使用 Azure Databricks AutoML UI 定型 ML 模型
本文示範如何使用 AutoML 和 Databricks 機器學習 UI 來定型機器學習模型。 AutoML UI 會逐步引導您在數據集上定型分類、回歸或預測模型。
請參閱 AutoML 實驗的需求 。
開啟 AutoML UI
若要存取 AutoML UI:
在提要欄位中,選取 [ 新增 > AutoML 實驗]。
您也可以從 [實驗] 頁面建立新的 AutoML 實驗。
[設定 AutoML 實驗] 頁面 隨即顯示。 在此頁面上,您會設定 AutoML 程式、指定要預測的數據集、問題類型、目標或標籤數據行、用來評估和評分實驗回合的計量,以及停止條件。
設定分類或回歸問題
您可以使用 AutoML UI 搭配下列步驟來設定分類或回歸問題:
在 [ 計算] 字段中,選取執行 Databricks Runtime ML 的叢集。
從 [ML 問題類型] 下拉功能表中,選取 [回歸] 或 [分類]。 如果您嘗試預測每個觀察的連續數值,例如年度收入,請選取回歸。 如果您嘗試將每個觀察指派給一組離散類別的其中一個,例如良好的信用風險或不良信用風險,請選取分類。
在 [數據集] 底下,選取 [流覽]。
流覽至您想要使用的數據表,然後按兩下 [ 選取]。 數據表架構隨即出現。
- 在 Databricks Runtime 10.3 ML 和更新版本中,您可以 指定 AutoML 應該用於定型的數據行。 您無法移除選取的數據行做為預測目標或分割資料的時間資料行。
- 在 Databricks Runtime 10.4 LTS ML 和更新版本中,您可以從 [插補] 下拉式清單中選取 ,以指定 Null 值插補的方式。 根據預設,AutoML 會根據數據行類型和內容選取插補方法。
注意
如果您指定非預設插補方法,AutoML 不會執行 語意類型偵測。
按兩下 [ 預測目標] 欄位中。 隨即會出現下拉式清單,其中列出架構中顯示的數據行。 選取您想要模型預測的數據行。
[ 實驗名稱] 欄位會顯示預設名稱。 若要變更它,請在欄位中輸入新的名稱。
您也可以:
- 指定 其他組態選項。
- 使用 功能存放區中的現有功能數據表來增強原始輸入數據集。
設定預測問題
您可以使用 AutoML UI 搭配下列步驟來設定預測問題:
在 [ 計算] 欄位中,選取執行 Databricks Runtime 10.0 ML 或更新版本的叢集。
從 [ML 問題類型] 下拉功能表中,選取 [預測]。
在 [數據集] 底下,按兩下 [瀏覽]。 流覽至您想要使用的數據表,然後按兩下 [ 選取]。 數據表架構隨即出現。
按兩下 [ 預測目標] 欄位中。 下拉功能表隨即出現,其中列出架構中顯示的數據行。 選取您想要模型預測的數據行。
按兩下 [ 時間] 資料行 欄位。 隨即會出現下拉式清單,其中顯示類型
timestamp為 或date的數據集數據行。 選取包含時間序列時間週期的數據行。針對多序列預測,請從 [時間序列標識元] 下拉式清單中選取識別個別時間序列的數據 行。。 AutoML 會將這些數據行分組為不同的時間序列,並個別定型每個數位的模型。 如果您將此欄位保留空白,AutoML 會假設資料集包含單一時間序列。
在 [ 預測地平線] 和 [頻率 ] 字段中,指定 AutoML 應計算預測值的未來時段數目。 在左方塊中,輸入要預測的週期整數數目。 在右側方塊中,選取單位。
注意
