適用於: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
提示
試用 Microsoft Fabric 中的 Data Factory,這是適用於企業的全方位分析解決方案。 Microsoft Fabric 涵蓋從資料移動到資料科學、即時分析、商業智慧和報告的所有項目。 了解如何免費開始新的試用!
在本教學課程中,您會使用 Azure PowerShell 建立 Data Factory 管道,以在 Azure 虛擬網路 (VNet) 中的 HDInsight 叢集上,使用 Hive 活動來轉換資料。 您會在本教學課程中執行下列步驟:
- 建立資料處理站。
- 撰寫和設定自我裝載整合執行階段
- 撰寫和部署連結服務。
- 撰寫和部署包含 Hive 活動的管道。
- 啟動管線執行。
- 監視管道執行
- 驗證輸出。
如果您沒有 Azure 訂用帳戶,請在開始前建立免費帳戶。
必要條件
注意
建議您使用 Azure Az PowerShell 模組來與 Azure 互動。 若要開始使用,請參閱安裝 Azure PowerShell (部分機器翻譯)。 若要了解如何移轉至 Az PowerShell 模組,請參閱將 Azure PowerShell 從 AzureRM 移轉至 Az。
Azure 儲存體帳戶。 您會建立 hive 指令碼,並上傳至 Azure 儲存體。 Hive 指令碼的輸出會儲存在此儲存體帳戶中。 在此範例中,HDInsight 叢集會使用此 Azure 儲存體帳戶作為主要儲存體。
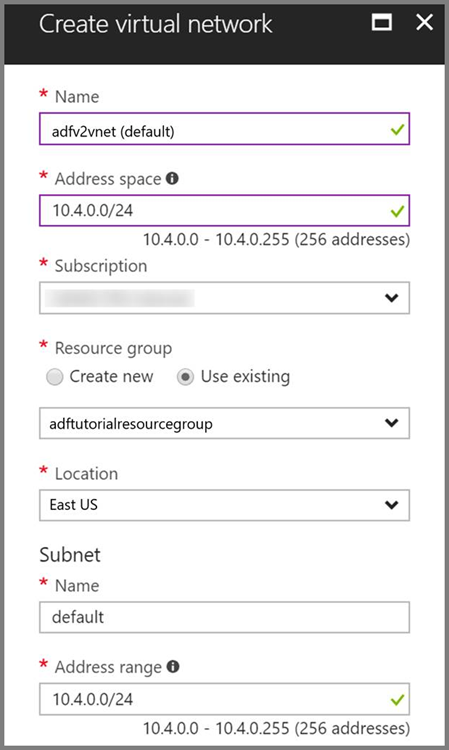
Azure 虛擬網路。 如果您沒有 Azure 虛擬網路,請依照這些指示建立。 在此範例中,HDInsight 在 Azure 虛擬網路中。 以下是 Azure 虛擬網路的設定範例。
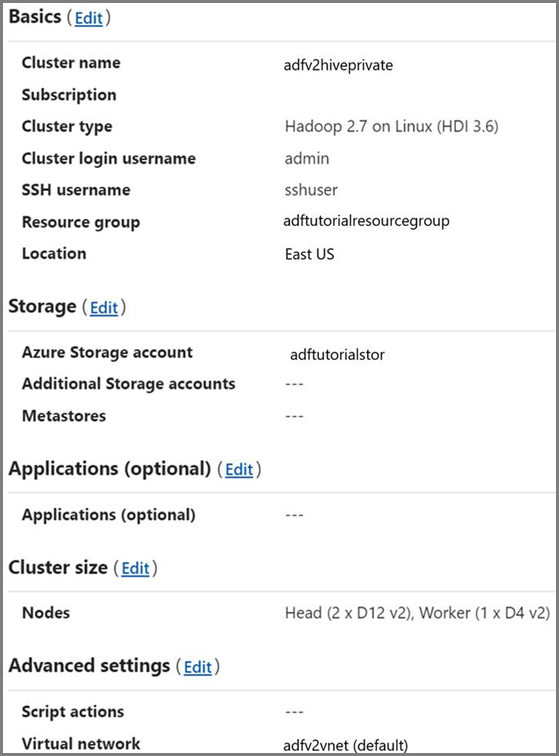
HDInsight 叢集。 請遵循這篇文章來建立 HDInsight 叢集,並將它加入您在上一個步驟中建立的虛擬網路:使用 Azure 虛擬網路延伸 Azure HDInsight。 以下是虛擬網路中的 HDInsight 設定範例。
Azure PowerShell。 遵循如何安裝並設定 Azure PowerShell 中的指示。
將 Hive 指令碼上傳至 Blob 儲存體帳戶
使用下列內容建立名為 hivescript.hql 的 Hive SQL 檔案:
DROP TABLE IF EXISTS HiveSampleOut; CREATE EXTERNAL TABLE HiveSampleOut (clientid string, market string, devicemodel string, state string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '${hiveconf:Output}'; INSERT OVERWRITE TABLE HiveSampleOut Select clientid, market, devicemodel, state FROM hivesampletable在 Azure Blob 儲存體中,建立名為 adftutorial 的容器 (如果不存在)。
建立名為 hivescripts 的資料夾。
將 hivescript.hql 檔案上傳至 hivescripts 子資料夾。
建立資料處理站
設定資源群組名稱。 在本教學課程進行期間,您會建立資源群組。 不過,如果您想要的話,也可以使用現有的資源群組。
$resourceGroupName = "ADFTutorialResourceGroup"指定 Data Factory 名稱。 必須是全域唯一的。
$dataFactoryName = "MyDataFactory09142017"指定管線的名稱。
$pipelineName = "MyHivePipeline" #指定自我裝載之整合執行階段的名稱。 當 Data Factory 需要存取 VNet 內部的資源 (例如 Azure SQL Database) 時,您必須有自我裝載的整合執行階段。
$selfHostedIntegrationRuntimeName = "MySelfHostedIR09142017"啟動 PowerShell。 保持開啟 Azure PowerShell,直到本快速入門結束為止。 如果您關閉並重新開啟,則需要再次執行這些命令。 如需目前可使用 Data Factory 的 Azure 區域清單,請在下列頁面上選取您感興趣的區域,然後展開 [分析] 以找出 [Data Factory]:依區域提供的產品。 資料處理站所使用的資料存放區 (Azure 儲存體、Azure SQL Database 等) 和計算 (HDInsight 等) 可位於其他區域。
執行下列命令,並輸入您用來登入 Azure 入口網站的使用者名稱和密碼:
Connect-AzAccount執行下列命令以檢視此帳戶的所有訂用帳戶:
Get-AzSubscription執行下列命令以選取您要使用的訂用帳戶。 以您的 Azure 訂用帳戶識別碼取代 SubscriptionId:
Select-AzSubscription -SubscriptionId "<SubscriptionId>"建立資源群組:ADFTutorialResourceGroup (如果尚不存在於訂用帳戶中)。
New-AzResourceGroup -Name $resourceGroupName -Location "East Us"建立資料處理站。
$df = Set-AzDataFactoryV2 -Location EastUS -Name $dataFactoryName -ResourceGroupName $resourceGroupName執行下列命令來查看輸出:
$df
建立自我裝載 IR
在本節中,您會建立自我裝載整合執行階段,並將它與 HDInsight 叢集所在的相同 Azure 虛擬網路中的 Azure VM 產生關聯。
建立自我裝載整合執行階段。 請使用唯一名稱,以防有另一個同名的整合執行階段存在。
Set-AzDataFactoryV2IntegrationRuntime -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -Name $selfHostedIntegrationRuntimeName -Type SelfHosted此命令會建立自我裝載整合執行階段的邏輯註冊。
使用 PowerShell 取出驗證金鑰,以註冊自我裝載整合執行階段。 複製其中一個金鑰,以註冊自我裝載整合執行階段。
Get-AzDataFactoryV2IntegrationRuntimeKey -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -Name $selfHostedIntegrationRuntimeName | ConvertTo-Json以下是範例輸出:
{ "AuthKey1": "IR@0000000000000000000000000000000000000=", "AuthKey2": "IR@0000000000000000000000000000000000000=" }請記下 AuthKey1 的值 (不含引號)。
建立 Azure VM,並將它加入您的 HDInsight 叢集所在的相同虛擬網路。 如需詳細資訊,請參閱如何建立虛擬機器。 將它們加入 Azure 虛擬網路。
在 Azure VM 上,下載自我裝載整合執行階段。 使用上一個步驟中取得的驗證金鑰,以手動註冊自我裝載整合執行階段。
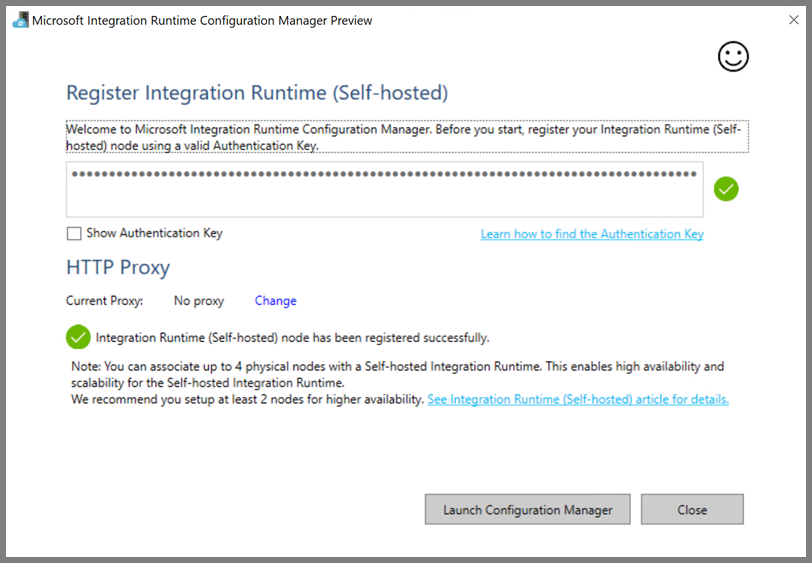
自我裝載整合執行階段註冊成功時,您會看到下列訊息:
當節點已連線至雲端服務時,您會看到下列頁面:
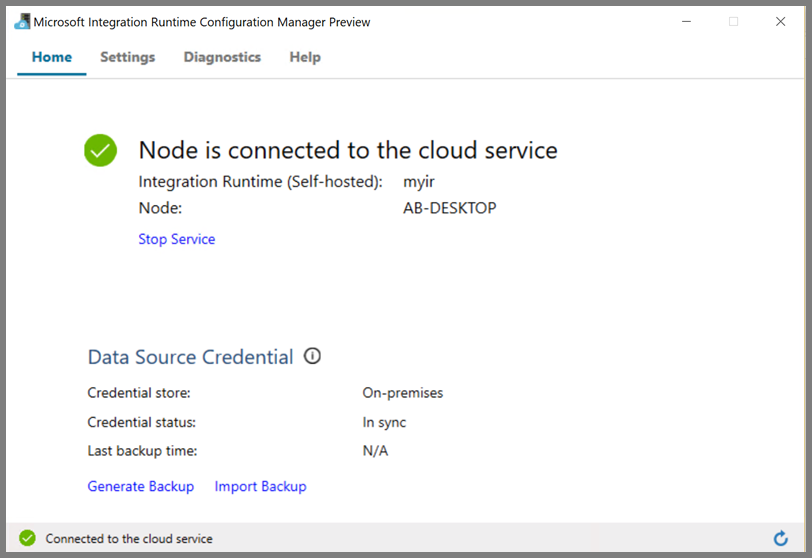
撰寫連結服務
在本節中,您會撰寫和部署兩個連結服務:
- 將 Azure 儲存體帳戶連結至資料處理站的 Azure 儲存體連結服務。 此儲存體是您的 HDInsight 叢集使用的主要儲存體。 在此案例中,我們也使用此 Azure 儲存體帳戶來保存 Hive 指令碼和指令碼的輸出。
- HDInsight 連結服務。 Azure Data Factory 會將 Hive 指令碼提交到此 HDInsight 叢集來執行。
Azure 儲存體連結服務
使用您慣用的編輯器建立 JSON 檔案、複製下列 Azure 儲存體連結服務的 JSON 定義,然後將檔案儲存為 MyStorageLinkedService.json。
{
