本頁說明如何在 Databricks 筆記本中開發程式碼,包括程式碼格式化、自動補全、混合語言及魔法指令。
如需編輯器可用之進階功能的詳細資訊,例如自動完成、變數選取、多數據指標支援和並存差異,請參閱 流覽 Databricks 筆記本和檔案編輯器。
當你使用筆記本或檔案編輯器時,Genie Code 可以協助你產生、解釋和除錯程式碼。 更多資訊請參見 使用精靈代碼 。
Databricks 筆記本也內建 Python 筆記本的互動式除錯器。 請參閱 調試筆記本。
重要
筆記本必須連接到活躍的 compute session,才能獲得程式碼輔助功能,包括自動補全、Python程式碼格式化及除錯器。
模組化程式碼
使用 Databricks Runtime 11.3 LTS 及以上版本,你可以在 Azure Databricks 工作區建立和管理原始碼檔案,然後視需要將這些檔案匯入筆記本。
欲了解更多關於原始碼檔案的操作資訊,請參閱 在 Databricks 筆記本間共享程式碼 及 使用 Python 和 R 模組。
格式化程式碼儲存格
Azure Databricks 提供工具,讓你能在筆記本儲存格中格式化 Python 和 SQL 程式碼。 這些工具可減少將程式碼格式化的工作,並協助在您的筆記本中強制執行相同的編碼標準。
Python 黑色格式化器函式庫
重要
這項功能處於 公開預覽狀態。
Azure Databricks 支援在筆記本內使用black來格式化 Python 程式碼。 筆記型電腦必須連接到安裝有 black 和 tokenize-rt Python 套件的叢集。
在 Databricks 11.3 LTS 及以上版本中,Azure Databricks預裝了 black 和 tokenize-rt。 您可以直接使用格式器,不需要安裝這些程式庫。
在 Databricks Runtime 10.4 LTS 及以下版本中,您必須在筆記型電腦或叢集上安裝 black==22.3.0 和 tokenize-rt==4.2.1,才能使用 Python 格式化器。 您可以在筆記本中執行下列命令:
%pip install black==22.3.0 tokenize-rt==4.2.1
或 在您的叢集上安裝程式庫。
欲了解更多安裝函式庫的細節,請參見 Python environment management。
對於 Databricks Git 資料夾中的檔案和筆記本,你可以根據 pyproject.toml 檔案來設定 Python 格式化器。 若要使用此功能,請在 Git 資料夾根目錄中建立檔案 pyproject.toml ,並根據 Black 組態格式進行設定。 編輯檔案中的 [tool.black] 區段。 當您格式化該 Git 資料夾中的任何檔案和筆記本時,設定即會套用。
如何格式化Python與 SQL 儲存格
您必須擁有筆記本的 CAN EDIT 許可權 ,才能格式化程式代碼。
Azure Databricks 使用自訂的 SQL 排版器來格式化 SQL,並使用 black 作為 Python 的程式碼排版器。
您可以透過下列方式啟動格式器:
格式化單一儲存格
格式化多個儲存格
選取多個儲存格,然後選取 [編輯>格式儲存格]。 如果你選擇多種語言的儲存格,只有 SQL 和 Python 儲存格會被格式化。 這包括使用
%sql和%python的。格式化筆記本中的所有Python和 SQL 儲存格
選取 [編輯 > 格式筆記本]。 如果你的筆記本包含多種語言,只有 SQL 和 Python 儲存格會被格式化。 這包括使用
%sql和%python的。
若要自定義 SQL 查詢格式化方式,請參閱 自定義格式 SQL 語句。
程式碼格式化限制
- Black 會強制執行 4 個空間縮排的 PEP 8 標準。 縮排設定無法調整。
- 不支援在 SQL UDF 中格式化嵌入的 Python 字串。 同樣地,Python UDF 中不支援格式化 SQL 字串。
