Azure 溝通網路閘道的可靠性
Azure 通訊閘道會使用 Azure 備援機制和 SIP 特定的重試行為,確保您的服務可靠。 您的網路必須符合特定需求,以確保服務可用性。
Azure 通訊閘道的備援模型
生產 Azure 通訊閘道部署(也稱為標準部署)包含三個不同的區域:管理區域和兩個服務區域。 實驗室部署包含一個管理區域和一個服務區域。
本文說明兩個不同的區域類型及其不同的備援模型。 其涵蓋可用性區域的區域可靠性,以及災害復原的跨區域可靠性。 如需更多關於 Azure 可靠性的詳細概觀,請參閱 Azure 可靠性。
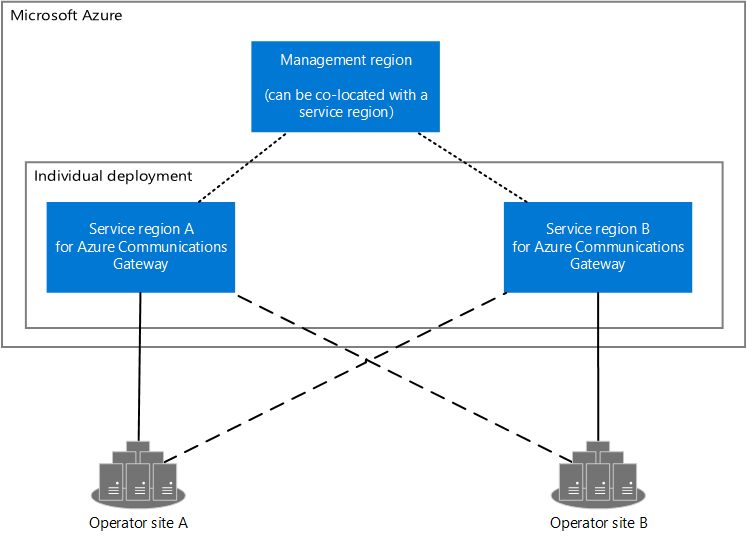
此圖顯示兩個操作員網站和 Azure 通訊閘道的 Azure 區域。 Azure 通訊閘道有兩個服務區域和一個管理區域。 服務區域會連線到管理區域和操作員月臺。 管理區域可以與服務區域共置。
服務區域
服務區域包含用來處理網路與所選通訊服務之間流量的語音和 API 基礎結構。
生產 Azure 通訊閘道部署有兩個服務區域,部署在主動-主動模式中(如 電信業者連線 和 Teams 電話 行動程式所需)。 服務區域之間的快速故障轉移是在基礎結構/IP 層級和應用程式 (SIP/RTP/HTTP) 層級提供。
服務區域也包含 Azure 通訊閘道佈建 API 的基礎結構。
提示
生產部署必須一律有兩個服務區域,即使選擇的其中一個服務區域位於單一區域的 Azure 地理位置(例如卡達)。 如果您選擇單一區域 Azure Geography,請選擇不同 Azure Geography 中的第二個 Azure 區域。
服務區域在作業中完全相同,並提供區域和區域失敗的復原能力。 每個服務區域都可以使用 Azure 通訊閘道實例來攜帶 100% 的流量。 因此,終端使用者仍應該能夠在任何區域或區域停機期間成功撥打和接聽電話。
實驗室部署有一個服務區域。
通話路由需求
Azure 通訊閘道提供「成功的重新串行化」備援模型:失敗對等所處理的呼叫會終止,但新的呼叫會路由傳送至狀況良好的對等。 此模型會鏡像 Microsoft Teams 所提供的備援模型。
針對生產環境部署,我們預期您的網路會有兩個異地備援月臺。 每個月臺都應該與 Azure 通訊閘道區域配對。 備援模型仰賴網路與 Azure 通訊閘道服務區域之間的跨連線。
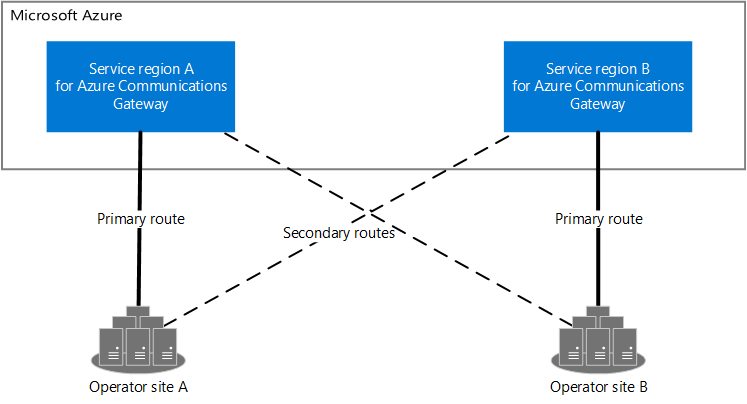
兩個操作員網站 (操作員網站 A 和操作員月臺 B) 和兩個服務區域 (服務區域 A 和服務區域 B) 的圖表。 操作員月臺 A 具有服務區域 A 的主要路由,以及服務區域 B 的次要路由。操作員月臺 B 有服務區域 B 的主要路由,以及服務區域 A 的次要路由。
實驗室部署必須連線到您網路中一個月臺。
每個 Azure 通訊閘道服務區域都會提供 SRV 記錄。 此記錄包含所有 SIP 對等,提供區域內 SBC 功能(用於將通話路由傳送至通訊服務)。 此 SRV 記錄可以指向上線小組提供給您 /28 IP 範圍中的任何 IP 位址。
如果您的 Azure 通訊閘道包含行動控制點 (MCP),則每個服務區域都會為 MCP 提供額外的 SRV 記錄。 每個區域 MCP 記錄都會在區域內包含最高優先順序的 MCP,另一個區域中的 MCP 優先順序較低。
您網路中的每個月臺都必須:
- 根據預設,將流量傳送至其本機 Azure 通訊閘道服務區域。
- 使用 DNS SRV 找出區域內的 Azure 通訊閘道對等互連,如 RFC 3263 中所述。
- 使用
_sip._tls.<regional-FQDN-from-portal>,對服務區域連線到您網路的域名進行 DNS SRV 查閱。 將 取代<regional-FQDN-from-portal>為 Azure 入口網站 中資源 [概觀] 頁面上 [主機名] 字段的 [每個區域 FQDN]。 例如,如果您的部署使用commsgw.azure.com功能變數名稱,請查閱_sip._tls.pstn-region1.<deployment-id>.commsgw.azure.com第一個區域。 - 如果 SRV 查閱傳回多個目標,請使用每個目標的權數和優先順序來選取單一目標。
- 使用
- 將新的呼叫傳送至可用的 Azure 通訊閘道對等。
- 能夠接收與 Azure 通訊閘道相關聯之每個 IP 範圍中任何 IP 位址的流量。
當您的網路將呼叫路由至 Azure 通訊閘道的 SIP 對等 SBC 函式時,它必須:
- 使用SIP OPTIONS(或OPTIONS和SIP流量的組合)來監視 Azure 通訊閘道 SIP 對等互連的可用性。
- 重試收到 408 個回應、503 個回應或 504 個回應或未收到回應的 INVITE,方法是將回應重新路由傳送至本機網站中的其他可用對等。 只有在本地服務區域中的所有對等節點都失敗時,才搜尋至其他服務區域(由其他區域的 SRV 記錄所定義)。
- 永不重試接收 408、503 和 504 以外的錯誤回應的呼叫。
如果您的 Azure 通訊閘道部署包含整合式行動控制點 (MCP),您的網路必須為 MCP 執行如下動作:
- 偵測區域中的 MCP 何時無法使用、將該區域 SRV 記錄的目標標示為無法使用,並定期重試以判斷區域何時可再次使用。 MCP 不會回應SIP OPTIONS。
- 根據您的組織原則處理 MCP 的 5xx 回應。 例如,您可以重試要求,或允許呼叫繼續,而不需通過 Azure 通訊閘道並傳入 Microsoft 電話 系統。
此路由行為的詳細數據專屬於您的網路。 您必須在整合項目期間同意您的上線小組。
管理區域
管理區域包含用於 Azure 通訊閘道的訂購、監視和計費基礎結構。 這些區域內的所有基礎結構都會以區域性備援的方式部署,這表示所有數據都會自動復寫到區域內的每個可用性區域。 所有重要的組態數據也會復寫到每個服務區域,以確保 Azure 區域失敗期間服務正常運作。
可用性區域支援
Azure 可用性區域是每個 Azure 區域內至少三個實體獨立的資料中心群組。 每個區域內的資料中心都配備了獨立的電源、冷卻和網路基礎結構。 可用性區域的作用是在一個區域受影響時 (例如本機區域失敗時),讓其餘兩個區域支援區域服務、容量和高可用性。
這類失敗的範圍可從軟體和硬體故障,擴及到如地震、淹水和火災的事件。 Azure 服務的備援和邏輯隔離功能可以容錯。 如需深入了解 Azure 的可用性區域,請參閱區域和可用性區域。
已啟用 Azure 可用性區域的服務是設計來提供正確的可靠性和彈性層級。 您可以透過兩種方式加以設定。 可採用區域備援 (可跨區域自動複寫) 或區域性 (將執行個體釘選在特定區域)。 兩種方法可以結合使用。 如需區域與區域備援結構的詳細資訊,請參閱使用可用性區域和區域的建議。
服務區域的區域關閉體驗
在全區域中斷期間,受影響區域的呼叫會終止,在服務自我修復將基礎資源重新平衡到狀況良好的區域之前,區域內的容量短暫遺失。 這種自我修復並不依賴區域還原:預期 Microsoft 管理的服務自助修復狀態會使用來自其他區域的容量來補償遺失的區域。 攜帶資源的流量會以區域備援方式部署,但以最低的規模流量可由單一資源處理。 在此情況下,本文所述的故障轉移機制會將所有流量重新平衡至其他服務區域,而攜帶流量的資源則會重新部署在狀況良好的區域中。
管理區域的區域關閉體驗
在全區域中斷期間,不需在區域復原期間採取任何動作。 管理區域自我修復和重新平衡,以自動利用健康區域。
災害復原:回復至其他區域
災害復原 (DR) 是指從重大影響事件中復原,例如自然災害或不成功的部署 (導致停機和資料遺失)。 無論原因為何,解決災害的最佳辦法是定義完善且經過測試的 DR 方案,以及主動支援 DR 的應用程式設計。 開始制定災害復原方案之前,請參閱設計災害復原策略的建議。
Microsoft 在災害復原方面,採取共同責任模型。 在共同責任模型中,Microsoft 確保基準基礎結構和平台服務可供使用。 此時許多 Azure 服務不會自動複寫資料,或從故障區域恢復並交叉複寫到另一個已啟用的區域。 您需要為這些服務制定適合工作負載的災害復原方案。 在 Azure 平台即服務 (PaaS) 供應項目上執行的多數服務,都有提供支援災害復原的功能和指導,您可以使用特定服務功能復原,制定災害復原方案。
本節說明在全區域中斷期間 Azure 通訊網關的行為。
災害復原:服務區域的跨區域故障轉移
在全區域中斷期間,本文中所述的故障轉移機制(OPTIONS 輪詢和失敗時 SIP 重試)將會重新平衡其他服務區域的所有呼叫流量,以維持可用性。 我們將開始還原區域備援。 在延長停機時間期間還原區域備援可能需要使用其他 Azure 區域。 如果需要將失敗的區域移轉至另一個區域,我們會在開始任何移轉之前諮詢您。
Azure 通訊閘道中的 SBC 函式會提供 OPTIONS 輪詢,讓您的網路判斷對等可用性。 針對 MCP,您的網路必須能夠偵測 MCP 何時無法使用,並定期重試以判斷 MCP 何時再次可用。 MCP 不會回應SIP OPTIONS。
布建 API 用戶端會使用部署的基底功能變數名稱連絡 Azure Communications Gateway。 此網域的 DNS 記錄具有 60 秒的存留時間(TTL)。 當區域失敗時,Azure 會更新 DNS 記錄以參考另一個區域,因此進行新 DNS 查閱的用戶端會收到新區域的詳細數據。 我們建議確保用戶端可以在逾時或 5xx 回應之後,進行新的 DNS 查閱,然後重試要求 60 秒。
提示
實驗室部署不提供跨區域故障轉移(因為它們只有一個服務區域)。
災害復原:管理區域的跨區域故障轉移
語音流量和透過號碼管理入口網站布建不受管理區域中失敗影響,因為對應的 Azure 資源裝載於服務區域中。 號碼管理入口網站的使用者可能需要再次登入。
監視服務可能暫時無法使用,直到服務還原為止。 如果管理區域遇到延長停機時間,我們會將受影響的資源移轉至另一個可用的區域。
選擇管理和服務區域
Azure 通訊閘道的單一部署旨在處理地理區域內的流量。 在相同地理區域內的生產部署中部署這兩個服務區域(例如 北美洲)。 此模型可確保語音通話的延遲會維持在 電信業者連線 和 Teams 電話 行動程式所需的限制內。
當您選擇服務區域位置時,請考慮下列幾點:
- 從可用的 Azure 區域清單中選取。 您可以在 [依區域的產品] 頁面上看到可選取為服務區域的 Azure 區域。
- 選擇靠近您自己內部部署的區域,以及網路與 Microsoft 之間的對等互連位置,以減少通話延遲。
- 偏好 使用區域配對 ,以在發生多區域中斷時將復原時間降到最低。
從下列清單中選擇管理區域:
- 美國東部
- 美國中西部
- 西歐
- 英國南部
- 印度中部
- 加拿大中部
- 澳大利亞東部
管理區域可以與服務區域共置。 建議您選擇最接近服務區域的管理區域。
注意
如果您啟用 Azure 操作員通話保護預覽版,您選取的服務區域可能不是部署支援資源的 Azure 區域。 如需目前支援的 Azure 操作員通話保護服務區域清單,請參閱 依區域的 Azure 產品,並在選取哪個區域時與您的上線小組交談。
服務等級協定
本檔中所述的可靠性設計是由 Microsoft 實作,無法設定。 如需 Azure 通訊閘道服務等級協定 (SLA) 的詳細資訊,請參閱 Azure 通訊閘道 SLA。
下一步
- 瞭解如何 將 Azure 通訊網關聯機到您的網路
- 瞭解 Azure 通訊閘道如何保護您的網路和數據安全
- 深入了解 規劃 Azure 通訊閘道部署