"name": "MyStorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<storageAccountName>;AccountKey=<storageAccountKey>"
},
"connectVia": {
"referenceName": "MySelfhostedIR",
"type": "IntegrationRuntimeReference"
}
}
}
以您的 Azure 儲存體帳戶名稱和金鑰取代 <accountname> 和 <accountkey>。
HDInsight 連結服務
使用您慣用的編輯器建立 JSON 檔案、複製下列 Azure HDInsight 連結服務的 JSON 定義,然後將檔案儲存為 MyHDInsightLinkedService.json。
{
"name": "MyHDInsightLinkedService",
"properties": {
"type": "HDInsight",
"typeProperties": {
"clusterUri": "https://<clustername>.azurehdinsight.net",
"userName": "<username>",
"password": {
"value": "<password>",
"type": "SecureString"
},
"linkedServiceName": {
"referenceName": "MyStorageLinkedService",
"type": "LinkedServiceReference"
}
},
"connectVia": {
"referenceName": "MySelfhostedIR",
"type": "IntegrationRuntimeReference"
}
}
}
在連結服務定義中更新下列屬性的值:
userName。 您在建立叢集時指定的叢集登入使用者名稱。
password。 使用者的密碼。
clusterUri。 以下列格式指定 HDInsight 叢集的 URL:
https://<clustername>.azurehdinsight.net。 本文假設您可以透過網際網路存取此叢集。 例如,您可以連線至位於https://clustername.azurehdinsight.net的叢集。 這個位址使用公用閘道,但如果您已使用網路安全性群組 (NSG) 或使用者定義的路由 (UDR) 來禁止從網際網路存取,則無法使用此位址。 為了讓 Data Factory 能夠將作業提交至 Azure 虛擬網路中的 HDInsight 叢集,您需要設定 Azure 虛擬網路,使得 URL 可解析成 HDInsight 所使用之閘道的私人 IP 位址。從 Azure 入口網站,開啟 HDInsight 所在的虛擬網路。 開啟名稱開頭為
nic-gateway-0的網路介面。 記下其私人 IP 位址。 例如,10.6.0.15。如果您的 Azure 虛擬網路有 DNS 伺服器,請更新 DNS 記錄,以便 HDInsight 叢集 URL
https://<clustername>.azurehdinsight.net可解析成10.6.0.15。 這是建議的處理方式。 如果您的 Azure 虛擬網路中沒有 DNS 伺服器,您可以編輯所有已註冊為自我裝載整合執行階段節點之 VM 的 hosts 檔案 (C:\Windows\System32\drivers\etc),在檔案中新增如下項目,以解決這個問題:10.6.0.15 myHDIClusterName.azurehdinsight.net
建立連結服務
在 PowerShell 中,切換至您建立 JSON 檔案的資料夾,然後執行下列命令來部署連結服務:
在 PowerShell 中,切換至您建立 JSON 檔案的資料夾。
執行下列命令來建立 Azure 儲存體連結服務。
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "MyStorageLinkedService" -File "MyStorageLinkedService.json"執行下列命令來建立 Azure HDInsight 連結服務。
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "MyHDInsightLinkedService" -File "MyHDInsightLinkedService.json"
撰寫管道
在此步驟中,您會建立具有 Hive 活動的新管道。 此活動會執行 Hive 指令碼,以傳回範例資料表的資料,並儲存到您定義的路徑。 在您慣用的編輯器中建立 JSON 檔案、複製下列管道定義 JSON 定義,然後儲存為 MyHivePipeline.json。
{
"name": "MyHivePipeline",
"properties": {
"activities": [
{
"name": "MyHiveActivity",
"type": "HDInsightHive",
"linkedServiceName": {
"referenceName": "MyHDILinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"scriptPath": "adftutorial\\hivescripts\\hivescript.hql",
"getDebugInfo": "Failure",
"defines": {
"Output": "wasb://<Container>@<StorageAccount>.blob.core.windows.net/outputfolder/"
},
"scriptLinkedService": {
"referenceName": "MyStorageLinkedService",
"type": "LinkedServiceReference"
}
}
}
]
}
}
請注意下列幾點:
- scriptPath 指向您用於 MyStorageLinkedService 的 Azure 儲存體帳戶上的 Hive 指令碼路徑。 路徑會區分大小寫。
-
Output 是 Hive 指令碼中使用的引數。 請使用
wasb://<Container>@<StorageAccount>.blob.core.windows.net/outputfolder/格式,以指向您的 Azure 儲存體上現有的資料夾。 路徑會區分大小寫。
切換至您建立 JSON 檔案的資料夾,然後執行下列命令來部署管道:
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name $pipelineName -File "MyHivePipeline.json"
啟動管道
啟動管線執行。 它也會擷取管線執行識別碼,方便後續監視。
$runId = Invoke-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -PipelineName $pipelineName執行下列程式碼以持續檢查管道執行狀態,直到完成為止。
while ($True) { $result = Get-AzDataFactoryV2ActivityRun -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -PipelineRunId $runId -RunStartedAfter (Get-Date).AddMinutes(-30) -RunStartedBefore (Get-Date).AddMinutes(30) if(!$result) { Write-Host "Waiting for pipeline to start..." -foregroundcolor "Yellow" } elseif (($result | Where-Object { $_.Status -eq "InProgress" } | Measure-Object).count -ne 0) { Write-Host "Pipeline run status: In Progress" -foregroundcolor "Yellow" } else { Write-Host "Pipeline '"$pipelineName"' run finished. Result:" -foregroundcolor "Yellow" $result break } ($result | Format-List | Out-String) Start-Sleep -Seconds 15 } Write-Host "Activity `Output` section:" -foregroundcolor "Yellow" $result.Output -join "`r`n" Write-Host "Activity `Error` section:" -foregroundcolor "Yellow" $result.Error -join "`r`n"執行範例的輸出如下:
Pipeline run status: In Progress ResourceGroupName : ADFV2SampleRG2 DataFactoryName : SampleV2DataFactory2 ActivityName : MyHiveActivity PipelineRunId : 000000000-0000-0000-000000000000000000 PipelineName : MyHivePipeline Input : {getDebugInfo, scriptPath, scriptLinkedService, defines} Output : LinkedServiceName : ActivityRunStart : 9/18/2017 6:58:13 AM ActivityRunEnd : DurationInMs : Status : InProgress Error : Pipeline ' MyHivePipeline' run finished. Result: ResourceGroupName : ADFV2SampleRG2 DataFactoryName : SampleV2DataFactory2 ActivityName : MyHiveActivity PipelineRunId : 0000000-0000-0000-0000-000000000000 PipelineName : MyHivePipeline Input : {getDebugInfo, scriptPath, scriptLinkedService, defines} Output : {logLocation, clusterInUse, jobId, ExecutionProgress...} LinkedServiceName : ActivityRunStart : 9/18/2017 6:58:13 AM ActivityRunEnd : 9/18/2017 6:59:16 AM DurationInMs : 63636 Status : Succeeded Error : {errorCode, message, failureType, target} Activity Output section: "logLocation": "wasbs://adfjobs@adfv2samplestor.blob.core.windows.net/HiveQueryJobs/000000000-0000-47c3-9b28-1cdc7f3f2ba2/18_09_2017_06_58_18_023/Status" "clusterInUse": "https://adfv2HivePrivate.azurehdinsight.net" "jobId": "job_1505387997356_0024" "ExecutionProgress": "Succeeded" "effectiveIntegrationRuntime": "MySelfhostedIR" Activity Error section: "errorCode": "" "message": "" "failureType": "" "target": "MyHiveActivity"在
outputfolder資料夾中,檢查 Hive 查詢結果所建立的新檔案,看起來應該如下列範例輸出:8 en-US SCH-i500 California 23 en-US Incredible Pennsylvania 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 246 en-US SCH-i500 District Of Columbia 246 en-US SCH-i500 District Of Columbia
相關內容
在本教學課程中,您已執行下列步驟:
- 建立資料處理站。
- 撰寫和設定自我裝載整合執行階段
- 撰寫和部署連結服務。
- 撰寫和部署包含 Hive 活動的管道。
- 啟動管線執行。
- 監視管道執行
- 驗證輸出。
進入下列教學課程,以了解如何在 Azure 上使用 Spark 叢集來轉換資料: