Azure Data Lake Storage 是一款高度可擴展且具成本效益的大數據湖分析解決方案。 它結合了高效能文件系統的強大功能與大規模和經濟性,以協助您縮短深入解析的時間。 Data Lake Storage Gen2 擴充了 Azure Blob 儲存體 的功能,並針對分析工作負載進行優化。
Azure Data Explorer 與 Azure Blob 儲存體 及 Azure Data Lake Storage(Gen1 和 Gen2)整合,提供快速、快取且索引化的外部儲存資料存取。 你可以在不事先將資料導入 Azure Data Explorer 的情況下分析和查詢資料。 您也可以同時查詢內嵌和未擷取的外部數據。 欲了解更多資訊,請參閱如何使用Azure Data Explorer網頁介面嚮導
提示
最佳的查詢效能需要資料擷取到 Azure Data Explorer。 在未預先擷取的情況下查詢外部數據的功能,只能用於很少查詢的歷史數據或數據。 優化外部數據查詢效能 ,以獲得最佳結果。
建立外部表格
假設您有許多 CSV 檔案,其中包含儲存在倉儲中之產品的歷程記錄資訊,而且您想要進行快速分析,以尋找去年最受歡迎的五種產品。 在此範例中,CSV 檔案看起來如下:
| 時間戳記 | ProductId | 產品描述 |
|---|---|---|
| 2019-01-01 11:21:00 | TO6050 | 3.5in DS/HD 軟盤 |
| 2019-01-01 11:30:55 | YDX1 | Yamaha DX1 合成器 |
| ... | ... | ... |
檔案儲存在 Azure Blob 儲存空間mycompanystorage,並以一個名為 archivedproducts 的容器下儲存,並依日期分割:
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00000-7e967c99-cf2b-4dbb-8c53-ce388389470d.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00001-ba356fa4-f85f-430a-8b5a-afd64f128ca4.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00002-acb644dc-2fc6-467c-ab80-d1590b23fc31.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00003-cd5fad16-a45e-4f8c-a2d0-5ea5de2f4e02.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/02/part-00000-ffc72d50-ff98-423c-913b-75482ba9ec86.csv.gz
...
若要直接對這些 CSV 檔案執行 KQL 查詢,請使用 .create external table 指令在 Azure Data Explorer 中定義外部資料表。 如需外部數據表建立命令選項的詳細資訊,請參閱 外部數據表命令。
.create external table ArchivedProducts(Timestamp:datetime, ProductId:string, ProductDescription:string)
kind=blob
partition by (Date:datetime = bin(Timestamp, 1d))
dataformat=csv
(
h@'https://mycompanystorage.blob.core.windows.net/archivedproducts;StorageSecretKey'
)
外部表格現在已在 Azure Data Explorer 網頁介面的左側窗格中可見:
外部數據表許可權
查看下表權限
- 資料庫使用者可以建立外部數據表。 數據表建立者會自動成為數據表管理員。
- 叢集、資料庫或數據表管理員可以編輯現有的數據表。
- 任何資料庫用戶或讀取器都可以查詢外部數據表。
查詢外部數據表
定義外部數據表之後, external_table() 即可使用 函式來參考它。 其餘查詢是標準 Kusto 查詢語言。
external_table("ArchivedProducts")
| where Timestamp > ago(365d)
| summarize Count=count() by ProductId,
| top 5 by Count
一起查詢外部和已匯入的資料
您可以在相同查詢查詢中查詢外部資料表和內嵌的資料表。 你可以對外部資料表執行 join 或 union,並將其與 Azure Data Explorer、SQL 伺服器或其他來源的資料結合。 使用 let( ) statement 為外部數據表參考指派速記名稱。
在下列範例中, Products 是內嵌的數據表, ArchivedProducts 是我們定義的外部數據表:
let T1 = external_table("ArchivedProducts") | where TimeStamp > ago(100d);
let T = Products; //T is an internal table
T1 | join T on ProductId | take 10
查詢階層式數據格式
Azure Data Explorer 允許查詢階層格式,例如 JSON、Parquet、Avro 以及 ORC。 若要將階層式數據架構對應至外部數據表架構(如果不同),請使用 外部數據表對應命令。 例如,如果您想要以下列格式查詢 JSON 記錄檔:
{
"timestamp": "2019-01-01 10:00:00.238521",
"data": {
"tenant": "aaaabbbb-0000-cccc-1111-dddd2222eeee",
"method": "RefreshTableMetadata"
}
}
{
"timestamp": "2019-01-01 10:00:01.845423",
"data": {
"tenant": "bbbbcccc-1111-dddd-2222-eeee3333ffff",
"method": "GetFileList"
}
}
...
外部資料表定義看起來像這樣:
.create external table ApiCalls(Timestamp: datetime, TenantId: guid, MethodName: string)
kind=blob
dataformat=multijson
(
h@'https://storageaccount.blob.core.windows.net/container1;StorageSecretKey'
)
定義 JSON 對應,將資料欄位對應至外部資料表定義欄位:
.create external table ApiCalls json mapping 'MyMapping' '[{"Column":"Timestamp","Properties":{"Path":"$.timestamp"}},{"Column":"TenantId","Properties":{"Path":"$.data.tenant"}},{"Column":"MethodName","Properties":{"Path":"$.data.method"}}]'
當您查詢外部資料表時,會調用映射,將相關資料映射到外部表的欄位:
external_table('ApiCalls') | take 10
如需對應語法的詳細資訊,請參閱 數據對應。
查詢 說明叢集中的TaxiRides 外部數據表
使用名為 help 的測試叢集來嘗試不同的Azure Data Explorer功能。 幫助叢集包含紐約市計程車數據集的外部資料表定義,其中包含數十億次計程車行程。
建立外部數據表 TaxiRides
這裡顯示的是用於在help叢集中建立TaxiRides外部表的查詢。 由於您已建立此數據表,因此您可以略過本節,並直接查詢 TaxiRides 外部數據表數據。
.create external table TaxiRides
(
trip_id: long,
vendor_id: string,
pickup_datetime: datetime,
dropoff_datetime: datetime,
store_and_fwd_flag: string,
rate_code_id: int,
pickup_longitude: real,
pickup_latitude: real,
dropoff_longitude: real,
dropoff_latitude: real,
passenger_count: int,
trip_distance: real,
fare_amount: real,
extra: real,
mta_tax: real,
tip_amount: real,
tolls_amount: real,
ehail_fee: real,
improvement_surcharge: real,
total_amount: real,
payment_type: string,
trip_type: int,
pickup: string,
dropoff: string,
cab_type: string,
precipitation: int,
snow_depth: int,
snowfall: int,
max_temperature: int,
min_temperature: int,
average_wind_speed: int,
pickup_nyct2010_gid: int,
pickup_ctlabel: string,
pickup_borocode: int,
pickup_boroname: string,
pickup_ct2010: string,
pickup_boroct2010: string,
pickup_cdeligibil: string,
pickup_ntacode: string,
pickup_ntaname: string,
pickup_puma: string,
dropoff_nyct2010_gid: int,
dropoff_ctlabel: string,
dropoff_borocode: int,
dropoff_boroname: string,
dropoff_ct2010: string,
dropoff_boroct2010: string,
dropoff_cdeligibil: string,
dropoff_ntacode: string,
dropoff_ntaname: string,
dropoff_puma: string
)
kind=blob
partition by (Date:datetime = bin(pickup_datetime, 1d))
dataformat=csv
(
h@'https://storageaccount.blob.core.windows.net/container1;secretKey'
)
你可以在Azure Data Explorer網頁介面的左側窗格找到已建立的 TaxiRides 表格。
查詢 TaxiRides 外部資料表數據
登入 https://dataexplorer.azure.com/clusters/help/databases/Samples。
查詢 TaxiRides 外部資料表而不進行分割
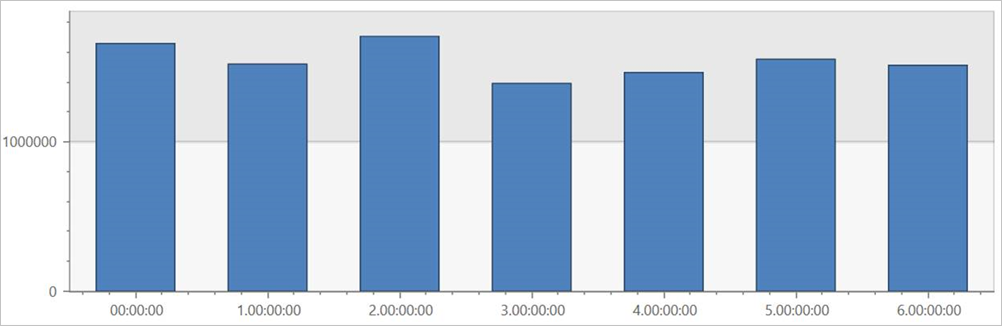
在外部數據表 TaxiRides 上執行此查詢,以顯示整個數據集中每周每天的車程。
external_table("TaxiRides")
| summarize count() by dayofweek(pickup_datetime)
| render columnchart
此查詢會顯示一周中最繁忙的一天。 由於數據未分割,因此查詢最多可能需要幾分鐘的時間才能傳回結果。
使用數據分割查詢 TaxiRides 外部數據表
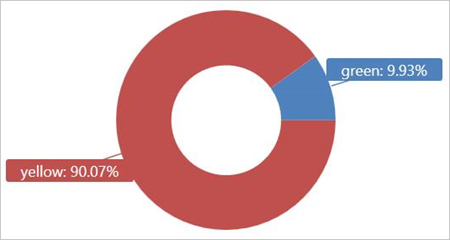
在外部數據表 TaxiRides 上執行此查詢,以顯示 2017 年 1 月使用的計程車類型(黃色或綠色)。
external_table("TaxiRides")
| where pickup_datetime between (datetime(2017-01-01) .. datetime(2017-02-01))
| summarize count() by cab_type
| render piechart
此查詢會使用數據分割,以優化查詢時間和效能。 查詢會篩選分割數據行 (pickup_datetime),並在幾秒鐘內傳回結果。
您可以撰寫其他查詢,以在外部數據表 TaxiRides 上執行,並深入了解數據。
優化查詢效能
使用下列查詢外部數據的最佳做法,在 Lake 中優化查詢效能。
資料格式
- 針對分析查詢使用單欄格式,原因如下:
- 只能讀取與查詢相關的數據行。
- 數據行編碼技術可以大幅減少數據大小。
- Azure Data Explorer 支援 Parquet 和 ORC 欄位格式。 因為其優化的實作,因此建議使用 Parquet 格式。
Azure 區域
檢查外部資料是否與你的 Azure Data Explorer 叢集處於同一 Azure 區域。 此設定可降低成本和數據擷取時間。
檔案大小
最佳檔案大小是每個檔案的數百 Mb(最多 1 GB)。 避免許多需要不必要的額外負荷的小型檔案,例如較慢的檔案列舉程式,以及有限的單欄格式使用。 檔案數量應該要大於你 Azure Data Explorer 叢集的 CPU 核心數。
壓縮
使用壓縮來減少從遠端記憶體擷取的數據量。 針對 Parquet 格式,請使用可個別壓縮欄位群組的內部 Parquet 壓縮機制,這樣您就可以分別讀取它們。 若要驗證壓縮機制的使用,請檢查檔案是否按照以下格式命名:<filename>.gz.parquet 或 <filename>.snappy.parquet,而不是 <filename>.parquet.gz。
分區
使用「資料夾」分割來組織您的資料,讓查詢略過不相關的路徑。 規劃分區時,請考慮檔案大小以及查詢中的常見篩選條件,例如時間戳記或租用戶標識符。
VM 大小
選取具有更多核心和更高網路輸送量的 VM SKU(記憶體較不重要)。 欲了解更多資訊,請參閱 選擇適合您Azure Data Explorer叢集的正確虛擬機 SKU。