若要使用 Auto-ARIMA,時間序列必須有一般頻率,其中任何兩個點之間的間隔在整個時間序列中必須相同。 頻率必須符合 API 呼叫或 AutoML UI 中指定的頻率單位。 AutoML 會以先前的值填入這些值,以處理遺漏的時間步驟。
在 Databricks Runtime 11.3 LTS ML 和更新版本中,您可以儲存預測結果。 若要這樣做,請在 [ 輸出資料庫 ] 字段中指定資料庫。 按兩下 [ 瀏覽 ],然後從對話框中選取資料庫。 AutoML 會將預測結果寫入此資料庫中的數據表。
[ 實驗名稱] 欄位會顯示預設名稱。 若要變更它,請在欄位中輸入新的名稱。
您也可以:
- 指定 其他組態選項。
- 使用 功能存放區中的現有功能數據表來增強原始輸入數據集。
從 Databricks 功能存放區使用現有的功能數據表
在 Databricks Runtime 11.3 LTS ML 和更新版本中,您可以使用 Databricks 功能存放區中的功能數據表來擴充分類和回歸問題的輸入定型數據集。
在 Databricks Runtime 12.2 LTS ML 和更新版本中,您可以使用 Databricks 功能存放區中的功能數據表,擴充所有 AutoML 問題的輸入定型數據集:分類、回歸和預測。
若要建立功能數據表,請參閱 在 Unity 目錄中 建立功能數據表或在 Databricks 功能存放區中建立功能數據表。
設定 AutoML 實驗之後,您可以使用下列步驟來選取功能資料表:
按兩下 [加入功能] (選擇性)。
![選取 [聯結功能] 按鈕](../../_static/images/machine-learning/automl-join-features.png)
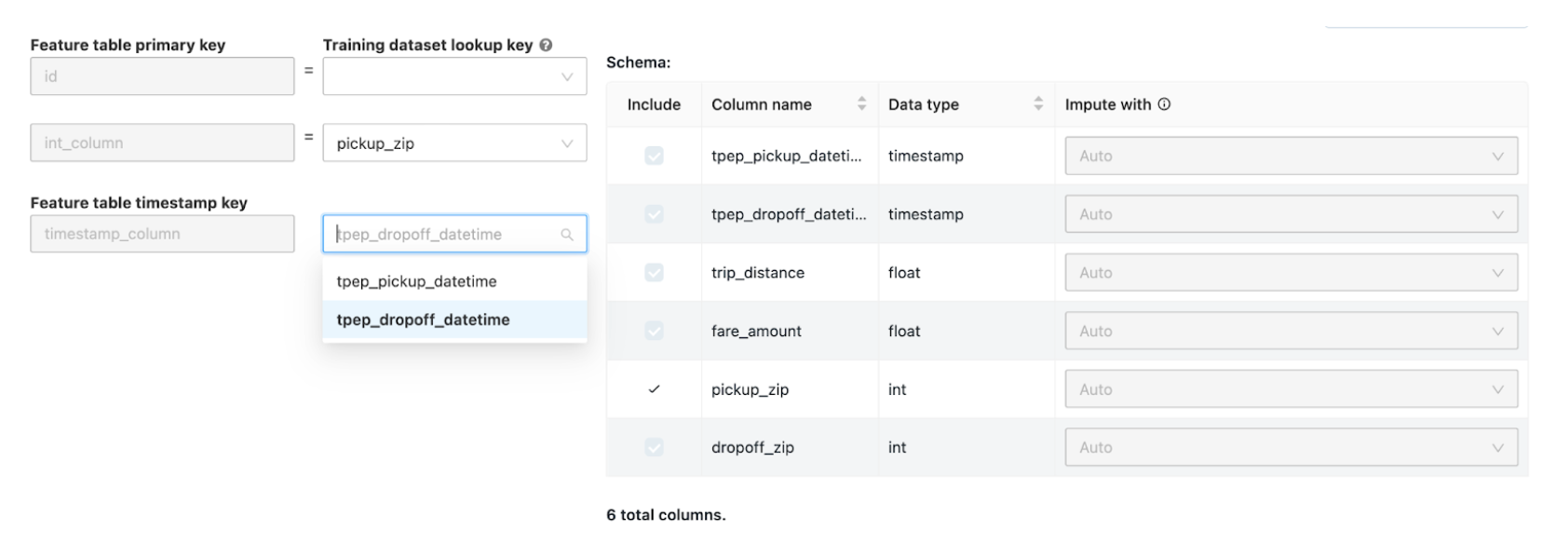
在 [聯結其他功能] 頁面上,選取 [功能數據表] 字段中的功能數據表。
針對每個 功能數據表主鍵,選取對應的查閱索引鍵。 查閱索引鍵應該是您為 AutoML 實驗提供的定型數據集中的數據行。
針對 時間序列功能數據表,選取對應的時間戳查閱索引鍵。 同樣地,時間戳查閱索引鍵應該是您為 AutoML 實驗提供的定型數據集中的數據行。
若要新增更多功能數據表,請按兩下 [新增其他數據表 ],然後重複上述步驟。
進階組態
開啟 [ 進階設定][選擇性] 區段以存取這些參數。
- 評估計量是 用來評分執行的主要計量 。
- 在 Databricks Runtime 10.4 LTS ML 和更新版本中,您可以將定型架構排除在考慮之外。 根據預設,AutoML 會使用 AutoML 演算法下 所列的架構來定型模型。
- 您可以編輯停止條件。 預設停止條件為:
- 針對預測實驗,請在 120 分鐘後停止。
- 在 Databricks Runtime 10.4 LTS ML 和以下的分類和回歸實驗中,於 60 分鐘後或完成 200 個試驗之後停止,以先發生。 針對 Databricks Runtime 11.0 ML 和更新版本,試用版數目不會當做停止條件使用。
- 在 Databricks Runtime 10.4 LTS ML 和更新版本中,針對分類和回歸實驗,AutoML 會納入早期停止;如果驗證計量不再改善,它會停止定型和微調模型。
- 在 Databricks Runtime 10.4 LTS ML 和更新版本中,您可以選取 時間數據行 ,以時間順序分割數據以進行定型、驗證和測試(僅適用於分類和回歸)。
- Databricks 建議不要填入 [資料目錄] 欄位。 這麼做會觸發將數據集安全地儲存為 MLflow 成品的預設行為。 您可以指定 DBFS 路徑,但在此情況下,數據集不會繼承 AutoML 實驗的訪問許可權。
執行實驗並監視結果
若要啟動 AutoML 實驗,請按兩下 [ 啟動 AutoML]。 實驗會開始執行,且 [AutoML 訓練] 頁面隨即出現。 若要重新整理執行資料表,請按下  。
。
您可以從這個頁面執行下列動作:
- 隨時停止實驗。
- 開啟數據探索筆記本。
- 監視執行。
- 流覽至任何回合的執行頁面。
使用 Databricks Runtime 10.1 ML 和更新版本時,AutoML 會顯示數據集潛在問題的警告,例如不支援的數據行類型或高基數數據行。
注意
Databricks 會盡最大努力指出潛在的錯誤或問題。 不過,這可能不完整,而且可能不會擷取您可能搜尋的問題或錯誤。
若要查看數據集的任何警告,請按兩下 訓練頁面或實驗完成後的 [警告 ] 索引標籤。

實驗完成時,您可以:
- 使用 MLflow 註冊並部署 其中一個模型。
- 選取 [檢視筆記本] 以檢閱和編輯建立最佳模型的筆記本。
- 選取 [ 檢視數據探索筆記本 ] 以開啟數據探索筆記本。
- 搜尋、篩選及排序執行數據表中的執行。
- 請參閱任何執行的詳細資料:
- 您可以按下 MLflow 執行,找到包含試用回合原始程式碼的已產生筆記本。 筆記本會儲存在 執行頁面的 [成品 ] 區段中。 如果工作區系統管理員已啟用下載成品,您可以下載此筆記本並將其匯入工作區。
- 若要檢視執行結果,請按兩下 [模型] 資料行或 [ 開始時間] 資料行。 [執行] 頁面隨即出現,其中顯示試用版執行的相關信息(例如參數、計量和標籤),以及執行所建立的成品,包括模型。 此頁面也包含代碼段,您可以用來對模型進行預測。
若要稍後返回此 AutoML 實驗,請在 [實驗] 頁面上的數據表中找到它。 每個 AutoML 實驗的結果,包括數據探索和訓練筆記本,都會儲存在databricks_automl執行實驗之使用者的主資料夾中。
註冊及部署模型
您可以使用 AutoML UI 註冊和部署模型:
- 選取要註冊之模型的 [模型] 數據行中的連結。 執行完成時,頂端數據列是最佳模型(根據主要計量)。
- 選取
 以在模型登錄中註冊模型。
以在模型登錄中註冊模型。 - 選取
 提要巡覽至模型登錄的提要欄位中的 [模型]。
提要巡覽至模型登錄的提要欄位中的 [模型]。 - 在模型數據表中選取模型的名稱。
- 從已註冊的模型頁面,您可以使用模型服務來提供模型。
沒有名為 『pandas.core.indexes.numeric』 的模組
使用 AutoML 搭配模型服務建置的模型時,您可能會收到錯誤: No module named 'pandas.core.indexes.numeric。
這是因為 AutoML 與服務端點環境的模型之間版本不相容 pandas 。 您可以執行 add-pandas-dependency.py 文稿來解決此錯誤。 文稿會編輯 記錄 requirements.txt 模型的 和 conda.yaml ,以包含適當的 pandas 相依性版本: pandas==1.5.3
- 變更文稿以包含
run_id記錄模型所在之 MLflow 執行的 。 - 將模型重新登錄至 MLflow 模型登錄。
- 請嘗試提供新版本的 MLflow 模型。
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應