使用 Docker 自訂語音轉換文字容器
自訂語音轉換文字容器會以中繼結果謄寫即時語音或批次音訊錄製。 您可以使用您在 自訂語音入口網站 中建立的自訂模型。 在本文中,您將了解如何下載、安裝及執行自訂語音轉換文字容器。
如需必要條件、驗證容器正在執行、在相同主機上執行多個容器,以及執行中斷連線容器的詳細資訊,請參閱使用 Docker 安裝及執行語音容器。
容器映像
您可以在 Microsoft Container Registry (MCR) 同步發行中找到所有支援版本和地區設定的自訂語音轉換文字容器映像。 其位於 azure-cognitive-services/speechservices/ 存放庫內,並命名為 custom-speech-to-text。

完整的容器映像名稱為 mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text。 附加特定版本或附加 :latest 以取得最新版本。
| 版本 | Path |
|---|---|
| 最新 | mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:latest |
| 4.10.0 | mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:4.10.0-amd64 |
除了 latest 以外的所有標籤都採用下列格式,而且會區分大小寫:
<major>.<minor>.<patch>-<platform>-<prerelease>
注意
適用於自訂語音轉換文字容器的 locale 和 voice 是由容器內嵌的自訂模型所決定。
為了方便起見,標籤也以 JSON 格式提供。 本文包含容器路徑和標籤清單。 標籤不會依版本排序,但 "latest" 一律會包含在清單結尾,如下列程式碼片段所示:
{
"name": "azure-cognitive-services/speechservices/custom-speech-to-text",
"tags": [
<--redacted for brevity-->
"4.4.0-amd64",
"4.5.0-amd64",
"4.6.0-amd64",
"4.7.0-amd64",
"4.8.0-amd64",
"4.9.0-amd64",
"4.10.0-amd64",
"latest"
]
}
使用 docker pull 取得容器映像
您需要必要條件,包括必要的硬體。 另請參閱每個語音容器的建議資源配置。
使用 docker pull 命令,從 Microsoft Container Registry下載容器映像:
docker pull mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:latest
注意
適用於自訂語音容器的 locale 和 voice 是由容器內嵌的自訂模型所決定。
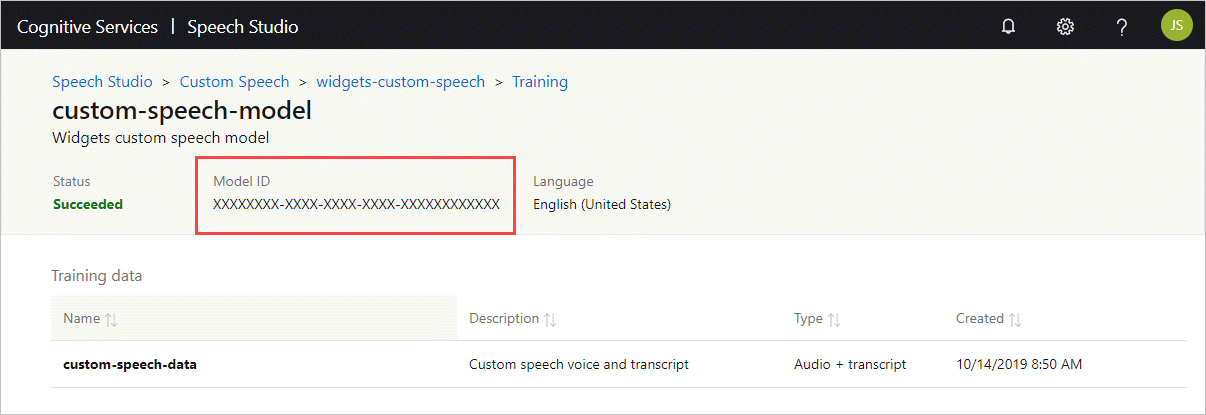
取得模型識別碼
您必須先知道自訂模型或基底模型識別碼的模型識別碼,才能執行容器。 當您執行容器時,您會指定要下載並使用的其中一個模型識別碼。
自訂模型必須使用 Speech Studio 來 訓練。 如需如何取得模型識別碼的詳細資訊,請參閱 自訂語音模型生命週期。
取得模型識別碼,用作 docker run 命令的 ModelId 參數引數。
顯示模型下載
在您執行容器前,您可以選擇性地取得可用的顯示模型資訊,並選擇將這些模型下載到語音轉換文字容器,以獲得大幅改善的最終顯示輸出。 自訂語音轉換文字容器 3.1.0 及更新版本可提供顯示模型下載。
注意
雖然您使用 docker run 命令,但容器並未啟動服務。
您可以查詢或下載下列任何或所有的顯示模型類型:重新評分 (Rescore)、標點符號 (Punct)、再分割 (Resegment) 和 wfstitn (Wfstitn)。 否則,您可以使用 FullDisplay 選項 (搭配或不搭配其他類型) 來查詢或下載所有類型的顯示模型。
設定 BaseModelLocale 以在目標地區設定上查詢最新的可用顯示模型。 如果您包含多個顯示模型類型,該命令會針對每個類型傳回最新的可用顯示模型。 例如:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
Punct Rescore Resegment Wfstitn \ # Specify `FullDisplay` or a space-separated subset of display models
BaseModelLocale={LOCALE} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
設定 DisplayLocale 以在目標地區設定上下載最新的可用顯示模型。 設定了 DisplayLocale 時,必須同時指定 FullDisplay 或以空格分隔的顯示模型子集。 該命令會下載每個指定類型的最新可用顯示模型。 例如:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
Punct Rescore Resegment Wfstitn \ # Specify `FullDisplay` or a space-separated subset of display models
DisplayLocale={LOCALE} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
設定一個模型識別碼參數以下載特定的顯示模型:重新評分 (RescoreId)、標點符號 (PunctId)、再分割 (ResegmentId) 或 wfstitn (WfstitnId)。 其運作方式與透過 ModelId 參數下載基礎模型相類似。 例如,若要下載重新評分顯示模型,您可以使用下列命令搭配 RescoreId 參數:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
RescoreId={RESCORE_MODEL_ID} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
注意
如果設定了多個查詢或下載參數,命令將會採用下列優先順序:BaseModelLocale、模型識別碼、DisplayLocale (僅適用於顯示模型)。
使用 docker run 執行容器
使用 docker run 命令來執行容器服務。
下表代表各種 docker run 參數及其對應的描述:
| 參數 | 描述 |
|---|---|
{VOLUME_MOUNT} |
主機電腦磁碟區掛接,可供 Docker 用來保存自訂模型。 例如 c:\CustomSpeech,其中,c:\ 磁碟機位於主機電腦上。 |
{MODEL_ID} |
自訂語音或基底模型識別碼。 如需詳細資訊,請參閱取得模型識別碼。 |
{ENDPOINT_URI} |
計量和帳單需要端點。 如需詳細資訊,請參閱計費引數。 |
{API_KEY} |
API 金鑰是必要的。 如需詳細資訊,請參閱計費引數。 |
當您執行自訂語音轉換文字容器時,請根據自訂語音轉換文字容器需求和建議,設定連接埠、記憶體和 CPU。
以下為具有預留位置值的範例 docker run 命令。 您必須指定 VOLUME_MOUNT、MODEL_ID、ENDPOINT_URI 和 API_KEY 值:
docker run --rm -it -p 5000:5000 --memory 8g --cpus 4 \
-v {VOLUME_MOUNT}:/usr/local/models \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
ModelId={MODEL_ID} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
此命令:
- 從容器映像執行自訂語音轉換文字容器。
- 配置 4 個 CPU 核心和 8 GB 的記憶體。
- 從磁碟區輸入掛接中載入自訂語音轉換文字模型,例如 C:\CustomSpeech。
- 公開 TCP 通訊埠 5000,並為容器配置虛擬 TTY。
- 鑒於
ModelId,請下載模型 (如果在磁碟區掛接上找不到的話)。 - 如果先前已下載自訂模型,則會忽略
ModelId。 - 在容器結束之後自動將其移除。 容器映像仍可在主機電腦上使用。
如需關於搭配語音容器執行 docker run 的詳細資訊,請參閱使用 Docker 安裝及執行語音容器。
使用該容器
語音容器會提供 Websocket 型查詢端點 API,其可透過語音 SDK 和語音 CLI 來存取。 根據預設,語音 SDK 和語音 CLI 會使用公用語音服務。 若要使用容器,您必須變更初始化方法。
重要
當您搭配容器使用語音服務時,請務必使用主機驗證。 如果您設定金鑰和區域,則要求會移至公用語音服務。 來自語音服務的結果可能並非如您預期的結果。 來自已中斷連線容器的要求將會失敗。
不要使用此 Azure 雲端初始化設定:
var config = SpeechConfig.FromSubscription(...);
搭配容器主機使用此設定:
var config = SpeechConfig.FromHost(
new Uri("ws://localhost:5000"));
不要使用此 Azure 雲端初始化設定:
auto speechConfig = SpeechConfig::FromSubscription(...);
搭配容器主機使用此設定:
auto speechConfig = SpeechConfig::FromHost("ws://localhost:5000");
不要使用此 Azure 雲端初始化設定:
speechConfig, err := speech.NewSpeechConfigFromSubscription(...)
搭配容器主機使用此設定:
speechConfig, err := speech.NewSpeechConfigFromHost("ws://localhost:5000")
不要使用此 Azure 雲端初始化設定:
SpeechConfig speechConfig = SpeechConfig.fromSubscription(...);
搭配容器主機使用此設定:
SpeechConfig speechConfig = SpeechConfig.fromHost("ws://localhost:5000");
不要使用此 Azure 雲端初始化設定:
const speechConfig = sdk.SpeechConfig.fromSubscription(...);
搭配容器主機使用此設定:
const speechConfig = sdk.SpeechConfig.fromHost("ws://localhost:5000");
不要使用此 Azure 雲端初始化設定:
SPXSpeechConfiguration *speechConfig = [[SPXSpeechConfiguration alloc] initWithSubscription:...];
搭配容器主機使用此設定:
SPXSpeechConfiguration *speechConfig = [[SPXSpeechConfiguration alloc] initWithHost:"ws://localhost:5000"];
不要使用此 Azure 雲端初始化設定:
let speechConfig = SPXSpeechConfiguration(subscription: "", region: "");
搭配容器主機使用此設定:
let speechConfig = SPXSpeechConfiguration(host: "ws://localhost:5000");
不要使用此 Azure 雲端初始化設定:
speech_config = speechsdk.SpeechConfig(
subscription=speech_key, region=service_region)
搭配容器端點使用此設定:
speech_config = speechsdk.SpeechConfig(
host="ws://localhost:5000")
當您在容器中使用語音 CLI 時,請包含 --host ws://localhost:5000/ 選項。 您也必須指定 --key none 來確保 CLI 不會嘗試使用語音金鑰進行驗證。 如需如何設定語音 CLI 的詳細資訊,請參閱開始使用 Azure AI 語音 CLI。
使用主機驗證而非金鑰和區域,嘗試語音轉換文字快速入門。
下一步
- 請參閱語音容器概觀
- 檢閱設定容器以了解組態設定
- 使用更多 Azure AI 容器