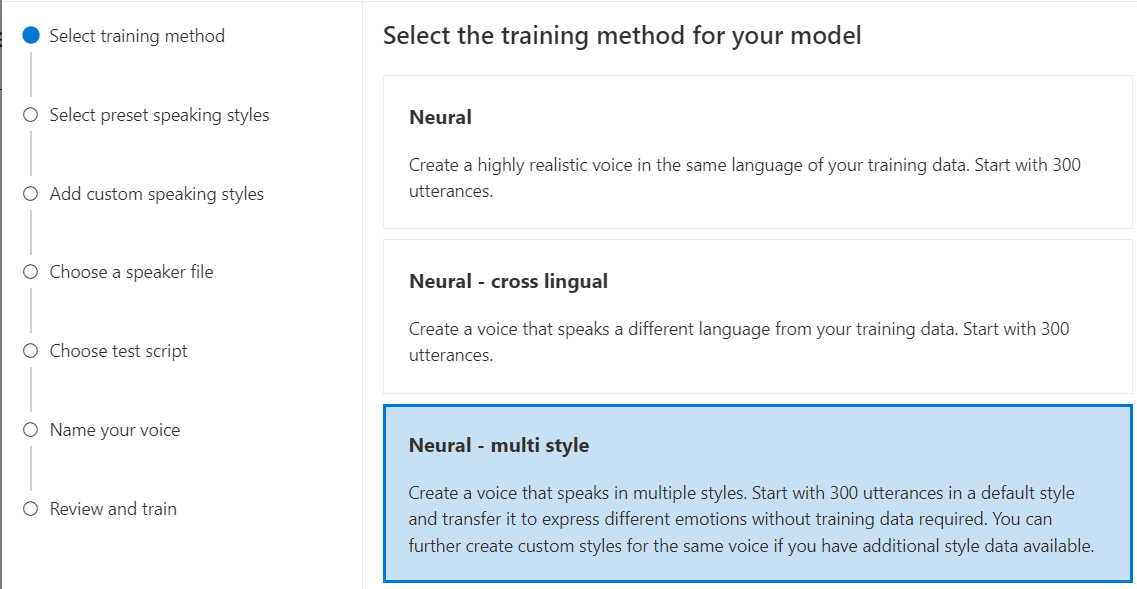
類神經 - 多樣式:建立以多個樣式和表情說話的自訂神經語音,而不需新增訓練資料。 多種風格語音特別適合視訊遊戲角色、交談聊天機器人、有聲書、內容讀取器等等。
若要建立多風格語音,您必須準備一組一般訓練資料,至少要有 300 個語句。 選取一或多種預設目標說話風格。 您也可以提供風格範例 (每種風格至少 100 個句) 作為相同語音的其他訓練資料,以建立多個自訂風格。 支援的預設樣式會根據不同的語言而有所不同。 請參閱 不同語言的可用預設風格。
訓練資料的語言必須是自訂神經語音、跨語言或多重風格訓練 支援的語言 其中之一。
定型您的自訂神經語音模型
若要在 Speech Studio 中建立自訂神經語音,請依照下列步驟執行下列其中一種方法:
登入 Speech Studio。
選取 [自訂語音]><您的專案名稱>>[訓練模型]>[訓練新模型]。
選取 [類神經] 作為模型的訓練方法,然後選取 [下一步]。 若要使用不同的訓練方法,請參閱類神經 - 跨語言或類神經 - 多樣式。
為模型選取訓練配方的版本。 根據預設,會選取最新版本。 支援的功能和訓練時間可能會因版本而異。 一般而言,我們建議使用最新版本。 在某些情況下,您可以選擇較舊的版本來縮短訓練時間。 如需雙語訓練和地區設定差異的詳細資訊,請參閱 雙語訓練。
注意
模型版本
V2.2021.07、V4.2021.10、V5.2022.05、V6.2022.11和V9.2023.10將於 2024 年 10 月 1 日淘汰。 這些已淘汰版本的語音模型不會受到影響。選取您要用於訓練的資料。 會從訓練中移除重複的音訊名稱。 請確認您選取的資料不會在多個 .zip 檔案中包含相同的音訊名稱。
您只能選取已成功處理的資料集進行訓練。 如果您在清單中沒有看到訓練集,請檢查資料處理狀態。
使用對應至訓練資料中說話者的語音配音員聲明,選取說話者檔案。
選取 [下一步]。
每次訓練都會自動產生 100 個範例音訊檔案,以協助您使用預設指令碼來測試模型。
或者,您也可以選取 [新增自己的測試指令碼],並提供最多含 100 個語句的自有測試指令碼來測試模型,而不需額外費用。 產生的音訊檔案是自動測試指令碼和自訂測試指令碼的組合。 如需詳細資訊,請參閱測試指令碼需求。
輸入 名稱 以協助您識別模型。 請謹慎選擇名稱。 模型名稱會作為 SDK 提出的 語音合成要求 和 SSML 輸入中的語音名稱。 只允許字母、數字與一些標點符號。 針對不同神經語音模型使用不同的名稱。
可選擇輸入 [描述] 以協助您識別模型。 描述常用於記錄建立模型時所使用的資料名稱。
選取 [下一步]。
檢閱設定,然後選取方塊以接受使用規定。
選取 [提交] 開始訓練模型。
雙語訓練
如果您選取 神經 訓練類型,您可以訓練語音以多種語言說話。 、 zh-CNzh-HK和 zh-TW 地區設定支援雙語訓練,讓語音講中文和英文。 部分取決於訓練資料,合成的語音可以使用英語本土口音或與訓練資料相同的口音來說英文。
注意
若要讓 zh-CN 地區設定中的語音使用與範例資料相同的口音來說英文,您應該在建立專案時選擇 Chinese (Mandarin, Simplified), English bilingual ,或透過 REST API 指定訓練資料的 zh-CN (English bilingual) 地區設定。
下表顯示地區設定之間的差異:
| Speech Studio 地區設定 | REST API 地區設定 | 雙語支援 |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
如果您的資料樣本包含英語,則合成的語音會以英語本土口音說英文,而不是與範例資料相同的口音,不論英語資料量為何。 |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
如果您想要合成語音使用與範例資料相同的口音來說英語,建議您在訓練集中包含 10% 以上的英語資料。 否則,英語口音可能不理想。 |
Chinese (Cantonese, Simplified) |
zh-HK |
如果您想要使用與範例資料相同的口音來訓練合成語音,請務必在訓練集中提供 10% 以上的英語資料。 否則,它會預設為英語本土口音。 10% 閾值是根據成功上傳後接受的資料計算,而不是上傳前的資料。 如果某些上傳的英語資料因瑕疵而遭到拒絕,且不符合 10% 閾值,合成的語音預設為英語本土口音。 |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
如果您想要使用與範例資料相同的口音來訓練合成語音,請務必在訓練集中提供 10% 以上的英語資料。 否則,它會預設為英語本土口音。 10% 閾值是根據成功上傳後接受的資料計算,而不是上傳前的資料。 如果某些上傳的英語資料因瑕疵而遭到拒絕,且不符合 10% 閾值,合成的語音預設為英語本土口音。 |
不同語言的可用預設樣式
