Apache Kafka 是用於建置即時串流資料管線和應用程式的分散式串流平台,可在系統或應用程式之間可靠地移動資料。 Kafka Connect 是一項工具,能夠彈性且可靠地在 Apache Kafka 和其他系統之間串流資料。 Kusto Kafka 接收器可作為 Kafka 的連接器,且不需要使用程式碼。 從 Git 存放庫或 Confluent Hub下載 sink 連接器 jar。
本文說明如何使用 Kafka 擷取資料,運用獨立的 Docker 設定以簡化 Kafka 叢集和 Kafka 連接器叢集設定。
必要條件
- Azure 訂用帳戶。 建立免費的 Azure 帳戶。
- 具有預設快取和保留原則的 Azure 數據總 管叢集和資料庫 。
- Azure CLI。
- Docker 與 Docker Compose。
建立 Microsoft Entra 服務主體
Microsoft Entra 服務主體可以透過 Azure 入口網站或以程式設計方式建立,如下列範例所示。
此服務主體是連接器用來在 Kusto 資料表中寫入您的資料的識別。 您會授與此服務主體存取 Kusto 資源的權限。
透過 Azure CLI 登入您的 Azure 訂用帳戶。 然後在瀏覽器中進行驗證。
az login選擇用來託管主體的訂用帳戶。 當您有多個訂用帳戶時,需要此步驟。
az account set --subscription YOUR_SUBSCRIPTION_GUID建立服務主體。 在此範例中,服務主體稱為
my-service-principal。az ad sp create-for-rbac -n "my-service-principal" --role Contributor --scopes /subscriptions/{SubID}從傳回的 JSON 資料中,複製
appId、password和tenant供日後使用。{ "appId": "00001111-aaaa-2222-bbbb-3333cccc4444", "displayName": "my-service-principal", "name": "my-service-principal", "password": "00001111-aaaa-2222-bbbb-3333cccc4444", "tenant": "00001111-aaaa-2222-bbbb-3333cccc4444" }
您已建立您的 Microsoft Entra 應用程式和服務主體。
建立目標資料表
從您的查詢環境,使用下列命令建立名為
Storms的資料表:.create table Storms (StartTime: datetime, EndTime: datetime, EventId: int, State: string, EventType: string, Source: string)使用下列指令建立已匯入資料與
Storms_CSV_Mapping的對應表:.create table Storms ingestion csv mapping 'Storms_CSV_Mapping' '[{"Name":"StartTime","datatype":"datetime","Ordinal":0}, {"Name":"EndTime","datatype":"datetime","Ordinal":1},{"Name":"EventId","datatype":"int","Ordinal":2},{"Name":"State","datatype":"string","Ordinal":3},{"Name":"EventType","datatype":"string","Ordinal":4},{"Name":"Source","datatype":"string","Ordinal":5}]'在資料表上建立引入批次策略,用以設定佇列引入延遲。
提示
輸入批次政策是一種效能最佳化工具,並包含三個參數。 首個滿足的條件會觸發資料擷取至資料表。
.alter table Storms policy ingestionbatching @'{"MaximumBatchingTimeSpan":"00:00:15", "MaximumNumberOfItems": 100, "MaximumRawDataSizeMB": 300}'使用來自建立 Microsoft Entra 服務主體的服務主體,授與使用資料庫的權限。
.add database YOUR_DATABASE_NAME admins ('aadapp=YOUR_APP_ID;YOUR_TENANT_ID') 'AAD App'
運行實驗室
下列實驗室旨在讓您體驗開始建立資料、設定 Kafka 連接器,以及串流此資料。 然後,您可以查看導入的資料。
複製 git 存放庫
複製實驗室的 git 存放庫。
在您的電腦上建立本機目錄。
mkdir ~/kafka-kusto-hol cd ~/kafka-kusto-hol複製存放庫。
cd ~/kafka-kusto-hol git clone https://github.com/Azure/azure-kusto-labs cd azure-kusto-labs/kafka-integration/dockerized-quickstart
複製的存放庫的內容
執行下列命令以列出複製的存放庫的內容:
cd ~/kafka-kusto-hol/azure-kusto-labs/kafka-integration/dockerized-quickstart
tree
此搜尋的結果是:
├── README.md
├── adx-query.png
├── adx-sink-config.json
├── connector
│ └── Dockerfile
├── docker-compose.yaml
└── storm-events-producer
├── Dockerfile
├── StormEvents.csv
├── go.mod
├── go.sum
├── kafka
│ └── kafka.go
└── main.go
檢閱複製的存放庫中的檔案
下列各節說明檔案樹狀結構中檔案的重要部分。
adx-sink-config.json
此檔案包含 Kusto 接收器屬性,您可以在其中更新特定的組態詳細資料:
{
"name": "storm",
"config": {
"connector.class": "com.microsoft.azure.kusto.kafka.connect.sink.KustoSinkConnector",
"flush.size.bytes": 10000,
"flush.interval.ms": 10000,
"tasks.max": 1,
"topics": "storm-events",
"kusto.tables.topics.mapping": "[{'topic': 'storm-events','db': '<enter database name>', 'table': 'Storms','format': 'csv', 'mapping':'Storms_CSV_Mapping'}]",
"aad.auth.authority": "<enter tenant ID>",
"aad.auth.appid": "<enter application ID>",
"aad.auth.appkey": "<enter client secret>",
"kusto.ingestion.url": "https://ingest-<name of cluster>.<region>.kusto.windows.net",
"kusto.query.url": "https://<name of cluster>.<region>.kusto.windows.net",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.storage.StringConverter"
}
}
根據您的設定,取代下列屬性的值:aad.auth.authority、aad.auth.appid、aad.auth.appkey、kusto.tables.topics.mapping、(資料庫名稱)、kusto.ingestion.url、和 kusto.query.url。
連接器 - Dockerfile
此檔案具有用來產生連接器執行個體的 Docker 映像的命令。 它包含從 git 存放庫發行目錄下載的連接器。
Storm-events-producer 目錄
此目錄具有 Go 程式,可讀取本機 "StormEvents.csv" 檔案,並將資料發佈至 Kafka 主題。
docker-compose.yaml
version: "2"
services:
zookeeper:
image: debezium/zookeeper:1.2
ports:
- 2181:2181
kafka:
image: debezium/kafka:1.2
ports:
- 9092:9092
links:
- zookeeper
depends_on:
- zookeeper
environment:
- ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092
kusto-connect:
build:
context: ./connector
args:
KUSTO_KAFKA_SINK_VERSION: 1.0.1
ports:
- 8083:8083
links:
- kafka
depends_on:
- kafka
environment:
- BOOTSTRAP_SERVERS=kafka:9092
- GROUP_ID=adx
- CONFIG_STORAGE_TOPIC=my_connect_configs
- OFFSET_STORAGE_TOPIC=my_connect_offsets
- STATUS_STORAGE_TOPIC=my_connect_statuses
events-producer:
build:
context: ./storm-events-producer
links:
- kafka
depends_on:
- kafka
environment:
- KAFKA_BOOTSTRAP_SERVER=kafka:9092
- KAFKA_TOPIC=storm-events
- SOURCE_FILE=StormEvents.csv
啟動容器
在終端機中,啟動容器:
docker-compose up產生者應用程式會開始將事件傳送至
storm-events主題。 您應該會看到類似以下的日誌記錄:.... events-producer_1 | sent message to partition 0 offset 0 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 00:00:00.0000000,13208,NORTH CAROLINA,Thunderstorm Wind,Public events-producer_1 | events-producer_1 | sent message to partition 0 offset 1 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 05:00:00.0000000,23358,WISCONSIN,Winter Storm,COOP Observer ....若要檢查記錄,請在單獨的終端機中執行下列命令:
