本文說明如何使用馬賽克 AI 向量搜尋 建立及查詢向量搜尋索引。
您可以使用UI、Python SDK,或 REST API來建立和管理向量搜尋元件,例如向量搜尋端點和向量搜尋索引。
要求
- 已啟用 Unity Catalog 的工作區。
- 已啟用無伺服器計算。 如需說明,請參閱 連線到無伺服器計算。
- 針對 標準端點,源表必須啟用變更資料饋入。 請參閱 在 Azure Databricks 上使用 Delta Lake 變更數據饋送。
- 若要建立向量搜尋索引,您必須在建立索引的目錄架構上擁有 CREATE TABLE 許可權。
- 若要查詢其他使用者擁有的索引,您必須擁有額外的許可權。 請參閱 查詢向量搜尋端點。
使用訪問控制清單來設定建立和管理向量搜尋端點的許可權。 請參閱 向量搜尋端點 ACL。
安裝
若要使用向量搜尋 SDK,您必須在筆記本中安裝它。 使用下列程式代碼來安裝套件:
%pip install databricks-vectorsearch
dbutils.library.restartPython()
然後使用下列命令匯入 VectorSearchClient:
from databricks.vector_search.client import VectorSearchClient
認證
請參閱 資料保護和驗證。
建立向量搜尋端點
您可以使用 Databricks UI、Python SDK 或 API 來建立向量搜尋端點。
使用UI建立向量搜尋端點
請遵循下列步驟,使用UI建立向量搜尋端點。
在左側邊欄中,點擊 [計算]。
點選 向量搜尋 標籤,然後點擊 建立。
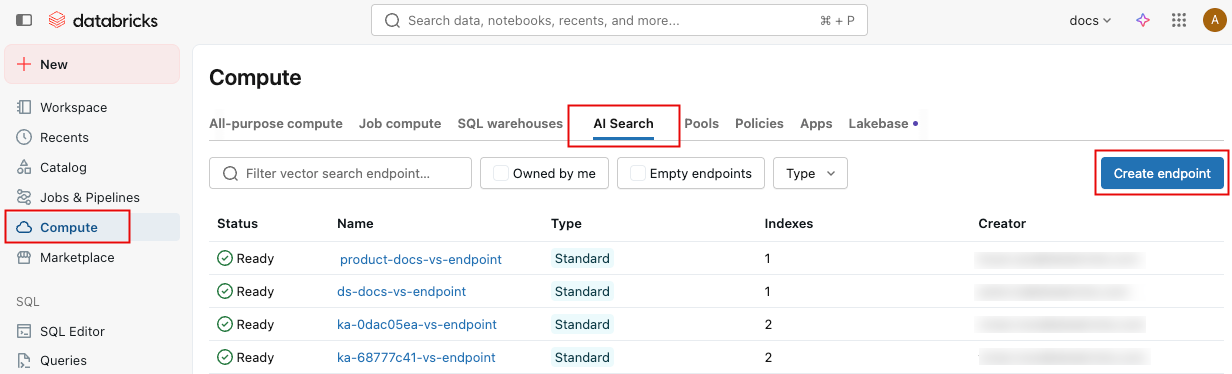
[建立端點] 表單 隨即開啟。 輸入此端點的名稱。
在 [ 類型] 欄位中,選取 [ 標準 ] 或 [ 記憶體優化]。 請參閱 端點選項。
(選擇性)在 [ 進階設定] 底下,選取預算原則。 請參閱 馬賽克 AI 向量搜尋:預算原則。
按一下 確認。
使用 Python SDK 建立向量搜尋端點
下列範例會使用 create_endpoint() SDK 函式來建立向量搜尋端點。
# The following line automatically generates a PAT Token for authentication
client = VectorSearchClient()
# The following line uses the service principal token for authentication
# client = VectorSearchClient(service_principal_client_id=<CLIENT_ID>,service_principal_client_secret=<CLIENT_SECRET>)
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD" # or "STORAGE_OPTIMIZED"
