適用於: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
秘訣
Data Factory in Microsoft Fabric 是下一代的 Azure Data Factory,擁有更簡單的架構、內建 AI 及新功能。 如果你是資料整合新手,建議先從 Fabric Data Factory 開始。 現有的 ADF 工作負載可升級至 Fabric,以存取資料科學、即時分析與報告等新能力。
在本教學課程中,您會使用 Azure 入口網站建立 Azure Data Factory 管線,對 Databricks Jobs 叢集執行 Databricks 筆記本。 執行時也會將 Azure Data Factory 參數傳遞給 Databricks 筆記本。
您會在本教學課程中執行下列步驟:
建立資料處理站。
建立使用 Databricks 筆記本活動的管線。
觸發管線執行。
監視管道執行。
如果你沒有Azure訂閱,請在開始前建立一個free帳號。
注意
如需如何使用 Databricks Notebook 活動的完整詳細數據,包括使用連結庫和傳遞輸入和輸出參數,請參閱 Databricks Notebook 活動 檔。
必要條件
- Azure Databricks workspace。 建立 Databricks 工作區或使用現有的工作區。 你可以在 Azure Databricks 工作區建立一個 Python 筆記本。 接著你執行筆記本,並用 Azure Data Factory 將參數傳入它。
建立資料處理站
啟動 Microsoft Edge 或 Google Chrome網頁瀏覽器。 目前,Data Factory UI 僅支援 Microsoft Edge 與 Google Chrome 網頁瀏覽器。
在Azure入口網站選單中選擇 Create a resource,然後選擇 Analytics>Data Factory :
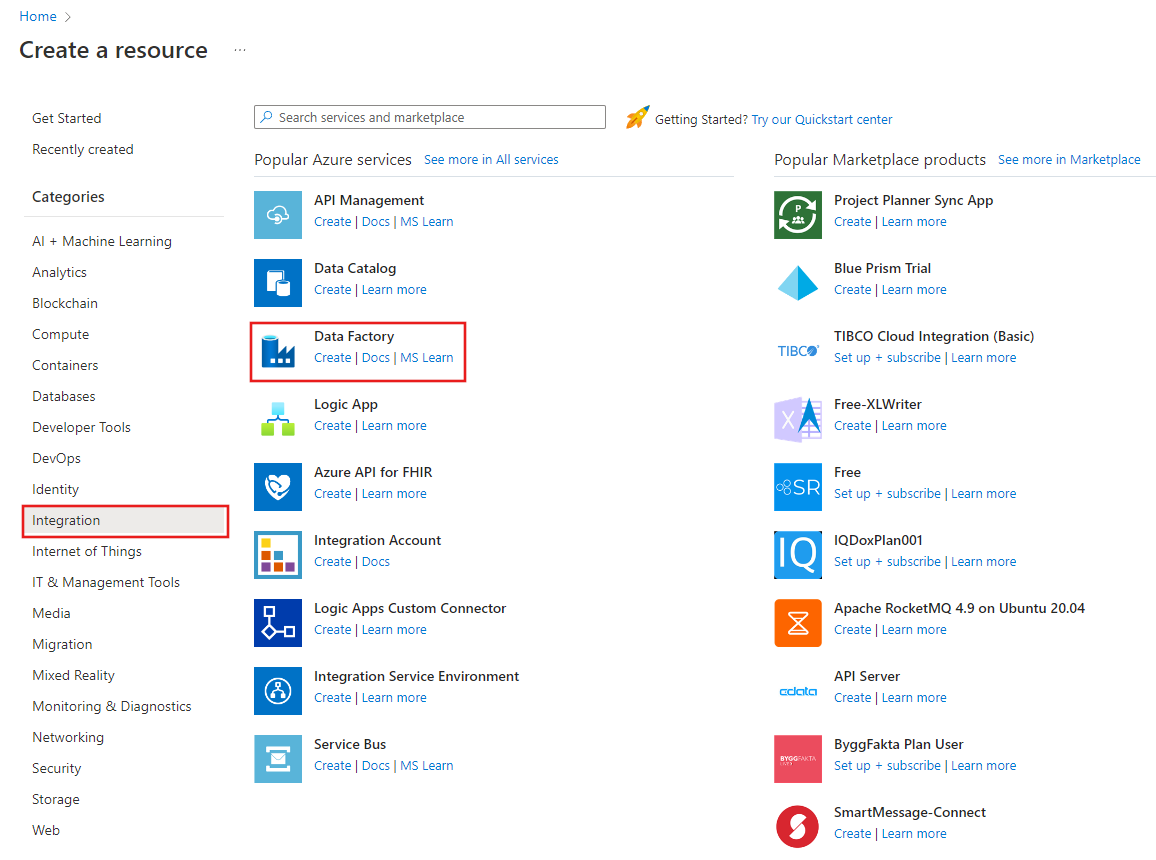
在 Create Data Factory 頁面,Basics 標籤下,選擇你想建立資料工廠的 Azure Subscription。
針對 [資源群組],採取下列其中一個步驟︰
從下拉式清單中選取現有的資源群組。
選取 [建立新的] ,然後輸入新資源群組的名稱。
欲了解資源群組,請參閱 Using resource groups to manage your Azure resources。
針對 [區域],選取資料處理站的位置。
清單只顯示 Data Factory 支援的地點,以及你的 Azure Data Factory 元資料將被儲存的位置。 Data Factory 使用的相關資料儲存(例如 Azure 儲存體 和 Azure SQL Database)以及運算工具(例如 Azure HDInsight)可以在其他區域執行。
針對 [名稱],輸入 ADFTutorialDataFactory。
Azure資料工廠的名稱必須為全球唯一。 如果您看到下列錯誤,請變更資料處理站的名稱 (例如,使用 <yourname>ADFTutorialDataFactory)。 如需 Data Factory 成品的命名規則,請參閱 Data Factory - 命名規則一文。
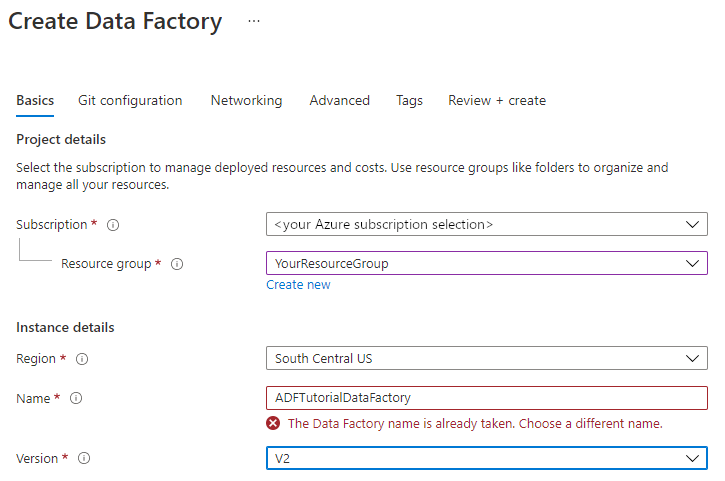
