將資料從 Apache HBase 移轉至 Azure Cosmos DB for NoSQL 帳戶
適用於:![]() NoSQL
NoSQL
Azure Cosmos DB 是可調整、全域散發的完全受控資料庫。 其可為您的資料提供保證低度延遲的存取。 若要深入了解 Azure Cosmos DB,請參閱概觀一文。 此文章將引導您將資料從 HBase 移轉至 Azure Cosmos DB for NoSQL 帳戶。
Azure Cosmos DB 與 HBase 之間的差異
在移轉之前,您必須了解 Azure Cosmos DB 與 HBase 之間的差異。
資源模型
Azure Cosmos DB 具有下列資源模型: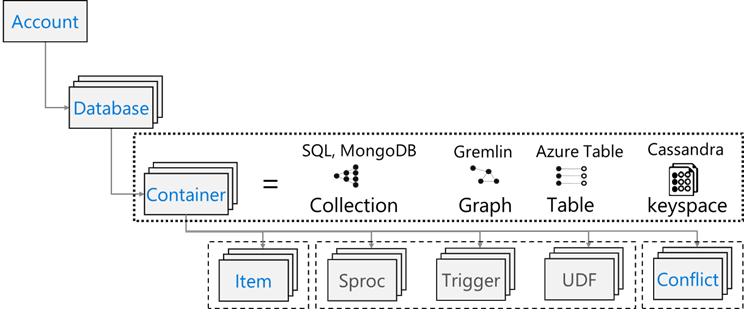
HBase 具有下列資源模型: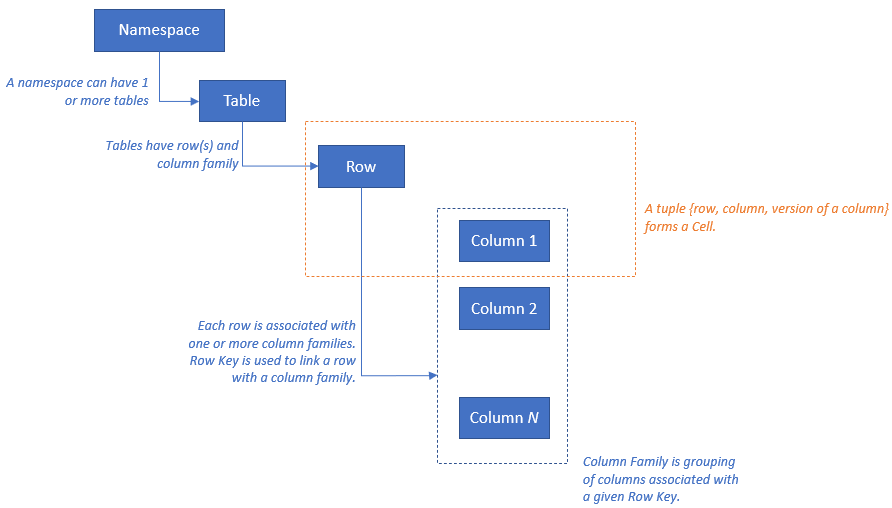
資源對應
下表顯示 Apache HBase、Apache Phoenix 和 Azure Cosmos DB 之間的概念性對應。
| HBase | Phoenix | Azure Cosmos DB |
|---|---|---|
| Cluster | 叢集 | 客戶 |
| Namespace | 結構描述 (若已啟用) | Database |
| Table | Table | 容器/集合 |
| 資料行系列 | 資料行系列 | N/A |
| 資料列 | 資料列 | 項目/文件 |
| 版本 (時間戳記) | 版本 (時間戳記) | N/A |
| N/A | 主索引鍵 | 分割區索引鍵 |
| N/A | 索引 | 索引 |
| N/A | 次要索引 | 次要索引 |
| N/A | 檢視 | N/A |
| N/A | 序列 | N/A |
資料結構比較和差異
Azure Cosmos DB 和 HBase 的資料結構之間的主要差異如下:
RowKey
在 HBase 中,資料是以 RowKey 儲存,並依資料表建立期間指定的 RowKey 範圍,以水平方式分割成多個區域。
另一端的 Azure Cosmos DB 會根據指定之分割區索引鍵的雜湊值,將資料散佈到各個分割區。
資料行系列
在 HBase 中,資料行會在資料行系列 (CF) 內分組。
Azure Cosmos DB (API for NoSQL) 會將資料儲存為 JSON 文件。 因此,與 JSON 資料結構相關聯的所有屬性都適用。
Timestamp
HBase 會使用時間戳記,為指定的資料格設定多個執行個體版本。 您可以使用時間戳記查詢不同版本的資料格。
Azure Cosmos DB 隨附變更摘要功能,可依其發生順序,追蹤容器變更的持續記錄。 接著依修改的順序來輸出已變更文件的排序清單。
資料格式
HBase 資料格式是由 RowKey、資料行系列 (資料行名稱、時間戳記、值) 所組成。 以下是 HBase 資料表資料列的範例:
ROW COLUMN+CELL 1000 column=Office:Address, timestamp=1611408732448, value=1111 San Gabriel Dr. 1000 column=Office:Phone, timestamp=1611408732418, value=1-425-000-0002 1000 column=Personal:Name, timestamp=1611408732340, value=John Dole 1000 column=Personal:Phone, timestamp=1611408732385, value=1-425-000-0001在 Azure Cosmos DB for NoSQL 中,JSON 物件代表資料格式。 分割區索引鍵位於文件中的欄位,並會設定哪一個欄位是集合的分割區索引鍵。 Azure Cosmos DB 沒有用於資料行系列或版本的時間戳記概念。 如先前所強調,其具有變更摘要支援,可讓您追蹤/記錄對容器執行的變更。 以下是文件的範例。
{ "RowId": "1000", "OfficeAddress": "1111 San Gabriel Dr.", "OfficePhone": "1-425-000-0002", "PersonalName": "John Dole", "PersonalPhone": "1-425-000-0001", }
提示
HBase 會將資料儲存在位元組陣列中,因此,如果您想要將包含雙位元組字元的資料移轉至 Azure Cosmos DB,資料必須是 UTF-8 編碼。
一致性模型
HBase 提供嚴格一致的讀取和寫入。
Azure Cosmos DB 提供五個定義完善的一致性層級。 每個層級都提供可用性和效能權衡取捨。 支援的一致性層級包括 (從最強到最弱):
- 強式
- 限定過期
- 工作階段
- 一致的前置詞
- 最終
調整大小
HBase
適用於 HBase、Master 的企業規模部署;區域伺服器;和 ZooKeeper 磁碟機大量調整大小。 HBase 與所有分散式應用程式一樣,都是針對擴增而設計。HBase 效能主要取決於 HBase RegionServers 的大小。 調整大小主要取決於兩個主要需求:必須儲存在 HBase 上的資料集輸送量和大小。
Azure Cosmos DB
Azure Cosmos DB 是 Microsoft 的 PaaS 供應項目,而底層基礎結構部署詳細資料則是從使用者擷取的。 佈建 Azure Cosmos DB 容器時,Azure 平台會自動佈建底層基礎結構 (計算、儲存體、記憶體、網路堆疊),以支援指定之工作負載的效能需求。 所有資料庫作業的成本都會由 Azure Cosmos DB 進行正規化,並以要求單位 (簡稱 RU) 表示。
若要估計您工作負載所耗用的 RU,請考慮下列因素:
容量計算機可協助您練習調整 RU 的大小。
您也可以在 Azure Cosmos DB 中使用自動調整佈建輸送量,自動並立即調整您的資料庫或容器輸送量 (RU/秒)。 輸送量會根據使用量進行調整,而不會影響工作負載可用性、延遲、輸送量或效能。
資料散發
HBase HBase 會根據 RowKey 排序資料。 接著,資料會分割成數個區域並儲存在 RegionServers 中。 自動分割會根據資料分割原則,水平分割區域。 這是由指派給 HBase 參數 hbase.hregion.max.filesize 的值所控制 (預設值為 10 GB)。 HBase 中具有指定之 RowKey 的資料列一律屬於一個區域。 此外,每個資料行系列的資料在磁碟上是分開的。 如此可在讀取和隔離 HFile 上的 I/O 時進行篩選。
Azure Cosmos DB Azure Cosmos DB 會使用資料分割來調整資料庫中的個別容器。 資料分割會將容器中的項目分割成稱為「邏輯分割區」的特定子集。 邏輯分割區是根據與容器中每個項目相關聯的「分割區索引鍵」值而形成的。 邏輯分割區中的所有項目都有相同的分割區索引鍵值。 每個邏輯分割區最多可以容納 20 GB 的資料。
每個實體分割區都包含資料的複本,以及 Azure Cosmos DB 資料庫引擎的執行個體。 此結構可讓您的資料具持久性與高可用性,並在本機實體分割區中平均分配輸送量。 實體分割區會自動建立及設定,您無法控制其大小、位置,或它們包含哪些邏輯分割區。 實體分割區之間不會分割邏輯分割區。
如同 HBase RowKey,分割區索引鍵的設計對於 Azure Cosmos DB 很重要。 HBase 資料列索引鍵的運作方式是排序資料並儲存連續資料,而 Azure Cosmos DB 的分割區索引鍵則是不同的機制,因為其會雜湊散發資料。 假設使用 HBase 的應用程式已針對 HBase 的資料存取模式最佳化,則針對分割區索引鍵使用相同的 RowKey 將無法提供良好的效能結果。 由於其是在 HBase 上排序的資料,因此 Azure Cosmos DB 複合式索引可能很有用。 如果您想要在多個欄位中使用 ORDER BY 子句,則為必要項目。 您也可以透過定義複合式索引來提升許多相等和範圍查詢的效能。
可用性
HBase HBase 是由 Master、區域伺服器和 ZooKeeper 所組成。 單一叢集中的高可用性可以透過將每個元件設為備援來達成。 設定異地備援時,可以將 HBase 叢集部署到不同的實體資料中心,並使用複寫讓多個叢集保持同步。
Azure Cosmos DB Azure Cosmos DB 不需要任何設定,例如叢集元件備援。 其針對高可用性、一致性和延遲,提供全方位的 SLA。 如需詳細資料,請參閱 Azure Cosmos DB 的 SLA。
資料可靠性
HBase HBase 建置在 Hadoop 分散式檔案系統 (HDFS) 之上,且儲存在 HDFS 上的資料會複寫三次。
Azure Cosmos DB Azure Cosmos DB 主要以兩種方式提供高可用性。 首先,Azure Cosmos DB 會在 Azure Cosmos DB 帳戶內設定的區域之間複寫資料。 其次,Azure Cosmos DB 會在區域中保留四個資料複本。
移轉前的考量
系統相依性
這方面的規劃著重於了解 HBase 執行個體的上游和下游相依性,而且這些相依性會移轉至 Azure Cosmos DB。
下游相依性的範例可能是從 HBase 讀取資料的應用程式。 這些必須經過重構,才能從 Azure Cosmos DB 讀取。 移轉時,您必須考慮下列幾點:
用於評估相依性的問題 - 目前的 HBase 系統是否為獨立元件? 或者,其是否會呼叫位於另一個系統上的程序,或是其會由另一個系統上的程序呼叫,或是使用目錄服務存取? 其他重要程序是否在您的 HBase 叢集中運作? 您需要先釐清這些系統相依性,才能判斷移轉的影響。
HBase 部署在內部部署的 RPO 和 RTO。
離線和線上移轉
為成功移轉資料,請務必了解使用資料庫之企業的特性,並決定如何進行。 如果您可以完全關閉系統、執行資料移轉,然後在目的地重新啟動系統,請選擇離線移轉。 此外,如果您的資料庫一直處於忙碌狀態,而且您無法承受長時間中斷,請考慮線上移轉。
注意
此文件僅涵蓋離線移轉。
執行離線資料移轉時,其取決於您目前正在執行的 HBase 版本以及可用的工具。 如需詳細資訊,請參閱資料移轉一節。
效能考量
這方面的規劃是了解 HBase 的效能目標,然後將其轉譯成 Azure Cosmos DB 語法。 例如,若要在 HBase 上叫用 "X" IOPS,Azure Cosmos DB 需要多少要求單位 (RU/秒)。 HBase 與 Azure Cosmos DB 之間有一些差異,此練習的重點在於建立如何將 HBase 的效能目標轉換成 Azure Cosmos DB 的觀點。 這將會推動調整練習。
要詢問的問題:
- HBase 部署是大量讀取還是大量寫入?
- 讀取和寫入之間的區別為何?
- 目標 IOPS 表示為百分位數是多少?
- 如何使用哪些應用程式將資料載入 HBase?
- 如何使用哪些應用程式從 HBase 讀取資料?
執行要求已排序資料的查詢時,HBase 會快速傳回結果,因為資料是依 RowKey 排序。 不過,Azure Cosmos DB 沒有這種概念。 為將效能最佳化,您可以視需要使用複合式索引。
部署考量
您可以使用 Azure 入口網站或 Azure CLI 部署 Azure Cosmos DB for NoSQ。 由於移轉目的地是 Azure Cosmos DB for NoSQ,因此在部署時,請為 API 選取 [NoSQL] 作為參數。 此外,根據您的可用性需求,設定異地備援、多重區域寫入及可用性區域。
網路考量
Azure Cosmos DB 有三個主要的網路選項。 第一個設定使用公用 IP 位址,並透過 IP 防火牆控制存取 (預設)。 第二個設定使用公用 IP 位址,且一律僅允許從特定虛擬網路的特定子網路存取 (服務端點)。 第三個設定 (私人端點) 使用私人 IP 位址加入私人網路。
如需有關三個網路選項的詳細資訊,請參閱下列文件:
評估現有的資料
資料探索
從現有的 HBase 叢集預先收集資訊,以識別您想要移轉的資料。 這些可以協助您確定移轉方式、決定要移轉的資料表、了解這些資料表內的結構,以及決定建置資料模型的方式。 例如,收集詳細資料,如下所示:
- HBase 版本
- 移轉目標資料表
- 資料行系列資訊
- 資料表狀態
下列命令示範如何使用 hbase shell 指令碼收集上述詳細資料,並將其儲存在作業電腦的本機檔案系統中。
取得 HBase 版本
hbase version -n > hbase-version.txt
輸出:
cat hbase-version.txt
HBase 2.1.8.4.1.2.5
取得資料表清單
您可以取得儲存在 HBase 中資料表的清單。 如果您已建立非預設的命名空間,則會以「命名空間: 資料表」格式輸出。
echo "list" | hbase shell -n > table-list.txt
HBase 2.1.8.4.1.2.5
輸出:
echo "list" | hbase shell -n > table-list.txt
cat table-list.txt
TABLE
COMPANY
Contacts
ns1:t1
3 row(s)
Took 0.4261 seconds
COMPANY
Contacts
ns1:t1
識別要移轉的資料表
透過指定要移轉的資料表名稱,取得資料表中資料行系列的詳細資料。
echo "describe '({Namespace}:){Table name}'" | hbase shell -n > {Table name} -schema.txt
輸出:
cat {Table name} -schema.txt
Table {Table name} is ENABLED
{Table name}
COLUMN FAMILIES DESCRIPTION
{NAME => 'cf1', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
{NAME => 'cf2', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
2 row(s)
Took 0.5775 seconds
取得資料表中的資料行系列及其設定
echo "status 'detailed'" | hbase shell -n > hbase-status.txt
輸出:
{HBase version}
0 regionsInTransition
active master: {Server:Port number}
2 backup masters
{Server:Port number}
{Server:Port number}
master coprocessors: []
# live servers
{Server:Port number}
requestsPerSecond=0.0, numberOfOnlineRegions=44, usedHeapMB=1420, maxHeapMB=15680, numberOfStores=49, numberOfStorefiles=14, storefileUncompressedSizeMB=7, storefileSizeMB=7, compressionRatio=1.0000, memstoreSizeMB=0, storefileIndexSizeKB=15, readRequestsCount=36210, filteredReadRequestsCount=415729, writeRequestsCount=439, rootIndexSizeKB=15, totalStaticIndexSizeKB=5, totalStaticBloomSizeKB=16, totalCompactingKVs=464, currentCompactedKVs=464, compactionProgressPct=1.0, coprocessors=[GroupedAggregateRegionObserver, Indexer, MetaDataEndpointImpl, MetaDataRegionObserver, MultiRowMutationEndpoint, ScanRegionObserver, SecureBulkLoadEndpoint, SequenceRegionObserver, ServerCachingEndpointImpl, UngroupedAggregateRegionObserver]
[...]
"Contacts,,1611126188216.14a597a0964383a3d923b2613524e0bd."
numberOfStores=2, numberOfStorefiles=2, storefileUncompressedSizeMB=7168, lastMajorCompactionTimestamp=0, storefileSizeMB=7, compressionRatio=0.0010, memstoreSizeMB=0, readRequestsCount=4393, writeRequestsCount=0, rootIndexSizeKB=14, totalStaticIndexSizeKB=5, totalStaticBloomSizeKB=16, totalCompactingKVs=0, currentCompactedKVs=0, compactionProgressPct=NaN, completeSequenceId=-1, dataLocality=0.0
[...]
您可以取得有用的調整大小資訊,例如堆積記憶體的大小、區域數目、要當作叢集狀態的要求數目,以及壓縮/未壓縮的資料大小作為資料表狀態。
如果您要在 HBase 叢集上使用 Apache Phoenix,則也需要從 Phoenix 收集資料。
- 移轉目標資料表
- 資料表結構描述
- 索引數
- 主要金鑰
在您的叢集上連線至 Apache Phoenix
sqlline.py ZOOKEEPER/hbase-unsecure
取得資料表清單
!tables
取得資料表詳細資料
!describe <Table Name>
取得索引詳細資料
!indexes <Table Name>
取得主要索引鍵詳細資料
!primarykeys <Table Name>
移轉資料
移轉選項
有各種方法可以離線移轉資料,但在此我們將介紹如何使用 Azure Data Factory。
| 解決方案 | 來源版本 | 考量 |
|---|---|---|
| Azure Data Factory | HBase < 2 | 容易設定。 適合大型資料集。 不支援 HBase 2 或更新版本。 |
| Apache Spark | 所有版本 | 支援所有版本的 HBase。 適合大型資料集。 需要設定 Spark。 |
| 具有 Azure Cosmos DB 大量執行工具程式庫的自訂工具 | 所有版本 | 在使用程式庫建立自訂資料移轉工具上最有彈性的選擇。 需要投入更多精力來設定。 |
下列流程圖會使用一些條件來達到可用的資料移轉方法。
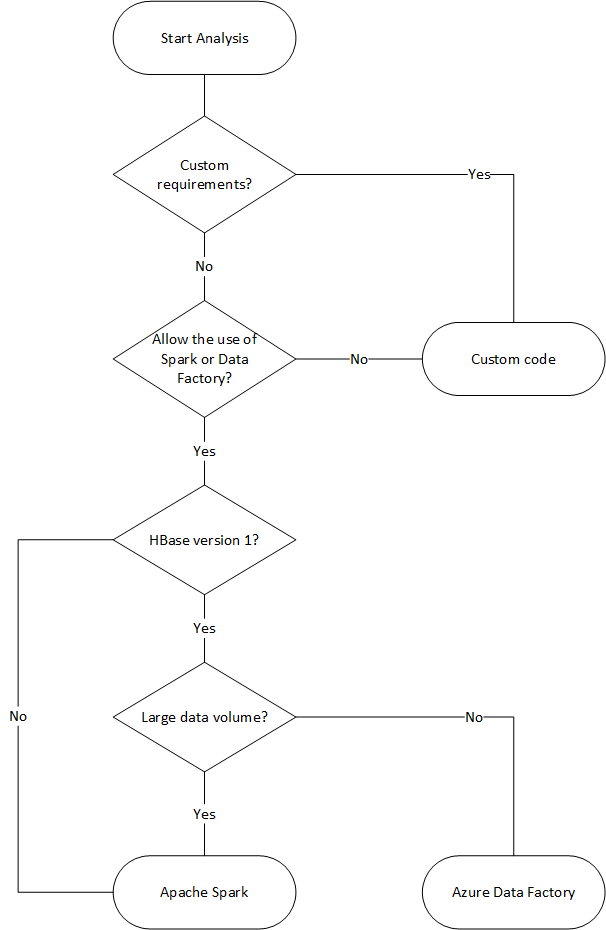
使用 Data Factory 移轉
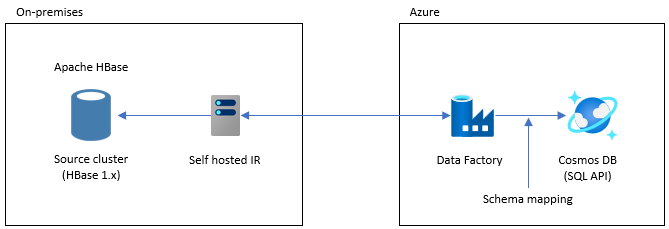
此選項適用於大型資料集。 使用 Azure Cosmos DB 大量執行工具程式庫。 沒有檢查點,因此,如果您在移轉期間遇到任何問題,就必須從頭開始重新啟動移轉程序。 您也可以使用 Data Factory 的自我裝載整合執行階段連線至內部部署 HBase,或將 Data Factory 部署至受控 VNET,然後透過 VPN 或 ExpressRoute 連線到內部部署網路。
Data Factory 的複製活動支援 HBase 作為資料來源。 如需詳細資訊,請參閱使用 Azure Data Factory 從 HBase 複製資料一文。
您可指定 Azure Cosmos DB (API for NoSQL) 作為資料的目的地。 如需詳細資訊,請參閱使用 Azure Data Factory 來複製和轉換 Azure Cosmos DB (API for NoSQL) 中的資料一文。
使用 Apache Spark 移轉 - Apache HBase 連接器和 Azure Cosmos DB Spark 連接器
以下是將您的資料移轉至 Azure Cosmos DB 的範例。 其假設 HBase 2.1.0 和 Spark 2.4.0 正在相同的叢集中執行。
Apache Spark - Apache HBase 連接器存放庫可在 Apache Spark - Apache HBase 連接器上找到
針對 Azure Cosmos DB Spark 連接器,請參閱快速入門手冊,並下載適用於您 Spark 版本的程式庫。
將 hbase-site.xml 複製到您的 Spark 設定目錄。
cp /etc/hbase/conf/hbase-site.xml /etc/spark2/conf/使用 Spark HBase 連接器和 Azure Cosmos DB Spark 連接器執行 spark -shell。
spark-shell --packages com.hortonworks.shc:shc-core:1.1.0.3.1.2.2-1 --repositories http://repo.hortonworcontent/groups/public/ --jars azure-cosmosdb-spark_2.4.0_2.11-3.6.8-uber.jarSpark 殼層啟動之後,請執行 Scala 程式碼,如下所示。 匯入從 HBase 載入資料所需的程式庫。
// Import libraries import org.apache.spark.sql.{SQLContext, _} import org.apache.spark.sql.execution.datasources.hbase._ import org.apache.spark.{SparkConf, SparkContext} import spark.sqlContext.implicits._針對 HBase 資料表定義 Spark 目錄結構描述。 在此命名空間為 "default",資料表名稱為 "Contacts"。 會將資料列索引鍵指定為索引鍵。 資料行、資料行系列和資料行都會對應至 Spark 的目錄。
// define a catalog for the Contacts table you created in HBase def catalog = s"""{ |"table":{"namespace":"default", "name":"Contacts"}, |"rowkey":"key", |"columns":{ |"rowkey":{"cf":"rowkey", "col":"key", "type":"string"}, |"officeAddress":{"cf":"Office", "col":"Address", "type":"string"}, |"officePhone":{"cf":"Office", "col":"Phone", "type":"string"}, |"personalName":{"cf":"Personal", "col":"Name", "type":"string"}, |"personalPhone":{"cf":"Personal", "col":"Phone", "type":"string"} |} |}""".stripMargin接下來,定義方法,以便從 HBase Contacts 資料表取得資料作為資料框架。
def withCatalog(cat: String): DataFrame = { spark.sqlContext .read .options(Map(HBaseTableCatalog.tableCatalog->cat)) .format("org.apache.spark.sql.execution.datasources.hbase") .load() }使用已定義的方法建立資料框架。
val df = withCatalog(catalog)接著,匯入使用 Azure Cosmos DB Spark 連接器所需的程式庫。
import com.microsoft.azure.cosmosdb.spark.schema._ import com.microsoft.azure.cosmosdb.spark._ import com.microsoft.azure.cosmosdb.spark.config.Config設定將資料寫入 Azure Cosmos DB。
val writeConfig = Config(Map( "Endpoint" -> "https://<cosmos-db-account-name>.documents.azure.com:443/", "Masterkey" -> "<comsmos-db-master-key>", "Database" -> "<database-name>", "Collection" -> "<collection-name>", "Upsert" -> "true" ))將資料框架資料寫入 Azure Cosmos DB。
import org.apache.spark.sql.SaveMode df.write.mode(SaveMode.Overwrite).cosmosDB(writeConfig)
其會以高速平行寫入,且其效能很高。 另一方面,請注意,其可能會耗用 Azure Cosmos DB 端的每秒 RU 數目。
Phoenix
支援 Phoenix 作為 Data Factory 資料來源。 如需詳細步驟,請參閱下列文件。
移轉程式碼
此節描述在 Azure Cosmos DB for NoSQL 和 HBase 中建立應用程式之間的差異。 此處的範例使用 Apache HBase 2.x API 和 Azure Cosmos DB Java SDK v4。
這些 HBase 的範例程式碼是以 HBase 官方文件中所述的程式碼為基礎。
此處呈現的 Azure Cosmos DB 程式碼是以 Azure Cosmos DB for NoSQL:Java SDK v4 範例文件為基礎。 您可以從文件中存取完整的程式碼範例。
程式碼移轉的對應會顯示在此處,但這些範例中使用的 HBase RowKey 和 Azure Cosmos DB 分割區索引鍵不一定經過妥善設計。 根據移轉來源的實際資料模型設計。
建立連線
HBase
Configuration config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum","zookeepernode0,zookeepernode1,zookeepernode2");
config.set("hbase.zookeeper.property.clientPort", "2181");
config.set("hbase.cluster.distributed", "true");
Connection connection = ConnectionFactory.createConnection(config)
Phoenix
//Use JDBC to get a connection to an HBase cluster
Connection conn = DriverManager.getConnection("jdbc:phoenix:server1,server2:3333",props);
Azure Cosmos DB
// Create sync client
client = new CosmosClientBuilder()
.endpoint(AccountSettings.HOST)
.key(AccountSettings.MASTER_KEY)
.consistencyLevel(ConsistencyLevel.{ConsistencyLevel})
.contentResponseOnWriteEnabled(true)
.buildClient();
建立資料庫/資料表/集合
HBase
// create an admin object using the config
HBaseAdmin admin = new HBaseAdmin(config);
// create the table...
HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf("FamilyTable"));
// ... with single column families
tableDescriptor.addFamily(new HColumnDescriptor("ColFam"));
admin.createTable(tableDescriptor);
Phoenix
CREATE IF NOT EXISTS FamilyTable ("id" BIGINT not null primary key, "ColFam"."lastName" VARCHAR(50));
Azure Cosmos DB
// Create database if not exists
CosmosDatabaseResponse databaseResponse = client.createDatabaseIfNotExists(databaseName);
database = client.getDatabase(databaseResponse.getProperties().getId());
// Create container if not exists
CosmosContainerProperties containerProperties = new CosmosContainerProperties("FamilyContainer", "/lastName");
// Provision throughput
ThroughputProperties throughputProperties = ThroughputProperties.createManualThroughput(400);
// Create container with 400 RU/s
CosmosContainerResponse databaseResponse = database.createContainerIfNotExists(containerProperties, throughputProperties);
container = database.getContainer(databaseResponse.getProperties().getId());
建立資料列/文件
HBase
HTable table = new HTable(config, "FamilyTable");
Put put = new Put(Bytes.toBytes(RowKey));
put.add(Bytes.toBytes("ColFam"), Bytes.toBytes("id"), Bytes.toBytes("1"));
put.add(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"), Bytes.toBytes("Witherspoon"));
table.put(put)
Phoenix
UPSERT INTO FamilyTable (id, lastName) VALUES (1, ‘Witherspoon’);
Azure Cosmos DB
Azure Cosmos DB 會透過資料模型提供類型安全。 我們使用名為 'Family' 的資料模型。
public class Family {
public Family() {
}
public void setId(String id) {
this.id = id;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
private String id="";
private String lastName="";
}
以上是程式碼的一部分。 請參閱完整的程式碼範例。
使用 [系列] 類別來定義文件並插入項目。
Family family = new Family();
family.setLastName("Witherspoon");
family.setId("1");
// Insert this item as a document
// Explicitly specifying the /pk value improves performance.
