使用 Azure Databricks 進行轉換
適用於: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
提示
試用 Microsoft Fabric 中的 Data Factory,這是適用於企業的全方位分析解決方案。 Microsoft Fabric 涵蓋從資料移動到資料科學、即時分析、商業智慧和報告的所有項目。 了解如何免費開始新的試用!
在本教學課程中,您會建立端對端管線,其中包含 Azure Data Factory 中的驗證、複製資料和筆記本活動。
驗證確保您的來源資料集已準備好供下游取用,然後再觸發複製和分析作業。
複製資料會將來源資料集複製至接收儲存體,此儲存體會掛接為 Azure Databricks 筆記本中的 DBFS。 如此一來,Spark 即可直接取用資料集。
筆記本會觸發可轉換資料集的 Databricks 筆記本。 其也會將資料集新增至已處理的資料夾或 Azure Synapse Analytics。
為了簡單起見,本教學課程中的範本不會建立排定的觸發程序。 如有需要,您可以新增一個。

必要條件
Azure Blob 儲存體帳戶,其有一個稱為
sinkdata的容器,用作接收器。記下儲存體帳戶名稱、容器名稱和存取金鑰。 您稍後在範本中會需要這些值。
Azure Databricks 工作區。
匯入筆記本進行轉換
若要將轉換筆記本匯入至 Databricks 工作區:
登入您的 Azure Databricks 工作區,然後選取 [匯入]。
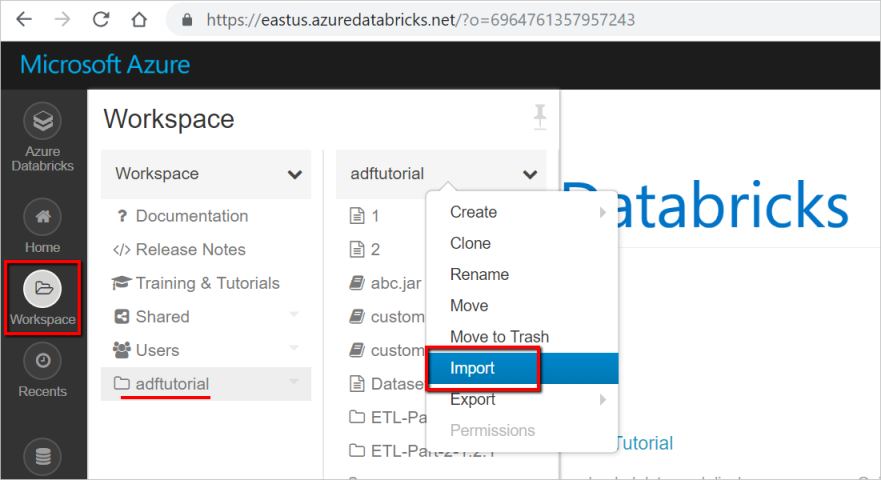 您的工作區路徑可以不同於顯示的工作區路徑,但記住該路徑,稍後會用到。
您的工作區路徑可以不同於顯示的工作區路徑,但記住該路徑,稍後會用到。選取 [匯入自: URL]。 在文字方塊中,輸入
https://adflabstaging1.blob.core.windows.net/share/Transformations.html。
現在,我們將以您的儲存體連線資訊更新轉換筆記本。
在匯入的筆記本中,移至命令 5,如下列程式碼片段所示。
- 將
<storage name>和<access key>取代為您自己的儲存體連線資訊。 - 搭配
sinkdata容器使用儲存體帳戶。
# Supply storageName and accessKey values storageName = "<storage name>" accessKey = "<access key>" try: dbutils.fs.mount( source = "wasbs://sinkdata\@"+storageName+".blob.core.windows.net/", mount_point = "/mnt/Data Factorydata", extra_configs = {"fs.azure.account.key."+storageName+".blob.core.windows.net": accessKey}) except Exception as e: # The error message has a long stack track. This code tries to print just the relevant line indicating what failed. import re result = re.findall(r"\^\s\*Caused by:\s*\S+:\s\*(.*)\$", e.message, flags=re.MULTILINE) if result: print result[-1] \# Print only the relevant error message else: print e \# Otherwise print the whole stack trace.- 將
產生供 Data Factory 用來存取 Databricks 的 Databricks 存取權杖。
- 在 Databricks 工作區中,選取右上方的使用者設定檔圖示。
- 選取 [使用者設定]。

- 選取 [存取權杖] 索引標籤底下的 [產生新權杖]。
- 選取產生。

儲存存取權杖,以在稍後建立 Databricks 連結服務時使用該存取權杖。 存取權杖看起來如下:
dapi32db32cbb4w6eee18b7d87e45exxxxxx。
如何使用此範本
移至 [使用 Azure Databricks 進行轉換] 範本,並針對下列連線建立新的連結服務。

來源 Blob 連線 - 存取來源資料。
針對此練習,您可以使用公用 Blob 儲存體,其中包含來源檔案。 參考設定的下列螢幕擷取畫面。 使用下列 SAS URL 連線到來源儲存體 (唯讀存取):
https://storagewithdata.blob.core.windows.net/data?sv=2018-03-28&si=read%20and%20list&sr=c&sig=PuyyS6%2FKdB2JxcZN0kPlmHSBlD8uIKyzhBWmWzznkBw%3D
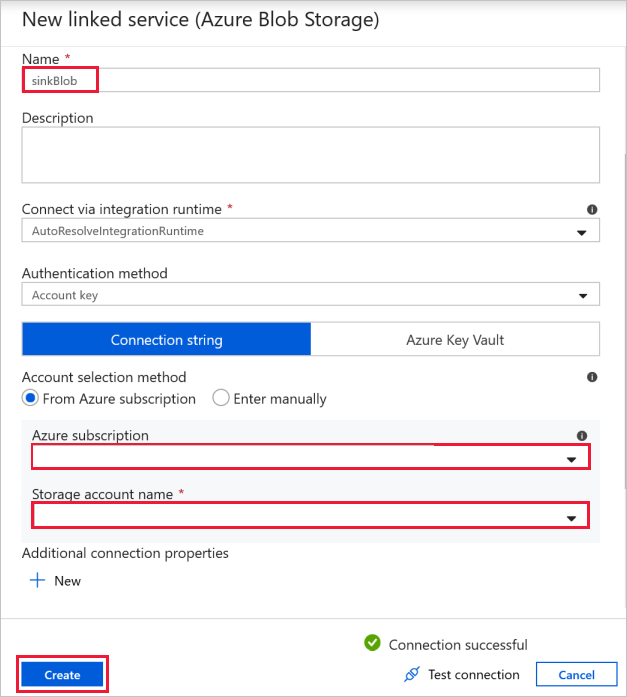
目的地 Blob 連線 - 儲存複製的資料。
在 [新增連結服務] 視窗中,選取您的接收儲存體 Blob。
Azure Databricks - 連線到 Databricks 叢集。
使用您先前產生的存取金鑰,建立 Databricks 連結服務。 您可以選擇選取「互動式叢集」(若有的話)。 此範例會使用 [新增作業叢集] 選項。

選取使用此範本。 您會看到已建立管線。

管線簡介和設定
在新管線中,大部分設定都會搭配預設值自動設定。 檢閱管線的設定,並進行任何必要的變更。
在驗證活動可用性旗標中,驗證來源資料集值是否已設定為您稍早建立的
SourceAvailabilityDataset。
在複製資料活動 file-to-blob 中,勾選 [來源] 和 [接收器] 索引標籤。 如有必要,請變更設定。
[來源] 索引標籤

[接收] 索引標籤

在筆記本活動轉換中,視需要檢閱並更新路徑和設定。
Databricks 連結服務應該預先填入來自前一個步驟的值,如下所示:

若要檢查 [筆記本] 設定:
選取 [設定] 索引標籤。針對 [筆記本路徑],驗證預設路徑是否正確。 您可能需要瀏覽並選擇正確的筆記本路徑。

展開 [基礎參數] 選取器,並驗證參數是否符合下列螢幕擷取畫面中顯示的內容。 這些參數會從 Data Factory 傳遞至 Databricks 筆記本。

驗證管線參數是否符合下列螢幕擷取畫面顯示的內容:

連線至您的資料集。
注意
在下列資料集中,範本中已自動指定檔案路徑。 如果需要任何變更,請確定您指定容器和目錄的路徑,以防發生任何連線錯誤。
SourceAvailabilityDataset - 檢查來源資料是否可用。

SourceFilesDataset - 存取來源資料。

DestinationFilesDataset - 將資料複製到接收目的地位置。 使用下列值:
在前一個步驟中建立的連結服務 -
sinkBlob_LS。檔案路徑 -
sinkdata/staged_sink。
選取 [偵錯] 以執行管線。 您可以尋找 Databricks 記錄的連結,以取得更詳細的 Spark 記錄。

您也可以使用 Azure 儲存體總管來驗證資料檔案。
注意
為了建立與 Data Factory 管線執行的相互關聯,此範例會將管線執行識別碼從資料處理站附加至輸出資料夾。 這有助於持續追蹤每個執行所產生的檔案。