下表摘要說明根據不同語言的不同預設樣式。
| 說話風格 | 語言 (地區設定) |
|---|---|
| 生氣 | 英語 (北美洲) (en-US)日語 (日本) ( ja-JP) 1中文 (普通話,簡體) ( zh-CN) 1 |
| 冷靜 | 中文 (普通話,簡體) (zh-CN) 1 |
| 聊天 | 中文 (普通話,簡體) (zh-CN) 1 |
| 愉快 | 英語 (北美洲) (en-US)日語 (日本) ( ja-JP) 1中文 (普通話,簡體) ( zh-CN) 1 |
| 不滿 | 中文 (普通話,簡體) (zh-CN) 1 |
| 興奮 | 英語 (北美洲) (en-US) |
| 害怕 | 中文 (普通話,簡體) (zh-CN) 1 |
| 友善 | 英語 (北美洲) (en-US) |
| 滿懷希望 | 英語 (北美洲) (en-US) |
| 傷心 | 英語 (北美洲) (en-US)日語 (日本) ( ja-JP) 1中文 (普通話,簡體) ( zh-CN) 1 |
| 喊叫 | 英語 (北美洲) (en-US) |
| 嚴肅 | 中文 (普通話,簡體) (zh-CN) 1 |
| 恐懼 | 英語 (北美洲) (en-US) |
| 不友善 | 英語 (北美洲) (en-US) |
| 低語 | 英語 (北美洲) (en-US) |
1 神經語音風格可在公開預覽版中取得。 公開預覽版的語音和風格僅適用於下列服務 區域:美國東部、西歐和東南亞。
[定型模型] 資料表會顯示與這個新建立模型對應的新項目。 該狀態會反映將資料轉換成語音模型的程序,如下列資料表中所描述:
| 狀態 | 意義 |
|---|---|
| 正在處理 | 已建立您的語音模型。 |
| 成功 | 已建立您的語音模型且可以部署。 |
| 失敗 | 您的語音模型在訓練時失敗。 例如,失敗原因可能是未看到的資料問題或網路問題。 |
| 已取消 | 已取消語音模型的訓練。 |
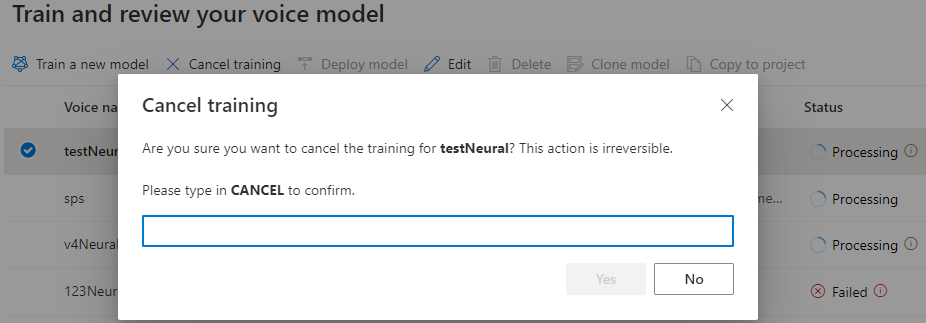
模型狀態是處理中時,您可以選取 [取消訓練] 來取消語音模型。 您不需要支付此取消訓練的費用。
成功完成模型訓練之後,您可以檢閱模型詳細資料,並 測試語音模型。
您可以使用 Speech Studio 中的 音訊內容建立 工具來建立音訊,並微調已部署的語音。 如果適用於您的語音,您可以選取其中一種風格。
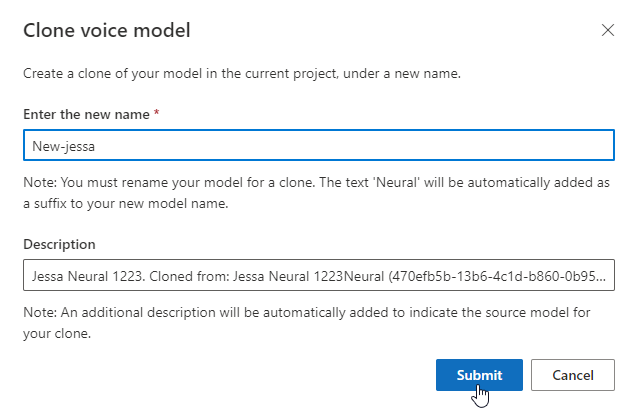
為模型重新命名