筆記本中的程式碼語言
設定預設語言
筆記本的默認語言會出現在筆記本名稱下方。

若要變更默認語言,請按下語言按鈕,然後從下拉功能表中選取新語言。 為了確保現有指令能夠繼續運作,先前預設語言的指令會自動加上語言魔術指令的前綴。
混合語言
根據預設,儲存格會使用筆記本的預設語言。 您可以按下語言按鈕,然後從下拉式功能表中選取語言,以覆寫儲存格中的預設語言。
或者,你也可以在儲存格開頭使用語言魔法指令 %<language> 。 支援的魔術命令包括: %python、%r、%scala 和 %sql。
注意
當您叫用語言相關特殊命令時,該命令會被分派至筆記本的執行環境中的 REPL。 以一種語言定義的變數 (因此在該語言的 REPL 中) 在另一種語言的 REPL 中不可用。 REPL 只能透過外部資源分享狀態,例如 DBFS 中的檔案或物件儲存體中的物件。
筆記本也支援一些輔助魔術命令:
-
%sh:可讓您在筆記本中執行 shell 程式碼。 如果 shell 命令的退出狀态是非零,若要使儲存格失敗,請使用新增選項-e。 此命令僅在 Apache Spark 驅動程式上執行,而不會在工作節點上執行。 若要在所有節點上執行 Shell 命令,請使用 init 腳本。 -
%fs:可讓您使用dbutils檔案系統命令。 例如,若要執行dbutils.fs.ls命令來列出檔案,您可以改為指定%fs ls。 更多資訊請參見 在 Azure Databricks 上處理檔案。 -
%md:可讓您包括各種類型的文件,包括文字、影像,以及數學公式和方程式。 請參閱下一節。
SQL 語法高亮顯示與 Python 指令中的自動補全功能
當你在 Python 指令中使用 SQL,例如 指令時,語法高亮和 SQL spark.sql 可以使用。
探索 SQL 儲存格結果
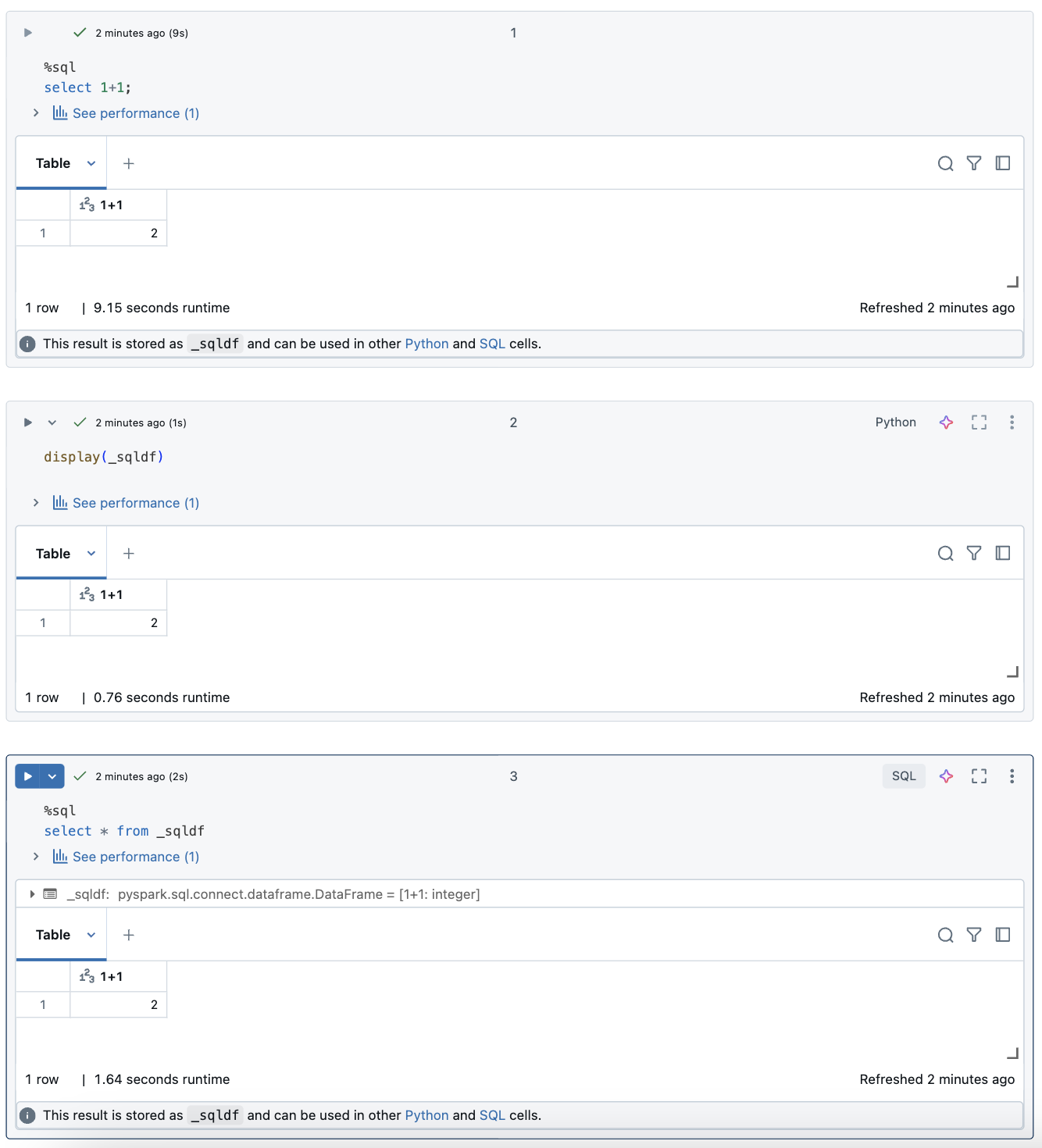
在 Databricks 筆記本中,SQL 語言數據格的結果會自動以指派給變數 _sqldf的隱含 DataFrame 形式提供。 接著你可以在之後執行的任何 Python 和 SQL 儲存格中使用這個變數,不論它們在筆記本中的位置如何。
注意
這項功能有下列限制:
- 變數
_sqldf不適用於使用 SQL 倉儲 進行計算的筆記本。 - 在 Databricks 執行時 13.3 及以上版本中,支援在後續的 Python 儲存格中使用
_sqldf。 - 只有在 Databricks Runtime 14.3 和更新版本中才支援在後續的 SQL 資料儲存格中使用
_sqldf。 - 如果查詢使用 關鍵詞
CACHE TABLE或UNCACHE TABLE,則_sqldf無法使用 變數。
下方截圖顯示 _sqldf 如何在後續的 Python 和 SQL 儲存格中使用:
重要
每次執行 SQL 數據格時,變數 _sqldf 都會重新指派。 若要避免遺失特定 DataFrame 結果的參考,請在執行下一個 SQL 數據格之前,將它指派給新的變數名稱:
Python
new_dataframe_name = _sqldf
SQL
ALTER VIEW _sqldf RENAME TO new_dataframe_name
平行執行 SQL 儲存格
當命令正在執行,且筆記本已連結至互動式叢集時,可以使用目前的命令同時執行 SQL 儲存格。 SQL 儲存格在新的平行工作階段中執行。
要平行運行一個單元:
按下 [立即執行]。 程式區塊會立即執行。
由於該單元在新會話中執行,暫時視圖、UDF,以及隱式 Python DataFrame()對於平行執行的單元不被支援。 此外,在平行執行期間會使用預設目錄和資料庫名稱。 如果您的程式代碼參考不同目錄或資料庫中的數據表,您必須使用三層命名空間來指定數據表名稱(catalog.schema.table)。
在 SQL 倉庫上執行 SQL 儲存格
您可以在 SQL 倉儲的 Databricks 筆記本中執行 SQL 命令,這是針對 SQL 分析優化的計算類型。 請參閱 搭配 SQL 倉儲使用筆記本。
使用魔術指令
Databricks 筆記本支援各種魔術命令,可將功能延伸至標準語法之外,以簡化一般工作。 行魔法以 % 作為前綴並適用於單行。 細胞魔法以「前綴 %% 」為前綴,並適用於整個細胞體。
| 魔法命令 | 範例 | 說明 |
|---|---|---|
%python |
%pythonprint("Hello") |
切換 cell 語言到 Python。 在儲存格中執行 Python 程式碼。 |
%r |
%rprint("Hello") |
將儲存格語言切換為 R。在儲存格中執行 R 程式碼。 |
%scala |
%scalaprintln("Hello") |
將儲存格語言切換為 Scala。 在儲存格中執行 Scala 程式碼。 |
%sql |
%sqlSELECT * FROM table |
將儲存格語言切換為 SQL。 結果以 _sqldf 格式在 Python/SQL 儲存格中提供。 |
%md |
%md# TitleContent here |
將儲存格語言切換為 Markdown。 在儲存格中呈現 Markdown 內容。 支持文本、圖像、公式和 LaTeX。 |
%pip |
%pip install pandas |
安裝 Python 套件(筆記本範圍)。 請參見 Notebook-scoped Python libraries。 |
%run |
%run /path/to/notebook |
執行另一個筆記本,匯入其函數和變數。 請參閱 筆記本工作流程。 |
%fs |
%fs ls /path |
執行 dbutils 檔案系統命令。
dbutils.fs 命令的簡寫。 請參閱 使用檔案。 |
%sh |
%sh ls -la |
執行 shell 命令。 僅在驅動程式節點上執行。 使用 -e 在錯誤時失敗。 |
%tensorboard |
%tensorboard --logdir /logs |
在介面中顯示 TensorBoard UI。 僅適用於 Databricks Runtime ML。 請參閱 TensorBoard。 |
%set_cell_max_output_size_in_mb |
%set_cell_max_output_size_in_mb 10 |
設定儲存格輸出大小上限。 範圍:1-20 MB。 套用至筆記本中的所有後續儲存格。 |
%skip |
%skipprint("This won't run") |
跳過儲存格執行。 防止筆記本執行時儲存格運行。 |
%%profile |
%%profilemy_function() |
分析 Python 程式碼執行。 顯示階層呼叫樹及時間資訊。 需要 Databricks 執行時間 17.2 及以上。 |
%%oprofile |
%%oprofilemy_function() |
在儲存格執行時建立設定檔物件。 顯示一個按類型分組的淨增新物件表。 需要 Databricks 執行時間 17.2 及以上。 |
注意
IPython Automagic:Databricks 筆記本預設啟用了 IPython automagic,讓某些命令,例如 pip,在無需加上 % 前綴下即可運行。 例如, pip install pandas 工作原理與 %pip install pandas相同。
重要
- 變數和狀態在不同語言的 REPL 之間隔離。 例如,Python 變數無法在 Scala 儲存格中存取。
- 一個筆記本儲存格只能有一個儲存格魔術指令,而且必須是儲存格的第一行。
-
%run必須單獨位於儲存格中,因為它會線上執行整個筆記本。 - 在 Databricks Runtime 12.2 LTS 及以下版本使用
%pip時,請將所有套件安裝指令放在筆記本的開頭,因為安裝後 Python 狀態會被重置。