適用於: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
提示
試用 Microsoft Fabric 中的 Data Factory,這是適用於企業的全方位分析解決方案。 Microsoft Fabric 涵蓋從資料移動到資料科學、即時分析、商業智慧和報告的所有項目。 了解如何免費開始新的試用!
數據流可在 Azure Data Factory 管線和 Azure Synapse Analytics 管線中使用。 本文適用於映射資料流。 如果您不熟悉資料轉換,請參閱入門文章使用對應資料流程轉換資料。
使用「解析轉換」來解析資料中的文字欄位,這些欄位是文件形式的字串。 目前支援的可剖析內嵌文件類型為 JSON、XML 和分隔文字。
組態
在剖析轉換設定面板中,您先挑選您想要剖析內嵌的資料行中包含的資料類型。 剖析轉換也包含下列組態設定。

Column
與派生資料行和彙總類似,資料行屬性是您可以透過從下拉式選取器中選取現有的資料行來修改它的位置。 或者,您也可以在這裡輸入新欄的名稱。 ADF 會將剖析的來源資料儲存至此資料行。 在大部分情況下,您會想要定義新的資料行,以剖析傳入的內嵌文件字串欄位。
表達式
使用運算式建構工具來設定解析的來源。 設定來源可以像只選擇包含您想要剖析的獨立資料的來源資料行一樣簡單,或者您可以建立複雜的運算式來進行剖析。
示例表達式
來源字串資料:
chrome|steel|plastic- 運算式:
(desc1 as string, desc2 as string, desc3 as string)
- 運算式:
來源 JSON 資料:
{"ts":1409318650332,"userId":"309","sessionId":1879,"page":"NextSong","auth":"Logged In","method":"PUT","status":200,"level":"free","itemInSession":2,"registration":1384448}- 運算式:
(level as string, registration as long)
- 運算式:
來源巢狀化 JSON 資料:
{"car" : {"model" : "camaro", "year" : 1989}, "color" : "white", "transmission" : "v8"}- 運算式:
(car as (model as string, year as integer), color as string, transmission as string)
- 運算式:
來源 XML 資料:
<Customers><Customer>122</Customer><CompanyName>Great Lakes Food Market</CompanyName></Customers>- 運算式:
(Customers as (Customer as integer, CompanyName as string))
- 運算式:
具有屬性資料的來源 XML:
<cars><car model="camaro"><year>1989</year></car></cars>- 運算式:
(cars as (car as ({@model} as string, year as integer)))
- 運算式:
具有保留字元的運算式:
{ "best-score": { "section 1": 1234 } }- 上述運算式無法運作,因為
best-score中的 '-' 字元會解譯為減法運算。 在這些情況下,請使用具有括弧標記法的變數,告知 JSON 引擎以字面方式解譯文字:var bestScore = data["best-score"]; { bestScore : { "section 1": 1234 } }
- 上述運算式無法運作,因為
注意:如果您從複雜類型中擷取屬性 (特別是 @model)) 時遇到錯誤,則其因應措施是將複雜類型轉換成字串,移除 @ 符號 (特別是 replace(toString(your_xml_string_parsed_column_name.cars.car),'@','')),然後使用剖析 JSON 轉換活動。
輸出資料行類型
以下是您從寫入至單一資料行的剖析中,設定目標輸出結構描述的位置。 設定解析輸出架構最簡單的方式,就是選取運算式產生器右上方的 [偵測類型] 按鈕。 ADF 會嘗試從您要剖析的字串欄位自動偵測結構描述,並在輸出運算式中為您設定。
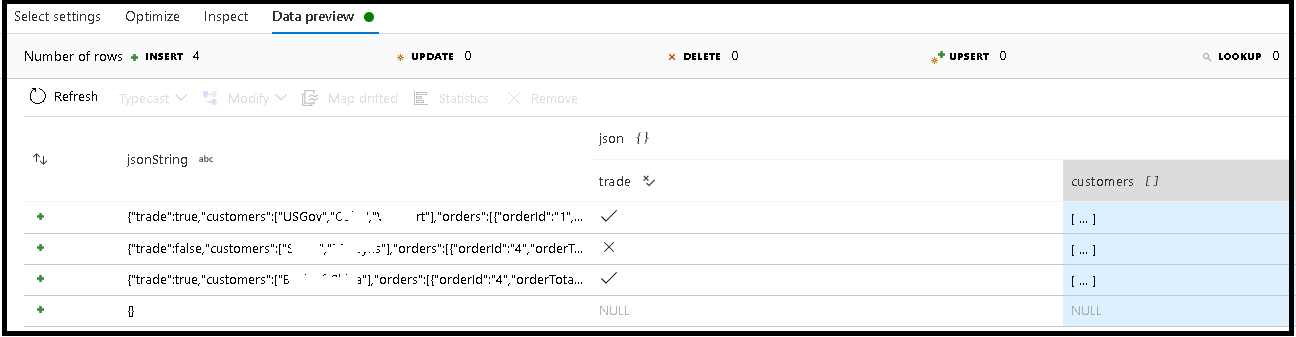
在此範例中,我們已定義傳入欄位 "jsonString" 的剖析 (其為純文字),但是格式化為 JSON 結構。 我們會在名為「json」的新資料行中將剖析的結果儲存為 JSON,具有此結構描述:
(trade as boolean, customers as string[])
請參閱檢查標籤和資料預覽,以確認輸出已正確映射。
使用派生的資料行活動來擷取階層式資料 (即運算式欄位中的 your_complex_column_name.car.model)
範例
source(output(
name as string,
location as string,
satellites as string[],
goods as (trade as boolean, customers as string[], orders as (orderId as string, orderTotal as double, shipped as (orderItems as (itemName as string, itemQty as string)[]))[])
),
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false,
documentForm: 'documentPerLine') ~> JsonSource
source(output(
movieId as string,
title as string,
genres as string
),
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false) ~> CsvSource
JsonSource derive(jsonString = toString(goods)) ~> StringifyJson
StringifyJson parse(json = jsonString ? (trade as boolean,
customers as string[]),
format: 'json',
documentForm: 'arrayOfDocuments') ~> ParseJson
CsvSource derive(csvString = 'Id|name|year\n\'1\'|\'test1\'|\'1999\'') ~> CsvString
CsvString parse(csv = csvString ? (id as integer,
name as string,
year as string),
format: 'delimited',
columnNamesAsHeader: true,
columnDelimiter: '|',
nullValue: '',
documentForm: 'documentPerLine') ~> ParseCsv
ParseJson select(mapColumn(
jsonString,
json
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> KeepStringAndParsedJson
ParseCsv select(mapColumn(
csvString,
csv
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> KeepStringAndParsedCsv
資料流程指令碼
語法
範例
parse(json = jsonString ? (trade as boolean,
customers as string[]),
format: 'json|XML|delimited',
documentForm: 'singleDocument') ~> ParseJson
parse(csv = csvString ? (id as integer,
name as string,
year as string),
format: 'delimited',
columnNamesAsHeader: true,
columnDelimiter: '|',
nullValue: '',
documentForm: 'documentPerLine') ~> ParseCsv