Azure Data Factory 和 Azure Synapse Analytics 中的資料流程活動
適用於: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
提示
試用 Microsoft Fabric 中的 Data Factory,這是適用於企業的全方位分析解決方案。 Microsoft Fabric 涵蓋從資料移動到資料科學、即時分析、商業智慧和報告的所有項目。 了解如何免費啟動新的試用版!
使用資料流程活動,以透過對應資料流程轉換和移動資料。 如果您不熟悉資料流程,請參閱對應資料流程概觀
建立具有 UI 的資料流程活動
若要在管線中使用資料流程活動,請完成下列步驟:
在管線 [活動] 窗格中搜尋「資料流程」,然後將資料流程活動拖曳至管線畫布。
在畫布上,選取新的資料流程活動 (如未選取) 和其 [設定] 索引標籤以編輯其詳細資料。
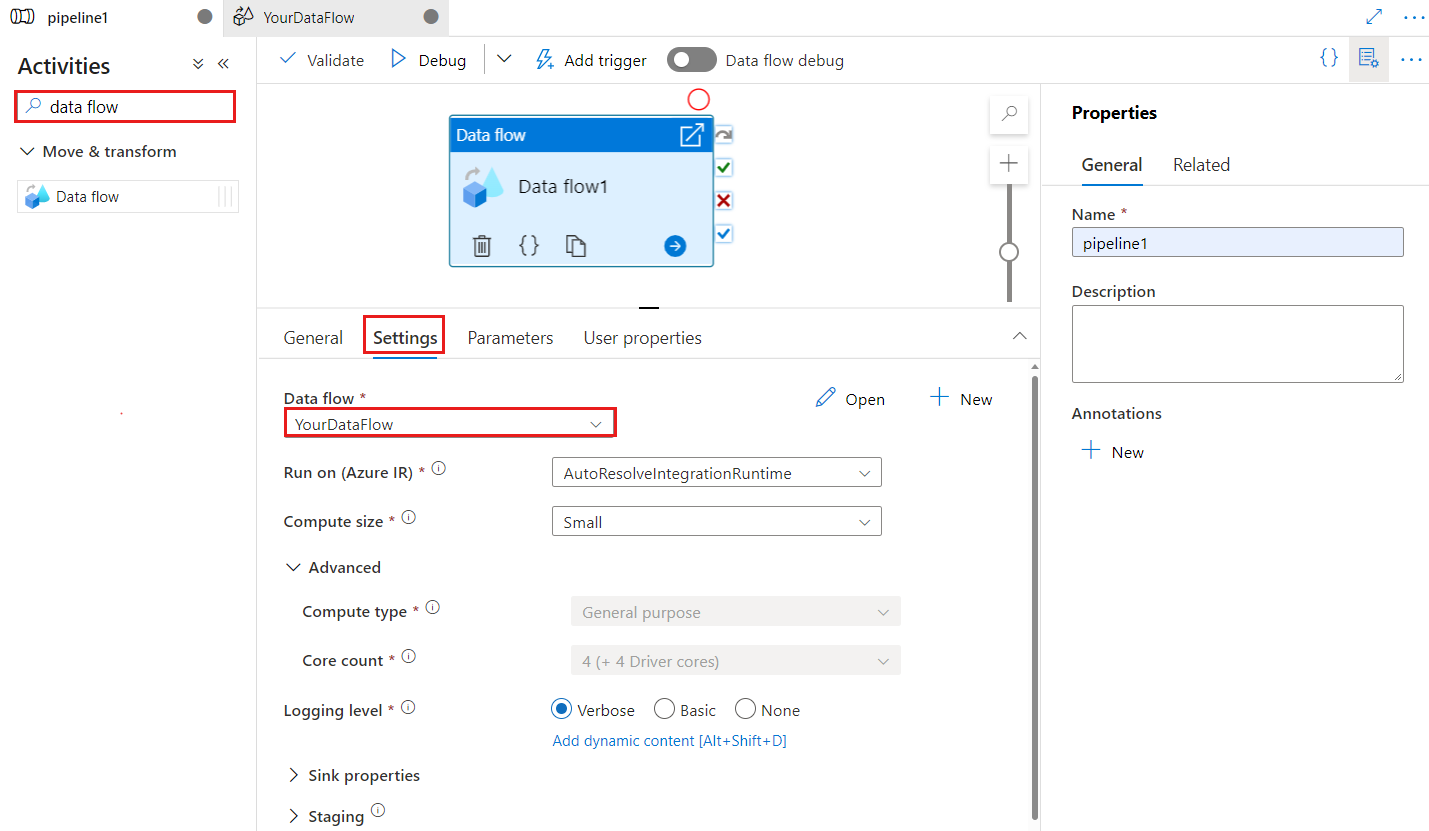
當資料流程用於變更的資料擷取時,會使用檢查點索引鍵來設定檢查點。 您可以覆寫它。 資料流程活動會使用 guid 值作為檢查點索引鍵,而不是「管線名稱 + 活動名稱」,以便持續追蹤客戶的異動資料擷取狀態,即使有任何重新命名的動作也一樣。 所有現有的資料流程活動都會使用舊模式索引鍵,以取得回溯相容性。 發佈新資料流程活動之後 (該活動具有異動資料擷取所啟用的資料流程資源),檢查點索引鍵選項如下所示。
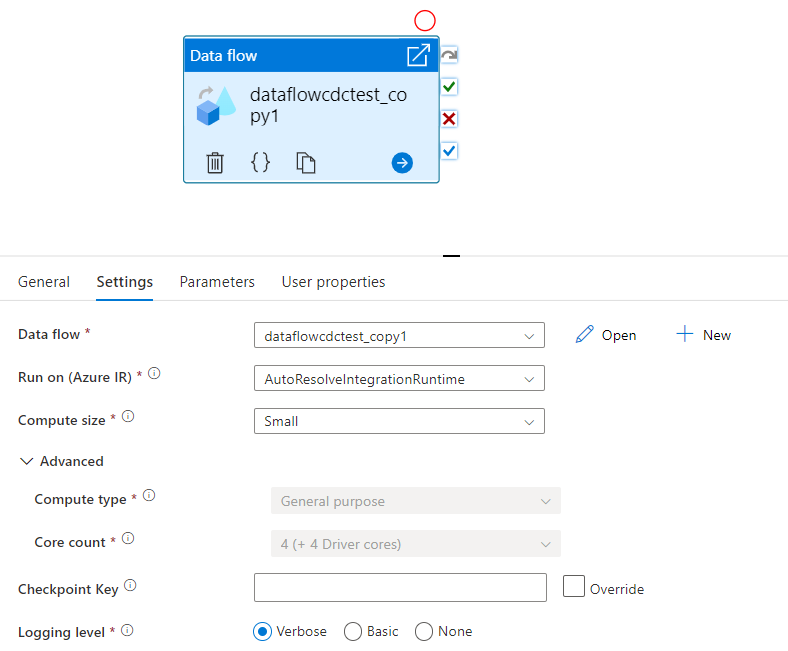
選取現有的資料流程,或使用 [新增] 按鈕建立新的管線。 視需要選取其他選項,以完成您的設定。
語法
{
"name": "MyDataFlowActivity",
"type": "ExecuteDataFlow",
"typeProperties": {
"dataflow": {
"referenceName": "MyDataFlow",
"type": "DataFlowReference"