container.createItem(family,new PartitionKey(family.getLastName()),new CosmosItemRequestOptions());
讀取資料列/文件
HBase
HTable table = new HTable(config, "FamilyTable");
Get get = new Get(Bytes.toBytes(RowKey));
get.addColumn(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"));
Result result = table.get(get);
byte[] col = result.getValue(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"));
Phoenix
SELECT lastName FROM FamilyTable;
Azure Cosmos DB
// Read document by ID
Family family = container.readItem(documentId,new PartitionKey(documentLastName),Family.class).getItem();
String sql = "SELECT lastName FROM c";
CosmosPagedIterable<Family> filteredFamilies = container.queryItems(sql, new CosmosQueryRequestOptions(), Family.class);
更新資料
HBase
針對 HBase,請使用 append 方法和 checkAndPut 方法來更新值。 append 是以不可部分完成的方式將值附加至目前值結尾的程序,而 checkAndPut 會以不可部分完成的方式將目前的值與預期的值進行比較,並只在相符時進行更新。
// append
HTable table = new HTable(config, "FamilyTable");
Append append = new Append(Bytes.toBytes(RowKey));
Append.add(Bytes.toBytes("ColFam"), Bytes.toBytes("id"), Bytes.toBytes(2));
Append.add(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"), Bytes.toBytes("Harris"));
Result result = table.append(append)
// checkAndPut
byte[] row = Bytes.toBytes(RowKey);
byte[] colfam = Bytes.toBytes("ColFam");
byte[] col = Bytes.toBytes("lastName");
Put put = new Put(row);
put.add(colfam, col, Bytes.toBytes("Patrick"));
boolearn result = table.checkAndPut(row, colfam, col, Bytes.toBytes("Witherspoon"), put);
Phoenix
UPSERT INTO FamilyTable (id, lastName) VALUES (1, ‘Brown’)
ON DUPLICATE KEY UPDATE id = "1", lastName = "Whiterspoon";
Azure Cosmos DB
在 Azure Cosmos DB 中,會將更新視為 Upsert 作業。 也就是說,如果文件不存在,則會將其插入。
// Replace existing document with new modified document (contingent on modification).
Family family = new Family();
family.setLastName("Brown");
family.setId("1");
CosmosItemResponse<Family> famResp = container.upsertItem(family, new CosmosItemRequestOptions());
刪除資料列/文件
HBase
在 Hbase 中,沒有依值選取資料列的直接刪除方式。 您可能已搭配 ValueFilter 等來實作刪除程序。在此範例中,要刪除的資料列是由 RowKey 所指定。
HTable table = new HTable(config, "FamilyTable");
Delete delete = new Delete(Bytes.toBytes(RowKey));
delete.deleteColumn(Bytes.toBytes("ColFam"), Bytes.toBytes("id"));
delete.deleteColumn(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"));
table.dalate(delete)
Phoenix
DELETE FROM TableName WHERE id = "xxx";
Azure Cosmos DB
依文件識別碼的刪除方法如下所示。
container.deleteItem(documentId, new PartitionKey(documentLastName), new CosmosItemRequestOptions());
查詢資料列/文件
HBase HBase 可讓您使用掃描擷取多個資料列。 您可以使用篩選來指定詳細的掃描條件。 如需了解 HBase 內建篩選類型,請參閱用戶端要求篩選。
HTable table = new HTable(config, "FamilyTable");
Scan scan = new Scan();
SingleColumnValueFilter filter = new SingleColumnValueFilter(Bytes.toBytes("ColFam"),
Bytes.toBytes("lastName"), CompareOp.EQUAL, New BinaryComparator(Bytes.toBytes("Witherspoon")));
filter.setFilterIfMissing(true);
filter.setLatestVersionOnly(true);
scan.setFilter(filter);
ResultScanner scanner = table.getScanner(scan);
Phoenix
SELECT * FROM FamilyTable WHERE lastName = "Witherspoon"
Azure Cosmos DB
篩選作業
String sql = "SELECT * FROM c WHERE c.lastName = 'Witherspoon'";
CosmosPagedIterable<Family> filteredFamilies = container.queryItems(sql, new CosmosQueryRequestOptions(), Family.class);
刪除資料表/集合
HBase
HBaseAdmin admin = new HBaseAdmin(config);
admin.deleteTable("FamilyTable")
Phoenix
DROP TABLE IF EXISTS FamilyTable;
Azure Cosmos DB
CosmosContainerResponse containerResp = database.getContainer("FamilyContainer").delete(new CosmosContainerRequestOptions());
其他考量
HBase 叢集可搭配 HBase 工作負載和 MapReduce、Hive、Spark 等使用。 如果您目前的 HBase 有其他工作負載,則也需要移轉這些工作負載。 如需詳細資訊,請參閱各個移轉指南。
- MapReduce
- hbase
- Spark
伺服器端程式設計
HBase 提供數個伺服器端程式設計功能。 如果您要使用這些功能,則也需要移轉其處理。
HBase
-
HBase 中預設會提供各種篩選,但您也可以實作自己的自訂篩選。 如果 HBase 上預設提供的篩選不符合您的需求,可以實作自訂篩選。
-
副處理器是一種架構,可讓您在區域伺服器上執行自己的程式碼。 使用副處理器可以執行在伺服器端的用戶端上執行的處理,而且視處理的不同,這樣做可能會更有效率。 副處理器有兩種類型,分別是觀察者和端點。
觀察者
- 觀察者會攔截特定的作業和事件。 這是用於新增任意處理的函式。 此功能類似於 RDBMS 觸發程序。
端點
- 端點是用於擴充 HBase RPC 的功能。 這是與 RDBMS 預存程序類似的函數。
Azure Cosmos DB
-
- Azure Cosmos DB 預存程序是以 JavaScript 撰寫,而且可以執行建立、更新、讀取、查詢和刪除 Azure Cosmos DB 容器中的項目等作業。
-
- 您可以針對資料庫上的作業指定觸發程序。 提供的方法有兩種:在資料庫項目變更之前執行的預先觸發程序,以及在資料庫項目變更之後執行的後續觸發程序。
-
- Azure Cosmos DB 可讓您定義使用者定義的函式 (UDF)。 UDF 也可以使用 JavaScript 撰寫。
預存程序和觸發程序都會根據所執行作業的複雜度耗用 RU。 開發伺服器端處理時,請檢查所需的使用方式,以進一步了解每個作業所耗用的 RU 量。 如需詳細資料,請參閱 Azure Cosmos DB 中的要求單位和將 Azure Cosmos DB 中的要求成本最佳化。
伺服器端程式設計對應
| hbase | Azure Cosmos DB | 描述 |
|---|---|---|
| 自訂篩選 | WHERE 子句 | 如果 Azure Cosmos DB 中的 WHERE 子句無法達成自訂篩選所實作的處理,請搭配 UDF 使用。 |
| 副處理器 (觀察者) | 觸發程序 | 觀察者是在特定事件之前和之後執行的觸發程序。 如同觀察者支援預先和後續呼叫,Azure Cosmos DB 的觸發程序也支援預先和後續觸發程序。 |
| 副處理器 (端點) | 預存程序 | 端點是針對每個區域執行的伺服器端資料處理機制。 這類似於 RDBMS 預存程序。 Azure Cosmos DB 預存程序是使用 JavaScript 撰寫的。 其可存取您可以透過預存程序在 Azure Cosmos DB 上執行的所有作業。 |
注意
根據在 HBase 上實作的處理,Azure Cosmos DB 可能需要不同的對應和實作。
安全性
資料安全性是客戶和資料庫提供者的共同責任。 針對內部部署解決方案,客戶必須提供從端點保護到實體硬體安全性的所有項目,這不是一個簡單的工作。 如果您選擇 PaaS 雲端資料庫提供者 (例如 Azure Cosmos DB),將會減少客戶介入。 Azure Cosmos DB 會在 Azure 平台上執行,因此可以使用與 HBase 不同的方式來增強。 Azure Cosmos DB 不需要安裝任何額外的元件即可確保安全性。 建議您考慮使用下列檢查清單來移轉您的資料庫系統安全性實作:
| 安全性控制 | HBase | Azure Cosmos DB |
|---|---|---|
| 網路安全性和防火牆設定 | 使用網路裝置等安全性功能來控制流量。 | 在輸入防火牆上支援以原則為基礎的 IP 型存取控制。 |
| 使用者驗證和細微的使用者控制 | 將 LDAP 與安全性元件 (例如 Apache Ranger) 結合在一起,以提供細微的存取控制。 | 您可以使用帳戶主要金鑰來建立每個資料庫的使用者和權限資源。 資源權杖會與資料庫中的權限相關聯,以決定使用者如何存取資料庫中的應用程式資源 (讀取/寫入、唯讀或無存取)。 您也可以使用 Microsoft Entra ID 來驗證您的資料要求。 這可讓您使用細微的 RBAC 模型來授權資料要求。 |
| 能夠將資料複寫到世界各地以防區域性失敗 | 使用 HBase 的複寫功能,在遠端資料中心製作資料庫複本。 | Azure Cosmos DB 可執行免設定的全球發佈,並可讓您在 Azure 中使用選取按鈕,將資料複寫到世界各地的資料中心。 就安全性而言,全域複寫可確保您的資料受到保護,不受本機失敗的影響。 |
| 從一個資料中心容錯移轉至另一個資料中心的能力 | 您必須自行實作容錯移轉。 | 如果您要將資料複寫到多個資料中心,且區域的資料中心離線,Azure Cosmos DB 就會自動變換作業。 |
| 在資料中心內的區域資料複寫 | HDFS 機制可讓您在單一檔案系統內跨節點擁有多個複本。 | Azure Cosmos DB 會自動複寫資料來維持高可用性,即使在單一資料中心內也一樣。 您可以自行選擇一致性層級。 |
| 自動資料備份 | 沒有自動備份功能。 您必須自行實作資料備份。 | 系統會定期備份 Azure Cosmos DB,並將其儲存在異地備援存放裝置中。 |
| 保護並隔離敏感性資料 | 例如,如果您要使用 Apache Ranger,則可以使用 Ranger 原則以將原則套用至資料表。 | 您可以將個人和其他敏感性資料分別放在特定的容器中並進行讀取/寫入,或限制特定使用者的唯讀存取權。 |
| 監視攻擊 | 必須使用協力廠商產品加以實作。 | 您可以使用稽核記錄和活動記錄,以監視帳戶的正常和異常活動。 |
| 回應攻擊 | 必須使用協力廠商產品加以實作。 | 當您連絡 Azure 支援並回報潛在的攻擊時,會開始五個步驟的事件回應程序。 |
| 能夠異地隔離資料以遵守資料控管限制 | 您需要檢查每個國家/地區的限制,並自行實作。 | 保證適用於主權區域 (德國、中國、美國政府等) 的資料治理。 |
| 實際保護受保護資料中心內的伺服器 | 這取決於系統所在的資料中心。 | 如需最新認證的清單,請參閱全球 Azure 合規性網站。 |
| 認證 | 取決於 Hadoop 散發。 | 請參閱 Azure 合規性文件 |
如需有關安全性的詳細資訊,請參閱 Azure Cosmos DB 的安全性 - 概觀
監視
HBase 通常會使用叢集計量 Web UI 或使用 Ambari、Cloudera Manager 或其他監視工具來監視叢集。 Azure Cosmos DB 可讓您使用 Azure 平台內建的監視機制。 如需有關 Azure Cosmos DB 監視的詳細資訊,請參閱監視 Azure Cosmos DB。
如果您的環境實作 HBase 系統監視以傳送警示 (例如,透過電子郵件),您可以將其取代為 Azure 監視器警示。 您可以根據 Azure Cosmos DB 帳戶的計量或活動記錄事件來接收警示。
如需有關 Azure 監視器中警示的詳細資訊,請參閱使用 Azure 監視器建立 Azure Cosmos DB 的警示
此外,請參閱 Azure 監視器可以收集的 Azure Cosmos DB 計量和記錄類型。
備份和災害復原
Backup
有幾種方式可以取得 HBase 的備份。 例如,快照集、匯出、CopyTable、HDFS 資料的離線備份,以及其他自訂備份。
Azure Cosmos DB 會自動定期備份資料,而不會影響資料庫作業的效能或可用性。 備份會儲存在 Azure 儲存體中,並可在需要時用來復原資料。 Azure Cosmos DB 備份有兩種類型:
災害復原
HBase 是容錯分散式系統,但是在資料中心層級失敗的情況下,備份位置需要容錯移轉時,您必須使用快照集、複寫等等來實作災害復原。 您可以使用下列三種複寫模型來設定 HBase 複寫:領導者/追隨者、領導者/領導者和循環。 如果來源 HBase 實作災害復原,您需要了解如何在 Azure Cosmos DB 中設定災害復原,並符合您的系統需求。
Azure Cosmos DB 是一種全域分散式資料庫,其中包含內建的災害復原功能。 您可以將 DB 資料複寫到任何 Azure 區域。 Azure Cosmos DB 可讓您的資料庫在某些區域發生故障時保持高可用性。
萬一某個區域發生故障,僅使用單一區域的 Azure Cosmos DB 帳戶可能會無法使用。 建議您至少設定兩個區域,以確保一律具有高可用性。 您也可以將 Azure Cosmos DB 帳戶設定為跨越至少兩個具有多個寫入區域的區域,以確保寫入和讀取的高可用性。 對於包含多個寫入區域的多區域帳戶,Azure Cosmos DB 用戶端會偵測到區域間的容錯移轉,並進行處理。 這些都是暫時的,不需要應用程式進行任何變更。 如此一來,您就可以達到可用性設定,其中包括適用於 Azure Cosmos DB 的災害復原。 如先前所提及,您可以使用三種模型來設定 HBase 複寫,但是透過設定單一寫入和多重寫入區域,可以使用以 SLA 為基礎的可用性設定 Azure Cosmos DB。
如需有關高可用性的詳細資訊,請參閱 Azure Cosmos DB 如何提供高可用性
常見問題集
為什麼要移轉至 API for NoSQL,而不是 Azure Cosmos DB 中的其他 API?
API for NoSQL 在介面、服務 SDK 用戶端程式庫方面提供最佳的端對端體驗。 Azure Cosmos DB 推出的新功能將會先在您的 API for NoSQL 帳戶中提供。 此外,API for NoSQL 支援分析,並在生產和分析工作負載之間提供不同的效能。 如果您想要使用現代化技術來建置應用程式,建議使用 API for NoSQL。
我是否可以將 HBase RowKey 指派給 Azure Cosmos DB 分割區索引鍵?
其可能不會按原樣進行最佳化。 在 HBase 中,資料會依指定的 RowKey 排序、儲存在區域中,並分成固定的大小。 這與 Azure Cosmos DB 中的資料分割運作方式不同。 因此,您必須重新設計索引鍵,以便根據工作負載的特性,更妥善地散發資料。 如需詳細資訊,請參閱散發一節。
資料是依 HBase 中的 RowKey 排序,但是在 Azure Cosmos DB 中是依索引鍵進行分割。 Azure Cosmos DB 如何達成排序和共置?
在 Azure Cosmos DB 中,您可以新增複合式索引,以遞增或遞減順序將資料排序,以提升相等和範圍查詢的效能。 請參閱散發一節和產品文件中的複合式索引。
分析處理是使用 Hive 或 Spark 在 HBase 資料上執行的。 我要如何在 Azure Cosmos DB 中將其現代化?
您可以使用 Azure Cosmos DB 分析存放區,將操作資料自動同步處理至另一個資料行存放區。 資料行存放區格式適用於以最佳化方式執行的大型分析查詢,可改善此類查詢的延遲。 Azure Synapse Link 可讓您直接從 Azure Synapse Analytics 連結至 Azure Cosmos DB 分析存放區,以建置無 ETL 的 HTAP 解決方案。 這可讓您執行大規模、近乎即時的操作資料分析。 Synapse Analytics 支援 Azure Cosmos DB 分析存放區中的 Apache Spark 和無伺服器 SQL 集區。 您可以利用此功能來移轉分析處理。 如需詳細資訊,請參閱分析存放區。
使用者如何在 HBase 中對 Azure Cosmos DB 使用時間戳記查詢?
Azure Cosmos DB 沒有與 HBase 完全相同的時間戳記版本設定功能。 但 Azure Cosmos DB 提供存取變更摘要的功能,而您可以利用該功能進行版本設定。
將每個版本/變更儲存為個別項目。
讀取變更摘要以合併/彙總變更,並使用 "_ts" 欄位進行篩選,以觸發適當的下游動作。 此外,針對舊版本的資料,您可以使用 TTL 讓舊版本過期。
下一步
若要執行效能測試,請參閱 Azure Cosmos DB 的效能和規模測試一文。
若要將程式碼最佳化,請參閱 Azure Cosmos DB 的效能祕訣一文。
探索 JAVA Async V3 SDK,SDK 參考 GitHub 存放庫。