若您想要將所建置的模型重新命名,可以選取 [複製模型],在目前專案中建立具有新名稱的模型複製品。
![選取 [複製模型] 按鈕的螢幕擷取畫面。](media/custom-voice/cnv-clone-model.png)
在 [複製語音模型] 視窗中輸入新名稱,然後選取 [提交]。 文字 Neural 會自動新增為新模型名稱的後綴。
測試語音模型
成功建置語音模型之後,您可以使用產生的範例音訊檔案來測試它,再進行部署。
語音品質取決於許多因素,例如:
- 訓練集的大小。
- 錄製的品質。
- 文字記錄檔案的精確度。
- 針對您預定使用案例所設計語音的特質與訓練資料中所錄製語音的符合程度。
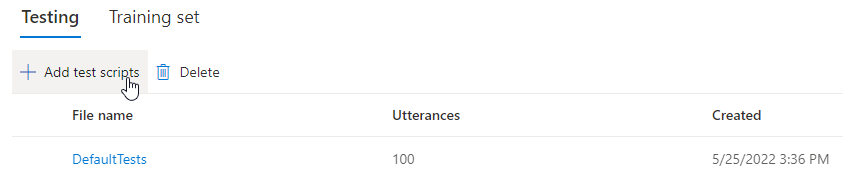
選取 [測試] 下的 [DefaultTests] 可聆聽範例音訊。 預設測試範例包含訓練期間自動產生的 100 個範例音訊檔案,以協助您測試模型。 根據預設,除了提供的這 100 個音訊檔案之外,也會將您自己在訓練期間所提供的測試指令碼語句新增至 DefaultTests 集合。 最多可新增 100 個語句。 您不需要支付使用 DefaultTests 測試的費用。
![在 [測試] 下選取 [DefaultTests] 的螢幕擷取畫面。](media/custom-voice/cnv-model-default-test.png)
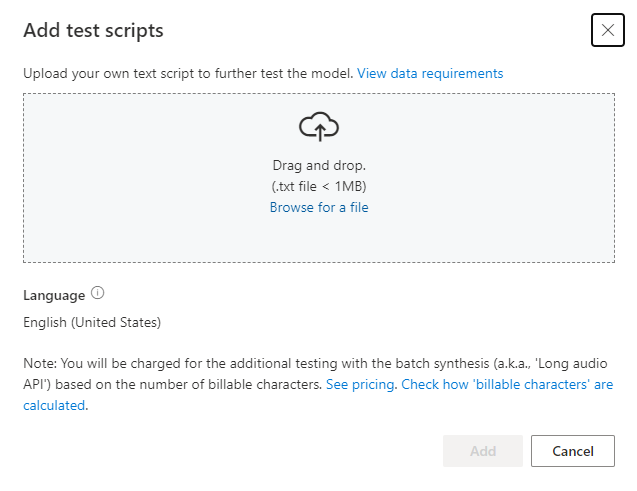
若您想要上傳自己的測試指令碼以進一步測試模型,請選取 [新增測試指令碼] 以上傳您自己的測試指令碼。
上傳測試指令碼之前,請先檢查 測試指令碼需求。 您需根據可計費字元數目,支付使用批次合成的額外測試費用。 請參閱 Azure AI 語音價格。
在 [新增測試指令碼] 視窗中,選取 [瀏覽檔案] 以選取您自己的指令碼,然後選取 [新增] 將其上傳。
測試指令碼需求
測試指令碼必須是小於 1 MB 的 .txt 檔案。 支援的編碼格式包括 ANSI/ASCII、UTF-8、UTF-8-BOM、UTF-16-LE 或 UTF-16-BE。
不同於 訓練謄寫檔案,測試指令碼應該排除語句識別碼 (每個語句的檔案名稱)。 否則,會說出這些識別碼。
以下是一個 .txt 檔案中的一組語句範例:
This is the waistline, and it's falling.
We have trouble scoring.
It was Janet Maslin.