},
"compute": {
"coreCount": 8,
"computeType": "General"
},
"traceLevel": "Fine",
"runConcurrently": true,
"continueOnError": true,
"staging": {
"linkedService": {
"referenceName": "MyStagingLinkedService",
"type": "LinkedServiceReference"
},
"folderPath": "my-container/my-folder"
},
"integrationRuntime": {
"referenceName": "MyDataFlowIntegrationRuntime",
"type": "IntegrationRuntimeReference"
}
}
類型屬性
| 屬性 | 說明 | 允許的值 | 必要 |
|---|---|---|---|
| 資料流程 | 正在執行的資料流程的參考 | DataFlowReference | Yes |
| integrationRuntime | 資料流程執行的計算環境。 如果未指定,則會使用自動解析 Azure 整合執行階段。 | IntegrationRuntimeReference | No |
| compute.coreCount | Spark 叢集中使用的核心數目。 只有在使用自動解析 Azure 整合執行階段時才能予以指定 | 8, 16, 32, 48, 80, 144, 272 | No |
| compute.computeType | Spark 叢集中使用的計算類型。 只有在使用自動解析 Azure 整合執行階段時才能予以指定 | “一般” | No |
| staging.linkedService | 如果您使用 Azure Synapse Analytics 來源或接收器,請指定用於 PolyBase 暫存的儲存體帳戶。 如果您的 Azure 儲存體設定了 VNet 服務端點,您必須使用受控識別驗證並將儲存體帳戶上的「允許受信任的 Microsoft 服務」開啟,請參閱使用 VNet 服務端點搭配 Azure 儲存體的影響。 同時了解 Azure Blob 和 Azure Data Lake Storage Gen2 個別所需的設定。 |
LinkedServiceReference | 只有在資料流程讀取或寫入至 Azure Synapse Analytics 時 |
| staging.folderPath | 如果您正在使用 Azure Synapse Analytics 來源或接收器,則為 Blob 儲存體帳戶中用於 PolyBase 暫存的資料夾路徑 | String | 只有在資料流程讀取或寫入至 Azure Synapse Analytics 時 |
| traceLevel | 設定資料流程活動執行的記錄層級 | 精細、粗略、無 | No |
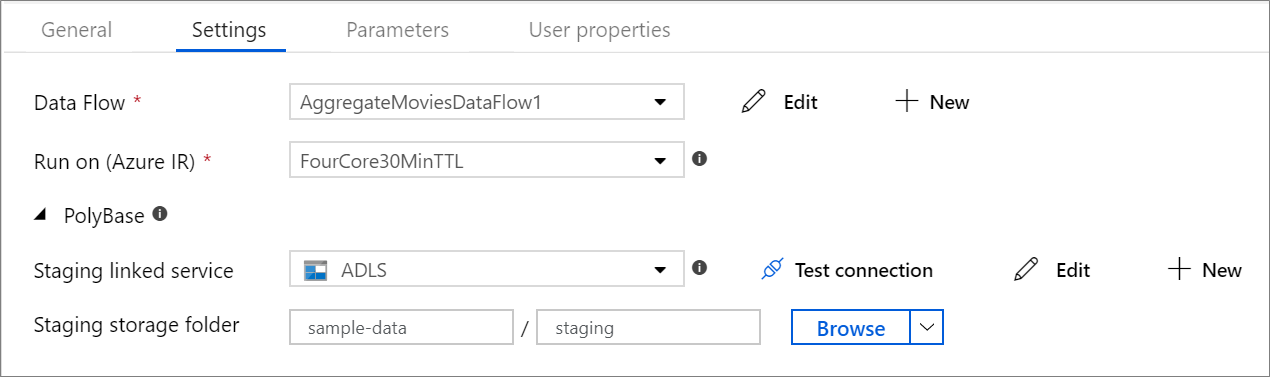
在執行階段動態調整資料流程計算大小
您可以動態設定核心計數和計算類型屬性,以便在執行階段調整為內送來源資料的大小。 使用「查閱」或「取得中繼資料」等管線活動來尋找來源資料集資料的大小。 接著,在資料流程活動屬性中使用 [新增動態內容]。 您可以選擇小型、中型或大型計算大小。 或者,選擇「自訂」並手動設定計算類型和核心數目。
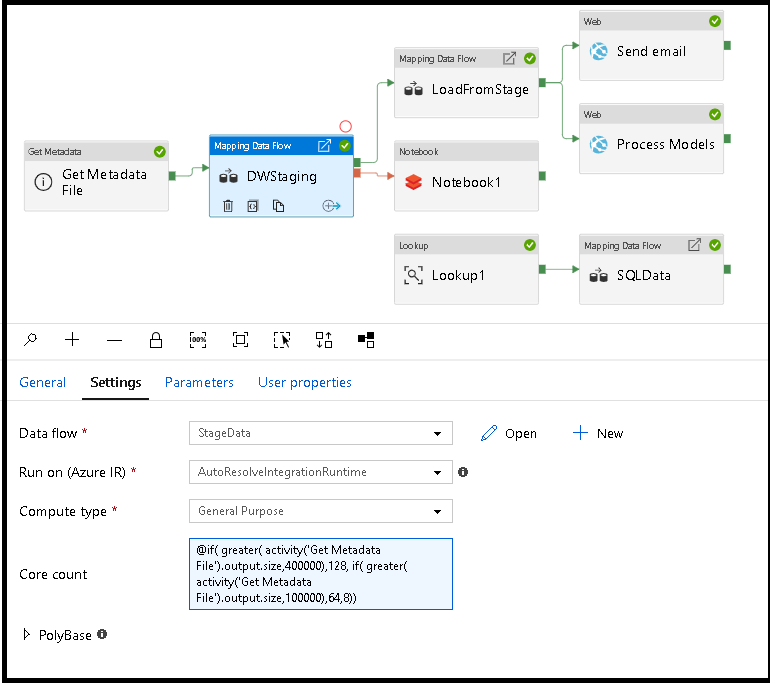
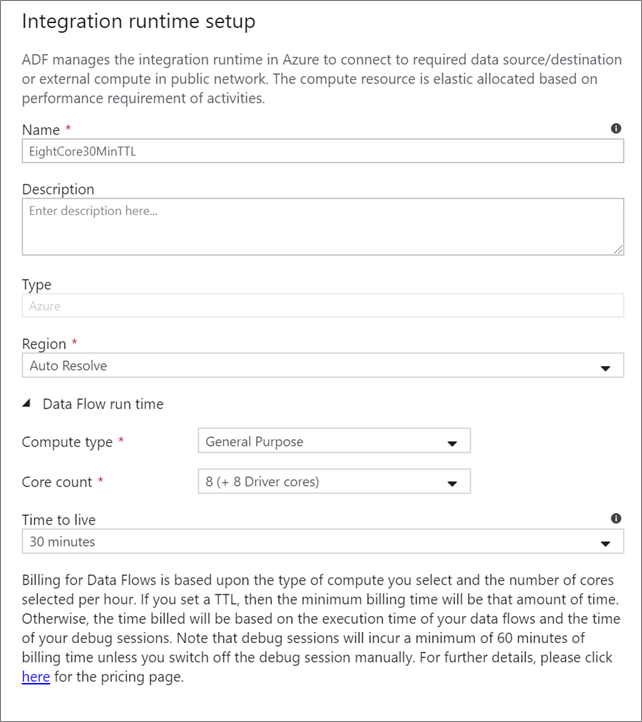
資料流程整合執行階段
選擇要用於資料流程活動執行的 Integration Runtime。 根據預設,服務會使用自動解決 Azure Integration Runtime 搭配四個工作者核心。 此 IR 具有一般用途的計算類型,並在與服務執行個體相同的區域中執行。 針對要實際運作的管線,強烈建議您建立自己的 Azure Integration Runtime 來定義特定區域、計算類型、核心計數和 TTL,以進行資料流程活動執行。
具有 8+8 (16 個虛擬核心) 設定的常規用途最小計算類型,以及 10 分鐘的存留時間 (TTL) 是大部分生產工作負載的建議最低要求。 Azure IR 可以設定小型 TTL 來維護暖叢集,讓暖叢集不會對冷叢集產生數分鐘的開始時間。 如需詳細資訊,請參閱 Azure Integration Runtime。
重要
資料流程活動中的 Integration Runtime 選取項目僅適用於管線的「觸發執行」。 使用資料流程對管線進行偵錯,會在偵錯工作階段中指定的叢集上執行。
PolyBase
如果您正在使用 Azure Synapse Analytics 作為接收器或來源,則您必須選擇 PolyBase 批次載入的暫存位置。 PolyBase 允許大量載入,而非逐列載入資料。 PolyBase 可大幅減少 Azure Synapse Analytics 的載入時間。
檢查點索引鍵
針對資料流程來源使用變更擷取選項時,ADF 會自動為您維護和管理檢查點。 預設檢查點索引鍵是資料流程名稱和管線名稱的雜湊。 如果您正在使用來源資料表或資料夾的動態模式,則建議您覆寫此雜湊,並在此設定您自己的檢查點索引鍵值。
記錄層級
如果您不需要每個資料流程活動的管線執行,即可完整記錄所有詳細的遙測記錄,則可以選擇性地將記錄層級設定為 [基本] 或 [無]。 在 [詳細資訊] 模式 (預設) 中執行資料流程時,您會要求服務在資料轉換期間於每個個別的分割區層級上完整記錄活動。 這可能是個高成本的作業,因此只有針對可以改善整體資料流程和管線效能而進行疑難排解時,才啟用詳細資訊。 「基本」模式只會記錄轉換持續時間,而「無」模式只會提供持續時間的摘要。

接收屬性
資料流程中的群組功能可讓您同時設定接收器的執行順序,以及使用相同的群組號碼將接收器群組在一起。 若要協助管理群組,您可以要求服務在相同的群組中透過平行方式執行接收器。 您也可以將接收器群組設定為即使在其中一個接收器遇到錯誤之後仍繼續。
資料流程接收器的預設行為是依序執行每個接收器,以序列方式執行,且在接收器中遇到錯誤時資料流程會失敗。 此外,除非您進入資料流程屬性,並針對接收器設定不同優先順序,否則所有接收器都會預設為相同的群組。

僅限第一個資料列
此選項僅適用於已啟用「輸出至活動」的快取接收器資料流程。 對於直接插入管線的資料流程而言,其輸出限制為 2 MB。 設定「僅限第一個資料列」可協助您在直接將資料流程活動輸出插入管線時,限制資料流程的資料輸出。
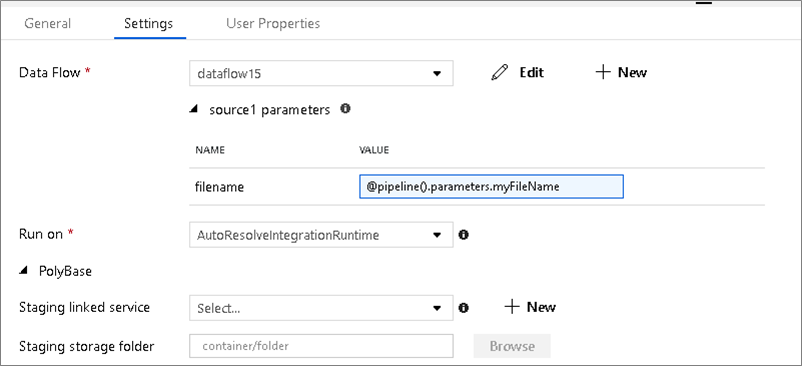
將資料流程參數化
已參數化的資料集
如果您的資料流程使用已參數化的資料集,請在 [設定] 索引標籤中設定參數值。
已參數化的資料流程
如果已參數化您的資料流程,則請在 [參數] 索引標籤中設定資料流程參數的動態值。您可以使用管線運算式語言或資料流程運算式語言來指派動態或常值參數值。 如需詳細資訊,請參閱資料流程參數。
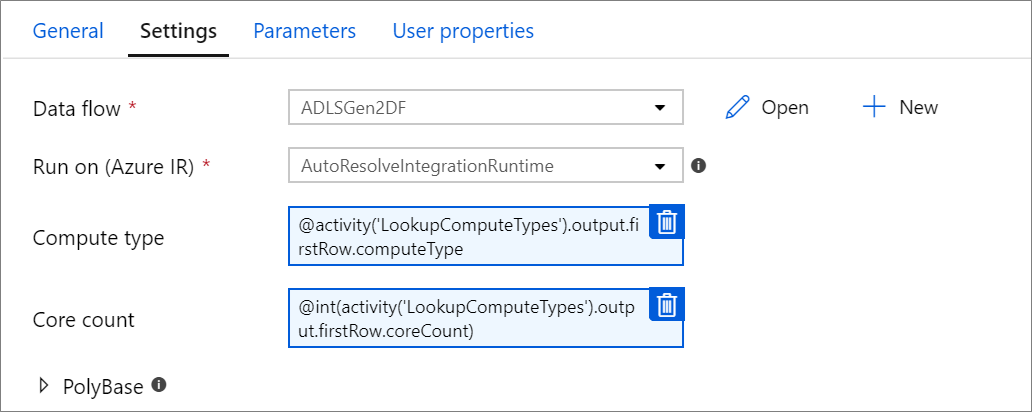
已參數化的計算屬性。
如果您使用自動解析 Azure 整合執行階段,並指定 compute.coreCount 和 compute.computeType 的值,則可以將核心計數或計算類型參數化。
資料流程活動的管線偵錯
若要使用資料流程活動執行偵錯管線,您必須透過頂端列上的 [資料流程偵錯] 滑桿來切換資料流程偵錯模式。 偵錯模式可讓您對作用中的 Spark 叢集執行資料流程。 如需詳細資訊,請參閱偵錯模式。
![顯示 [偵錯] 按鈕位置的螢幕快照](media/data-flow/debug-button-3.png)
偵錯管線會針對作用中的偵錯叢集執行,而不是 [資料流程活動] 設定中指定的整合執行階段環境。 您可以在啟動偵錯模式時選擇偵錯計算環境。
監視資料流程活動
資料流程活動的監視體驗十分特殊,您可以在其中檢視資料分割、階段時間和資料譜系資訊。 透過 [動作] 下方的眼鏡圖示開啟監視窗格。 如需詳細資訊,請參閱監視資料流程。
使用資料流程活動會導致後續活動
資料流程活動會輸出有關寫入每個接收器的資料列數目,以及從每個來源讀取的資料列數目的計量。 這些結果會在活動執行結果的 output 區段中傳回。 傳回的計量格式如下方的 JSON 所示。
{
"runStatus": {
"metrics": {
"<your sink name1>": {
"rowsWritten": <number of rows written>,
"sinkProcessingTime": <sink processing time in ms>,
"sources": {
"<your source name1>": {
"rowsRead": <number of rows read>
},
"<your source name2>": {
"rowsRead": <number of rows read>
},
...
}
},
"<your sink name2>": {
...
},
...
}
}
}
例如,若要取得在名為 'dataflowActivity' 的活動中寫入接收器 'sink1' 的資料列數目,請使用 @activity('dataflowActivity').output.runStatus.metrics.sink1.rowsWritten。
若要取得從該接收器中使用的來源 'source1' 所讀取的資料列數目,請使用 @activity('dataflowActivity').output.runStatus.metrics.sink1.sources.source1.rowsRead。
注意
如果接收器寫入零個資料列,則不會顯示在計量中。 可以使用 contains 函式來驗證其存在。 例如,contains(activity('dataflowActivity').output.runStatus.metrics, 'sink1') 會檢查是否已將任何資料列寫入 sink1。
相關內容
查看支援的控制流程活動: