Azure HDInsight 是雲端中供企業使用的受控、全方位的開放原始碼分析服務。 透過 HDInsight,便可以在您的 Azure 環境中使用開放原始碼架構,例如 Apache Spark、Apache Hive、LLAP、Apache Kafka、Hadoop 等。
什麼是 HDInsight 和 Hadoop 技術堆疊?
Azure HDInsight 是受控叢集平台,可讓您輕鬆地在 Azure 環境中執行巨量資料架構,例如 Apache Spark、Apache Hive、LLAP、Apache Kafka、Apache Hadoop 和其他架構。 其設計目的是要以高速和高效率處理大量資料。
為什麼應該使用 Azure HDInsight?
| 功能 | 描述 |
|---|---|
| 雲端原生 | Azure HDInsight 可讓您在 Azure 上建立適用於 Spark、互動式查詢 (LLAP)、Kafka、HBase 與 Hadoop 的最佳化叢集。 HDInsight 也提供所有生產工作負載的端對端 SLA。 |
| 低成本且可調整 | HDInsight 可讓您相應增加或減少工作負載。 您可以依照需求建立叢集,且只支付您所使用的部分來降低成本。 您也可以建置資料管線來施行您的作業。 分離計算與儲存體,讓效能與彈性變得更好。 |
| 安全且符合規範 | HDInsight 可讓您使用 Azure 虛擬網路、加密,以及與 Microsoft Entra ID 整合來保護企業資料資產。 HDInsight 也符合最受歡迎的產業和政府合規性標準。 |
| 監視 | Azure HDInsight 與 Azure 監視器記錄整合後會提供單一介面,以便監視所有的叢集。 |
| 整體可用性 | HDInsight 的適用區域超過任何其他巨量資料分析供應項目。 Azure HDInsight 也會適用於 Azure Government、中國和德國,可讓您符合您在重要主權區域中的企業需求。 |
| 生產力 | Azure HDInsight 可讓您在慣用的開發環境中,使用多種 Hadoop 與 Spark 的生產工具。 這些開發環境包括適用於 Scala、Python、JAVA 和 .NET 的 Visual Studio、VS Code、Eclipse 和 IntelliJ。 |
| 擴充性 | 您可以透過使用指令碼動作安裝的元件 (Hue、Presto 等)、新增邊緣節點,或與其他巨量資料認證的應用程式整合,來擴充 HDInsight 叢集。 透過單鍵部署,HDInsight 即可與最受歡迎的巨量資料解決方案緊密整合。 |
什麼是巨量資料?
比起以往,巨量資料的收集量快速增加,收集速度加快,收集格式也愈來愈多。 其可以是歷史 (意指已儲存) 或即時 (意指從來源串流) 的。 請參閱使用 HDInsight 的案例,了解巨量資料的最常見使用案例。
HDInsight 中的叢集類型
HDInsight 包含特定叢集類型和叢集自訂功能,例如新增元件、公用程式及語言的功能。 HDInsight 提供下列叢集類型:
| 叢集類型 | 描述 | 開始使用 |
|---|---|---|
| Apache Hadoop \(英文\) | 使用 HDFS、YARN 資源管理和簡單 MapReduce 程式設計模型的架構,用來平行處理和分析批次資料。 | 建立 Apache Hadoop 叢集 |
| Apache Spark | 開放原始碼的平行處理架構,可支援記憶體內部處理,以大幅提升巨量資料分析應用程式的效能。 請參閱什麼是 HDInsight 中的 Apache Spark?。 | 建立 Apache Spark 叢集 |
| Apache HBase | 建置於 Hadoop 上的 NoSQL 資料庫,可針對大量非結構化及半結構化資料 (可能是數十億個資料列乘以數百萬個資料行) 提供隨機存取功能和強大的一致性。 請參閱什麼是 HDInsight 上的 HBase? | 建立 Apache HBase 叢集 |
| Apache 互動式查詢 | 更快速進行互動式 Hive 查詢的記憶體內部快取。 請參閱在 HDInsight 中使用互動式查詢。 | 建立互動式查詢叢集 |
| Apache Kafka | 用來建立串流資料管線和應用程式的開放原始碼平台。 Kafka 也提供訊息佇列功能,可讓您發佈和訂閱資料流。 請參閱 HDInsight 上的 Apache Kafka 簡介。 | 建立 Apache Kafka 叢集 |
使用 HDInsight 的案例
Azure HDInsight 可在巨量資料處理的各種情節中使用。 其可以是歷程資料 (已收集及儲存的資料) 或即時資料 (從來源直接串流處理的資料)。 下列類別概述處理這類資料的案例:
批次處理 (ETL)
在擷取、轉換及載入 (ETL) 程序中,非結構化或結構化資料會擷取自異質資料來源。 然後轉換成結構化格式,並載入資料存放區。 您可以將已轉換的資料用於資料科學或資料倉儲上。
資料倉儲
您可以使用 HDInsight 對任何格式的結構化或非結構化資料執行 PB 規模的互動式查詢。 您也可以建置模型,將這些查詢連線至 BI 工具。
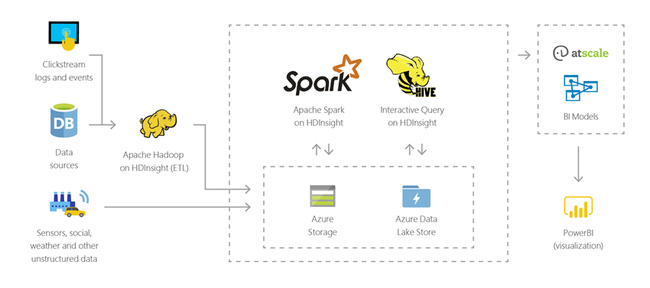
物聯網 (IoT)
您可以使用 HDInsight 來處理從不同裝置類型即時接收的串流資料。 如需詳細資訊,請閱讀 Azure 的此部落格文章,其中宣佈了在 HDInsight 上使用 Azure 受控磁碟的 Apache Kafka 公開預覽。
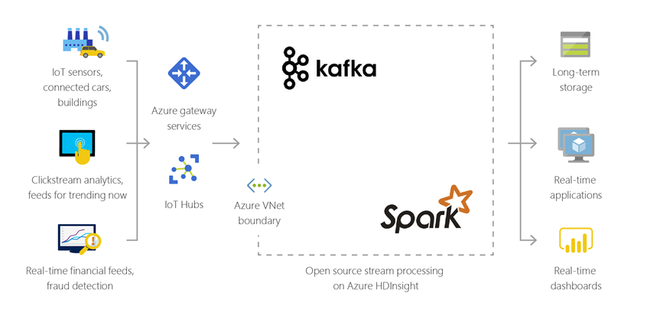
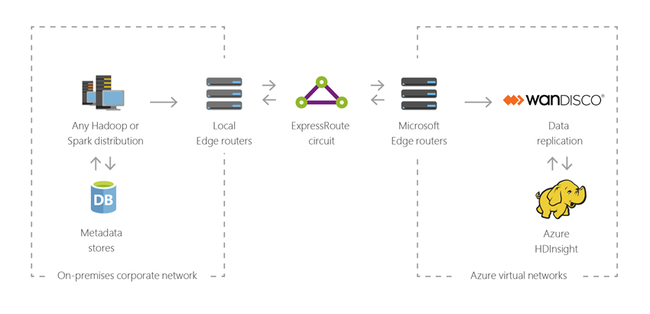
混合式
您可以使用 HDInsight 將現有的內部部署巨量資料基礎結構延伸至 Azure,套用至雲端的進階分析功能。
HDInsight 中的開放原始碼元件
Azure HDInsight 可讓您使用 Spark、Hive、LLAP、Kafka、Hadoop 及 HBase 等開放原始碼架構來建立叢集。 根據預設,這些叢集包含各種開放原始碼元件,例如 Apache Ambari、Avro、Apache Hive3、HCatalog、Apache Hadoop MapReduce、Apache Hadoop YARN、Apache Phoenix、Apache Pig、Apache Sqoop、Apache Tez、Apache Oozie 和 Apache ZooKeeper。
HDInsight 中的程式設計語言
HDInsight 叢集 (包括 Spark、HBase、Kafka、Hadoop 等) 支援許多種程式設計語言。 某些程式設計語言並未預設安裝。 針對未預設安裝的程式庫、模組或套件,請使用指令碼動作來安裝元件。
| 程式設計語言 | 資訊 |
|---|---|
| 預設的程式設計語言支援 | 根據預設,HDInsight 叢集可支援:
|
| Java 虛擬機器 (JVM) 語言 | Java 虛擬機器 (JVM) 上可以執行許多 Java 以外的語言。 不過如要執行這些語言,可能必須在叢集上安裝更多元件。 HDInsight 叢集上支援下列以 JVM 為基礎的語言:
|
| Hadoop 專屬語言 | HDInsight 叢集支援下列 Hadoop 技術堆疊專屬語言:
|
適用於 HDInsight 的開發工具
您可以使用 HDInsight 開發工具 (包括 IntelliJ、Eclipse、Visual Studio Code 和 Visual Studio),透過與 Azure 的完美整合,以撰寫並提交 HDInsight 資料查詢和作業。
- 適用於 IntelliJ 10 的 Azure 工具組
- 適用於 Eclipse 6 的 Azure 工具組
- 適用於 VS Code 13 的 Azure HDInsight 工具
- 適用於 Visual Studio 9 的 Azure Data Lake 工具
HDInsight 上的商業智慧
熟悉的商業智慧 (BI) 工具可使用 Power Query 增益集或 Microsoft Hive ODBC 驅動程式來擷取、分析和報告與 HDInsight 整合的資料:
在 Azure HDInsight 中使用 Microsoft Power BI 將 Apache Hive 資料視覺化
使用 Power Query 將 Excel 連線到 Apache Hadoop (需要 Windows)
使用 Microsoft Hive ODBC 驅動程式將 Excel 連線到 Apache Hadoop (需要 Windows)
區域內資料落地
Spark、Hadoop 和 LLAP 不會儲存客戶數據,因此這些服務會自動滿足 Azure 全域基礎結構網站中指定的區域數據落地需求。
Kafka 和 HBase 會儲存客戶資料。 此數據會自動由 Kafka 和 HBase 儲存在單一區域中,因此此服務符合 Azure 全域基礎結構網站中指定的區域內數據落地需求。
熟悉的商業智慧 (BI) 工具可使用 Power Query 增益集或 Microsoft Hive ODBC 驅動程式來擷取、分析和報告與 HDInsight 整合的資料。