語句的每個段落都會產生個別音訊。 若您想要將所有句子合併至一個音訊中,請將其放在同一個段落中。
注意
產生的音訊檔案是自動測試指令碼和自訂測試指令碼的組合。
更新語音模型的引擎版本
Azure 文字轉換語音引擎會不時更新,以擷取定義語言發音的最新語言模型。 訓練語音之後,您可以更新至最新的引擎版本,將語音套用至新的語言模型。
當新的引擎可供使用時,會提示您更新神經語音模型。

移至模型詳細資料頁面,並依照畫面上的指示來安裝最新引擎。
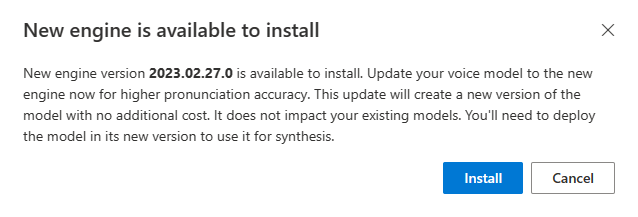
或者,選取稍後 [安裝最新引擎],將您的模型更新為最新的引擎版本。
![螢幕擷取畫面:選取 [安裝最新引擎] 按鈕來更新引擎。](media/custom-voice/cnv-install-latest-engine.png)
您不需要支付引擎更新的費用。 舊版仍會保留。
您可以從 [引擎版本] 清單中檢查模型的所有引擎版本,或者如果您不再需要某個模型,請將其移除。
![顯示 [引擎版本] 下拉式清單的螢幕擷取畫面。](media/custom-voice/cnv-engine-version.png)
更新的版本會自動設定為預設值。 但您可以藉由從下拉式清單中選取版本並選取 [設定為預設值] 來變更預設版本。
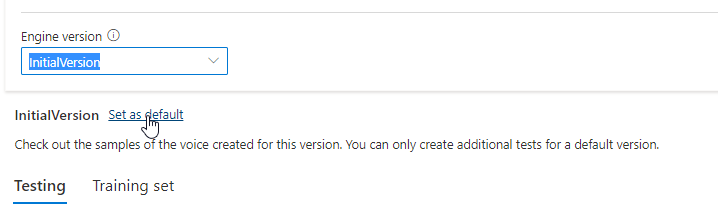

若您想要測試語音模型的每個引擎版本,可以從清單中選取版本,然後選取 [測試] 下的 [DefaultTests] 以聆聽範例音訊檔案。 如果您想要上傳自己的測試指令碼以進一步測試目前的引擎版本,請先確認版本已設定為預設值,然後遵循 測試語音模型 中的步驟。
更新引擎會建立新版本的模型,不需額外費用。 更新語音模型的引擎版本之後,您必須部署新版本以 建立新端點。 您只能部署預設版本。
建立新的端點之後,您必須 將流量傳送至產品中的新端點。
若要深入瞭解這項功能的功能和限制,以及改善模型品質的最佳做法,請參閱 使用自訂神經語音的特性和限制。
將語音模型複製到另一個專案
您可以將語音模型複製到相同區域或另一個區域的另一個專案。 例如,您可以將一個區域中定型的神經語音模型複製到另一個區域的專案。
注意
自訂神經語音定型目前僅在部分區域提供使用。 您可以將神經語音模型從這些區域複製到其他區域。 如需詳細資訊,請參閱自訂神經語音的區域。
若要將自訂神經語音模型複製到另一個專案:
在 [定型模型] 索引標籤上,選取您想要複製的語音模型,然後選取 [複製到專案]。
![[複製到專案] 選項的螢幕擷取畫面。](media/custom-voice/cnv-model-copy.png)
選取您要複製模型的 [訂用帳戶]、[區域]、[語音資源] 和 [專案]。 您必須具有在目標區域中的語音資源和專案,否則必須先建立語音資源和專案。
![[複製語音模型] 對話方塊的螢幕擷取畫面。](media/custom-voice/cnv-model-copy-dialog.png)
選取 [提交] 以複製模型。
選取複製成功通知訊息下的 [檢視模型]。
瀏覽至您複製模型以部署模型複本的專案。
下一步
在本文中,您將瞭解如何透過自訂語音 API 來訓練自訂神經語音。
重要
自訂神經語音訓練目前僅在部分區域提供使用。 在支援的區域中將語音模型定型之後,您可以視需要將其複製到另一個區域中的語音資源。 如需詳細資訊,請參閱 語音服務資料表 中的註腳。
定型持續時間會根據您要訓練的資料量而有所不同。 平均需要大約 40 個計算時數來定型自訂神經語音。 標準訂閱 (S0) 使用者可同時訓練四個語音。 若達到限制,請等候直到至少其中一個語音模型完成訓練,然後再試一次。
注意
雖然每個 訓練方法 所需的總時數有所不同,但每個方法的單價都相同。 如需詳細資訊,請參閱 自訂類神經定型價格詳細資料。
選擇訓練方法
您的資料檔案經過驗證之後,就可以用於建置自訂神經語音模型。 當您建立自訂神經語音時,您可以選擇使用下列其中一種方法來訓練:
神經:使用與訓練資料相同的語言建立語音。
神經 - 交叉語言:建立所說語言與訓練資料不同的語音。 例如,使用
fr-FR訓練資料,您可以建立說en-US的語音。訓練資料和目標語言的語言必須是其中一種對於跨語言語音訓練支援的語言。 您不必以目標語言準備訓練資料,但您的測試指令碼必須是目標語言。
類神經 - 多樣式:建立以多個樣式和表情說話的自訂神經語音,而不需新增訓練資料。 多種風格語音特別適合視訊遊戲角色、交談聊天機器人、有聲書、內容讀取器等等。
若要建立多風格語音,您必須準備一組一般訓練資料,至少要有 300 個語句。 選取一或多種預設目標說話風格。 您也可以提供風格範例 (每種風格至少 100 個句) 作為相同語音的其他訓練資料,以建立多個自訂風格。 支援的預設樣式會根據不同的語言而有所不同。 請參閱 不同語言的可用預設風格。
訓練資料的語言必須是其中一種對於自訂神經語音、跨語言或多重風格訓練 支援的語言。
建立語音模型
若要建立神經語音,請使用自訂語音 API 的 Models_Create 作業。 根據下列指示來建構要求本文:
- 設定必要的
projectId屬性。 請參閱 建立專案。 - 設定必要的
consentId屬性。 請參閱 新增語音配音員同意。 - 設定必要的
trainingSetId屬性。 請參閱 建立訓練集。 - 將必要配方的
kind屬性設定為Default以進行神經語音訓練。 配方種類表示訓練方法,且稍後無法變更。 若要使用不同的訓練方法,請參閱類神經 - 跨語言或類神經 - 多樣式。 如需雙語訓練和地區設定差異的詳細資訊,請參閱 雙語訓練。 - 設定必要的
voiceName屬性。 語音名稱必須以「Neural」結尾,且稍後無法變更。 請謹慎選擇名稱。 語音名稱會使用於 SDK 提出的 語音合成要求 和 SSML 輸入中。 只允許字母、數字與一些標點符號。 針對不同神經語音模型使用不同的名稱。 - 選擇性地設定語音描述的
description屬性。 稍後可以變更語音描述。
使用 URI 提出 HTTP PUT 要求,如下列 Models_Create 範例所示。
- 以您的語音資源金鑰取代
YourResourceKey。 - 將
YourResourceRegion取代為您的語音資源區域。 - 將
JessicaModelId取代為您選擇的模型識別碼。 區分大小寫的識別碼將會用於模型的 URI 中,且稍後無法變更。
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2024-02-01-preview"
您應該會收到下列格式的回應本文:
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V7.2023.03"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "NotStarted",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
雙語訓練
如果您選取 神經 訓練類型,您可以訓練語音以多種語言說話。 、 zh-CNzh-HK和 zh-TW 地區設定支援雙語訓練,讓語音講中文和英文。 部分取決於訓練資料,合成的語音可以使用英語本土口音或與訓練資料相同的口音來說英文。
注意
若要讓 zh-CN 地區設定中的語音使用與範例資料相同的口音來說英文,您應該在建立專案時選擇 Chinese (Mandarin, Simplified), English bilingual ,或透過 REST API 指定訓練資料的 zh-CN (English bilingual) 地區設定。
下表顯示地區設定之間的差異:
| Speech Studio 地區設定 | REST API 地區設定 | 雙語支援 |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
如果您的資料樣本包含英語,則合成的語音會以英語本土口音說英文,而不是與範例資料相同的口音,不論英語資料量為何。 |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