對 版本,選擇 V2。
完成時,選取 [下一步:Git 組態],接著選取 [稍後設定 Git] 核取方塊。
選取 [檢閱 +建立],然後在通過驗證後選取 [建立]。
在建立完成後,選取 [前往資源],以瀏覽至 [資料處理站] 頁面。 選擇 Open Azure Data Factory Studio 圖塊,在獨立的瀏覽器分頁啟動 Azure Data Factory 使用者介面(UI)應用程式。

建立連結服務
在本節中,您會建立 Databricks 連結服務。 此連結服務包含 Databricks 叢集的連線資訊:
建立 Azure Databricks 連結服務
在首頁,切換至左側面板中的 [管理] 索引標籤。
![顯示 [管理] 索引標籤的螢幕快照。](media/doc-common-process/get-started-page-manage-button.png)
選取 [連線] 底下的 [已連結的服務],然後選取 [+ 新增]。
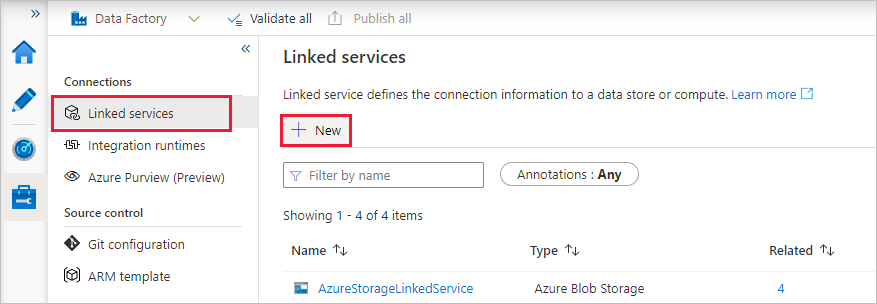
在 New linked service 視窗中,選擇 Compute>Azure Databricks,然後選擇 Continue。

在 [新增已連結的服務] 視窗中,完成下列步驟:
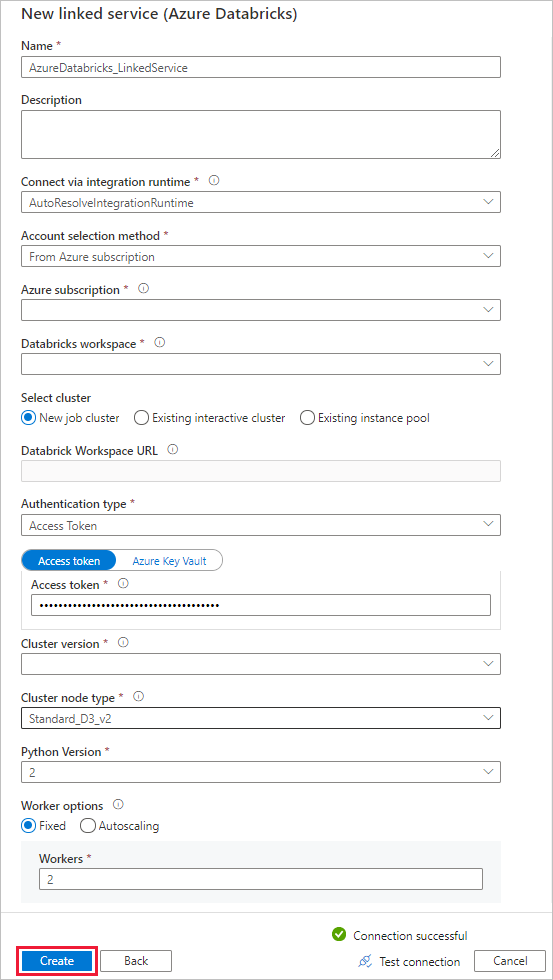
針對 [名稱],輸入 AzureDatabricks_LinkedService。
選取您將用來執行筆記本的適當 Databricks 工作區 。
針對 [選取叢集],選取 [新增作業叢集]。
針對 Databricks 工作區 URL,應該會自動填入資訊。
