適用於:![]() MongoDB
MongoDB
此移轉指南是將資料庫從 MongoDB 移轉至適用於 MongoDB 的 Azure Cosmos DB API 系列的一部分。 重要的移轉步驟分為移轉前、移轉和移轉後,如下所示。
使用 Azure Databricks 移轉資料
Azure Databricks 是 Apache Spark 的平台即服務 (PaaS) 供應項目。 其提供一種在大規模資料集上執行離線移轉的方法。 您可以使用 Azure Databricks,將資料庫從 MongoDB 離線移轉至 Azure Cosmos DB for MongoDB。
在本教學課程中,您將了解如何:
佈建 Azure Databricks 叢集
新增相依性
建立並執行 Scala 或 Python 筆記本
最佳化移轉效能
針對可能會在移轉期間觀察到的錯誤進行疑難排解
必要條件
若要完成本教學課程,您需要:
- 完成移轉前步驟,例如估計輸送量和選擇分區金鑰。
- 建立 Azure Cosmos DB for MongoDB 帳戶。
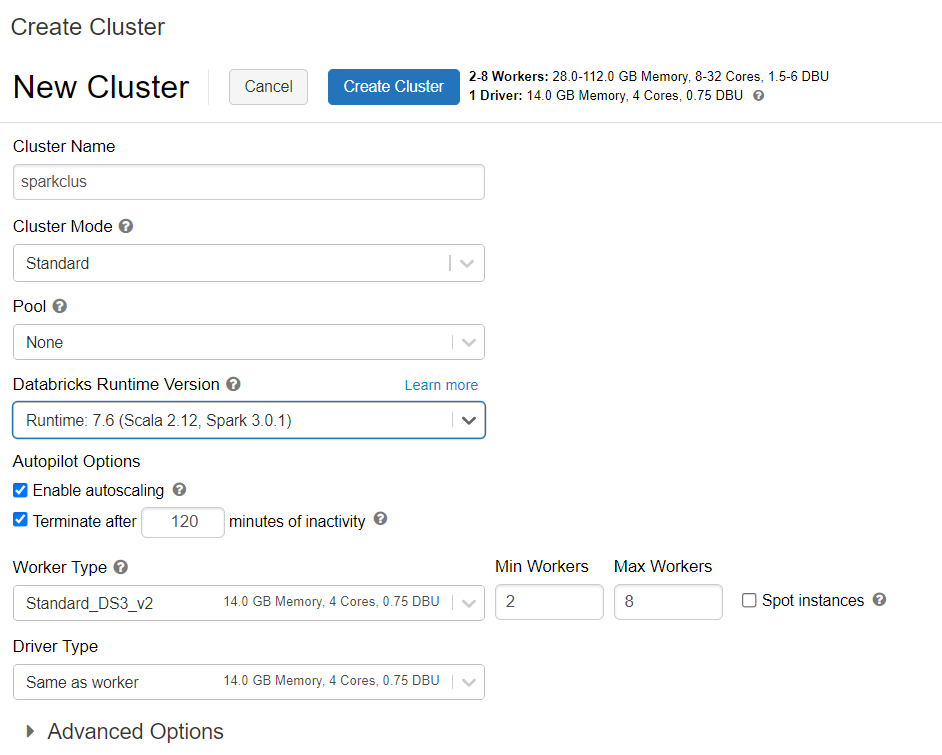
佈建 Azure Databricks 叢集
您可以遵循指示來佈建 Azure Databricks 叢集。 建議您選取支援 Spark 3.0 的 Databricks Runtime 7.6 版本。
新增相依性
將適用於 Spark 的 MongoDB 連接器程式庫新增至您的叢集,以同時連線至原生 MongoDB 端點和 Azure Cosmos DB for MongoDB 端點。 在您的叢集中,選取 [程式庫] > [安裝新的] > [Maven],然後新增 org.mongodb.spark:mongo-spark-connector_2.12:3.0.1 Maven 座標。
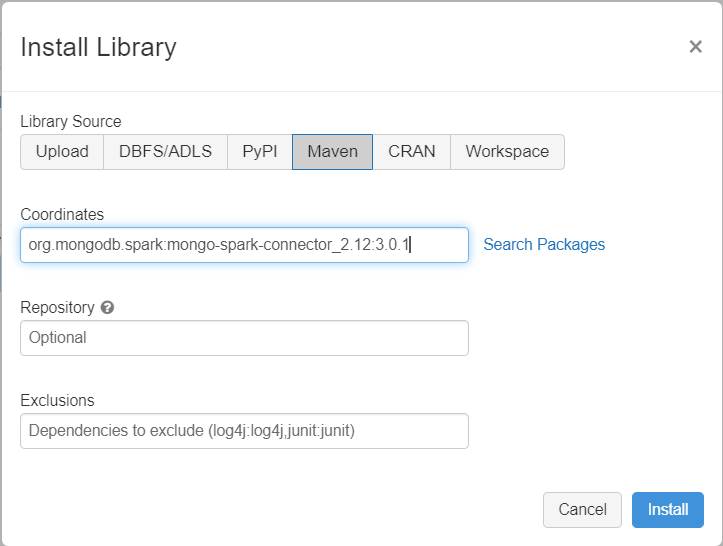
選取 [安裝],然後在安裝完成時重新啟動叢集。
注意
在安裝了適用於 Spark 的 MongoDB 連接器程式庫之後,請務必重新啟動 Databricks 叢集。
接著,您可以建立 Scala 或 Python 筆記本以進行移轉。
建立 Scala 筆記本以進行移轉
在 Databricks 中建立 Scala 筆記本。 請務必先為變數輸入正確的值,然後再執行下列程式碼:
import com.mongodb.spark._
import com.mongodb.spark.config._
import org.apache.spark._
import org.apache.spark.sql._
var sourceConnectionString = "mongodb://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<AUTHDB>"
var sourceDb = "<DB NAME>"
var sourceCollection = "<COLLECTIONNAME>"
var targetConnectionString = "mongodb://<ACCOUNTNAME>:<PASSWORD>@<ACCOUNTNAME>.mongo.cosmos.azure.com:10255/?ssl=true&replicaSet=globaldb&retrywrites=false&maxIdleTimeMS=120000&appName=@<ACCOUNTNAME>@"
var targetDb = "<DB NAME>"
