快速入門:辨識語音並轉換成文字
重要
本文中標示為 (預覽) 的項目目前處於公開預覽狀態。 此預覽版本沒有服務等級協定,不建議將其用於生產工作負載。 可能不支援特定功能,或可能已經限制功能。 如需詳細資訊,請參閱 Microsoft Azure 預覽版增補使用條款。
在本快速入門中,您會在 Azure AI Foundry 中嘗試即時語音轉換文字。
必要條件
- Azure 訂用帳戶 - 建立免費帳戶。
- 某些 Azure AI 服務功能可在 Azure AI Foundry 入口網站中免費試用。 若要存取本文中所述的所有功能,您需要 在 Azure AI Foundry 中連接 AI 服務。
嘗試即時語音轉換文字:
移至您的 Azure AI Foundry 專案。 如果您需要建立專案,請參閱 建立 Azure AI Foundry 專案。
從左窗格中選取 [遊樂場 ],然後選取要使用的遊樂場。 在此範例中,選取 [ 試用語音遊樂場]。

您可以選擇性地選取不同的連線,以在遊樂場中使用。 在語音遊樂場中,您可以連線到 Azure AI Services 多服務資源或語音服務資源。

選取 [實時轉譯]。
選取 [顯示進階選項] 來設定語音轉換文字選項,例如:
- 語言識別: 用來根據支援的語言清單比較識別音訊中的口說語言。 如需語言識別選項的詳細資訊,例如開始和連續辨識,請參閱語言識別。
- 說話者自動分段標記: 用來識別和分隔音訊中說話者的段落。 自動分段標記針對參與交談的不同說話者進行區分。 語音服務提供有關哪位說話者正在講出所謄寫語音之特定部分的資訊。 如需說話者自動分段標記的詳細資訊,請參閱使用說話者自動分段標記即時語音轉換文字快速入門。
- 自訂端點: 使用自訂語音的已部署模型來改善辨識正確性。 若要使用 Microsoft 的基準模型,請將此設定保留為 None。 如需自訂語音的詳細資訊,請參閱自訂語音。
- 輸出格式: 選擇簡單和詳細的輸出格式。 包含格式和時間戳記的簡易輸出。 詳細的輸出包含更多格式 (例如顯示、語彙、ITN 和遮罩 ITN)、時間戳記和 N 最佳列表。
- 片語清單: 透過提供已知片語清單,例如人員名稱或特定位置,以改善謄寫正確性。 使用逗號或分號分隔片語清單中的每個值。 如需片語清單的詳細資訊,請參閱 片語清單。
選取要上傳的音訊檔案,或即時錄製音訊。 在此範例中,我們使用 GitHub 上語音 SDK 存放庫中可用的
Call1_separated_16k_health_insurance.wav檔案。 您可以下載檔案或使用自己的音訊檔案。
您可以在頁面底部檢視實時轉譯。
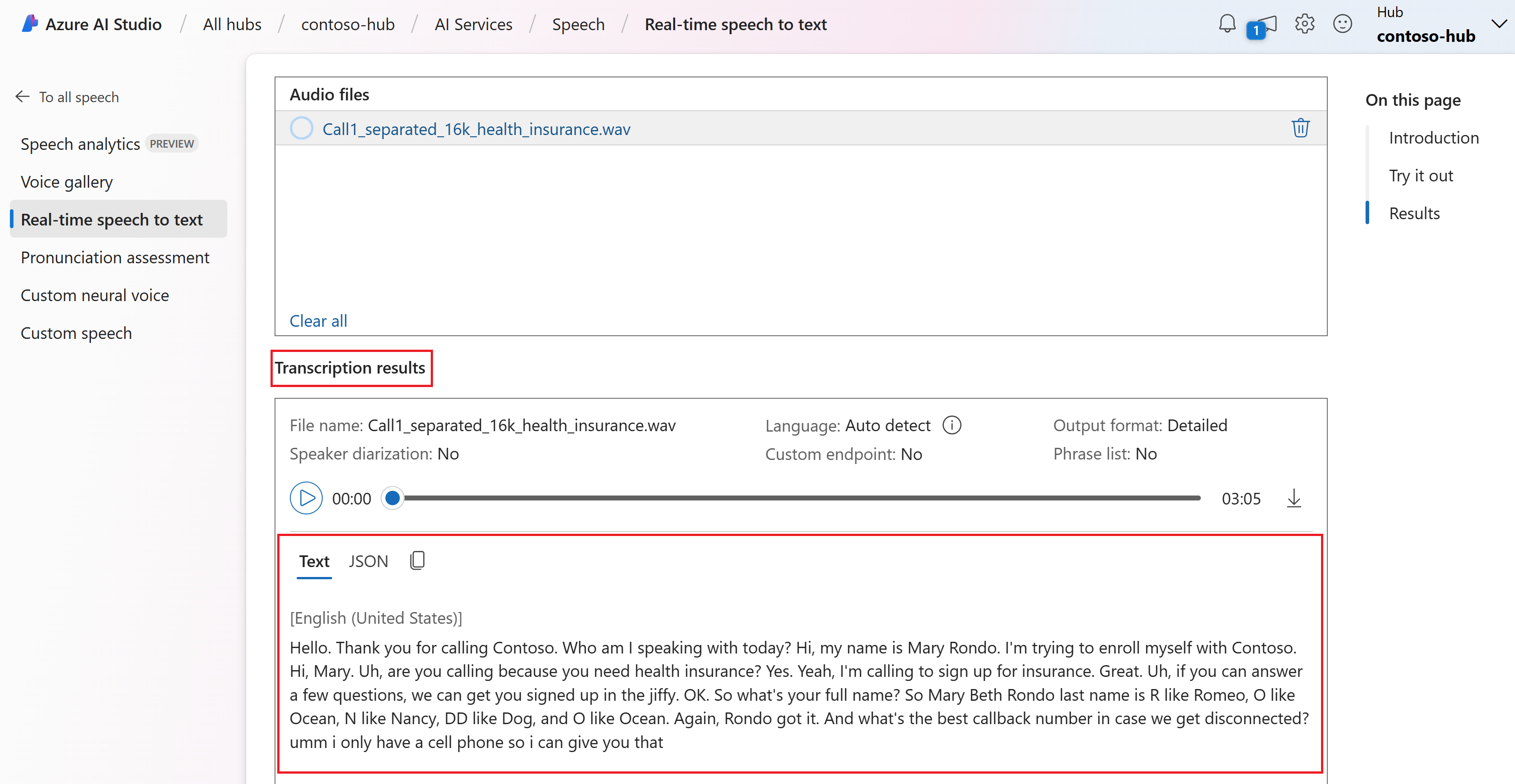
您可以選取 [JSON] 索引標籤,以查看轉譯的 JSON 輸出。 屬性包括
Offset、Duration、RecognitionStatus、Display、Lexical、ITN等等。





參考文件 | 套件 (NuGet) | GitHub 上的其他範例
在此快速入門中,您會建立並執行應用程式,以即時辨識和轉譯語音轉換文字。
若要改為以非同步方式轉譯音訊檔案,請參閱什麼是批次轉譯。 如果您不確定哪個語音轉換文字解決方案適合您,請參閱什麼是語音轉換文字?
必要條件
- Azure 訂用帳戶。 您可以免費建立一個訂用帳戶。
- 在 Azure 入口網站上建立語音資源。
- 取得語音資源金鑰和區域。 部署語音資源之後,選取 [移至資源] 以檢視和管理索引鍵。
設定環境
語音 SDK 可以 NuGet 套件的形式取得,並且實作 .NET Standard 2.0。 您稍後會在本指南中安裝語音 SDK。 如有任何其他需求,請參閱安裝語音 SDK。
設定環境變數
您必須驗證應用程式以存取 Azure AI 服務。 本文說明如何使用環境變數來儲存您的認證。 然後,您可以從程式碼存取環境變數,以驗證您的應用程式。 針對實際執行環境,使用更安全的方法來儲存和存取您的認證。
重要
我們建議使用適用於 Azure 資源的受控識別搭配 Microsoft Entra ID 驗證,以避免使用在雲端執行的應用程式儲存認證。
如果您使用 API 金鑰,請將其安全地儲存在別處,例如 Azure Key Vault。 請勿在程式碼中直接包含 API 金鑰,且切勿公開張貼金鑰。
如需 AI 服務安全性的詳細資訊,請參閱驗證對 Azure AI 服務的要求。
若要設定語音資源索引鍵和區域的環境變數,請開啟主控台視窗,並遵循作業系統和開發環境的指示進行。
- 若要設定
SPEECH_KEY環境變數,請以您其中一個資源金鑰取代 your-key。 - 若要設定
SPEECH_REGION環境變數,請以您的其中一個資源區域取代 your-region。
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
注意
如果您只需要存取目前主控台的環境變數,您可以使用 set (而不是 setx) 來設定環境變數。
新增環境變數之後,您可能需要重新啟動任何需要讀取環境變數的程式,包括主控台視窗。 例如,如果正在使用 Visual Studio 作為編輯器,請您在執行範例前重新啟動 Visual Studio。
從麥克風辨識語音
提示
試用 Azure AI 語音工具組,輕鬆地在 Visual Studio Code 上建置和執行範例。
遵循下列步驟來建立主控台應用程式並安裝語音 SDK。
在資料夾開啟要新增專案的命令提示字元視窗。 執行此命令以使用 .NET CLI 建立主控台應用程式。
dotnet new console此命令會在您的專案目錄中建立 Program.cs 檔案。
使用 .NET CLI 在新專案中安裝語音 SDK。
dotnet add package Microsoft.CognitiveServices.Speech使用下列程式碼取代 Program.cs 的內容:
using System; using System.IO; using System.Threading.Tasks; using Microsoft.CognitiveServices.Speech; using Microsoft.CognitiveServices.Speech.Audio; class Program { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" static string speechKey = Environment.GetEnvironmentVariable("SPEECH_KEY"); static string speechRegion = Environment.GetEnvironmentVariable("SPEECH_REGION"); static void OutputSpeechRecognitionResult(SpeechRecognitionResult speechRecognitionResult) { switch (speechRecognitionResult.Reason) { case ResultReason.RecognizedSpeech: Console.WriteLine($"RECOGNIZED: Text={speechRecognitionResult.Text}"); break; case ResultReason.NoMatch: Console.WriteLine($"NOMATCH: Speech could not be recognized."); break; case ResultReason.Canceled: var cancellation = CancellationDetails.FromResult(speechRecognitionResult); Console.WriteLine($"CANCELED: Reason={cancellation.Reason}"); if (cancellation.Reason == CancellationReason.Error) { Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}"); Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}"); Console.WriteLine($"CANCELED: Did you set the speech resource key and region values?"); } break; } } async static Task Main(string[] args) { var speechConfig = SpeechConfig.FromSubscription(speechKey, speechRegion); speechConfig.SpeechRecognitionLanguage = "en-US"; using var audioConfig = AudioConfig.FromDefaultMicrophoneInput(); using var speechRecognizer = new SpeechRecognizer(speechConfig, audioConfig); Console.WriteLine("Speak into your microphone."); var speechRecognitionResult = await speechRecognizer.RecognizeOnceAsync(); OutputSpeechRecognitionResult(speechRecognitionResult); } }若要變更語音辨識語言,請以另一種支援的語言取代
en-US。 例如,es-ES為西班牙文 (西班牙)。 如果您未指定任何語言,則預設值為en-US。 如需詳細了解如何識別所可能說出的多種語言之一,請參閱語言識別。執行新的主控台應用程式,以從麥克風啟動語音辨識:
dotnet run重要
確保您已設定
SPEECH_KEY和SPEECH_REGION環境變數。 如果您未設定這些變數,則範例會失敗,並顯示錯誤訊息。出現提示時,請用麥克風說話。 您說話的內容應該會以文字的形式顯示:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
備註
一些其他考量:
此範例使用
RecognizeOnceAsync作業來轉換最長 30 秒的語句,或直到偵測到無聲為止。 如需較長音訊的連續辨識相關資訊 (包括多語系交談),請參閱如何辨識語音。若要從音訊檔案辨識語音,請使用
FromWavFileInput,而不是FromDefaultMicrophoneInput:using var audioConfig = AudioConfig.FromWavFileInput("YourAudioFile.wav");針對 MP4 之類的壓縮音訊檔案,請安裝 GStreamer 並使用
PullAudioInputStream或PushAudioInputStream。 如需詳細資訊,請參閱如何使用壓縮的輸入音訊。
清除資源
您可以使用 Azure 入口網站或 Azure 命令列介面 (CLI) 來移除您所建立的語音資源。
參考文件 | 套件 (NuGet) | GitHub 上的其他範例
在此快速入門中,您會建立並執行應用程式,以即時辨識和轉譯語音轉換文字。
若要改為以非同步方式轉譯音訊檔案,請參閱什麼是批次轉譯。 如果您不確定哪個語音轉換文字解決方案適合您,請參閱什麼是語音轉換文字?