對於 Authentication Type,如果你選擇 Access Token,請從 Azure Databricks 平台生成該憑證。 您可以在這裡找到步驟。 對於管理服務身份及用戶指定的管理身份,請在Azure Databricks資源的存取控制選單中,授予兩個身份貢獻者角色。
針對 [叢集版本],選取您想要使用的版本。
在此教學課程中,針對 叢集節點類型,選擇在 一般用途 (HDD) 類別下的 Standard_D3_v2。
針對 工作者,輸入 2。
選擇 建立。
建立新管線
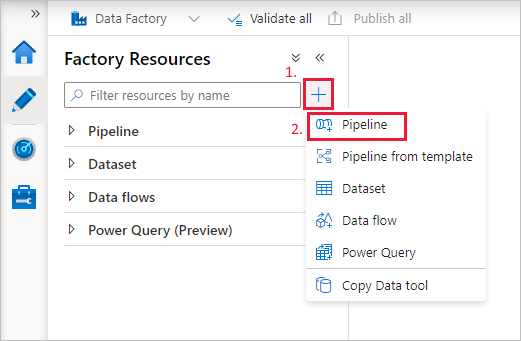
選取 + (加號) 按鈕,然後選取選單上的 管線。
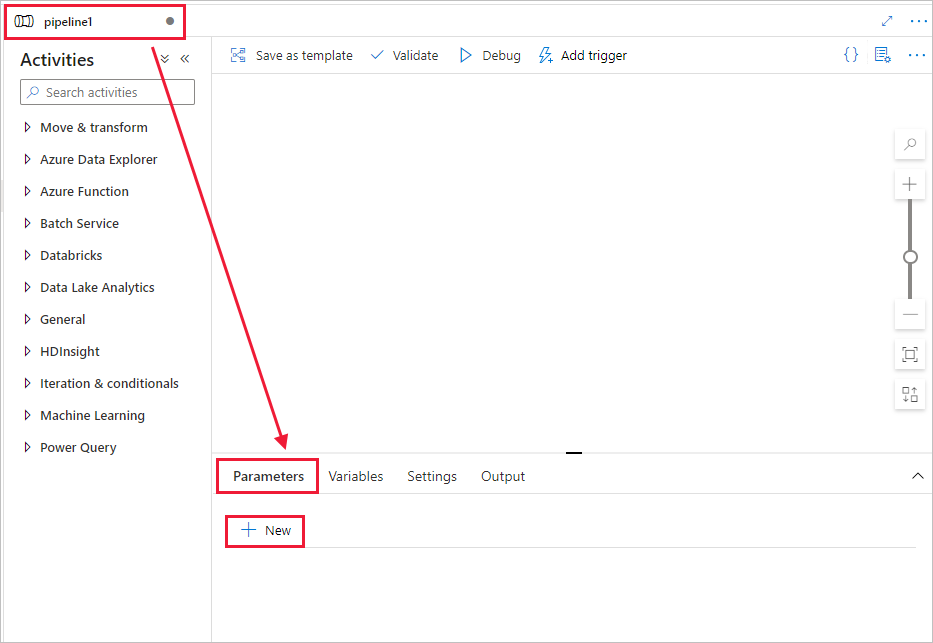
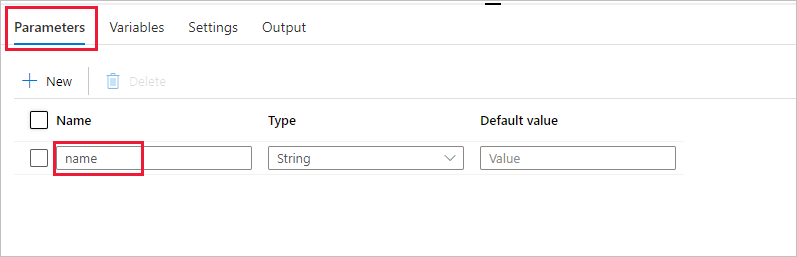
建立一個參數以用於管線。 稍後您會將此參數傳遞給 Databricks Notebook 活動。 在空的管線中,選取 [參數] 索引標籤,然後選取 [+ 新增],並將其命名為 'name'。
在活動工具箱中,展開Databricks。 將 Notebook 活動從 Activities 工具箱拖到管線設計工具介面。
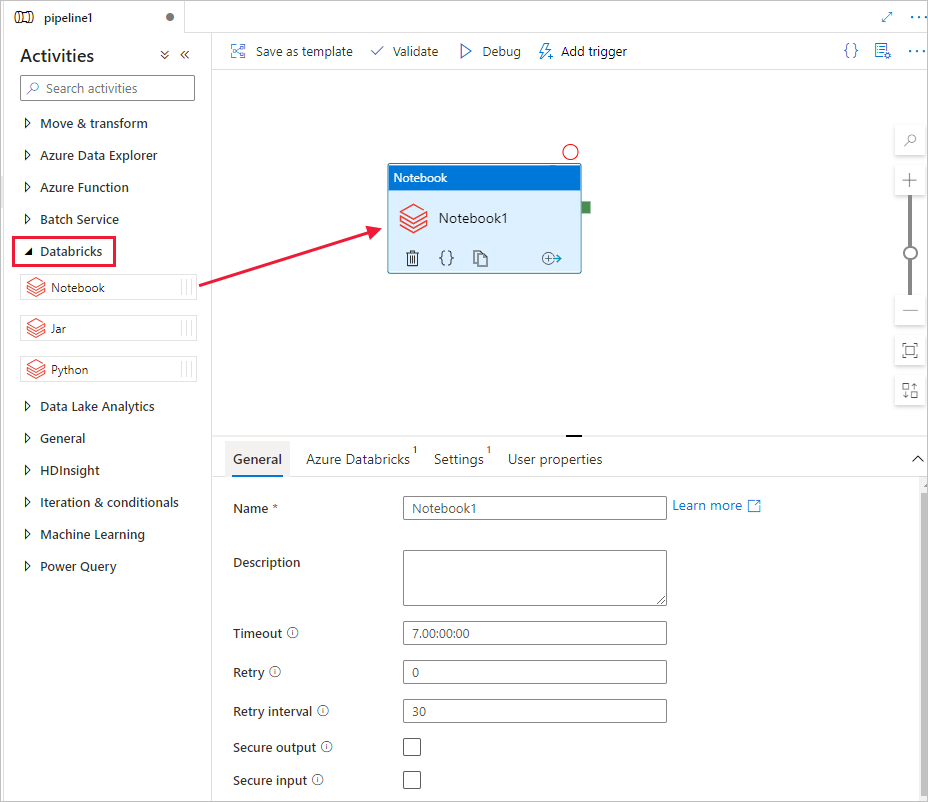
在底部的 DatabricksNotebook 活動視窗屬性中,完成下列步驟:
切換到Azure Databricks分頁。
選取 [AzureDatabricks_LinkedService] (已在上一個程序中建立)。
切換到 [設定] 索引標籤。