var targetCollection = "<COLLECTIONNAME>"
val readConfig = ReadConfig(Map(
"spark.mongodb.input.uri" -> sourceConnectionString,
"spark.mongodb.input.database" -> sourceDb,
"spark.mongodb.input.collection" -> sourceCollection,
))
val writeConfig = WriteConfig(Map(
"spark.mongodb.output.uri" -> targetConnectionString,
"spark.mongodb.output.database" -> targetDb,
"spark.mongodb.output.collection" -> targetCollection,
"spark.mongodb.output.maxBatchSize" -> "8000"
))
val sparkSession = SparkSession
.builder()
.appName("Data transfer using spark")
.getOrCreate()
val customRdd = MongoSpark.load(sparkSession, readConfig)
MongoSpark.save(customRdd, writeConfig)
建立 Python 筆記本以進行移轉
在 Databricks 中建立 Python 筆記本。 請務必先為變數輸入正確的值,然後再執行下列程式碼:
from pyspark.sql import SparkSession
sourceConnectionString = "mongodb://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<AUTHDB>"
sourceDb = "<DB NAME>"
sourceCollection = "<COLLECTIONNAME>"
targetConnectionString = "mongodb://<ACCOUNTNAME>:<PASSWORD>@<ACCOUNTNAME>.mongo.cosmos.azure.com:10255/?ssl=true&replicaSet=globaldb&retrywrites=false&maxIdleTimeMS=120000&appName=@<ACCOUNTNAME>@"
targetDb = "<DB NAME>"
targetCollection = "<COLLECTIONNAME>"
my_spark = SparkSession \
.builder \
.appName("myApp") \
.getOrCreate()
df = my_spark.read.format("com.mongodb.spark.sql.DefaultSource").option("uri", sourceConnectionString).option("database", sourceDb).option("collection", sourceCollection).load()
df.write.format("mongo").mode("append").option("uri", targetConnectionString).option("maxBatchSize",2500).option("database", targetDb).option("collection", targetCollection).save()
最佳化移轉效能
您可以透過下列設定來調整移轉效能:
Spark 叢集中的背景工作角色和核心數目:背景工作角色越多,表示有越多計算節點執行工作。
maxBatchSize:
maxBatchSize值會控制將資料儲存至目標 Azure Cosmos DB 集合的速率。 不過,如果 maxBatchSize 對集合輸送量而言太高,其可能會導致速率限制錯誤。您必須調整背景工作角色的數目和 maxBatchSize,取決於 Spark 叢集中的執行程式數目、也可能是每個所寫入文件的大小 (這就是為何使用 RU 成本的原因),以及目標集合輸送量限制。
提示
maxBatchSize = 集合輸送量 / (1 份文件的 RU 成本 * Spark 背景工作角色的數目 * 每個背景工作角色的 CPU 核心數目)
MongoDB Spark 分割區和 partitionKey:所使用的預設分割區為 MongoDefaultPartitioner,而預設 partitionKey 為 _id。 您可以藉由將值
MongoSamplePartitioner指派給輸入設定屬性spark.mongodb.input.partitioner來變更分割器。 同樣地,可以藉由將適當的欄位名稱指派給輸入設定屬性spark.mongodb.input.partitioner.partitionKey來變更 partitionKey。 正確的 partitionKey 有助於避免資料扭曲 (針對相同的分區金鑰值寫入大量記錄)。在資料傳輸期間停用索引:針對大量的資料移轉,請考慮停用索引,特別是目標集合上的萬用字元索引。 索引會增加寫入每份文件的 RU 成本。 釋放這些 RU 可協助改善資料傳輸速率。 一旦資料移轉後,您就可以啟用索引。
疑難排解
逾時錯誤 (錯誤碼 50)
對 Azure Cosmos DB for MongoDB 資料庫進行作業時,您可能會看到 50 錯誤碼。 下列案例可能會導致逾時錯誤:
- 配置給資料庫的輸送量很低:請確定目標集合已獲派足夠的輸送量。
- 具有大量資料量的資料扭曲過多。 如果您有大量資料要移轉到給定的資料表,但在資料中有明顯的扭曲,則即使您在資料表中佈建了數個要求單位,仍可能會遇到速率限制。 要求單位會平均分配至實體分割區,而大量資料扭曲可能會造成單一分區要求的瓶頸。 資料扭曲表示相同分區金鑰值的大量記錄。
速率限制 (錯誤碼 16500)
對 Azure Cosmos DB for MongoDB 資料庫進行作業時,您可能會看到 16500 錯誤碼。 這些是速率限制錯誤,而且可能會在停用伺服器端重試功能的較舊帳戶上觀察到這些錯誤。
- 啟用伺服器端重試:啟用伺服器端重試 (SSR) 功能,並讓伺服器自動重試速率限制的作業。
移轉後最佳化
移轉資料後,您可以連線到 Azure Cosmos DB 並管理資料。 您也可以遵循其他的移轉後步驟,例如將索引編製原則最佳化、更新預設的一致性層級或設定 Azure Cosmos DB 帳戶的全域散發。 如需詳細資訊,請參閱移轉後最佳化一文。
其他資源
- 正在嘗試為遷移至 Azure Cosmos DB 進行容量規劃嗎?
- 如果您知道現有資料庫叢集中的虛擬核心和伺服器數目,請參閱使用虛擬核心或 vCPU 來估計要求單位
- 如果您知道目前資料庫工作負載的一般要求率,請參閱使用 Azure Cosmos DB 容量規劃工具來估計要求單位