使用 Azure Databricks 上的檔案
Azure Databricks 提供多個公用程序和 API,以便與下列位置中的檔案互動:
- Unity 目錄磁碟區
- 工作區檔案
- 雲端物件儲存體
- DBFS 掛接和 DBFS 根目錄
- 附加至叢集驅動程序節點的暫時記憶體
本文提供下列工具在這些位置中與檔案互動的範例:
- Apache Spark
- Spark SQL 和 Databricks SQL
- Databricks 文件系統 utitlities (
dbutils.fs或%fs) - Databricks CLI
- Databricks REST API
- Bash 殼層指令 (
%sh) - 使用 安裝筆記本範圍的連結庫
%pip - Pandas
- OSS Python 檔案管理和處理公用程式
重要
需要 FUSE 存取資料的檔案作業無法使用 URI 直接存取雲端物件記憶體。 Databricks 建議使用 Unity 目錄磁碟區來設定 FUSE 這些位置的存取權。
Scala 不支援 UNITY 目錄磁碟區或工作區檔案的 FUSE,其計算是以沒有 Unity 目錄的單一使用者存取模式或叢集所設定。 Scala 支援在以 Unity 目錄和共用存取模式設定的計算上,針對 Unity 目錄磁碟區和工作區檔案使用 FUSE。
我需要提供 URI 配置來存取資料嗎?
Azure Databricks 中的數據存取路徑遵循下列其中一個標準:
URI 樣式路徑 包含URI配置。 針對 Databricks 原生數據存取解決方案,在大部分使用案例中,URI 配置都是選擇性的。 當您直接存取雲端物件記憶體中的數據時,您必須為記憶體類型提供正確的 URI 配置。
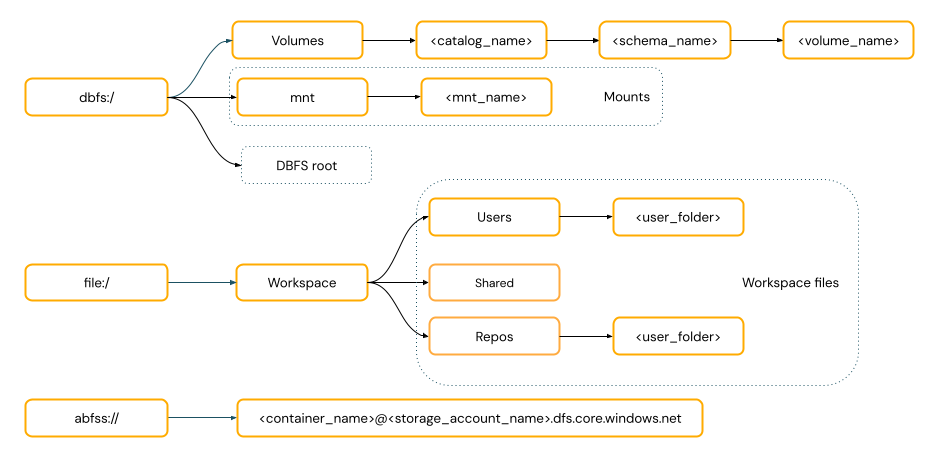
POSIX 樣式路徑 會提供相對於驅動程式根目錄的數據存取權(
/)。 POSIX 樣式的路徑永遠不需要配置。 您可以使用 Unity 目錄磁碟區或 DBFS 掛接,提供 POSIX 樣式存取雲端物件記憶體中的數據。 許多 ML 架構和其他 OSS Python 模組都需要 FUSE,而且只能使用 POSIX 樣式的路徑。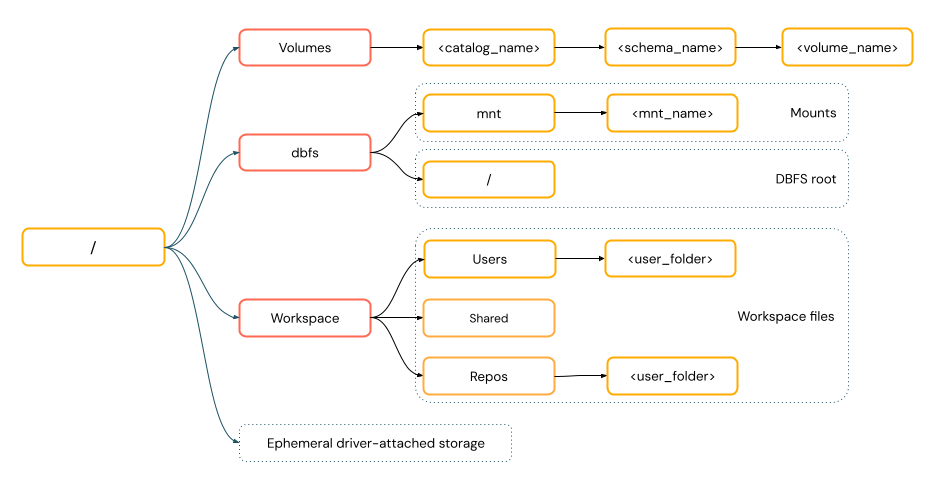
使用 Unity 目錄磁碟區中的檔案
Databricks 建議使用 Unity 目錄磁碟區來設定存取儲存在雲端物件記憶體中的非表格式數據檔。 請參閱 建立和使用磁碟區。
| 工具 | 範例 |
|---|---|
| Apache Spark | spark.read.format("json").load("/Volumes/my_catalog/my_schema/my_volume/data.json").show() |
| Spark SQL 和 Databricks SQL | SELECT * FROM csv.`/Volumes/my_catalog/my_schema/my_volume/data.csv`; LIST '/Volumes/my_catalog/my_schema/my_volume/'; |
| Databricks 檔案系統公用程式 | dbutils.fs.ls("/Volumes/my_catalog/my_schema/my_volume/") %fs ls /Volumes/my_catalog/my_schema/my_volume/ |
| Databricks CLI | databricks fs cp /path/to/local/file dbfs:/Volumes/my_catalog/my_schema/my_volume/ |
| Databricks REST API | POST https://<databricks-instance>/api/2.1/jobs/create {"name": "A multitask job", "tasks": [{..."libraries": [{"jar": "/Volumes/dev/environment/libraries/logging/Logging.jar"}],},...]} |
| Bash 殼層命令 | %sh curl http://<address>/text.zip -o /Volumes/my_catalog/my_schema/my_volume/tmp/text.zip |
| 連結庫安裝 | %pip install /Volumes/my_catalog/my_schema/my_volume/my_library.whl |
| Pandas | df = pd.read_csv('/Volumes/my_catalog/my_schema/my_volume/data.csv') |
| OSS Python | os.listdir('/Volumes/my_catalog/my_schema/my_volume/path/to/directory') |
注意
使用 dbfs:/ Databricks CLI 時需要架構。
磁碟區限制
磁碟區有下列限制:
不支援直接附加或非循序(隨機)寫入,例如寫入 Zip 和 Excel 檔案。 針對直接附加或隨機寫入工作負載,請先在本機磁碟上執行作業,然後將結果複製到 Unity 目錄磁碟區。 例如:
# python import xlsxwriter from shutil import copyfile workbook = xlsxwriter.Workbook('/local_disk0/tmp/excel.xlsx') worksheet = workbook.add_worksheet() worksheet.write(0, 0, "Key") worksheet.write(0, 1, "Value") workbook.close() copyfile('/local_disk0/tmp/excel.xlsx', '/Volumes/my_catalog/my_schema/my_volume/excel.xlsx')不支援疏鬆檔案。 若要複製疏鬆檔案, 請使用
cp --sparse=never:$ cp sparse.file /Volumes/my_catalog/my_schema/my_volume/sparse.file error writing '/dbfs/sparse.file': Operation not supported $ cp --sparse=never sparse.file /Volumes/my_catalog/my_schema/my_volume/sparse.file
使用工作區檔案
Databricks 工作區檔案 是工作區中不是筆記本的檔案集。 您可以使用工作區檔案來儲存和存取與筆記本和其他工作區資產一起儲存的數據和其他檔案。 因為工作區檔案有大小限制,Databricks 建議只在這裡儲存小型數據檔,主要是用於開發和測試。
| 工具 | 範例 |
|---|---|
| Apache Spark | spark.read.format("json").load("file:/Workspace/Users/<user-folder>/data.json").show() |
| Spark SQL 和 Databricks SQL | SELECT * FROM json.`file:/Workspace/Users/<user-folder>/file.json`; |
| Databricks 檔案系統公用程式 | dbutils.fs.ls("file:/Workspace/Users/<user-folder>/") %fs ls file:/Workspace/Users/<user-folder>/ |
| Databricks CLI | databricks workspace list |
| Databricks REST API | POST https://<databricks-instance>/api/2.0/workspace/delete {"path": "/Workspace/Shared/code.py", "recursive": "false"} |
| Bash 殼層命令 | %sh curl http://<address>/text.zip -o /Workspace/Users/<user-folder>/text.zip |
| 連結庫安裝 | %pip install /Workspace/Users/<user-folder>/my_library.whl |
| Pandas | df = pd.read_csv('/Workspace/Users/<user-folder>/data.csv') |
| OSS Python | os.listdir('/Workspace/Users/<user-folder>/path/to/directory') |
注意
使用 file:/ Databricks Utilities、Apache Spark 或 SQL 時,需要架構。
工作區檔案限制
工作區檔案有下列限制:
工作區檔案大小限制為UI的500 MB。 從叢集寫入時允許的檔案大小上限為 256 MB。
如果您的工作流程使用位於遠端 Git 存放庫的原始程式碼,則您無法使用相對路徑寫入目前目錄或寫入。 將數據寫入其他位置選項。
當您儲存至工作區檔案時,無法使用
git命令。 工作區檔案中不允許建立.git目錄。無伺服器計算對工作區檔案作業的支援有限。
執行程式無法寫入工作區檔案。
不支援符號連結。
刪除的工作區檔案會移至何處?
刪除工作區檔案會將它傳送至垃圾桶。 您可以使用 UI 從回收站復原或永久刪除檔案。
請參閱 刪除物件。
使用雲端物件記憶體中的檔案
Databricks 建議使用 Unity 目錄磁碟區來設定雲端物件記憶體中檔案的安全存取。 如果您選擇使用 URI 直接存取雲端物件記憶體中的數據,您必須設定許可權。 請參閱 管理外部位置、外部數據表和外部磁碟區。
下列範例使用 URI 來存取雲端物件記憶體中的資料:
| 工具 | 範例 |
|---|---|
| Apache Spark | spark.read.format("json").load("abfss://container-name@storage-account-name.dfs.core.windows.net/path/file.json").show() |
| Spark SQL 和 Databricks SQL | SELECT * FROM csv.`abfss://container-name@storage-account-name.dfs.core.windows.net/path/file.json`; LIST 'abfss://container-name@storage-account-name.dfs.core.windows.net/path'; |
| Databricks 檔案系統公用程式 | dbutils.fs.ls("abfss://container-name@storage-account-name.dfs.core.windows.net/path/") %fs ls abfss://container-name@storage-account-name.dfs.core.windows.net/path/ |
| Databricks CLI | 不支援 |
| Databricks REST API | 不支援 |
| Bash 殼層命令 | 不支援 |
| 連結庫安裝 | %pip install abfss://container-name@storage-account-name.dfs.core.windows.net/path/to/library.whl |
| Pandas | 不支援 |
| OSS Python | 不支援 |
注意
雲端物件記憶體不支援認證傳遞。
使用 DBFS 掛接和 DBFS 根目錄中的檔案
DBFS 掛接不是使用 Unity 目錄的安全性實體,而且 Databricks 已不再建議使用。 儲存在 DBFS 根目錄中的數據可供工作區中的所有使用者存取。 Databricks 建議將任何敏感性或生產程式代碼或數據儲存在 DBFS 根目錄中。 請參閱 什麼是 Databricks 檔案系統 (DBFS)?。
| 工具 | 範例 |
|---|---|
| Apache Spark | spark.read.format("json").load("/mnt/path/to/data.json").show() |
| Spark SQL 和 Databricks SQL | SELECT * FROM json.`/mnt/path/to/data.json`; |
| Databricks 檔案系統公用程式 | dbutils.fs.ls("/mnt/path") %fs ls /mnt/path |
| Databricks CLI | databricks fs cp dbfs:/mnt/path/to/remote/file /path/to/local/file |
| Databricks REST API | POST https://<host>/api/2.0/dbfs/delete --data '{ "path": "/tmp/HelloWorld.txt" }' |
| Bash 殼層命令 | %sh curl http://<address>/text.zip > /dbfs/mnt/tmp/text.zip |
| 連結庫安裝 | %pip install /dbfs/mnt/path/to/my_library.whl |
| Pandas | df = pd.read_csv('/dbfs/mnt/path/to/data.csv') |
| OSS Python | os.listdir('/dbfs/mnt/path/to/directory') |
注意
使用 dbfs:/ Databricks CLI 時需要架構。
使用附加至驅動程序節點的暫時記憶體中的檔案
連結至驅動程序節點的 ephermal 記憶體是使用原生 POSIX 型路徑存取的區塊記憶體。 當叢集終止或重新啟動時,儲存在此位置的任何數據都會消失。
| 工具 | 範例 |
|---|---|
| Apache Spark | 不支援 |
| Spark SQL 和 Databricks SQL | 不支援 |
| Databricks 檔案系統公用程式 | dbutils.fs.ls("file:/path") %fs ls file:/path |
| Databricks CLI | 不支援 |
| Databricks REST API | 不支援 |
| Bash 殼層命令 | %sh curl http://<address>/text.zip > /tmp/text.zip |
| 連結庫安裝 | 不支援 |
| Pandas | df = pd.read_csv('/path/to/data.csv') |
| OSS Python | os.listdir('/path/to/directory') |
注意
使用 file:/ Databricks Utilities 時需要架構。
將數據從暫時記憶體移至磁碟區
您可能想要使用 Apache Spark 存取下載或儲存至暫時記憶體的數據。 因為暫時記憶體會連結至驅動程式,而Spark是分散式處理引擎,並非所有作業都可以直接存取此處的數據。 如果您需要將數據從驅動程式檔案系統移至 Unity 目錄磁碟區,您可以使用 magic 命令或 Databricks 公用程式來複製檔案,如下列範例所示:
dbutils.fs.cp ("file:/<path>", "/Volumes/<catalog>/<schema>/<volume>/<path>")
%sh cp /<path> /Volumes/<catalog>/<schema>/<volume>/<path>
%fs cp file:/<path> /Volumes/<catalog>/<schema>/<volume>/<path>
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應