必要條件
- Azure 訂用帳戶。 您可以免費建立一個訂用帳戶。
- 在 Azure 入口網站上建立語音資源。
- 取得語音資源金鑰和區域。 部署語音資源之後,選取 [移至資源] 以檢視和管理索引鍵。
設定環境
語音 SDK 可以 NuGet 套件的形式取得,並且實作 .NET Standard 2.0。 您稍後會在本指南中安裝語音 SDK。 如有其他需求,請參閱安裝語音 SDK。
設定環境變數
您必須驗證應用程式以存取 Azure AI 服務。 本文說明如何使用環境變數來儲存您的認證。 然後,您可以從程式碼存取環境變數,以驗證您的應用程式。 針對實際執行環境,使用更安全的方法來儲存和存取您的認證。
重要
我們建議使用適用於 Azure 資源的受控識別搭配 Microsoft Entra ID 驗證,以避免使用在雲端執行的應用程式儲存認證。
如果您使用 API 金鑰,請將其安全地儲存在別處,例如 Azure Key Vault。 請勿在程式碼中直接包含 API 金鑰,且切勿公開張貼金鑰。
如需 AI 服務安全性的詳細資訊,請參閱驗證對 Azure AI 服務的要求。
若要設定語音資源索引鍵和區域的環境變數,請開啟主控台視窗,並遵循作業系統和開發環境的指示進行。
- 若要設定
SPEECH_KEY環境變數,請以您其中一個資源金鑰取代 your-key。 - 若要設定
SPEECH_REGION環境變數,請以您的其中一個資源區域取代 your-region。
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
注意
如果您只需要存取目前主控台的環境變數,您可以使用 set (而不是 setx) 來設定環境變數。
新增環境變數之後,您可能需要重新啟動任何需要讀取環境變數的程式,包括主控台視窗。 例如,如果正在使用 Visual Studio 作為編輯器,請您在執行範例前重新啟動 Visual Studio。
從麥克風辨識語音
提示
試用 Azure AI 語音工具組,輕鬆地在 Visual Studio Code 上建置和執行範例。
遵循下列步驟來建立主控台應用程式並安裝語音 SDK。
在 Visual Studio Community 中建立名為
SpeechRecognition的新 C++ 主控台專案。選取 [工具]>[Nuget 套件管理員]>[套件管理員主控台]。 在套件管理員主控台中,執行此命令。
Install-Package Microsoft.CognitiveServices.Speech以下列程式碼取代
SpeechRecognition.cpp的內容:#include <iostream> #include <stdlib.h> #include <speechapi_cxx.h> using namespace Microsoft::CognitiveServices::Speech; using namespace Microsoft::CognitiveServices::Speech::Audio; std::string GetEnvironmentVariable(const char* name); int main() { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" auto speechKey = GetEnvironmentVariable("SPEECH_KEY"); auto speechRegion = GetEnvironmentVariable("SPEECH_REGION"); if ((size(speechKey) == 0) || (size(speechRegion) == 0)) { std::cout << "Please set both SPEECH_KEY and SPEECH_REGION environment variables." << std::endl; return -1; } auto speechConfig = SpeechConfig::FromSubscription(speechKey, speechRegion); speechConfig->SetSpeechRecognitionLanguage("en-US"); auto audioConfig = AudioConfig::FromDefaultMicrophoneInput(); auto speechRecognizer = SpeechRecognizer::FromConfig(speechConfig, audioConfig); std::cout << "Speak into your microphone.\n"; auto result = speechRecognizer->RecognizeOnceAsync().get(); if (result->Reason == ResultReason::RecognizedSpeech) { std::cout << "RECOGNIZED: Text=" << result->Text << std::endl; } else if (result->Reason == ResultReason::NoMatch) { std::cout << "NOMATCH: Speech could not be recognized." << std::endl; } else if (result->Reason == ResultReason::Canceled) { auto cancellation = CancellationDetails::FromResult(result); std::cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl; if (cancellation->Reason == CancellationReason::Error) { std::cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl; std::cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl; std::cout << "CANCELED: Did you set the speech resource key and region values?" << std::endl; } } } std::string GetEnvironmentVariable(const char* name) { #if defined(_MSC_VER) size_t requiredSize = 0; (void)getenv_s(&requiredSize, nullptr, 0, name); if (requiredSize == 0) { return ""; } auto buffer = std::make_unique<char[]>(requiredSize); (void)getenv_s(&requiredSize, buffer.get(), requiredSize, name); return buffer.get(); #else auto value = getenv(name); return value ? value : ""; #endif }若要變更語音辨識語言,請以另一種支援的語言取代
en-US。 例如,es-ES為西班牙文 (西班牙)。 如果您未指定任何語言,則預設值為en-US。 如需詳細了解如何識別所可能說出的多種語言之一,請參閱語言識別。組建並執行新的主控台應用程式,以從麥克風啟動語音辨識。
重要
確保您已設定
SPEECH_KEY和SPEECH_REGION環境變數。 如果您未設定這些變數,則範例會失敗,並顯示錯誤訊息。出現提示時,請用麥克風說話。 您說話的內容應該會以文字的形式顯示:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
備註
一些其他考量:
此範例使用
RecognizeOnceAsync作業來轉換最長 30 秒的語句,或直到偵測到無聲為止。 如需較長音訊的連續辨識相關資訊 (包括多語系交談),請參閱如何辨識語音。若要從音訊檔案辨識語音,請使用
FromWavFileInput,而不是FromDefaultMicrophoneInput:auto audioConfig = AudioConfig::FromWavFileInput("YourAudioFile.wav");針對 MP4 之類的壓縮音訊檔案,請安裝 GStreamer 並使用
PullAudioInputStream或PushAudioInputStream。 如需詳細資訊,請參閱如何使用壓縮的輸入音訊。
清除資源
您可以使用 Azure 入口網站或 Azure 命令列介面 (CLI) 來移除您所建立的語音資源。
參考文件 | 套件 (Go) | GitHub 上的其他範例
在此快速入門中,您會建立並執行應用程式,以即時辨識和轉譯語音轉換文字。
若要改為以非同步方式轉譯音訊檔案,請參閱什麼是批次轉譯。 如果您不確定哪個語音轉換文字解決方案適合您,請參閱什麼是語音轉換文字?
必要條件
- Azure 訂用帳戶。 您可以免費建立一個訂用帳戶。
- 在 Azure 入口網站上建立語音資源。
- 取得語音資源金鑰和區域。 部署語音資源之後,選取 [移至資源] 以檢視和管理索引鍵。
設定環境
安裝適用於 Go 的語音 SDK。 如需需求和指示,請參閱 安裝語音 SDK。
設定環境變數
您必須驗證應用程式以存取 Azure AI 服務。 本文說明如何使用環境變數來儲存您的認證。 然後,您可以從程式碼存取環境變數,以驗證您的應用程式。 針對實際執行環境,使用更安全的方法來儲存和存取您的認證。
重要
我們建議使用適用於 Azure 資源的受控識別搭配 Microsoft Entra ID 驗證,以避免使用在雲端執行的應用程式儲存認證。
如果您使用 API 金鑰,請將其安全地儲存在別處,例如 Azure Key Vault。 請勿在程式碼中直接包含 API 金鑰,且切勿公開張貼金鑰。
如需 AI 服務安全性的詳細資訊,請參閱驗證對 Azure AI 服務的要求。
若要設定語音資源索引鍵和區域的環境變數,請開啟主控台視窗,並遵循作業系統和開發環境的指示進行。
- 若要設定
SPEECH_KEY環境變數,請以您其中一個資源金鑰取代 your-key。 - 若要設定
SPEECH_REGION環境變數,請以您的其中一個資源區域取代 your-region。
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
注意
如果您只需要存取目前主控台的環境變數,您可以使用 set (而不是 setx) 來設定環境變數。
新增環境變數之後,您可能需要重新啟動任何需要讀取環境變數的程式,包括主控台視窗。 例如,如果正在使用 Visual Studio 作為編輯器,請您在執行範例前重新啟動 Visual Studio。
從麥克風辨識語音
遵循下列步驟來建立 GO 模組。
在資料夾開啟要新增專案的命令提示字元視窗。 建立名為 speech-recognition.go 的新檔案。
將下列程式碼複製到 speech-recognition.go:
package main import ( "bufio" "fmt" "os" "github.com/Microsoft/cognitive-services-speech-sdk-go/audio" "github.com/Microsoft/cognitive-services-speech-sdk-go/speech" ) func sessionStartedHandler(event speech.SessionEventArgs) { defer event.Close() fmt.Println("Session Started (ID=", event.SessionID, ")") } func sessionStoppedHandler(event speech.SessionEventArgs) { defer event.Close() fmt.Println("Session Stopped (ID=", event.SessionID, ")") } func recognizingHandler(event speech.SpeechRecognitionEventArgs) { defer event.Close() fmt.Println("Recognizing:", event.Result.Text) } func recognizedHandler(event speech.SpeechRecognitionEventArgs) { defer event.Close() fmt.Println("Recognized:", event.Result.Text) } func cancelledHandler(event speech.SpeechRecognitionCanceledEventArgs) { defer event.Close() fmt.Println("Received a cancellation: ", event.ErrorDetails) fmt.Println("Did you set the speech resource key and region values?") } func main() { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" speechKey := os.Getenv("SPEECH_KEY") speechRegion := os.Getenv("SPEECH_REGION") audioConfig, err := audio.NewAudioConfigFromDefaultMicrophoneInput() if err != nil { fmt.Println("Got an error: ", err) return } defer audioConfig.Close() speechConfig, err := speech.NewSpeechConfigFromSubscription(speechKey, speechRegion) if err != nil { fmt.Println("Got an error: ", err) return } defer speechConfig.Close() speechRecognizer, err := speech.NewSpeechRecognizerFromConfig(speechConfig, audioConfig) if err != nil { fmt.Println("Got an error: ", err) return } defer speechRecognizer.Close() speechRecognizer.SessionStarted(sessionStartedHandler) speechRecognizer.SessionStopped(sessionStoppedHandler) speechRecognizer.Recognizing(recognizingHandler) speechRecognizer.Recognized(recognizedHandler) speechRecognizer.Canceled(cancelledHandler) speechRecognizer.StartContinuousRecognitionAsync() defer speechRecognizer.StopContinuousRecognitionAsync() bufio.NewReader(os.Stdin).ReadBytes('\n') }執行下列命令來建立 go.mod 檔案,該檔案會連結至 Github 上託管的元件:
go mod init speech-recognition go get github.com/Microsoft/cognitive-services-speech-sdk-go重要
確保您已設定
SPEECH_KEY和SPEECH_REGION環境變數。 如果您未設定這些變數,則範例會失敗,並顯示錯誤訊息。建置並執行程式碼:
go build go run speech-recognition
清除資源
您可以使用 Azure 入口網站或 Azure 命令列介面 (CLI) 來移除您所建立的語音資源。
在此快速入門中,您會建立並執行應用程式,以即時辨識和轉譯語音轉換文字。
若要改為以非同步方式轉譯音訊檔案,請參閱什麼是批次轉譯。 如果您不確定哪個語音轉換文字解決方案適合您,請參閱什麼是語音轉換文字?
必要條件
- Azure 訂用帳戶。 您可以免費建立一個訂用帳戶。
- 在 Azure 入口網站上建立語音資源。
- 取得語音資源金鑰和區域。 部署語音資源之後,選取 [移至資源] 以檢視和管理索引鍵。
設定環境
若要設定環境,請 安裝語音 SDK。 本快速入門中的範例適用於 JAVA 執行階段。
安裝 Apache Maven。 然後執行
mvn -v以確認安裝成功。在專案的根目錄中建立新
pom.xml檔案,並將下列程式碼複製到其中:<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.microsoft.cognitiveservices.speech.samples</groupId> <artifactId>quickstart-eclipse</artifactId> <version>1.0.0-SNAPSHOT</version> <build> <sourceDirectory>src</sourceDirectory> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.7.0</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> </plugins> </build> <dependencies> <dependency> <groupId>com.microsoft.cognitiveservices.speech</groupId> <artifactId>client-sdk</artifactId> <version>1.42.0</version> </dependency> </dependencies> </project>安裝語音 SDK 和相依性。
mvn clean dependency:copy-dependencies
設定環境變數
您必須驗證應用程式以存取 Azure AI 服務。 本文說明如何使用環境變數來儲存您的認證。 然後,您可以從程式碼存取環境變數,以驗證您的應用程式。 針對實際執行環境,使用更安全的方法來儲存和存取您的認證。
重要
我們建議使用適用於 Azure 資源的受控識別搭配 Microsoft Entra ID 驗證,以避免使用在雲端執行的應用程式儲存認證。
如果您使用 API 金鑰,請將其安全地儲存在別處,例如 Azure Key Vault。 請勿在程式碼中直接包含 API 金鑰,且切勿公開張貼金鑰。
如需 AI 服務安全性的詳細資訊,請參閱驗證對 Azure AI 服務的要求。
若要設定語音資源索引鍵和區域的環境變數,請開啟主控台視窗,並遵循作業系統和開發環境的指示進行。
- 若要設定
SPEECH_KEY環境變數,請以您其中一個資源金鑰取代 your-key。 - 若要設定
SPEECH_REGION環境變數,請以您的其中一個資源區域取代 your-region。
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
注意
如果您只需要存取目前主控台的環境變數,您可以使用 set (而不是 setx) 來設定環境變數。
新增環境變數之後,您可能需要重新啟動任何需要讀取環境變數的程式,包括主控台視窗。 例如,如果正在使用 Visual Studio 作為編輯器,請您在執行範例前重新啟動 Visual Studio。
從麥克風辨識語音
遵循下列步驟來建立新的主控台應用程式,以進行語音辨識。
在相同的專案根目錄中建立名為 SpeechRecognition.java 的新檔案。
將下列程式碼複製到 SpeechRecognition.java:
import com.microsoft.cognitiveservices.speech.*; import com.microsoft.cognitiveservices.speech.audio.AudioConfig; import java.util.concurrent.ExecutionException; import java.util.concurrent.Future; public class SpeechRecognition { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" private static String speechKey = System.getenv("SPEECH_KEY"); private static String speechRegion = System.getenv("SPEECH_REGION"); public static void main(String[] args) throws InterruptedException, ExecutionException { SpeechConfig speechConfig = SpeechConfig.fromSubscription(speechKey, speechRegion); speechConfig.setSpeechRecognitionLanguage("en-US"); recognizeFromMicrophone(speechConfig); } public static void recognizeFromMicrophone(SpeechConfig speechConfig) throws InterruptedException, ExecutionException { AudioConfig audioConfig = AudioConfig.fromDefaultMicrophoneInput(); SpeechRecognizer speechRecognizer = new SpeechRecognizer(speechConfig, audioConfig); System.out.println("Speak into your microphone."); Future<SpeechRecognitionResult> task = speechRecognizer.recognizeOnceAsync(); SpeechRecognitionResult speechRecognitionResult = task.get(); if (speechRecognitionResult.getReason() == ResultReason.RecognizedSpeech) { System.out.println("RECOGNIZED: Text=" + speechRecognitionResult.getText()); } else if (speechRecognitionResult.getReason() == ResultReason.NoMatch) { System.out.println("NOMATCH: Speech could not be recognized."); } else if (speechRecognitionResult.getReason() == ResultReason.Canceled) { CancellationDetails cancellation = CancellationDetails.fromResult(speechRecognitionResult); System.out.println("CANCELED: Reason=" + cancellation.getReason()); if (cancellation.getReason() == CancellationReason.Error) { System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode()); System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails()); System.out.println("CANCELED: Did you set the speech resource key and region values?"); } } System.exit(0); } }若要變更語音辨識語言,請以另一種支援的語言取代
en-US。 例如,es-ES為西班牙文 (西班牙)。 如果您未指定任何語言,則預設值為en-US。 如需詳細了解如何識別所可能說出的多種語言之一,請參閱語言識別。執行新的主控台應用程式,以從麥克風啟動語音辨識:
javac SpeechRecognition.java -cp ".;target\dependency\*" java -cp ".;target\dependency\*" SpeechRecognition重要
確保您已設定
SPEECH_KEY和SPEECH_REGION環境變數。 如果您未設定這些變數,則範例會失敗,並顯示錯誤訊息。出現提示時,請用麥克風說話。 您說話的內容應該會以文字的形式顯示:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
備註
一些其他考量:
此範例使用
RecognizeOnceAsync作業來轉換最長 30 秒的語句,或直到偵測到無聲為止。 如需較長音訊的連續辨識相關資訊 (包括多語系交談),請參閱如何辨識語音。若要從音訊檔案辨識語音,請使用
fromWavFileInput,而不是fromDefaultMicrophoneInput:AudioConfig audioConfig = AudioConfig.fromWavFileInput("YourAudioFile.wav");針對 MP4 之類的壓縮音訊檔案,請安裝 GStreamer 並使用
PullAudioInputStream或PushAudioInputStream。 如需詳細資訊,請參閱如何使用壓縮的輸入音訊。
清除資源
您可以使用 Azure 入口網站或 Azure 命令列介面 (CLI) 來移除您所建立的語音資源。
參考文件 | 套件 (npm) | GitHub 上的其他範例 | 程式庫原始程式碼
在此快速入門中,您會建立並執行應用程式,以即時辨識和轉譯語音轉換文字。
若要改為以非同步方式轉譯音訊檔案,請參閱什麼是批次轉譯。 如果您不確定哪個語音轉換文字解決方案適合您,請參閱什麼是語音轉換文字?
必要條件
- Azure 訂用帳戶。 您可以免費建立一個訂用帳戶。
- 在 Azure 入口網站上建立語音資源。
- 取得語音資源金鑰和區域。 部署語音資源之後,選取 [移至資源] 以檢視和管理索引鍵。
您也需要本機電腦上的 .wav 音訊檔案。 您可以使用自己的 .wav 檔案 (最多 30 秒) 或下載 https://crbn.us/whatstheweatherlike.wav 範例檔案。
設定環境
若要設定環境,請安裝適用於 JavaScript 的語音 SDK。 執行此命令︰npm install microsoft-cognitiveservices-speech-sdk。 如需安裝指示,請參閱安裝語音 SDK。
設定環境變數
您必須驗證應用程式以存取 Azure AI 服務。 本文說明如何使用環境變數來儲存您的認證。 然後,您可以從程式碼存取環境變數,以驗證您的應用程式。 針對實際執行環境,使用更安全的方法來儲存和存取您的認證。
重要
我們建議使用適用於 Azure 資源的受控識別搭配 Microsoft Entra ID 驗證,以避免使用在雲端執行的應用程式儲存認證。
如果您使用 API 金鑰,請將其安全地儲存在別處,例如 Azure Key Vault。 請勿在程式碼中直接包含 API 金鑰,且切勿公開張貼金鑰。
如需 AI 服務安全性的詳細資訊,請參閱驗證對 Azure AI 服務的要求。
若要設定語音資源索引鍵和區域的環境變數,請開啟主控台視窗,並遵循作業系統和開發環境的指示進行。
- 若要設定
SPEECH_KEY環境變數,請以您其中一個資源金鑰取代 your-key。 - 若要設定
SPEECH_REGION環境變數,請以您的其中一個資源區域取代 your-region。
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
注意
如果您只需要存取目前主控台的環境變數,您可以使用 set (而不是 setx) 來設定環境變數。
新增環境變數之後,您可能需要重新啟動任何需要讀取環境變數的程式,包括主控台視窗。 例如,如果正在使用 Visual Studio 作為編輯器,請您在執行範例前重新啟動 Visual Studio。
從檔案辨識語音
提示
試用 Azure AI 語音工具組,輕鬆地在 Visual Studio Code 上建置和執行範例。
請遵循下列步驟來建立 Node.js 主控台應用程式進行語音辨識。
開啟要新增專案的命令提示視窗,然後建立名為 SpeechRecognition.js 的新檔案。
安裝適用於 JavaScript 的語音 SDK:
npm install microsoft-cognitiveservices-speech-sdk將下列程式碼複製到 SpeechRecognition.js:
const fs = require("fs"); const sdk = require("microsoft-cognitiveservices-speech-sdk"); // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" const speechConfig = sdk.SpeechConfig.fromSubscription(process.env.SPEECH_KEY, process.env.SPEECH_REGION); speechConfig.speechRecognitionLanguage = "en-US"; function fromFile() { let audioConfig = sdk.AudioConfig.fromWavFileInput(fs.readFileSync("YourAudioFile.wav")); let speechRecognizer = new sdk.SpeechRecognizer(speechConfig, audioConfig); speechRecognizer.recognizeOnceAsync(result => { switch (result.reason) { case sdk.ResultReason.RecognizedSpeech: console.log(`RECOGNIZED: Text=${result.text}`); break; case sdk.ResultReason.NoMatch: console.log("NOMATCH: Speech could not be recognized."); break; case sdk.ResultReason.Canceled: const cancellation = sdk.CancellationDetails.fromResult(result); console.log(`CANCELED: Reason=${cancellation.reason}`); if (cancellation.reason == sdk.CancellationReason.Error) { console.log(`CANCELED: ErrorCode=${cancellation.ErrorCode}`); console.log(`CANCELED: ErrorDetails=${cancellation.errorDetails}`); console.log("CANCELED: Did you set the speech resource key and region values?"); } break; } speechRecognizer.close(); }); } fromFile();在 SpeechRecognition.js 中,將 YourAudioFile.wav 取代為您自己的 .wav 檔案。 此範例只會辨識 .wav 檔案中的語音。 如需其他音訊格式的資訊,請參閱如何使用壓縮的輸入音訊。 此範例支援最多 30 秒的音訊。
若要變更語音辨識語言,請以另一種支援的語言取代
en-US。 例如,es-ES為西班牙文 (西班牙)。 如果您未指定任何語言,則預設值為en-US。 如需詳細了解如何識別所可能說出的多種語言之一,請參閱語言識別。執行新的主控台應用程式,以從檔案啟動語音辨識:
node.exe SpeechRecognition.js重要
確保您已設定
SPEECH_KEY和SPEECH_REGION環境變數。 如果您未設定這些變數,則範例會失敗,並顯示錯誤訊息。音訊檔案中的語音應輸出為文字:
RECOGNIZED: Text=I'm excited to try speech to text.
備註
此範例使用 recognizeOnceAsync 作業來轉換最長 30 秒的語句,或直到偵測到無聲為止。 如需較長音訊的連續辨識相關資訊 (包括多語系交談),請參閱如何辨識語音。
注意
Node.js 不支援從麥克風辨識語音。 這項功能僅在瀏覽器型 JavaScript 環境中受到支援。 如需詳細資訊,請參閱 React 範例,以及 GitHub 上的從麥克風進行語音轉換文字實作。
React 範例會顯示驗證權杖交換和管理的設計模式。 該範例也會顯示要進行語音轉換文字時從麥克風或檔案的音訊擷取。
清除資源
您可以使用 Azure 入口網站或 Azure 命令列介面 (CLI) 來移除您所建立的語音資源。
參考文件 | 套件 (PyPi) | GitHub 上的其他範例
在此快速入門中,您會建立並執行應用程式,以即時辨識和轉譯語音轉換文字。
若要改為以非同步方式轉譯音訊檔案,請參閱什麼是批次轉譯。 如果您不確定哪個語音轉換文字解決方案適合您,請參閱什麼是語音轉換文字?
必要條件
- Azure 訂用帳戶。 您可以免費建立一個訂用帳戶。
- 在 Azure 入口網站上建立語音資源。
- 取得語音資源金鑰和區域。 部署語音資源之後,選取 [移至資源] 以檢視和管理索引鍵。
設定環境
適用於 Python 的語音 SDK 會以 Python 套件索引 (PyPI) 模組的形式提供。 適用於 Python 的語音 SDK 與 Windows、Linux 和 macOS 相容。
- 在 Windows 上,請為平台安裝適用於 Visual Studio 2015、2017、2019 和 2022 的 Microsoft Visual C++ 可轉散發套件。 第一次安裝此套件時可能需要重新啟動。
- 在 Linux 上,您必須使用 x64 目標架構。
安裝 Python 從 3.7 或更新的版本。 如有其他需求,請參閱安裝語音 SDK。
設定環境變數
您必須驗證應用程式以存取 Azure AI 服務。 本文說明如何使用環境變數來儲存您的認證。 然後,您可以從程式碼存取環境變數,以驗證您的應用程式。 針對實際執行環境,使用更安全的方法來儲存和存取您的認證。
重要
我們建議使用適用於 Azure 資源的受控識別搭配 Microsoft Entra ID 驗證,以避免使用在雲端執行的應用程式儲存認證。
如果您使用 API 金鑰,請將其安全地儲存在別處,例如 Azure Key Vault。 請勿在程式碼中直接包含 API 金鑰,且切勿公開張貼金鑰。
如需 AI 服務安全性的詳細資訊,請參閱驗證對 Azure AI 服務的要求。
若要設定語音資源索引鍵和區域的環境變數,請開啟主控台視窗,並遵循作業系統和開發環境的指示進行。
- 若要設定
SPEECH_KEY環境變數,請以您其中一個資源金鑰取代 your-key。 - 若要設定
SPEECH_REGION環境變數,請以您的其中一個資源區域取代 your-region。
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
注意
如果您只需要存取目前主控台的環境變數,您可以使用 set (而不是 setx) 來設定環境變數。
新增環境變數之後,您可能需要重新啟動任何需要讀取環境變數的程式,包括主控台視窗。 例如,如果正在使用 Visual Studio 作為編輯器,請您在執行範例前重新啟動 Visual Studio。
從麥克風辨識語音
提示
試用 Azure AI 語音工具組,輕鬆地在 Visual Studio Code 上建置和執行範例。
請遵循下列步驟以建立主控台應用程式。
在資料夾開啟要新增專案的命令提示字元視窗。 建立名為 speech_recognition.py 的新檔案。
執行此命令以安裝語音 SDK:
pip install azure-cognitiveservices-speech將下列程式碼複製到 speech_recognition.py:
import os import azure.cognitiveservices.speech as speechsdk def recognize_from_microphone(): # This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" speech_config = speechsdk.SpeechConfig(subscription=os.environ.get('SPEECH_KEY'), region=os.environ.get('SPEECH_REGION')) speech_config.speech_recognition_language="en-US" audio_config = speechsdk.audio.AudioConfig(use_default_microphone=True) speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config) print("Speak into your microphone.") speech_recognition_result = speech_recognizer.recognize_once_async().get() if speech_recognition_result.reason == speechsdk.ResultReason.RecognizedSpeech: print("Recognized: {}".format(speech_recognition_result.text)) elif speech_recognition_result.reason == speechsdk.ResultReason.NoMatch: print("No speech could be recognized: {}".format(speech_recognition_result.no_match_details)) elif speech_recognition_result.reason == speechsdk.ResultReason.Canceled: cancellation_details = speech_recognition_result.cancellation_details print("Speech Recognition canceled: {}".format(cancellation_details.reason)) if cancellation_details.reason == speechsdk.CancellationReason.Error: print("Error details: {}".format(cancellation_details.error_details)) print("Did you set the speech resource key and region values?") recognize_from_microphone()若要變更語音辨識語言,請以另一種支援的語言取代
en-US。 例如,es-ES為西班牙文 (西班牙)。 如果您未指定任何語言,則預設值為en-US。 如需詳細了解如何識別所可能說出的多種語言之一,請參閱語言識別。執行新的主控台應用程式,以從麥克風啟動語音辨識:
python speech_recognition.py重要
確保您已設定
SPEECH_KEY和SPEECH_REGION環境變數。 如果您未設定這些變數,則範例會失敗,並顯示錯誤訊息。出現提示時,請用麥克風說話。 您說話的內容應該會以文字的形式顯示:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
備註
一些其他考量:
此範例使用
recognize_once_async作業來轉換最長 30 秒的語句,或直到偵測到無聲為止。 如需較長音訊的連續辨識相關資訊 (包括多語系交談),請參閱如何辨識語音。若要從音訊檔案辨識語音,請使用
filename,而不是use_default_microphone:audio_config = speechsdk.audio.AudioConfig(filename="YourAudioFile.wav")針對 MP4 之類的壓縮音訊檔案,請安裝 GStreamer 並使用
PullAudioInputStream或PushAudioInputStream。 如需詳細資訊,請參閱如何使用壓縮的輸入音訊。
清除資源
您可以使用 Azure 入口網站或 Azure 命令列介面 (CLI) 來移除您所建立的語音資源。
參考文件 | 套件 (下載) | GitHub 上的其他範例
在此快速入門中,您會建立並執行應用程式,以即時辨識和轉譯語音轉換文字。
若要改為以非同步方式轉譯音訊檔案,請參閱什麼是批次轉譯。 如果您不確定哪個語音轉換文字解決方案適合您,請參閱什麼是語音轉換文字?
