Azure 服務匯流排
Azure 佇列儲存體
Azure 事件中樞
許多服務會 使用節流模式 來控制其取用的資源,並限制其他應用程式或服務可以存取它們的速率。 您可以使用速率限制模式來協助您避免或最小化與這些節流限制相關的節流錯誤,並協助您更準確地預測輸送量。
在許多案例中,速率限制模式很適合,但對於大規模重複的自動化工作,例如批處理特別有説明。
內容和問題
使用節流服務執行大量作業可能會導致流量和輸送量增加,因為您必須追蹤已拒絕的要求,然後重試這些作業。 隨著操作次數增加,節流限制可能需要多次重送資料,導致效能影響更大。
例如,請考慮下列天真重試錯誤程式,以將數據內嵌至 Azure Cosmos DB:
- 您的應用程式必須將 10,000 筆記錄內嵌至 Azure Cosmos DB。 每個記錄都會花費 10 個要求單位(RU)來內嵌,總共需要 100,000 RU 才能完成作業。
- 您的 Azure Cosmos DB 實例有 20,000 個 RU 布建的容量。
- 您會將所有 10,000 筆記錄傳送至 Azure Cosmos DB。成功寫入 2,000 筆記錄,並拒絕 8,000 筆記錄。
- 您將剩餘的 8,000 筆記錄傳送至 Azure Cosmos DB。成功寫入 2,000 筆記錄,並拒絕 6,000 筆記錄。
- 您將剩餘的 6,000 筆記錄傳送至 Azure Cosmos DB。成功寫入 2,000 筆記錄,並拒絕 4,000 筆記錄。
- 您將剩餘的 4,000 筆記錄傳送至 Azure Cosmos DB。成功寫入 2,000 筆記錄,並拒絕 2,000 筆記錄。
- 您會將其餘 2,000 筆記錄傳送至 Azure Cosmos DB。 全部都已成功寫入。
擷取作業已順利完成,但只有在將 30,000 筆記錄傳送至 Azure Cosmos DB 之後,即使整個數據集只包含 10,000 筆記錄。
上述範例中有需要考慮的其他因素:
- 大量錯誤也會導致額外的工作記錄這些錯誤,並處理產生的記錄數據。 這種天真的方法會處理 20,000 個錯誤,而記錄這些錯誤可能會造成處理、記憶體或儲存資源的負擔。
- 不知道擷取服務的節流限制,天真的方法無法設定數據處理需要多久的預期。 速率限制可讓您計算擷取所需的時間。
Solution
速率限制可減少流量,並可能藉由減少在指定時間內傳送至服務的記錄數目來改善輸送量。
服務可以根據不同指標隨時間進行限速,例如:
- 作業數目(例如每秒 20 個要求)。
- 數據量(例如每分鐘 2 GiB)。
- 作業的相對成本(例如每秒 20,000 RU)。
不論用於節流的計量為何,您的速率限制實作都會牽涉到控制在特定時間週期內傳送至服務的作業數目和/或大小,將服務的使用優化,同時未超過其節流容量。
在 API 處理請求速度超過限速匯入服務允許的情況下,你必須管理使用該服務的速度。 僅將限速視為資料速率不匹配,並在服務恢復前緩衝擷取請求,會造成風險。 如果應用程式在此情況下當機,任何緩衝資料可能會遺失。
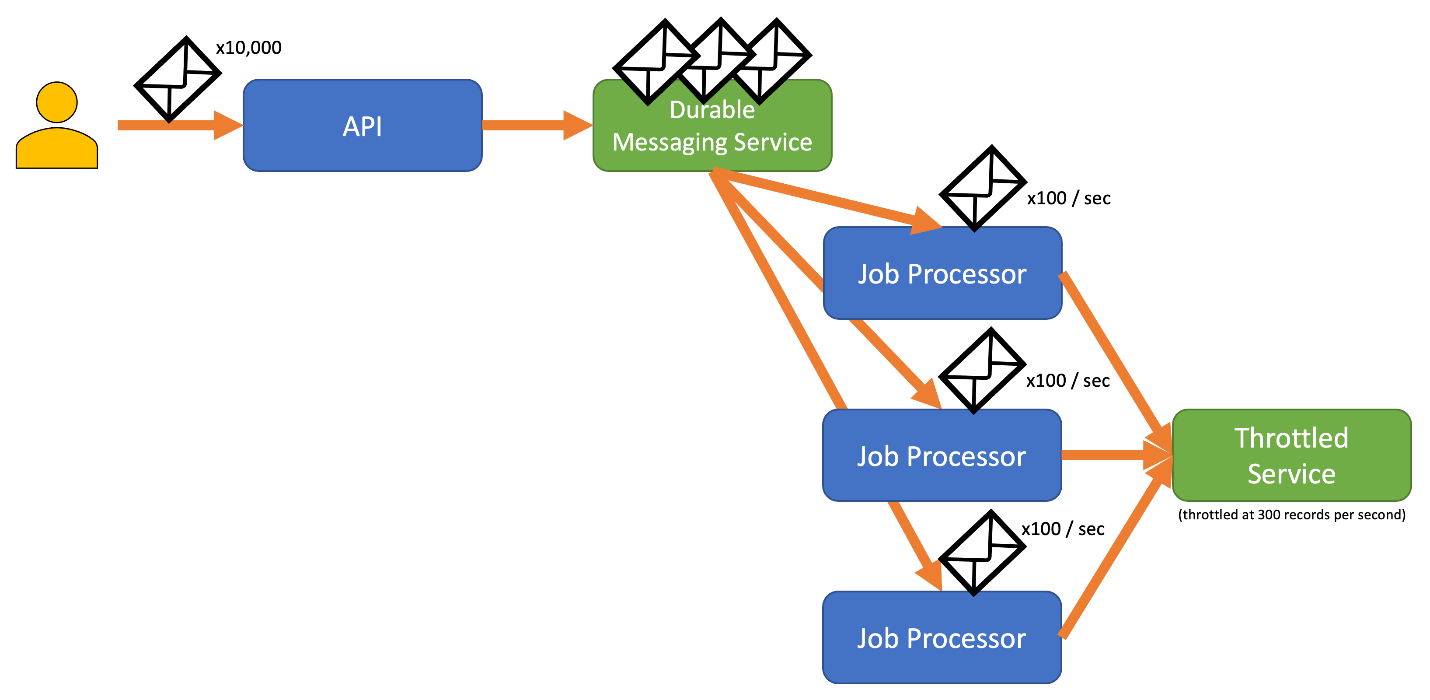
若要避免此風險,請考慮將記錄傳送至可處理完整擷取率的持久傳訊系統。 (Azure 事件中樞 等服務每秒可以處理數百萬個作業。 然後,您可以使用一或多個作業處理器,以受節流服務限制內的受控制速率從傳訊系統讀取記錄。 將記錄提交至傳訊系統可以儲存內部記憶體,方法是讓您只清除在指定時間間隔內可處理的記錄。
Azure 提供數個可搭配此模式使用的持久傳訊服務,包括:
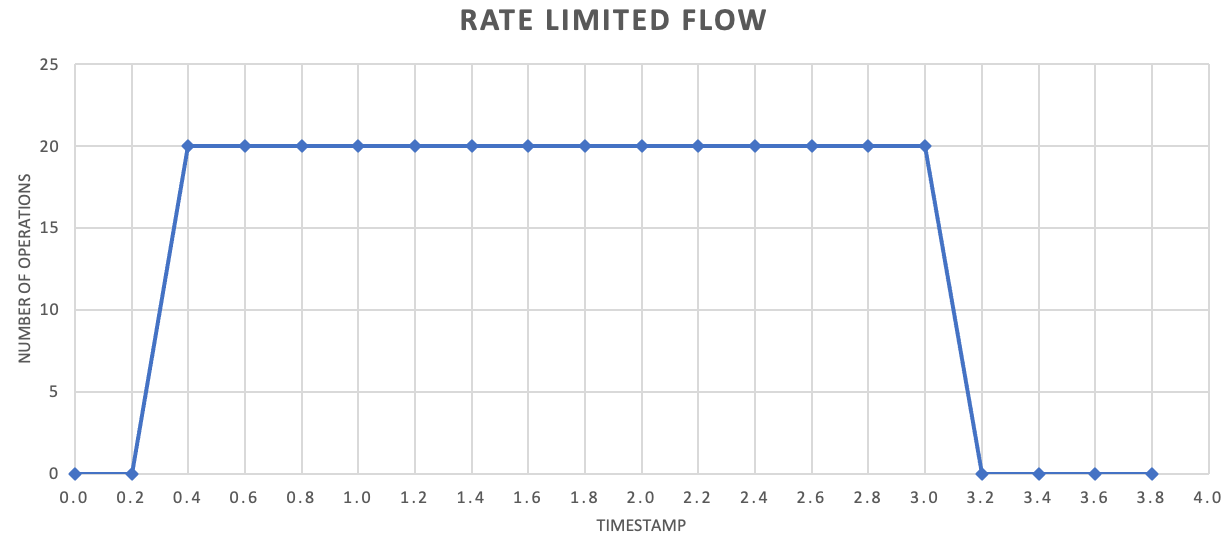
