解決方案構想
本文說明解決方案概念。 您的雲端架構設計人員可以使用本指南,協助可視化此架構的一般實作的主要元件。 使用本文作為起點,設計符合您工作負載特定需求的架構良好解決方案。
在 Azure 中實作自定義自然語言處理 (NLP) 解決方案。 針對主題和情感偵測和分析等工作使用Spark NLP。
Apache、Apache® Spark 和火焰標誌是 美國 和/或其他國家/地區的 Apache Software Foundation 註冊商標或商標。 使用這些標記不會隱含 Apache Software Foundation 的背書。
架構

工作流程
- Azure 事件中樞、Azure Data Factory 或兩個服務都會接收檔或非結構化文字數據。
- 事件中樞和 Data Factory 會將數據以檔格式儲存在 Azure Data Lake Storage 中。 建議您設定符合商務需求的目錄結構。
- Azure 電腦視覺 API 會使用其光學字元辨識 (OCR) 功能來取用數據。 接著,API 會將數據寫入銅層。 此取用平臺會使用 Lakehouse 架構。
- 在銅層中,各種Spark NLP功能會前置處理文字。 範例包括分割、更正拼字、清除和瞭解文法。 建議您在銅層執行檔分類,然後將結果寫入銀層。
- 在銀層中,進階Spark NLP功能會執行檔分析工作,例如具名實體辨識、摘要和資訊擷取。 在某些架構中,結果會寫入金層。
- 在金層中,Spark NLP 會在文字數據上執行各種語言視覺分析。 這些分析提供語言相依性的深入解析,並協助呈現 NER 標籤的視覺效果。
- 使用者會將金層文字數據查詢為數據框架,並在 Power BI 或 Web 應用程式中檢視結果。
在處理步驟期間,Azure Databricks、Azure Synapse Analytics 和 Azure HDInsight 會與 Spark NLP 搭配使用,以提供 NLP 功能。
元件
- Data Lake Storage 是 Hadoop 相容的文件系統,具有整合式階層命名空間,以及 Azure Blob 儲存體 的大規模和經濟性。
- Azure Synapse Analytics 是適用於數據倉儲和巨量數據系統的分析服務。
- Azure Databricks 是巨量數據的分析服務,可方便共同作業,並以 Apache Spark 為基礎。 Azure Databricks 專為數據科學和數據工程而設計。
- 事件中 樞會擷取用戶端應用程式產生的數據流。 事件中樞會儲存串流數據,並保留接收的事件序列。 取用者可以連線到中樞端點,以擷取要處理的訊息。 事件中樞會與 Data Lake Storage 整合,如此解決方案所示。
- Azure HDInsight 是企業雲端中受控、全方位的開放原始碼分析服務。 您可以搭配 Azure HDInsight 使用開放原始碼架構,例如 Hadoop、Apache Spark、Apache Hive、LLAP、Apache Kafka、Apache Storm 和 R。
- Data Factory 會自動在不同安全性層級的記憶體帳戶之間移動數據,以確保職責分離。
- 電腦視覺 使用文字辨識 API 來辨識影像中的文字,並擷取該資訊。 讀取 API 會使用最新的辨識模型,並針對大型、重文字的檔和嘈雜的影像進行優化。 OCR API 並未針對大型文件進行優化,但支援比讀取 API 更多的語言。 此解決方案會使用 OCR 來產生 hOCR 格式的數據。
案例詳細資料
自然語言處理 (NLP) 有許多用途:情感分析、主題偵測、語言偵測、關鍵片語擷取和文件分類。
Apache Spark 是一種平行處理架構,可支援記憶體內部處理,以提升如 NLP 等巨量數據分析應用程式的效能。 Azure Synapse Analytics、 Azure HDInsight 和 Azure Databricks 提供 Spark 的存取權,並利用其處理能力。