瀏覽以選取 Databricks 筆記本路徑。 讓我們建立 Notebook 並在此指定路徑。 您可以依照下列步驟取得 Notebook 路徑。
啟動你的 Azure Databricks 工作空間。
在工作區中建立新資料夾,並將它稱為 adftutorial。
建立新的筆記本,讓我們將其稱為 mynotebook。 以滑鼠右鍵按兩下 adftutorial 資料夾,然後選取 [ 建立]。
在新建立的筆記本 [mynotebook] 中,新增下列程式碼:
# Creating widgets for leveraging parameters, and printing the parameters dbutils.widgets.text("input", "","") y = dbutils.widgets.get("input") print ("Param -\'input':") print (y)在此案例中,[筆記本路徑] 是 /adftutorial/mynotebook。
切換回 Data Factory UI 撰寫工具。 瀏覽至 [Notebook1] 活動底下的 [設定] 索引標籤。
一。 新增參數至 Notebook 活動。 您可使用先前已新增到 [管線] 中的同一個參數。
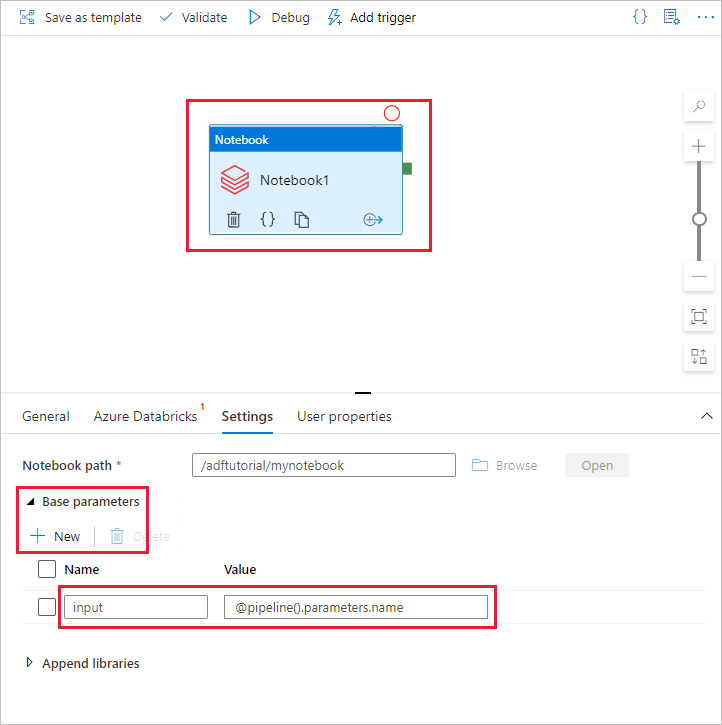
b。 將參數命名為 input,並以 @pipeline().parameters.name 運算式的形式提供值。
若要驗證管線,選取工具列上的 [驗證] 按鈕。 若要關閉驗證視窗,請選取 [關閉] 按鈕。
選擇全部發佈。 Data Factory 介面會將實體(連結服務與管線)發佈至 Azure Data Factory 服務。
觸發管線執行
選取工具列上的 [新增觸發程序],然後選取 [立即觸發]。
![顯示如何選取 [立即觸發] 命令的螢幕快照。](media/transform-data-using-databricks-notebook/databricks-notebook-activity-image-20.png)
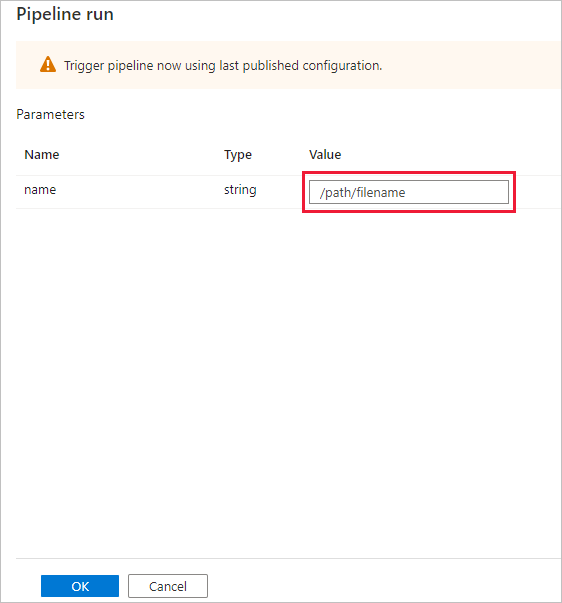
管線執行對話方塊會要求輸入name這個參數。 在此使用 /path/filename 作為參數。 選擇 [確定]。
監視管道運行
切換至 監視 索引標籤,確認您看到管道運行。 建立 Databricks 作業叢集約需 5 到 8 分鐘,系統會在該叢集上執行筆記本。
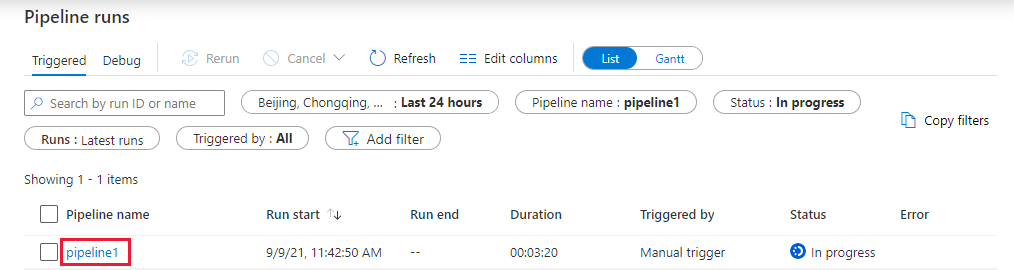
請定期選取 [重新整理] 以檢查管線運行狀態。
若要查看與管線執行相關聯的活動執行,請在管線名稱欄位下選取 pipeline1 連結。
在 [活動執行] 頁面中,選取 [活動名稱] 欄中的 [輸出] 以檢視每個活動的輸出,而您可以在 [輸出] 窗格中找到 Databricks 記錄的連結,以取得更詳細的 Spark 記錄。
您可以切換回管線執行檢視,請在頂端的階層連結功能表中,選取所有管線執行連結。
驗證輸出
你可以登入
您可以選取 [作業名稱 ],並流覽以查看進一步的詳細數據。 成功執行後,你可以驗證傳遞的參數以及 Python 筆記本的輸出。
摘要
此範例中的管線會觸發 Databricks Notebook 活動並將參數傳遞給它。 您已了解如何︰
建立資料處理站。
建立使用 Databricks 筆記本活動的管線。
觸發管線執行。
監視管道執行。