當你傳送紀錄時,你用來釋出紀錄的時間可能比服務限速的時間更細緻。 系統通常會根據您可以輕鬆地理解和使用的時間範圍來設定節流。 然而,對於執行服務的電腦來說,這些時間範圍可能遠遠超過它處理資訊的速度。 例如,系統可能會每秒或每分鐘節流,但通常程式代碼會以 nanoseconds 或毫秒的順序進行處理。
雖然不需要,但通常建議更頻繁地傳送少量的記錄,以改善輸送量。 所以,與其試圖每秒或每分鐘一次批量發佈,不如更細緻地處理,讓資源消耗(記憶體、CPU 和網路)以更均勻的速度流動,避免因突發請求爆發而造成瓶頸。 例如,若服務允許每秒 100 次操作,則實作速率限制器可能會透過每 200 毫秒釋放 20 次操作來平衡請求,如下圖所示。
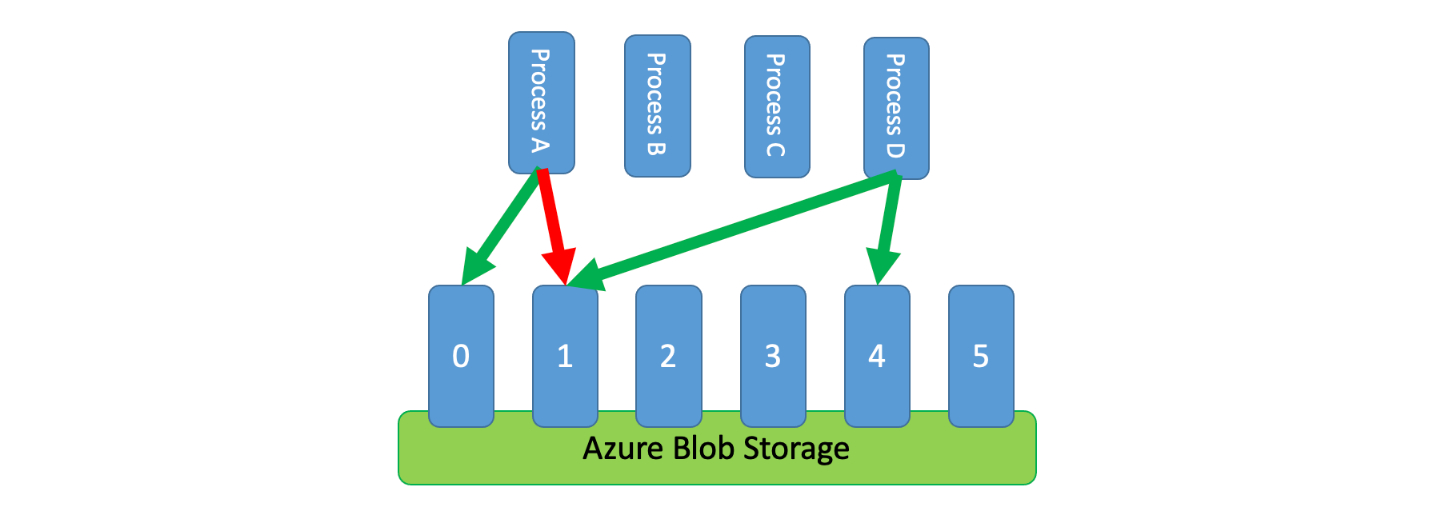
此外,有時需要多個未協調的進程來共用節流服務。 若要在此案例中實作速率限制,您可以以邏輯方式分割服務的容量,然後使用分散式互斥系統來管理這些分割區的獨佔鎖定。 然後,未協調的進程可以在需要容量時爭奪這些分割區的鎖定。 針對進程保留鎖定的每個分割區,它會被授與一定數量的容量。
例如,如果節流系統允許每秒 500 個要求,您可能會建立每秒 20 個值 25 個要求的數據分割。 如果需要發出 100 個要求的程式,可能會要求分散式互斥系統提供四個分割區。 系統可能會授與兩個分割區 10 秒。 接著,此程式會將速率限制為每秒 50 個要求、在兩秒內完成工作,然後釋放鎖定。
實作此模式的其中一種方法是使用 Azure 儲存體。 在此案例中,您會在容器中為每個邏輯分割區建立一個0位元組的 Blob。 然後,您的應用程式可以直接針對這些 Blob 取得 一段短時間內的獨佔租用 (例如 15 秒)。 針對應用程式授與的每個租用,應用程式就能夠使用該數據分割的容量。 然後,應用程式需要追蹤租用時間,如此一來,當租用到期時,就可以停止使用已授與的容量。 實作此模式時,您通常會希望每個進程在需要容量時嘗試租用隨機分割區。
若要進一步降低延遲,您可以為每個進程配置少量的獨佔容量。 然後,如果需要超過其保留容量,程式只會尋求取得共用容量的租用。
除了 Azure 儲存體 以外,您也可以使用 Zookeeper、Consul 等技術、Redis/Redsync 等技術來實作這類租用管理系統。
問題和考量
決定如何實作此模式時,請考慮下列事項:
- 雖然速率限制模式可以減少限速錯誤的數量,但你的應用程式仍需妥善處理可能發生的限速錯誤。
- 如果您的應用程式有多個工作流程可存取相同的節流服務,您必須將所有數據流整合到速率限制策略中。 例如,您可能支援將記錄大量載入資料庫中,但也會查詢相同資料庫中的記錄。 您可以藉由確保所有工作流程都透過相同的速率限制機制來管理容量。 或者,您可以為每個工作流程保留個別的容量集區。
- 限速服務可用於多種應用。 在某些情況下,但並非全部的情況,可以協調該使用方式(如上所示)。 如果您開始看到比預期更多的限流錯誤,這可能是應用程式在存取服務時出現競爭的徵兆。 如果是這樣,你可能需要考慮暫時降低速率限制機制所施加的吞吐量,直到其他應用程式的使用量下降。
使用此模式的時機
使用此模式來:
- 減少節流限制服務所引發的節流錯誤。
- 相較於錯誤方法的天真重試,減少流量。
- 只有在有容量可處理記錄時,才能減少記憶體耗用量。
工作負載設計
架構設計人員應該評估如何在工作負載的設計中使用速率限制模式,以解決 Azure 良好架構架構支柱中涵蓋的目標和原則。 例如:
| Pillar | 此模式如何支援支柱目標 |
|---|---|
| 可靠性設計決策可協助工作負載復原到故障,並確保它會在發生失敗后復原到完全正常運作的狀態。 | 當服務想要避免過度使用時,此策略可藉由認可並接受與服務通訊的限制和成本,以保護用戶端。 - RE:07 自我保護 |
如同任何設計決策,請考慮對其他可能以此模式導入之目標的任何取捨。
Example
下列範例應用程式可讓使用者將不同類型的記錄提交至 API。 執行下列步驟的每個記錄類型都有唯一的作業處理器:
- Validation
- Enrichment
- 將記錄插入資料庫
應用程式的所有元件(API、工作處理器 A 與工作處理器 B)都是獨立的程序,可以獨立擴展。 進程不會彼此直接通訊。
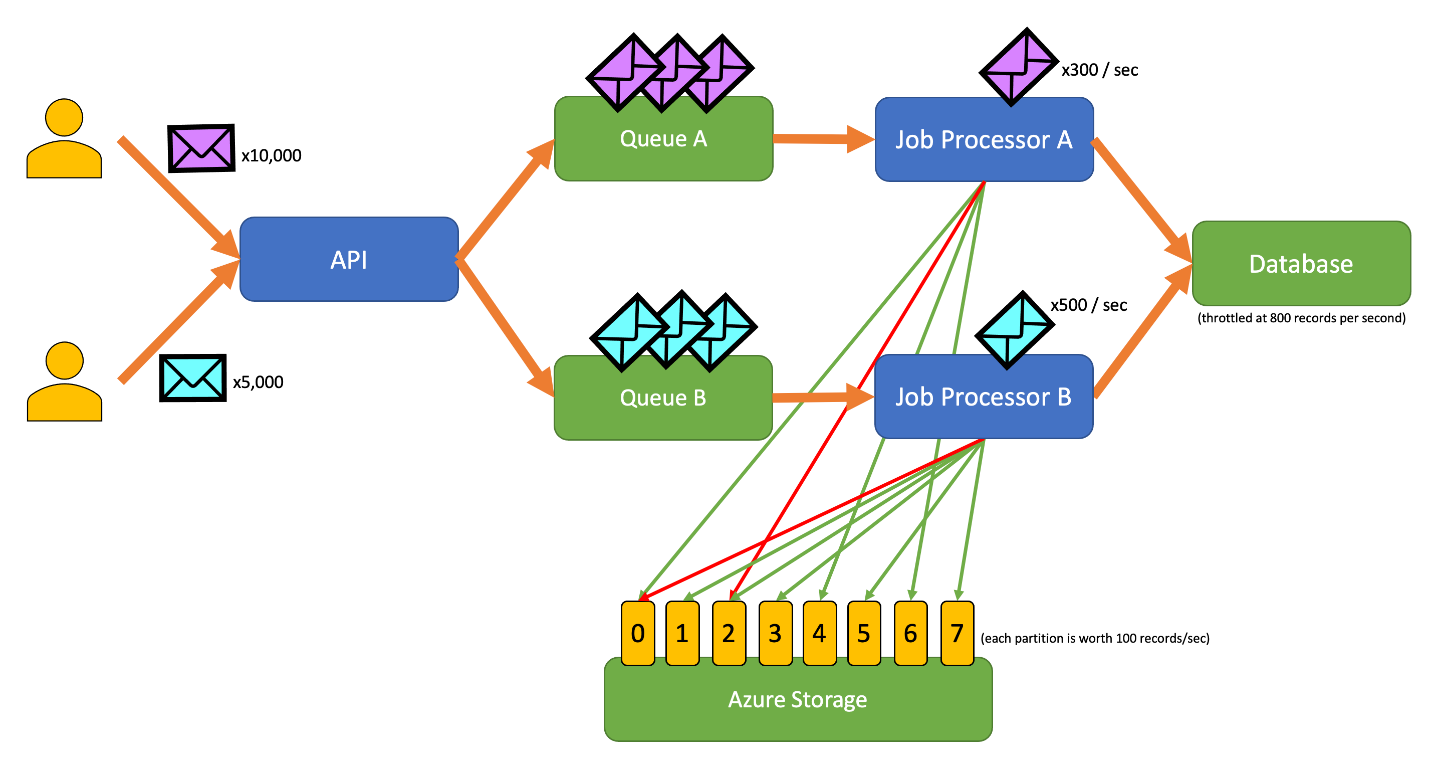
此圖表包含下列工作流程:
- 使用者會將 A 類型的 10,000 筆記錄提交至 API。
- API 會將佇列 A 中的 10,000 筆記錄加入佇列。
- 使用者會將類型 B 的 5,000 筆記錄提交至 API。
- API 會將這 5,000 筆記錄加入佇列 B 中。
- 作業處理器 A 看到佇列 A 有記錄,並嘗試在 Blob 2 上取得獨佔租用。
- 作業處理器 B 看到佇列 B 有記錄,並嘗試在 Blob 2 上取得獨佔租用。
- 作業處理器 A 無法取得租用。
- 作業處理器 B 會在 Blob 2 上取得租用 15 秒。 它現在可以以每秒 100 的速率對資料庫的要求進行速率限制。
- 作業處理器 B 會從佇列 B 清除 100 筆記錄,並加以寫入。
- 一秒通過。
- 作業處理器 A 看到佇列 A 有更多記錄,並嘗試在 Blob 6 上取得獨佔租用。
- 作業處理器 B 看到佇列 B 有更多記錄,並嘗試在 Blob 3 上取得獨佔租用。
- 作業處理器 A 會取得 Blob 6 的租用 15 秒。 它現在可以以每秒 100 的速率對資料庫的要求進行速率限制。
- 作業處理器 B 會在 Blob 3 上取得租用 15 秒。 它現在可以以每秒 200 的速率對資料庫的要求進行速率限制。 (它也保留 Blob 2 的租用。
- 作業處理器 A 會從佇列 A 清除 100 筆記錄,並加以寫入。
- 作業處理器 B 會從佇列 B 清除 200 筆記錄,並加以寫入。
- 一秒通過。
- 作業處理器 A 看到佇列 A 有更多記錄,並嘗試在 Blob 0 上取得獨佔租用。
- 作業處理器 B 看到佇列 B 有更多記錄,並嘗試在 Blob 1 上取得獨佔租用。
- 作業處理器 A 會取得 Blob 0 的租用 15 秒。 它現在可以以每秒 200 的速率對資料庫的要求進行速率限制。 (它也保留 Blob 6 的租用。
- 作業處理器 B 取得 Blob 1 的租用 15 秒。 它現在可以以每秒 300 的速度對資料庫的要求進行速率限制。 (它也保留 Blob 2 和 3 的租用。
- 作業處理器 A 會從佇列 A 清除 200 筆記錄,並加以寫入。
- 作業處理器 B 會從佇列 B 清除 300 筆記錄,並加以寫入。
- 等等...
15 秒之後,仍然不會完成一或兩個作業。 當租用到期時,處理器也應該減少其排入佇列和寫入的要求數目。
 此模式的實作以不同的程式設計語言提供:
此模式的實作以不同的程式設計語言提供:
相關資源
實作此模式時,下列模式和指引也可能相關:
- Throttling. 此處討論的速率限制模式通常會實作,以回應節流的服務。
- Retry. 當對節流服務的要求導致節流錯誤時,通常適合在適當的間隔后重試這些錯誤。
佇列型負載撫平 類似,但與速率限制模式有幾種主要方式不同:
- 速率限制不一定需要使用佇列來管理負載,但它確實需要使用永久性傳訊服務。 例如,速率限制模式可以使用Apache Kafka或 Azure 事件中樞等服務。
- 速率限制模式引進分割區上分散式互斥系統的概念,可讓您管理與相同節流服務通訊之多個未協調進程的容量。
- 每當服務之間有效能不符或改善復原能力時,佇列型負載撫平模式就適用。 這讓其比速率限制更廣,更具體來說,就是有效率地存取節流服務。