針對自定義的 NLP 工作負載,開放原始碼連結庫 Spark NLP 可作為處理大量文字的有效架構。 本文提供 Azure 中大規模自定義 NLP 的解決方案。 解決方案會使用Spark NLP功能來處理和分析文字。 如需Spark NLP的詳細資訊,請參閱 本文稍後的Spark NLP功能和管線。
潛在使用案例
檔案分類: Spark NLP 提供數個選項進行文字分類:
- 以 Spark ML 為基礎的 Spark NLP 和機器學習演算法中的文字前置處理
- 文字前置處理和文字內嵌在Spark NLP和機器學習演算法中,例如 GloVe、BERT 和 ELMo
- 文字前置處理和句子內嵌在Spark NLP和機器學習演算法和模型,例如通用句子編碼器
- 使用 ClassifierDL 標注器的 Spark NLP 中的文字前置處理和分類,並以 TensorFlow 為基礎
名稱實體擷取 (NER): 在Spark NLP中,使用幾行程式代碼,您可以定型使用 BERT 的 NER 模型,而您可以達到最先進的精確度。 NER 是資訊擷取的子工作。 NER 會找出非結構化文字中的具名實體,並將其分類為預先定義的類別,例如人員名稱、組織、位置、醫療代碼、時間表達式、數量、貨幣值和百分比。 Spark NLP 使用最先進的 NER 模型搭配 BERT。 此模型受到前 NER 模型、雙向 LSTM-CNN 的啟發。 該前模型會使用新的類神經網路架構來自動偵測文字層級和字元層級特徵。 為此,模型會使用混合式雙向 LSTM 和 CNN 架構,因此不需要進行大部分的功能工程。
情感和表情偵測: Spark NLP 可以自動偵測語言的正面、負面和中性層面。
語音的一部分(POS): 此功能會將文法標籤派給輸入文字中的每個標記。
句子偵測 (SD): SD 是以一般用途神經網路模型為基礎,用於識別文字內句子的句子界限偵測。 許多 NLP 工作會採用句子作為輸入單位。 這些工作的範例包括 POS 標記、相依性剖析、具名實體辨識,以及機器翻譯。
Spark NLP 功能和管線
Spark NLP 提供 Python、Java 和 Scala 連結庫,可提供傳統 NLP 連結庫的完整功能,例如 spaCy、NLTK、Stanford CoreNLP 和 Open NLP。 Spark NLP 也提供拼字檢查、情感分析和文件分類等功能。 Spark NLP 藉由提供最先進的精確度、速度和延展性,來改善先前的工作。
Spark NLP 是迄今為止最快的開放原始碼 NLP 連結庫。 最近的公開基準檢驗顯示 Spark NLP 的速度比 spaCy 快 38 和 80 倍,其可比定型自定義模型的正確性。 Spark NLP 是唯一可以使用分散式 Spark 叢集的開放原始碼連結庫。 Spark NLP 是 Spark ML 的原生延伸模組,可直接在數據框架上運作。 因此,叢集上的加速會導致效能提升的另一個數量級。 因為每個 Spark NLP 管線都是 Spark ML 管線,因此 Spark NLP 非常適合用來建置統一的 NLP 和機器學習管線,例如檔分類、風險預測和推薦管線。
除了出色的效能,Spark NLP 也為越來越多的 NLP 工作提供最先進的精確度。 Spark NLP 小組會定期閱讀最新的相關學術論文,併產生最精確的模型。
針對 NLP 管線的執行順序,Spark NLP 遵循與傳統 Spark 機器學習模型相同的開發概念。 但 Spark NLP 會套用 NLP 技術。 下圖顯示 Spark NLP 管線的核心元件。
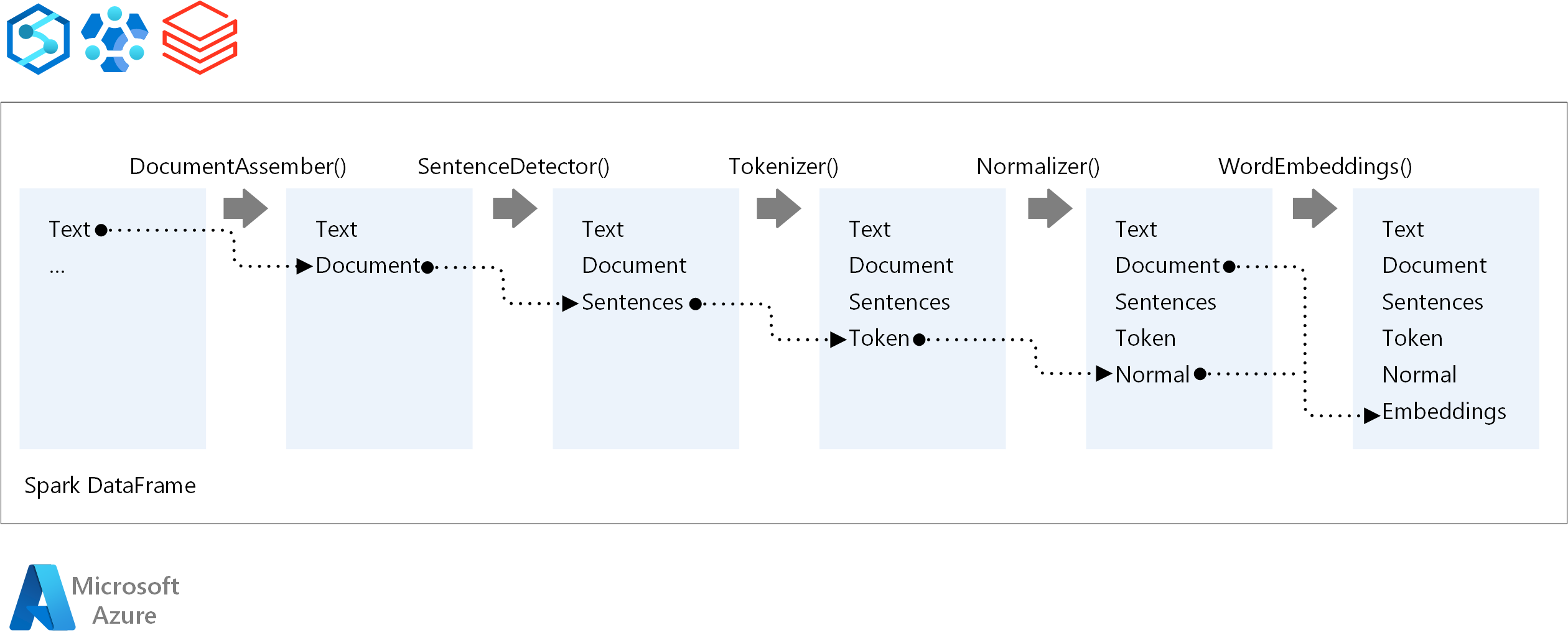
參與者
本文由 Microsoft 維護。 原始投稿人如下。
主體作者:
- 莫里茨·斯特勒 |資深雲端解決方案架構師
下一步
Spark NLP 檔:
Azure 元件: