雖然無結構描述的資料庫 (例如 Azure Cosmos DB) 可讓您輕鬆儲存和查詢非結構化資料與半結構化資料,但請考慮到您的資料模型,以將效能、可擴縮性和成本最佳化。
儲存資料的方式 您的應用程式如何擷取和查詢資料? 您的應用程式是大量讀取或大量寫入?
閱讀完本文之後,您可以回答下列問題:
- 什麼是資料模型化,以及為什麼應該關心?
- Azure Cosmos DB 中的資料模型化與關聯式資料庫中的有何不同?
- 如何表達非關聯式資料庫中的資料關聯性?
- 何時內嵌資料,以及何時連結至資料?
JSON 中的數字
Azure Cosmos DB 會以 JSON 格式儲存文件,因此請務必先判斷是否要將數字轉換成字串,再將數字儲存在 JSON 中。 如果數字可能超過 IEEE 754 binary64 (英文) 所定義的雙精確度數字範圍,請將所有數字轉換為 String。
JSON 規格 (英文) 會說明為什麼因為互通性問題,使用超出此範圍的數字是不好的作法。 這些問題尤其與分割區索引鍵資料行有關,因為其不可變,必須在資料移轉後才能變更。
內嵌資料
當您在 Azure Cosmos DB 中將資料模型化時,請將您的實體視為以 JSON 文件表示的獨立式項目。
為了進行比較,我們先來看看我們可能會如何在關係資料庫中建立資料模型。 下列範例示範人員可能如何儲存在關聯式資料庫中。
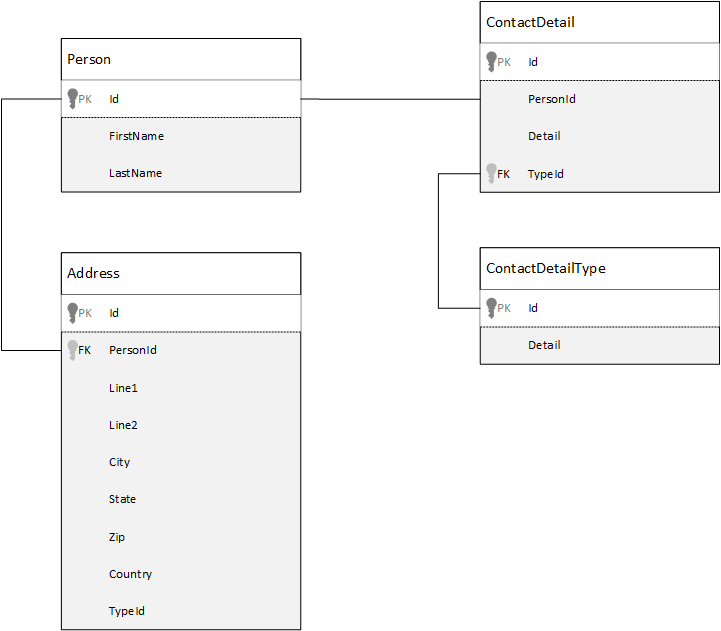
使用關聯式資料庫時,策略是將您所有的資料標準化。 將您的資料正規化通常會牽涉到取得某個實體 (例如某個人),然後將其分解為離散的元件。 在範例中,人員可以有多個連絡詳細資料記錄,以及多個地址記錄。 您可以透過擷取類型等常見欄位,來進一步細分連絡人詳細資料。 同樣的方法也適用於地址。 每筆記錄都可以分類為「家裡」或「公司」。
將資料正規化的引導前提是在每個記錄資料上避免儲存多餘的資料,而是參考資料。 在此範例中,若要讀取人員及其所有連絡詳細資料和地址,您需要使用「聯結」有效地在執行階段回寫 (或反正規化) 資料。
SELECT p.FirstName, p.LastName, a.City, cd.Detail
FROM Person p
JOIN ContactDetail cd ON cd.PersonId = p.Id
JOIN ContactDetailType cdt ON cdt.Id = cd.TypeId
JOIN Address a ON a.PersonId = p.Id
更新單一人員的連絡詳細資料和地址需要跨許多個別資料表執行寫入作業。
現在讓我們看看如何將相同的資料模型化為 Azure Cosmos DB 中的獨立實體。
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"addresses": [
{
"line1": "100 Some Street",
"line2": "Unit 1",
"city": "Seattle",
"state": "WA",
"zip": 98012
}
],
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555", "extension": 5555}
]
}
使用此方法,我們已將人員記錄反正規化,方法是內嵌與人員相關的所有資訊 (例如他們的連絡詳細資料和地址) 到「單一 JSON」文件。 此外,因為我們不受限於固定的架構,我們有彈性可以處理聯絡資訊的不同形式。
從資料庫擷取完整的人員記錄現在是針對單一項目的單一容器所執行的單一讀取作業。 更新連絡詳細資料和地址等個人記錄,也是針對單一項目的單一寫入作業。
將資料反正規化可能會減少應用程式完成一般作業所需的查詢和更新數目。
內嵌的時機
一般而言,使用內嵌的資料模型的時機為:
- 實體之間有內含的關聯性。
- 實體之間有 一對少數 關聯性。
- 資料很少變更。
- 資料不會無限制地成長。
- 資料經常一起進行查詢。
附註
通常反正規化的資料模型可提供較佳的 讀取 效能。
不要內嵌的時機
雖然在 Azure Cosmos DB 中的經驗法則是將所有項目反正規化,並將所有資料內嵌到單一項目,但此方法可能會導致某些要避免的情況。