)
使用 REST API 建立向量搜尋端點
請參閱 REST API 參考檔:POST /api/2.0/vector-search/endpoints。
(選擇性)建立並設定端點來提供內嵌模型
如果您選擇讓 Databricks 計算內嵌,您可以使用預先設定的基礎模型 API 端點,或建立服務端點的模型來提供您選擇的內嵌模型。 如需指示,請參閱 依令牌付費基礎模型 API 或 建立服務端點的基礎模型。 若要查看範例筆記本,請參閱用於調用嵌入模型的筆記本範例。
當您配置內嵌端點時,Databricks 建議您取消預設選項,使 的縮放比例設為零,。 服務端點需要幾分鐘才能完成熱身,而縮減的端點上的索引初始查詢可能會逾時。
注意
如果未適當地為數據集設定內嵌端點,向量搜尋索引初始化可能會逾時。 您應該只針對小型資料集和測試使用 CPU 端點。 針對較大的數據集,請使用 GPU 端點以獲得最佳效能。
建立向量搜尋索引
您可以使用UI、Python SDK 或 REST API 來建立向量搜尋索引。 UI 是最簡單的方法。
有兩種類型的索引:
- 差異同步索引 會自動與來源 Delta 數據表同步,並在差異數據表中的基礎數據變更時自動和累加地更新索引。
- 直接向量存取索引 支援向量和元數據的直接讀取和寫入。 用戶須負責使用 REST API 或 Python SDK 來更新此資料表。 您無法使用 UI 建立這種類型的索引。 您必須使用 REST API 或 SDK。
注意
欄位名稱 _id 是保留的。 如果您的來源表有一個名為_id的欄位,在建立向量搜尋索引前請先重新命名。
使用 UI 建立索引
在左側邊欄中,按一下 [目錄] 以開啟 [目錄瀏覽器介面]。
導覽到您想使用的 Delta 表格。
單擊右上角的 [[建立] 按鈕,然後從下拉菜單中選取 向量搜尋索引。
![[建立索引] 按鈕](../_static/images/generative-ai/create-index-button.png)
使用對話框中的選取器來設定索引。
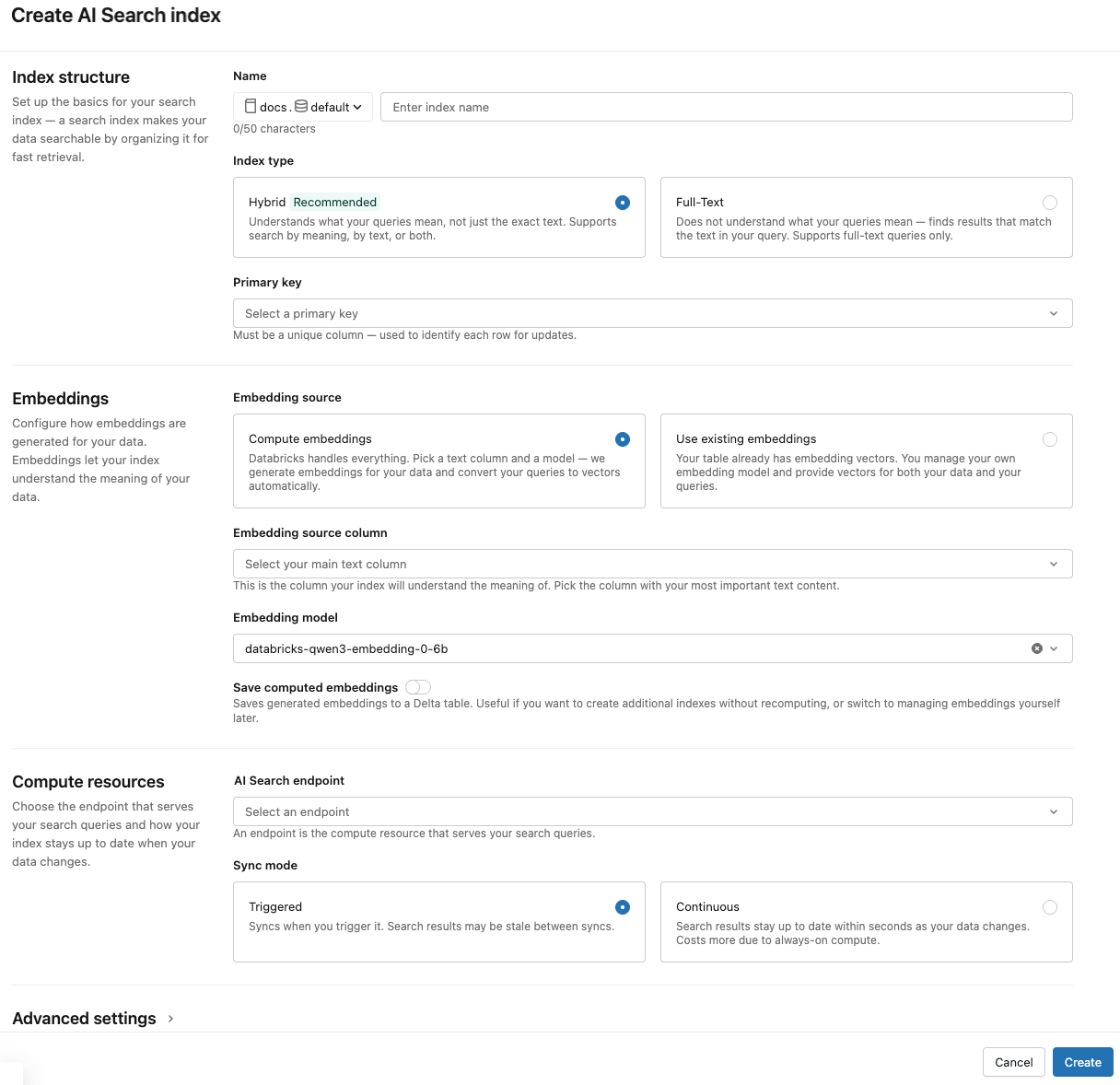
名稱:用於 Unity Catalog 中線上資料表的名稱。 名稱需要三層命名空間,
<catalog>.<schema>.<name>。 只允許英文字母、數字和下劃線。主鍵:用作主鍵的欄位。
端點:選取您想要使用的向量搜尋端點。
要同步處理的資料列:(僅支援標準端點。)選取要與向量索引同步的數據行。 如果您將此欄位保留空白,源數據表中的所有資料行都會與索引同步。 主鍵數據行和內嵌源數據行或內嵌向量數據行一律會同步處理。 針對儲存優化端點,來源表中的所有欄位都會同步。
內嵌來源:指出您是否希望 Databricks 計算 Delta 數據表中文字數據行的內嵌(計算內嵌),或如果您的 Delta 數據表包含預先計算的內嵌 (使用現有的內嵌數據行)。
- 如果您選取 計算內嵌,請選取您要內嵌計算的數據行,以及為內嵌模型提供服務的端點。 僅支援文字欄位。 針對大規模的嵌入生成,Databricks 建議使用按令牌付費的基礎模型
databricks-gte-large-en以達到更高的輸送量。 - 如果您選擇了使用現有的嵌入列,請選擇包含預先計算的嵌入和嵌入維度的列。 預先計算的內嵌資料列格式應該
array[float]。 針對記憶體優化的端點,內嵌維度必須平均地由16來分割。
同步計算內嵌:切換此設定,將產生的內嵌儲存至 Unity 目錄數據表。 如需詳細資訊,請參閱 儲存產生的內嵌資料表。
同步模式:連續保持索引同步,延遲時間以秒計。 不過,由於已布建計算叢集以執行持續同步串流管線,因此其成本較高。 對於標準端點, 「連續 」和 「觸發」 都會執行累加式更新,因此只會處理自上次同步處理后已變更的數據。 針對儲存優化的端點,每次同步都會完全重建向量搜尋索引。 請參閱 記憶體優化的端點限制。
使用觸發同步模式時,您可以使用 Python SDK 或 REST API 來啟動同步。請參閱更新 Delta 同步索引。
針對儲存空間優化的端點,僅支援 觸發的 同步模式。
- 如果您選取 計算內嵌,請選取您要內嵌計算的數據行,以及為內嵌模型提供服務的端點。 僅支援文字欄位。 針對大規模的嵌入生成,Databricks 建議使用按令牌付費的基礎模型
當您完成索引設定後,請點擊 [建立]。
使用 Python SDK 建立索引
以下範例會建立一個 Delta Sync 索引,其中的嵌入向量由 Databricks 計算。 如需詳細資訊,請參閱 Python SDK 參考。
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_source_column="text",
embedding_model_endpoint_name="e5-small-v2"
)
下列範例會建立具有自我管理的嵌入向量的 Delta 同步索引。 此範例也會示範使用選擇性參數 columns_to_sync 只選取索引中要使用的數據行子集。
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector"
)
根據預設,源數據表中的所有數據行都會與索引同步。
在標準端點上,您可以使用 columns_to_sync 選取要同步處理的欄子集。 主鍵和內嵌數據行一律包含在索引中。
若要同步 ,只同步 的主鍵與嵌入欄位,您必須在 columns_to_sync 中指定它們,如下所示:
index = client.create_delta_sync_index(
...
columns_to_sync=["id", "text_vector"] # to sync only the primary key and the embedding column
)
若要同步其他欄,請如下所示指定它們。 您不需要包括主鍵和嵌入列,因為它們總是同步的。
index = client.create_delta_sync_index(
...
columns_to_sync=["revisionId", "text"] # to sync the `revisionId` and `text` columns in addition to the primary key and embedding column.
)
下列範例會建立直接向量存取索引。
client = VectorSearchClient()
index = client.create_direct_access_index(
endpoint_name="storage_endpoint",
index_name=f"{catalog_name}.{schema_name}.{index_name}",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector",
schema={
"id": "int",
"field2": "string",
"field3": "float",
"text_vector": "array<float>"}
)
使用 REST API 建立索引
請參閱 REST API 參考檔:POST /api/2.0/vector-search/indexes。
儲存產生的內嵌數據表
如果 Databricks 產生內嵌,您可以將產生的內嵌儲存至 Unity 目錄中的數據表。 此數據表會建立於與向量索引相同的架構中,並從向量索引頁面連結。
資料表的名稱是向量搜尋索引的名稱,附加 _writeback_table。 無法編輯名稱。
您可以像 Unity 目錄中的任何其他資料表一樣存取和查詢資料表。 不過,您不應該卸除或修改數據表,因為它不適合手動更新。 如果刪除索引,數據表會自動刪除。
更新向量搜尋索引
更新差異同步索引
當來源 Delta 數據表變更時,使用 連續 同步模式建立的索引會自動更新。 如果您使用 觸發同步 模式,您可以使用UI、Python SDK 或 REST API 來啟動同步處理。
Databricks 使用者介面
在目錄總管中,流覽至向量搜尋索引。
在 [ 概觀] 索引標籤的 [ 數據內嵌] 區段中,按兩下 [立即同步處理]。
![[立即同步處理] 按鈕,從目錄總管同步向量搜尋索引。](../_static/images/generative-ai/sync-now.png)
Python SDK
如需詳細資訊,請參閱 Python SDK 參考。
client = VectorSearchClient()
index = client.get_index(index_name="vector_search_demo.vector_search.en_wiki_index")
index.sync()
REST API
請參閱 REST API 參考檔:POST /api/2.0/vector-search/indexes/{index_name}/sync。
更新直接向量存取索引
您可以使用 Python SDK 或 REST API,從直接向量存取索引插入、更新或刪除數據。
Python SDK
如需詳細資訊,請參閱 Python SDK 參考。
index.upsert([
{
"id": 1,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.0] * 1024
},
{
"id": 2,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.1] * 1024
}
])
REST API
請參閱 REST API 參考檔:POST /api/2.0/vector-search/indexes。
針對生產應用程式,Databricks 建議使用服務主體,而不是個人存取令牌。 查詢性能可提高,每次查詢最多減少 100 毫秒的處理時間。
下列程式代碼範例說明如何使用服務主體更新索引。
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "WriteVectorIndex"}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Upsert data into vector search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/upsert-data --data '{"inputs_json": "[...]"}'
# Delete data from vector search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/delete-data --data '{"primary_keys": [...]}'
下列程式代碼範例說明如何使用個人存取令牌來更新索引(PAT)。
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Upsert data into vector search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/upsert-data --data '{"inputs_json": "..."}'
# Delete data from vector search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/delete-data --data '{"primary_keys": [...]}'
查詢向量搜尋端點
您只能使用 Python SDK、REST API 或 SQL vector_search() AI 函式來查詢向量搜尋端點。
注意
如果查詢端點的使用者不是向量搜尋索引的擁有者,用戶必須具有下列 UC 許可權:
- USE CATALOG 位於包含向量搜尋索引的目錄中。
- USE SCHEMA 在包含向量搜尋索引的架構中。
- 向量搜尋索引上的 SELECT。
默認查詢類型為 ann (近似近鄰)。 若要執行混合式關鍵字相似性搜尋,請將 參數 query_type 設定為 hybrid。 使用混合式搜尋時,會包含所有文字元數據行,且最多會傳回 200 個結果。
Python SDK 標準端點
如需詳細資訊,請參閱 Python SDK 參考。
# Delta Sync Index with embeddings computed by Databricks
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "field2"],
num_results=2
)
# Delta Sync Index using hybrid search, with embeddings computed by Databricks
results3 = index.similarity_search(
query_text="Greek myths",
columns=["id", "field2"],
num_results=2,
query_type="hybrid"
)
# Delta Sync Index with pre-calculated embeddings
results2 = index.similarity_search(
query_vector=[0.9] * 1024,
columns=["id", "text"],
num_results=2
)
Python SDK 記憶體優化端點
如需詳細資訊,請參閱 Python SDK 參考。
現有的篩選介面已針對記憶體優化向量搜尋索引重新設計,採用更類似 SQL 的篩選字串,而不是標準向量搜尋端點中使用的篩選字典。
client = VectorSearchClient()
index = client.get_index(index_name="vector_search_demo.vector_search.en_wiki_index")
# similarity search with query vector
results = index.similarity_search(
query_vector=[0.2, 0.33, 0.19, 0.52],
columns=["id", "text"],
num_results=2
)
# similarity search with query vector and filter string
results = index.similarity_search(
query_vector=[0.2, 0.33, 0.19, 0.52],
columns=["id", "text"],
# this is a single filter string similar to SQL WHERE clause syntax
filters="language = 'en' AND country = 'us'",
num_results=2
)
REST API
請參閱 REST API 參考檔:POST /api/2.0/vector-search/indexes/{index_name}/query。
針對生產應用程式,Databricks 建議使用服務主體,而不是個人存取令牌。 除了改善安全性和存取管理之外,使用服務主體可使每個查詢的效能提升最多 100 毫秒。
下列程式代碼範例說明如何使用服務主體查詢索引。
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "ReadVectorIndex"}'
# If you are using an route_optimized embedding model endpoint, then you need to have additional authorization details to invoke the serving endpoint
# export EMBEDDING_MODEL_SERVING_ENDPOINT_ID=...
# export AUTHORIZATION_DETAILS="$AUTHORIZATION_DETAILS"',{"type":"workspace_permission","object_type":"serving-endpoints","object_path":"/serving-endpoints/'"$EMBEDDING_MODEL_SERVING_ENDPOINT_ID"'","actions": ["query_inference_endpoint"]}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Query vector search index.
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/query --data '{"num_results": 3, "query_vector": [...], "columns": [...], "debug_level": 1}'
# Query vector search index.
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/query --data '{"num_results": 3, "query_text": "...", "columns": [...], "debug_level": 1}'
下列程式代碼範例說明如何使用個人存取令牌來查詢索引(PAT)。
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Query vector search index with `query_vector`
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/query --data '{"num_results": 3, "query_vector": [...], "columns": [...], "debug_level": 1}'
# Query vector search index with `query_text`
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/query --data '{"num_results": 3, "query_text": "...", "columns": [...], "debug_level": 1}'
SQL
重要
vector_search() AI 功能目前在 公開預覽中。
若要使用此 AI 函式,請參閱 vector_search 函式。
在查詢上使用篩選
查詢可以根據 Delta 資料表中的任何數據行來定義篩選。
similarity_search 只會傳回符合指定篩選的數據列。
下表列出支持的篩選條件。
| 篩選運算子 | 行為 | 例子 |
|---|---|---|
NOT |
標準:否定篩選條件。 密鑰必須以「NOT」結尾。 例如,值為 “red” 的 “color NOT” 用於比對顏色不是紅色的文件。 儲存優化:請參閱 != (bangeq 符號) 運算符。 |
標準: {"id NOT": 2}{“color NOT”: “red”}記憶體優化: "id != 2" "color != 'red'" |
< |
標準:檢查域值是否小於篩選值。 索引鍵必須以 「<」 結尾。 例如,值為 200 的「價格 <」會比對價格小於 200 的檔。 記憶體優化:請參閱 < (lt sign) 運算符。 |
標準: {"id <": 200}記憶體優化: "id < 200" |
<= |
標準:檢查域值是否小於或等於篩選值。 密鑰的結尾必須是「<=」。 例如,值為 200 的 「price <=」 會比對價格小於或等於 200 的檔。 記憶體優化:請參閱 <= (lt eq sign) 運算符。 |
標準: {"id <=": 200}記憶體優化: "id <= 200" |
> |
標準:檢查域值是否大於篩選值。 索引鍵必須以 「>」 結尾。 例如,值為 200 的「價格 >」會比對價格大於 200 的檔。 記憶體優化:請參閱 > (gt sign) 運算符。 |
標準: {"id >": 200}記憶體優化: "id > 200" |
>= |
標準:檢查域值是否大於或等於篩選值。 密鑰的結尾必須是「>=」。 例如,值為 200 的 「price >=」 會比對價格大於或等於 200 的檔。 記憶體優化:請參閱 >= (gt eq sign) 運算符。 |
標準: {"id >=": 200}記憶體優化: "id >= 200" |
OR |
標準:檢查域值是否符合任何篩選值。 鍵值必須包含 OR,以分隔多個子鍵。 例如,值為 color1 OR color2 的 ["red", "blue"] 的文檔符合 color1 為 red 或 color2 為 blue的條件。記憶體優化:請參閱 or 運算元。 |
標準: {"color1 OR color2": ["red", "blue"]}記憶體優化: "color1 = 'red' OR color2 = 'blue'" |
LIKE |
標準:比對字串中的空格符分隔標記。 請參閱下列程式代碼範例。 記憶體優化:請參閱 like 運算元。 |
標準: {"column LIKE": "hello"}記憶體優化: "column LIKE 'hello'" |
| 未指定篩選運算子 |
標準:篩選檢查是否完全相符。 如果指定了多個值,則會比對任何值。 記憶體優化:請參閱 = (eq sign) 運算符 和 in 述詞。 |
標準: {"id": 200}{"id": [200, 300]}記憶體優化: "id = 200""id IN (200, 300)" |
to_timestamp (僅限記憶體優化端點) |
記憶體優化:篩選時間戳。 請參閱 to_timestamp 函式 |
記憶體優化: "date > TO_TIMESTAMP('1995-01-01')" |
請參閱下列程式代碼範例:
Python SDK 標準端點
# Match rows where `title` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title": ["Ares", "Athena"]},
num_results=2
)
# Match rows where `title` or `id` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title OR id": ["Ares", "Athena"]},
num_results=2
)
# Match only rows where `title` is not `Hercules`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title NOT": "Hercules"},
num_results=2
)
Python SDK 記憶體優化端點
# Match rows where `title` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters='title IN ("Ares", "Athena")',
num_results=2
)
# Match rows where `title` or `id` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters='title = "Ares" OR id = "Athena"',
num_results=2
)
# Match only rows where `title` is not `Hercules`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters='title != "Hercules"',
num_results=2
)
REST API
請參閱 POST /api/2.0/vector-search/indexes/{index_name}/query。
喜歡
LIKE 範例
{"column LIKE": "apple"}:符合字串 「apple」 和 「apple pear」,但不符合 「pineapple」 或 「pear」。 請注意,它不匹配「鳳梨」,即使其中包含子字串「apple」──它尋找的是空格分隔標記中的完全匹配,例如「蘋果 梨」。
{"column NOT LIKE": "apple"} 做相反的事情。 它匹配「鳳梨」和「梨子」,但不匹配「蘋果」或「蘋果梨」。
範例筆記本
本節中的範例示範向量搜尋 Python SDK 的使用方式。 如需參考資訊,請參閱 Python SDK 參考。
LangChain 範例
請參閱 如何將 LangChain 套件與馬賽克 AI 向量搜尋整合使用,以了解如何在 LangChain 套件中整合馬賽克 AI 向量搜尋。
下列筆記本示範如何將相似度搜尋結果轉換成 LangChain 檔。
使用 Python SDK 筆記本進行向量搜尋
Notebook 呼叫嵌入模型的範例
下列筆記本示範如何設定馬賽克 AI 模型服務端點以進行內嵌產生。