docker-compose logs -f | grep kusto-connect
啟動連接器
使用 Kafka Connect REST 呼叫來啟動連接器。
在不同的終端機中,使用下列命令來執行資料匯入任務:
curl -X POST -H "Content-Type: application/json" --data @adx-sink-config.json http://localhost:8083/connectors若要檢查狀態,請在單獨的終端機中執行下列命令:
curl http://localhost:8083/connectors/storm/status
連接器會啟動佇列匯入程序。
備註
如果您遇到日誌連接器問題,請建立事件。
受控識別
根據預設,Kafka 連接器會在擷取期間使用應用程式方法來進行驗證。 使用受管理身份來驗證:
將叢集指派受控識別,並授予儲存體帳戶讀取許可權。 如需詳細資訊,請參閱 使用受控識別驗證擷取數據。
在您的 adx-sink-config.json 檔案中,將 設定
aad.auth.strategy為managed_identity,並確定aad.auth.appid已設定為受控識別用戶端 (應用程式) 識別碼。使用 私有實例中繼資料服務令牌 ,取代 Microsoft Entra 服務主體。
備註
使用管理身份時,連接器會自動從呼叫上下文中取得 appId 和 tenant ,因此你不需要提供密碼。
查詢和審閱資料
確認資料匯入
一旦資料抵達
Storms資料表,請先檢查資料列的計數以確保資料已成功傳輸。Storms | count確認擷取程序中沒有發生失敗:
.show ingestion failures一旦您看到資料,請嘗試一些查詢。
查詢資料
若要查看所有記錄,請執行下列查詢:
Storms | take 10使用
where和project來篩選特定資料:Storms | where EventType == 'Drought' and State == 'TEXAS' | project StartTime, EndTime, Source, EventId使用
summarize運算子:Storms | summarize event_count=count() by State | where event_count > 10 | project State, event_count | render columnchart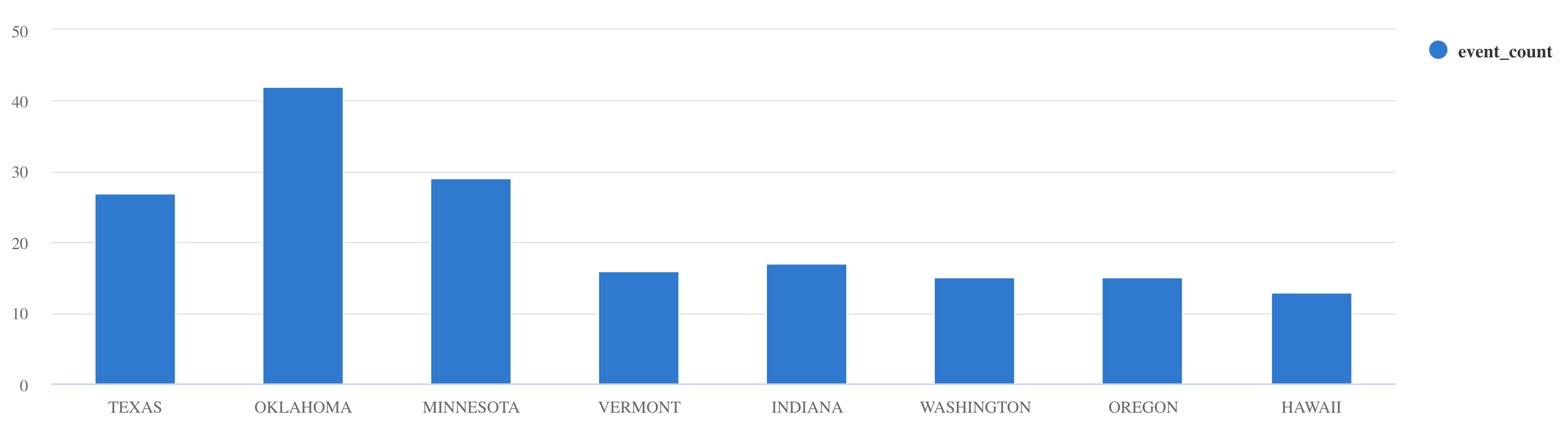
如需更多查詢範例和指導,請參閱在 KQL 中寫入查詢和 Kusto 查詢語言文件。
重置
若要重設,請執行下列步驟:
- 停止容器 (
docker-compose down -v) - 刪除 (
drop table Storms) - 重新建立
Storms資料表 - 重新建立資料表對應
- 重新啟動容器 (
docker-compose up)
清除資源
若要刪除 Azure 數據總管資源,請使用 az kusto cluster delete (kusto extension) 或 az kusto database delete (kusto extension):
az kusto cluster delete --name "<cluster name>" --resource-group "<resource group name>"
az kusto database delete --cluster-name "<cluster name>" --database-name "<database name>" --resource-group "<resource group name>"
您也可以透過 Azure 入口網站 刪除叢集和資料庫。 如需詳細資訊,請參閱 刪除 Azure 資料總管叢集 和 刪除 Azure 數據總管中的資料庫。
調整 Kafka Sink 連接器
調整 Kafka Sink 連接器以適應引入批次原則:
- 調整 Kafka 接收器
flush.size.bytes限制大小,從 1 MB 開始,逐步增加 10 MB 或 100 MB。 - 使用 Kafka 匯入端時,資料會彙總兩次。 連接器端資料會根據排清設定進行彙總,並根據批次原則在服務端彙總。 如果批次時間過短,以致連接器和服務無法導入資料,則必須增加批次時間。 將批次大小設定為 1 GB,並視需要增加或減少 100 MB 的增量。 例如,如果排清大小為 1 MB,且批次原則大小為 100 MB,則 Kafka 接收器連接器會將資料彙總成 100 MB 的批次。 服務接著會擷取該批次。 如果批次原則時間是 20 秒,而 Kafka Sink 連接器會在 20 秒的時間內排清 50 MB,則服務會接收一個 50 MB 的批次。
- 您可以透過新增實例和 Kafka 分割區來調整。 將分割區的數目增加
tasks.max。 如果您有足夠的資料來生成符合flush.size.bytes設定大小的 Blob,請建立分割區。 如果 Blob 較小,則批次會在達到時間限制時處理,因此分割區無法接收足夠的輸送量。 大量的分割區表示有更多的處理額外負荷。