如果您想要合成語音使用與範例資料相同的口音來說英語,建議您在訓練集中包含 10% 以上的英語資料。 否則,英語口音可能不理想。 |
Chinese (Cantonese, Simplified) |
zh-HK |
如果您想要使用與範例資料相同的口音來訓練合成語音,請務必在訓練集中提供 10% 以上的英語資料。 否則,它會預設為英語本土口音。 10% 閾值是根據成功上傳後接受的資料計算,而不是上傳前的資料。 如果某些上傳的英語資料因瑕疵而遭到拒絕,且不符合 10% 閾值,合成的語音預設為英語本土口音。 |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
如果您想要使用與範例資料相同的口音來訓練合成語音,請務必在訓練集中提供 10% 以上的英語資料。 否則,它會預設為英語本土口音。 10% 閾值是根據成功上傳後接受的資料計算,而不是上傳前的資料。 如果某些上傳的英語資料因瑕疵而遭到拒絕,且不符合 10% 閾值,合成的語音預設為英語本土口音。 |
不同語言的可用預設樣式
下表摘要說明根據不同語言的不同預設樣式。
| 說話風格 | 語言 (地區設定) |
|---|---|
| 生氣 | 英語 (北美洲) (en-US)日語 (日本) ( ja-JP) 1中文 (普通話,簡體) ( zh-CN) 1 |
| 冷靜 | 中文 (普通話,簡體) (zh-CN) 1 |
| 聊天 | 中文 (普通話,簡體) (zh-CN) 1 |
| 愉快 | 英語 (北美洲) (en-US)日語 (日本) ( ja-JP) 1中文 (普通話,簡體) ( zh-CN) 1 |
| 不滿 | 中文 (普通話,簡體) (zh-CN) 1 |
| 興奮 | 英語 (北美洲) (en-US) |
| 害怕 | 中文 (普通話,簡體) (zh-CN) 1 |
| 友善 | 英語 (北美洲) (en-US) |
| 滿懷希望 | 英語 (北美洲) (en-US) |
| 傷心 | 英語 (北美洲) (en-US)日語 (日本) ( ja-JP) 1中文 (普通話,簡體) ( zh-CN) 1 |
| 喊叫 | 英語 (北美洲) (en-US) |
| 嚴肅 | 中文 (普通話,簡體) (zh-CN) 1 |
| 恐懼 | 英語 (北美洲) (en-US) |
| 不友善 | 英語 (北美洲) (en-US) |
| 低語 | 英語 (北美洲) (en-US) |
1 神經語音風格可在公開預覽版中取得。 公開預覽版的語音和風格僅適用於下列服務 區域:美國東部、西歐和東南亞。
取得定型狀態
若要取得語音模型的訓練狀態,請使用自訂語音 API 的 Models_Get 作業。 根據下列指示建構要求 URI:
使用 URI 提出 HTTP GET 要求,如下列 Models_Get 範例所示。
- 以您的語音資源金鑰取代
YourResourceKey。 - 將
YourResourceRegion取代為您的語音資源區域。 - 如果您在上一個步驟中指定了不同的模型識別碼,請取代
JessicaModelId。
curl -v -X GET "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2024-02-01-preview" -H "Ocp-Apim-Subscription-Key: YourResourceKey"
您應該會收到下列格式的回應本文。
注意
配方 kind 和其他屬性取決於您如何 訓練語音。 在此範例中,配方種類 Default 用於神經語音訓練。
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V7.2023.03"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
您可能需要等候幾分鐘,才能完成訓練。 最終狀態會變更為 Succeeded 或 Failed。