必要條件
- Azure 訂用帳戶。 您可以免費建立一個訂用帳戶。
- 在 Azure 入口網站上建立語音資源。
- 取得語音資源金鑰和區域。 部署語音資源之後,選取 [移至資源] 以檢視和管理索引鍵。
設定環境
適用於 Swift 的語音 SDK 會以架構套件組合的形式散發。 此架構同時支援 iOS 和 macOS 上的 Objective-C 和 Swift。
語音 SDK 可用於 Xcode 專案中做為 CocoaPod,或直接下載並手動連結。 本指南使用 CocoaPod。 依照安裝指示中的說明安裝 CocoaPod 相依性管理員。
設定環境變數
您必須驗證應用程式以存取 Azure AI 服務。 本文說明如何使用環境變數來儲存您的認證。 然後,您可以從程式碼存取環境變數,以驗證您的應用程式。 針對實際執行環境,使用更安全的方法來儲存和存取您的認證。
重要
我們建議使用適用於 Azure 資源的受控識別搭配 Microsoft Entra ID 驗證,以避免使用在雲端執行的應用程式儲存認證。
如果您使用 API 金鑰,請將其安全地儲存在別處,例如 Azure Key Vault。 請勿在程式碼中直接包含 API 金鑰,且切勿公開張貼金鑰。
如需 AI 服務安全性的詳細資訊,請參閱驗證對 Azure AI 服務的要求。
若要設定語音資源索引鍵和區域的環境變數,請開啟主控台視窗,並遵循作業系統和開發環境的指示進行。
- 若要設定
SPEECH_KEY環境變數,請以您其中一個資源金鑰取代 your-key。 - 若要設定
SPEECH_REGION環境變數,請以您的其中一個資源區域取代 your-region。
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
注意
如果您只需要存取目前主控台的環境變數,您可以使用 set (而不是 setx) 來設定環境變數。
新增環境變數之後,您可能需要重新啟動任何需要讀取環境變數的程式,包括主控台視窗。 例如,如果正在使用 Visual Studio 作為編輯器,請您在執行範例前重新啟動 Visual Studio。
從麥克風辨識語音
遵循下列步驟在 macOS 應用程式中辨識語音。
複製 Azure-Samples/cognitive-services-speech-sdk 存放庫,以取得在 macOS 上的 Swift 中從麥克風辨識語音範例專案。 存放庫也有 iOS 範例。
瀏覽至在終端中所下載範例應用程式 (
helloworld) 的目錄。執行
pod install命令。 此命令會產生一個helloworld.xcworkspaceXcode 工作區,其中包含範例應用程式和作為相依性的語音 SDK。在 XCode 中開啟
helloworld.xcworkspace工作區。開啟名為 AppDelegate.swift 的檔案,並找出
applicationDidFinishLaunching和recognizeFromMic方法,如下所示。import Cocoa @NSApplicationMain class AppDelegate: NSObject, NSApplicationDelegate { var label: NSTextField! var fromMicButton: NSButton! var sub: String! var region: String! @IBOutlet weak var window: NSWindow! func applicationDidFinishLaunching(_ aNotification: Notification) { print("loading") // load subscription information sub = ProcessInfo.processInfo.environment["SPEECH_KEY"] region = ProcessInfo.processInfo.environment["SPEECH_REGION"] label = NSTextField(frame: NSRect(x: 100, y: 50, width: 200, height: 200)) label.textColor = NSColor.black label.lineBreakMode = .byWordWrapping label.stringValue = "Recognition Result" label.isEditable = false self.window.contentView?.addSubview(label) fromMicButton = NSButton(frame: NSRect(x: 100, y: 300, width: 200, height: 30)) fromMicButton.title = "Recognize" fromMicButton.target = self fromMicButton.action = #selector(fromMicButtonClicked) self.window.contentView?.addSubview(fromMicButton) } @objc func fromMicButtonClicked() { DispatchQueue.global(qos: .userInitiated).async { self.recognizeFromMic() } } func recognizeFromMic() { var speechConfig: SPXSpeechConfiguration? do { try speechConfig = SPXSpeechConfiguration(subscription: sub, region: region) } catch { print("error \(error) happened") speechConfig = nil } speechConfig?.speechRecognitionLanguage = "en-US" let audioConfig = SPXAudioConfiguration() let reco = try! SPXSpeechRecognizer(speechConfiguration: speechConfig!, audioConfiguration: audioConfig) reco.addRecognizingEventHandler() {reco, evt in print("intermediate recognition result: \(evt.result.text ?? "(no result)")") self.updateLabel(text: evt.result.text, color: .gray) } updateLabel(text: "Listening ...", color: .gray) print("Listening...") let result = try! reco.recognizeOnce() print("recognition result: \(result.text ?? "(no result)"), reason: \(result.reason.rawValue)") updateLabel(text: result.text, color: .black) if result.reason != SPXResultReason.recognizedSpeech { let cancellationDetails = try! SPXCancellationDetails(fromCanceledRecognitionResult: result) print("cancelled: \(result.reason), \(cancellationDetails.errorDetails)") print("Did you set the speech resource key and region values?") updateLabel(text: "Error: \(cancellationDetails.errorDetails)", color: .red) } } func updateLabel(text: String?, color: NSColor) { DispatchQueue.main.async { self.label.stringValue = text! self.label.textColor = color } } }在 AppDelegate.m 中,使用您先前所設定的環境變數 (針對語音資源金鑰和區域)。
sub = ProcessInfo.processInfo.environment["SPEECH_KEY"] region = ProcessInfo.processInfo.environment["SPEECH_REGION"]若要變更語音辨識語言,請以另一種支援的語言取代
en-US。 例如,es-ES為西班牙文 (西班牙)。 如果您未指定任何語言,則預設值為en-US。 如需詳細了解如何識別所可能說出的多種語言之一,請參閱語言識別。若要顯示偵錯輸出 選取 [檢視]>[偵錯區域]> [啟動主控台]。
建置並執行範例程式碼,方法是從功能表中選取 [產品] > [執行] ,或選取 [播放] 按鈕。
重要
確保您已設定
SPEECH_KEY和SPEECH_REGION環境變數。 如果您未設定這些變數,則範例會失敗,並顯示錯誤訊息。
選取應用程式中的按鈕,並說出幾個字後,應該會在螢幕的下半部看到說出的文字。 當您第一次執行應用程式時,系統會提示您為應用程式授與電腦麥克風的存取權。
備註
此範例使用 recognizeOnce 作業來轉換最長 30 秒的語句,或直到偵測到無聲為止。 如需較長音訊的連續辨識相關資訊 (包括多語系交談),請參閱如何辨識語音。
Objective-C
適用於 Objective-C 的語音 SDK 會與適用於 Swift 的語音 SDK 共用用戶端程式庫和參考文件。 如需 Objective-C 程式碼範例,請參閱 GitHub 中 於 macOS 上使用 Objective-C 內的麥克風辨識語音範例專案。
清除資源
您可以使用 Azure 入口網站或 Azure 命令列介面 (CLI) 來移除您所建立的語音資源。
語音轉換文字 REST API 參考 | 適用於簡短音訊的語音轉換文字 REST API 參考 | GitHub 上的其他範例
在此快速入門中,您會建立並執行應用程式,以即時辨識和轉譯語音轉換文字。
若要改為以非同步方式轉譯音訊檔案,請參閱什麼是批次轉譯。 如果您不確定哪個語音轉換文字解決方案適合您,請參閱什麼是語音轉換文字?
必要條件
- Azure 訂用帳戶。 您可以免費建立一個訂用帳戶。
- 在 Azure 入口網站上建立語音資源。
- 取得語音資源金鑰和區域。 部署語音資源之後,選取 [移至資源] 以檢視和管理索引鍵。
您也需要本機電腦上的 .wav 音訊檔案。 您可以使用自己最多 60 秒的 .wav 檔案或下載 https://crbn.us/whatstheweatherlike.wav 範例檔案。
設定環境變數
您必須驗證應用程式以存取 Azure AI 服務。 本文說明如何使用環境變數來儲存您的認證。 然後,您可以從程式碼存取環境變數,以驗證您的應用程式。 針對實際執行環境,使用更安全的方法來儲存和存取您的認證。
重要
我們建議使用適用於 Azure 資源的受控識別搭配 Microsoft Entra ID 驗證,以避免使用在雲端執行的應用程式儲存認證。
如果您使用 API 金鑰,請將其安全地儲存在別處,例如 Azure Key Vault。 請勿在程式碼中直接包含 API 金鑰,且切勿公開張貼金鑰。
如需 AI 服務安全性的詳細資訊,請參閱驗證對 Azure AI 服務的要求。
若要設定語音資源索引鍵和區域的環境變數,請開啟主控台視窗,並遵循作業系統和開發環境的指示進行。
- 若要設定
SPEECH_KEY環境變數,請以您其中一個資源金鑰取代 your-key。 - 若要設定
SPEECH_REGION環境變數,請以您的其中一個資源區域取代 your-region。
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
注意
如果您只需要存取目前主控台的環境變數,您可以使用 set (而不是 setx) 來設定環境變數。
新增環境變數之後,您可能需要重新啟動任何需要讀取環境變數的程式,包括主控台視窗。 例如,如果正在使用 Visual Studio 作為編輯器,請您在執行範例前重新啟動 Visual Studio。
從檔案辨識語音
開啟主控台視窗,然後執行下列 cURL 命令: 將 YourAudioFile.wav 取代為音訊檔案的路徑和名稱。
curl --location --request POST "https://%SPEECH_REGION%.stt.speech.microsoft.com/speech/recognition/conversation/cognitiveservices/v1?language=en-US&format=detailed" ^
--header "Ocp-Apim-Subscription-Key: %SPEECH_KEY%" ^
--header "Content-Type: audio/wav" ^
--data-binary "@YourAudioFile.wav"
重要
確保您已設定 SPEECH_KEY 和 SPEECH_REGION環境變數。 如果您未設定這些變數,則範例會失敗,並顯示錯誤訊息。
您應該會收到類似此處所示的回應。
DisplayText 應該是從音訊檔案辨識出的文字。 此命令可辨識最多 60 秒的音訊,並將該音訊轉換成文字。
{
"RecognitionStatus": "Success",
"DisplayText": "My voice is my passport, verify me.",
"Offset": 6600000,
"Duration": 32100000
}
如需詳細資訊,請參閱簡短音訊的語音轉換文字 REST API。
清除資源
您可以使用 Azure 入口網站或 Azure 命令列介面 (CLI) 來移除您所建立的語音資源。
在此快速入門中,您會建立並執行應用程式,以即時辨識和轉譯語音轉換文字。
若要改為以非同步方式轉譯音訊檔案,請參閱什麼是批次轉譯。 如果您不確定哪個語音轉換文字解決方案適合您,請參閱什麼是語音轉換文字?
必要條件
- Azure 訂用帳戶。 您可以免費建立一個訂用帳戶。
- 在 Azure 入口網站上建立語音資源。
- 取得語音資源金鑰和區域。 部署語音資源之後,選取 [移至資源] 以檢視和管理索引鍵。
設定環境
請遵循下列步驟,並參閱語音 CLI 快速入門,以了解平台的其他需求。
執行下列 .NET CLI 命令以安裝 Speech CLI:
dotnet tool install --global Microsoft.CognitiveServices.Speech.CLI執行下列命令來設定您的語音資源金鑰和區域。 以您的語音資源金鑰取代
SUBSCRIPTION-KEY,而以您的語音資源區域取代REGION。spx config @key --set SUBSCRIPTION-KEY spx config @region --set REGION
從麥克風辨識語音
執行下列命令即可從麥克風啟動語音辨識:
spx recognize --microphone --source en-US用麥克風說話,您會看到單字即時轉譯成文字。 語音 CLI 會在一段無回應時間 (30 秒) 之後,或當您按下 Ctrl+ C 時停止。
Connection CONNECTED... RECOGNIZED: I'm excited to try speech to text.
備註
一些其他考量:
若要從音訊檔案辨識語音,請使用
--file,而不是--microphone。 針對 MP4 之類的壓縮音訊檔案,請安裝 GStreamer 並使用--format。 如需詳細資訊,請參閱如何使用壓縮的輸入音訊。spx recognize --file YourAudioFile.wav spx recognize --file YourAudioFile.mp4 --format any若要改善特定單字或語句的辨識正確性,請使用片語清單。 您可以在
recognize命令中包含內置的片語清單或片語清單文字檔:spx recognize --microphone --phrases "Contoso;Jessie;Rehaan;" spx recognize --microphone --phrases @phrases.txt若要變更語音辨識語言,請以另一種支援的語言取代
en-US。 例如,es-ES為西班牙文 (西班牙)。 如果您未指定任何語言,則預設值為en-US。spx recognize --microphone --source es-ES若要連續辨識超過 30 秒的音訊,請附加
--continuous:spx recognize --microphone --source es-ES --continuous執行此命令以取得更多語音辨識選項的相關資訊,例如檔案輸入和輸出:
spx help recognize
清除資源
您可以使用 Azure 入口網站或 Azure 命令列介面 (CLI) 來移除您所建立的語音資源。