取得此 JSON 程式碼片段。
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"comments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
…
{"id": 100001, "author": "jane", "comment": "and on we go ..."},
…
{"id": 1000000001, "author": "angry", "comment": "blah angry blah angry"},
…
{"id": ∞ + 1, "author": "bored", "comment": "oh man, will this ever end?"},
]
}
如果我們要將一般的部落格或內容管理系統 (CMS) 模型化,此範例可能是具有內嵌註解的貼文實體的可能樣貌。 此範例的問題在於註解陣列是 unbounded,表示任何單一文章可以具備的註解數目沒有 (實際) 的限制。 這種設計可能會導致問題,因為項目的大小可能會成長到無限大,因此請避免使用。
隨著項目大小的增加,大規模傳輸、讀取和更新資料變得越發困難。
在此情況下,最好考慮使用下列資料模型。
Post item:
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"recentComments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
{"id": 3, "author": "jane", "comment": "....."}
]
}
Comment items:
[
{"id": 4, "postId": "1", "author": "anon", "comment": "more goodness"},
{"id": 5, "postId": "1", "author": "bob", "comment": "tails from the field"},
...
{"id": 99, "postId": "1", "author": "angry", "comment": "blah angry blah angry"},
{"id": 100, "postId": "2", "author": "anon", "comment": "yet more"},
...
{"id": 199, "postId": "2", "author": "bored", "comment": "will this ever end?"}
]
這個模型會為每一則留言建立一個項目,項目裡會有一個屬性,屬性中包含貼文的識別碼。 這個模型可讓貼文包含任意數量的留言,並且可以有效率地成長。 使用者不只是想查看最近的留言,則會在查詢此容器時傳遞 postId,而這應該是留言容器的分割區索引鍵。
內嵌資料並不是好主意的另一種情況是在內嵌的資料經常跨項目使用,而且經常變更時。
取得此 JSON 程式碼片段。
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{
"numberHeld": 100,
"stock": { "symbol": "zbzb", "open": 1, "high": 2, "low": 0.5 }
},
{
"numberHeld": 50,
"stock": { "symbol": "xcxc", "open": 89, "high": 93.24, "low": 88.87 }
}
]
}
此範例可以代表個人的股票投資組合。 我們已選擇內嵌股票資料到每個投資組合文件。 在相關資料經常會變更的環境中,內嵌經常變更的資料表示您會經常更新每個投資組合。 以股票交易應用程式為例,您每次交易股票時都會更新每個投資組合的項目。
股票 zbzb 可能在一天之中交易數百次,而且 zbzb 可能會在上千名使用者的投資組合中。 使用此範例之類的資料模型時,系統必須每天多次更新數千個投資組合文件,這樣的模型不易縮放。
參考資料
內嵌資料適合許多情況,但有時將資料反正規化會造成更多問題,而得不償失。 那麼,您可以做什麼呢?
您可以在文件資料庫中 (而不只是在關聯式資料庫中) 的實體之間建立關聯性。 在文件資料庫中,一個項目可以包含連接至其他文件中資料的資訊。 Azure Cosmos DB 並非專為複雜的關聯性 (例如關聯式資料庫中的關聯性) 而設計,但項目之間的簡單連結是做得到的,而且可能會有所幫助。
在 JSON 中,我們使用先前的股票投資組合範例,但這次我們改為參考 (而非內嵌) 投資組合中的股票項目。 如此一來,當股票項目在一整天之中頻繁變更時,需要更新的項目就只有那一個股票文件。
Person document:
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{ "numberHeld": 100, "stockId": 1},
{ "numberHeld": 50, "stockId": 2}
]
}
Stock documents:
{
"id": "1",
"symbol": "zbzb",
"open": 1,
"high": 2,
"low": 0.5,
"vol": 11970000,
"mkt-cap": 42000000,
"pe": 5.89
},
{
"id": "2",
"symbol": "xcxc",
"open": 89,
"high": 93.24,
"low": 88.87,
"vol": 2970200,
"mkt-cap": 1005000,
"pe": 75.82
}
這個方法有一個缺點,那就是您的應用程式必須提出數個資料庫要求,才能取得個人投資組合中每檔股票的相關資訊。 這種設計可加快資料寫入速度,因為更新發生得很頻繁。 然而,卻會降低資料的讀取或查詢速度,不會這一點對此系統來說較不重要。
附註
正規化的資料模型 可能需要更多來回行程 到伺服器。
外部索引鍵呢?
因為沒有限制式的概念 (例如外部索引鍵),所以資料庫不會驗證文件中的任何文件間關聯性;這些連結實際上很「薄弱」。如果您想要確保項目所參考的資料確實存在,就必須在應用程式中執行此步驟,或在 Azure Cosmos DB 上使用伺服器端觸發程序或預存程序。
參考時機
一般而言,使用正規化資料模型的時機為:
- 代表一對多關聯性。
- 代表多對多關聯性。
- 相關資料 經常變更。
- 參考資料可能是無限制的。
附註
通常正規化可提供較佳的 寫入 效能。
關聯性應置於何處?
關聯性的成長有助於判斷用來儲存參考的項目。
如果我們觀察為出版商和書籍建立模型的 JSON。
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press",
"books": [ 1, 2, 3, ..., 100, ..., 1000]
}
Book documents:
{"id": "1", "name": "Azure Cosmos DB 101" }
{"id": "2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "3", "name": "Taking over the world one JSON doc at a time" }
...
{"id": "100", "name": "Learn about Azure Cosmos DB" }
...
{"id": "1000", "name": "Deep Dive into Azure Cosmos DB" }
如果每個出版社出版的書籍數量很少且成長有限,則將書籍參考儲存在出版社項目內可能會很有用。 不過,如果每個發行者的書籍數量無限,此資料模型會導致可變動、成長的陣列,如範例發行者文件所示。
切換結構會產生代表相同資料的模型,但能避免出現大型且可變動的集合。
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press"
}
Book documents:
{"id": "1","name": "Azure Cosmos DB 101", "pub-id": "mspress"}
{"id": "2","name": "Azure Cosmos DB for RDBMS Users", "pub-id": "mspress"}
{"id": "3","name": "Taking over the world one JSON doc at a time", "pub-id": "mspress"}
...
{"id": "100","name": "Learn about Azure Cosmos DB", "pub-id": "mspress"}
...
{"id": "1000","name": "Deep Dive into Azure Cosmos DB", "pub-id": "mspress"}
在此範例中,出版社文件不再包含無限制的集合。 相反地,每個書籍文件都包含對其出版社的參考。
如何建立多對多關聯性的模型?
在關聯式資料庫中,通常會使用聯結資料表將多對多關聯性模型化。 這些關聯性只會將其他資料表中的記錄聯結在一起。
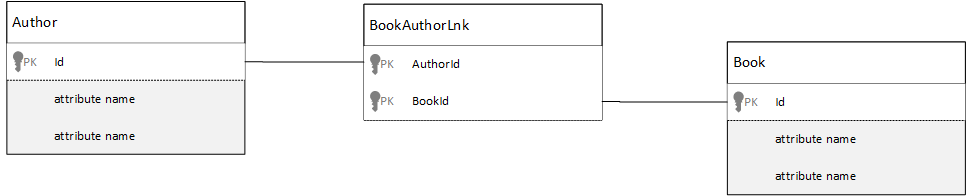
您可能會想要使用文件複寫相同的項目,並產生看起來如下所示的資料模型。
Author documents:
{"id": "a1", "name": "Thomas Andersen" }
{"id": "a2", "name": "William Wakefield" }
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101" }
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "b3", "name": "Taking over the world one JSON doc at a time" }
{"id": "b4", "name": "Learn about Azure Cosmos DB" }
{"id": "b5", "name": "Deep Dive into Azure Cosmos DB" }
Joining documents:
{"authorId": "a1", "bookId": "b1" }
{"authorId": "a2", "bookId": "b1" }
{"authorId": "a1", "bookId": "b2" }
{"authorId": "a1", "bookId": "b3" }
這種方法可行,但要載入某位作者及其撰寫的書籍,或是載入某本書及其作者,一律至少需要額外兩個資料庫查詢。 一個查詢用來取得聯結的項目,另一個查詢則用來擷取要被聯結的實際項目。
如果此聯結的作用只是在將兩組資料結合在一起,那麼為何不將其完全捨棄? 請思考一下下列範例。
Author documents:
{"id": "a1", "name": "Thomas Andersen", "books": ["b1", "b2", "b3"]}
{"id": "a2", "name": "William Wakefield", "books": ["b1", "b4"]}
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101", "authors": ["a1", "a2"]}
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users", "authors": ["a1"]}
{"id": "b3", "name": "Learn about Azure Cosmos DB", "authors": ["a1"]}
{"id": "b4", "name": "Deep Dive into Azure Cosmos DB", "authors": ["a2"]}
使用此模型時,您可以透過查看作者的文件,輕鬆了解作者寫了哪些書。 您還可以透過查看書籍文件,了解哪些作者寫了某本書。 您不需要使用個別的聯結資料表或進行額外的查詢。 此模型可讓您的應用程式更快、更簡單地取得所需的資料。
混合式資料模型
我們將探討資料的內嵌 (或反正規化) 與參考 (或正規化)。 這兩種方法各有其優點,同時也伴隨著取捨。
不一定非得二擇一。 可以放心地稍微混合使用看看。
根據您應用程式的具體使用模式和工作負載,混合使用內嵌資料和參考資料可能是合理的做法。 這種方法可以簡化應用程式邏輯、減少伺服器往返次數,並維持良好的效能。
請考慮下列 JSON。
Author documents:
{
"id": "a1",
"firstName": "Thomas",
"lastName": "Andersen",
"countOfBooks": 3,
"books": ["b1", "b2", "b3"],
"images": [
{"thumbnail": "https://....png"}
{"profile": "https://....png"}
{"large": "https://....png"}
]
},
{
"id": "a2",
"firstName": "William",
"lastName": "Wakefield",
"countOfBooks": 1,
"books": ["b1"],
"images": [
{"thumbnail": "https://....png"}
]
}
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
{"id": "a2", "name": "William Wakefield", "thumbnailUrl": "https://....png"}
]
},
{
"id": "b2",
"name": "Azure Cosmos DB for RDBMS Users",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
]
}
這裡我們 (大致上) 採用了內嵌模型,即來自其他實體的資料會內嵌在最上層的文件中,但其他資料則以參考方式處理。
如果您查看書籍文件,在查看作者陣列時就會看到一些有趣的欄位。 有一個 id 欄位,這是我們用來往回參考某個作者文件的欄位,也是正規化模型中的標準做法;但我們同時也有 name 和 thumbnailUrl。 我們可以只使用 id,讓應用程式使用「連結」從對應的作者項目中擷取其所需的任何其他資訊。不過,由於應用程式會在每本書中顯示作者的姓名和縮圖,因此將作者的某些資料反正規化,可以減少清單中每本書的伺服器往返次數。
如果作者的姓名發生變化或作者更新了相片,則您需要更新其所出版的每一本書。 不過,對於此應用程式來說,假設作者姓名很少變更,則這種折衷方案是可接受的設計決策。
範例中有預先計算的彙總值,可節省讀取作業期間的高昂處理費用。 在範例中,作者項目中內嵌的部分資料是在執行階段計算的資料。 每次有新書出版時,系統便會建立書籍項目,並且會將 countOfBooks 欄位設定為根據某位特定作者存在的書籍文件數目所計算出的值。 在讀取繁重的系統中 (我們可以負擔執行寫入計算以最佳化讀取),這項最佳化將很適合。
由於 Azure Cosmos DB 支援多文件交易,因此模型現在能夠具有預先計算的欄位。 許多 NoSQL 存放區無法跨文件執行交易,因此會因應這個限制而建議採取「所有資料一律嵌入」之類的設計決策。 藉由 Azure Cosmos DB,您可以使用伺服器端觸發程序或預存程序,插入書籍並更新作者,全都在 ACID 交易內完成。 現在,您不必為了確保資料一致性就把所有資料都內嵌到一個項目中。
區分不同的項目類型
在某些情況下,您可能會想要在相同的集合中混合使用不同的項目類型;當您想要讓多個相關文件位於相同的分割區時,通常就會選擇這個設計。 例如,您可以將書籍和書籍評論放在相同的集合中,並依 bookId 將其分割。 在這種情況下,您通常會想要在文件中新增可識別文件類型的欄位,以便能加以區分。
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"bookId": "b1",
"type": "book"
}
Review documents:
{
"id": "r1",
"content": "This book is awesome",
"bookId": "b1",
"type": "review"
}
{
"id": "r2",
"content": "Best book ever!",
"bookId": "b1",
"type": "review"
}
適用於 Azure Synapse Link 和 Azure Cosmos DB 分析存放區的資料模型
適用於 Azure Cosmos DB 的 Azure Synapse Link 是雲端原生的混合式交易和分析處理 (HTAP) 功能,可讓您對 Azure Cosmos DB 中的作業資料執行近即時分析。 Azure Synapse Link 會在 Azure Cosmos DB 與 Azure Synapse Analytics 之間建立順暢的整合。
這項整合會透過 Azure Cosmos DB 分析存放區來實現,分析存放區會以單欄方式呈現您的交易資料,能夠進行大規模分析,又不會影響交易工作負載。 分析存放區可讓您以快速且經濟實惠的方式,對大型資料集執行查詢。 您不需要複製資料,也不需要擔心會減慢主資料庫的速度。 當您開啟容器的分析存放區時,您對資料所做的每項變更幾乎都會立即複製到分析存放區。 您不需要設定變更摘要或執行擷取、轉換和載入 (ETL) 作業。 系統會自動幫您保持兩個存放區的同步。
有了 Azure Synapse Analytics,您現在可以從 Azure Synapse Analytics 直接連線到您的 Azure Cosmos DB 容器,並存取分析存放區,而不需要要求單位 (要求單位) 成本。 Azure Synapse Analytics 目前支援 Azure Synapse Link 搭配 Synapse Apache Spark 和無伺服器 SQL 集區。 如果您有全域分佈的 Azure Cosmos DB 帳戶,在啟用容器的分析存放區之後,該存放區將可用於該帳戶的所有區域。
分析存放區自動結構描述推斷
Azure Cosmos DB 的交易存放區是資料列導向的半結構化資料,分析存放區則會使用單欄式和結構化的格式。 這項轉換會使用分析存放區的結構描述推斷規則來自動為客戶進行。 轉換程序有一些限制:最大的巢狀層級數目、屬性的最大數目、不支援的資料類型等等。
附註
在分析存放區的內容中,我們將下列結構視為屬性:
- JSON「元素」,或「以
:分隔的字串-值組」 - JSON 物件 (以
{和}分隔) - JSON 陣列 (以
[和]分隔)
您可以使用下列技術,將結構描述推斷轉換的效果降到最低,並最大幅度提高分析功能。
正規化
正規化的重要性降低了,因為 Azure Synapse Link 允許您使用 T-SQL 或 Spark SQL 來聯結容器。 正規化的預期優點如下:
- 交易和分析存放區中的資料磁碟使用量較小。
- 交易較小。
- 每份文件的屬性較少。
- 具有較少巢狀層級的資料結構。
減少資料中的屬性和層級,可加快分析查詢的速度。 這麼做也有助於確保資料的所有部分都納入到分析存放區中。 如自動結構描述推斷規則一文所述,在分析存放區中表示的層級和屬性數目有一些限制。
正規化的另一個重要因素是,Azure Synapse 中的 SQL 無伺服器集區支援最多 1,000 個資料行的結果集,而公開的巢狀資料行也會計入該限制。 換句話說,分析存放區和 Synapse SQL 無伺服器集區的限制為 1,000 個屬性。
但是,由於反正規化是 Azure Cosmos DB 的重要資料模型技術,應該採取什麼動作? 答案是您必須找出交易和分析工作負載的正確平衡。
分割區索引鍵
Azure Cosmos DB 分割區索引鍵 (PK) 不會用在分析存放區中。 現在您可以使用您所需的任何 PK,將分析存放區自訂分割區用於分析存放區的複本。 由於這項隔離,您可以針對交易資料選擇 PK,並將焦點放在資料擷取和點讀取,同時使用 Azure Synapse Link 來完成跨分割區查詢。 看看以下範例:
在假想的全球 IoT 案例中,device id 是不錯的分割區索引鍵,因為所有裝置都會產生類似的資料量,從而防止經常性分割區問題。 但是,如果您想要分析多個裝置的資料,例如「所有來自昨天的資料」或「每個城市的總計」,您可能會遇到問題,因為這些查詢是跨分割區的查詢。 這些查詢可能會損害您的交易效能,因為其會在要求單位中使用您的部分輸送量來執行。 但使用 Azure Synapse Link 時,您可以不花費要求單位成本來執行這些分析查詢。 分析存放區的單欄式格式已針對分析查詢進行最佳化,而 Azure Synapse Link 則透過 Azure Synapse Analytics 執行階段來支援絕佳的效能。
資料類型和屬性名稱
自動結構描述推斷規則文章會列出支援的資料類型。 雖然 Azure Synapse 執行階段可能會以不同的方式處理支援的資料類型,但不支援的資料類型會阻礙在分析存放區中的表示。 其中一個範例是:使用遵循 ISO 8601 UTC 標準的日期時間字串時,Azure Synapse 中的 Spark 集區會將這些欄表示為 string,而 Azure Synapse 中的 SQL 無伺服器集區則會將這些欄表示為 varchar(8000)。
另一個挑戰是 Azure Synapse Spark 並不接受所有字元。 在接受空白字元的情況下,不會有冒號、抑音符號和逗點等字元。 假設您的項目有一個名為 "First Name, Last Name" 的屬性。 這個屬性表示在分析儲存中,而 Synapse SQL 無伺服器集區可以毫無問題地讀取它。 但因為其是在分析存放區中,所以 Azure Synapse Spark 無法讀取分析存放區中的任何資料,包括所有其他屬性。 最終來說,如果某個屬性的名稱中使用了不支援的字元,那麼您就無法使用 Azure Synapse Spark。
資料壓平合併
Azure Cosmos DB 資料最上層的每個屬性都會成為分析存放區中的欄。 巢狀物件或陣列內的屬性會以 JSON 的形式儲存在分析存放區中,並保留其結構。 巢狀結構會要求從 Azure Synapse 執行階段進行額外的處理,以將資料以結構化格式壓平合併,在大型資料案例中可能會是一大挑戰。
在分析存放區中,這個項目只有兩個欄,分別是 id 和 contactDetails。 所有其他資料 (email 和 phone) 則需要透過 SQL 函式進行額外處理才能個別讀取。
{
"id": "1",
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555"}
]
}
在分析存放區中,這個項目有三個欄,分別是 id、email 和 phone。 所有資料都可以直接以資料行的形式存取。
{
"id": "1",
"email": "thomas@andersen.com",
"phone": "+1 555 555-5555"
}
資料分層
Azure Synapse Link 可讓您從下列方面降低成本:
- 在交易資料庫中執行的查詢較少。
- 針對資料擷取和點讀取最佳化的 PK,可減少資料磁碟使用量、經常性存取層分割區案例和分割區分割。
- 由於分析存留時間 (attl) 與交易存留時間 (tttl) 無關,因此資料會分層。 您可以在交易存放區中保留幾天、數周、數個月的交易資料,並將資料保留在分析存放區數年或永久保存。 分析存放區的單欄式格式會帶來自然資料壓縮,從 50% 高達 90%。 而其每 GB 的成本是交易存放區實際價格的大約 10%。 如需目前備份限制的詳細資訊,請參閱分析存放區概觀。
- 沒有任何 ETL 作業在您的環境中執行,這表示您不需要為其配置要求單位。
控制的冗餘
這個技術是資料模型已存在且無法變更時的絕佳替代方案。 目前的資料模型和分析存放區之間的搭配效果不理想。 這個技術的優勢在於,分析存放區有一些規則,會限制您可以將資料巢狀化的層級數目,以及每個文件中可以擁有的屬性數目。 如果您的資料太複雜或欄位太多,則某些重要資訊可能不會納入到分析存放區中。 如果這個案例便是您的情況,您可以使用 Azure Cosmos DB 變更摘要 (部分機器翻譯) 將資料複寫到另一個容器,並套用 Azure Synapse Analytics 易記資料模型所需的轉換。 看看以下範例:
案例
容器 CustomersOrdersAndItems 用來儲存線上訂單,包括客戶和項目詳細資料:帳單地址、交貨地址、交貨方法、交貨狀態、項目價格等等。只會顯示前 1,000 個屬性,而且金鑰資訊不會包含在分析存放區中,因此會封鎖 Azure Synapse Link 的使用。 該容器具有數 PB 的記錄,因此無法變更應用程式並將資料重新模型化。
這個問題的另一個方面是資料量龐大。 分析部門經常使用數十億個資料列,而無法使用 tttl 來刪除舊的資料。 由於分析需求,在交易資料庫中維護整個資料歷程記錄會強制其不斷增加要求單位佈建,進而影響成本。 交易和分析工作負載會同時競爭相同的資源。
您可以做什麼?
具有變更摘要的解決方案
- 工程小組決定使用變更摘要來填入三個新的容器:
Customers、Orders和Items。 使用變更摘要時,其會將資料正規化和壓平合併。 從資料模型中移除不必要的資訊,而且每個容器都有接近 100 個屬性,可避免因為自動結構描述推斷限制而造成資料遺失。 - 這些新容器已啟用分析存放區,分析部門會使用 Synapse Analytics 來讀取資料。 這樣的設計能減少要求單位的使用量,因為分析查詢會在 Synapse Apache Spark 和無伺服器 SQL 集區中執行。
- 容器
CustomersOrdersAndItems現在已將存留時間 (TTL) 設定為只保留資料六個月,從而進一步降低要求單位的使用量,因為在 Azure Cosmos DB 中,每 GB 至少會有一個要求單位。 較少的資料、較少的要求單位。
重要心得
這篇文章最重要的重點是,即使在無結構描述的環境中,資料模型化依然同樣重要。
正如同沒有單一方法可表示螢幕上的資料片段,沒有單一方法可為您的資料建立模型。 您需要了解您的應用程式,以及其如何產生、取用和處理資料。 藉由套用此處所提供的指導方針,您可以建立模型來處理您應用程式的立即需求。 當應用程式發生變化時,請使用無結構描述資料庫的彈性,輕鬆調整和發展您的資料模型。