本文說明如何使用 Databricks 模型服務來建立服務端點,以提供自定義模型的服務。
Model Serving 提供下列選項來提供端點建立服務:
- 服務用戶界面
- REST API
- MLflow SDK 部署
如需建立提供產生 AI 模型的端點,請參閱 建立服務端點的基礎模型。
需求
- 您的工作區必須位於 支持的區域中。
- 如果您將自定義庫或從私人鏡像伺服器的庫用於模型,請在建立模型端點之前參閱 使用自定義 Python 庫搭配模型服務。
- 若要使用 MLflow 部署 SDK 建立端點,必須安裝 MLflow 部署用戶端。 若要進行安裝,請執行:
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
存取控制
若要瞭解端點管理模型服務端點的存取控制選項,請參閱 管理模型服務端點的許可。
模型服務端點運行所依據的身分識別已綁定至端點的原始建立者。 建立端點之後,無法在端點上變更或更新相關聯的身分識別。 此身分識別及其相關聯的許可權可用來存取 Unity 目錄資源以進行部署。 如果身分識別沒有適當的許可權來存取所需的 Unity 目錄資源,您必須刪除端點,並在可存取這些 Unity 目錄資源的使用者或服務主體下重新建立它。
您也可以新增環境變數來儲存模型服務的認證。 請參閱 配置模型服務端點的資源存取
建立端點
提供 UI 服務
您可以使用 服務 UI 建立模型服務的端點。
按下側邊欄的 [服務] 可顯示 [服務] UI。
按下 [建立服務端點]。
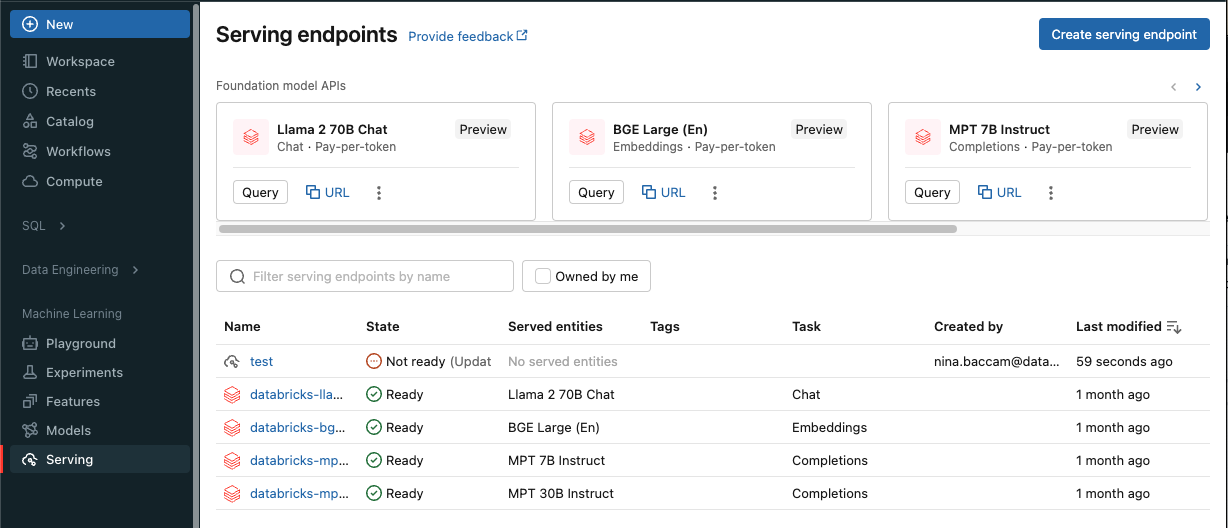
針對在工作區模型登錄中註冊的模型,或 Unity 目錄中的模型:
在 [名稱] 欄位中,提供端點的名稱。
- 端點名稱不能使用
databricks-前置詞。 此前置詞保留給 Databricks 預先設定的端點。
- 端點名稱不能使用
在 [服務實體] 區 段中
- 點擊 實體 欄位以開啟 選取提供的實體 表單。
- 根據模型的註冊位置,選取 [ 我的模型 - Unity 目錄 ] 或 [我的模型 - 模型登錄 ]。 表單會根據您的選擇動態更新。
- 選擇您想要提供服務的模型及其版本。
- 選擇要導向您模型服務的流量百分比。
- 選取要使用的計算大小。 您可以針對工作負載使用 CPU 或 GPU 計算。 如需可用 GPU 計算的詳細資訊,請參閱 GPU 工作負載類型 。
- 在計算擴展下,選取與此服務模型能同時處理的請求數量相對應的計算大小。 此數字應大致等於 QPS x 模型執行時間。 如需客戶定義的計算設定,請參閱 模型服務限制。
- 可用大小包括適用於 0-4 個要求的 [小型]、適用於 8-16 個要求的 [中型],以及適用於16-64 個要求的 [大型]。
- 指定端點在不使用時是否應該調整為零。 不建議針對生產端點調整為零,因為調整為零時不保證容量。 當端點縮減至零時,當端點擴展回來以處理請求時,會出現額外的延遲,這也稱為冷啟動。
- 在 進階設定下,您可以:
- 重新命名已服務的實體,以自訂其在端點中的顯示方式。
- 新增環境變數以從端點連接至資源,或將特徵查詢 DataFrame記錄到端點的預測表格。 記錄特徵查找的DataFrame需要MLflow 2.14.0或更新版本。
- (選用)若要將其他服務實體新增至端點,請按一下 新增服務實體 並重複上述設定步驟。 您可以從單一端點提供多個模型或模型版本,並控制它們之間的流量分割。 如需詳細資訊,請參閱 提供多個模型 。
在 [ 路由優化] 區段中,您可以啟用端點的路由優化。 建議針對具有高 QPS 和輸送量需求的端點進行路由最佳化。 請參閱 服務端點的路由優化。
在 [ AI 閘道 ] 區段中,您可以選取要在您的端點上啟用的治理功能。 請參閱 馬賽克 AI 閘道簡介。
按一下 建立。 [服務端點] 頁面隨即出現,[服務端點狀態] 顯示為 [未就緒]。
REST API
可以使用 REST API 建立端點。 如需端點組態參數,請參閱 POST /api/2.0/service-endpoints 。
下列範例會建立一個端點,此端點提供在 Unity 目錄模型註冊中註冊的 my-ads-model 模型的第三個版本。 若要從 Unity 目錄指定模型,請提供完整的模型名稱,包括父目錄和架構,例如,catalog.schema.example-model。 此範例使用自訂並行 min_provisioned_concurrency 和 max_provisioned_concurrency。 並行值必須是 4 的倍數。
POST /api/2.0/serving-endpoints
{
"name": "uc-model-endpoint",
"config":
{
"served_entities": [
{
"name": "ads-entity",
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"min_provisioned_concurrency": 4,
"max_provisioned_concurrency": 12,
"scale_to_zero_enabled": false
}
]
}
}
以下是回覆範例。 端點 config_update 的狀態為 NOT_UPDATING ,且服務模型處於 READY 狀態。
{
"name": "uc-model-endpoint",
"creator": "user@email.com",
"creation_timestamp": 1700089637000,
"last_updated_timestamp": 1700089760000,
"state": {
"ready": "READY",
"config_update": "NOT_UPDATING"
},
"config": {
"served_entities": [
{
"name": "ads-entity",
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"min_provisioned_concurrency": 4,
"max_provisioned_concurrency": 12,
"scale_to_zero_enabled": false,
"workload_type": "CPU",
"state": {
"deployment": "DEPLOYMENT_READY",
"deployment_state_message": ""
},
"creator": "user@email.com",
"creation_timestamp": 1700089760000
}
],
"config_version": 1
},
"tags": [
{
"key": "team",
"value": "data science"
}
],
"id": "e3bd3e471d6045d6b75f384279e4b6ab",
"permission_level": "CAN_MANAGE",
"route_optimized": false
}
MLflow SDK 部署
MLflow 部署 提供用於建立、更新和刪除工作的 API。 這些工作的 API 接受與 REST API 相同的參數,用以操作端點。 如需端點組態參數,請參閱 POST /api/2.0/service-endpoints 。
下列範例會建立一個端點,此端點提供在 Unity 目錄模型註冊中註冊的 my-ads-model 模型的第三個版本。 您必須提供完整的模型名稱,包括父目錄和架構,例如,catalog.schema.example-model。 此範例使用自訂並行 min_provisioned_concurrency 和 max_provisioned_concurrency。 並行值必須是 4 的倍數。
import mlflow
from mlflow.deployments import get_deploy_client
mlflow.set_registry_uri("databricks-uc")
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="unity-catalog-model-endpoint",
config={
"served_entities": [
{
"name": "ads-entity",
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"min_provisioned_concurrency": 4,
"max_provisioned_concurrency": 12,
"scale_to_zero_enabled": False
}
]
}
)
工作區用戶端
下列範例示範如何使用 Databricks Workspace 用戶端 SDK 建立端點。
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput
w = WorkspaceClient()
w.serving_endpoints.create(
name="uc-model-endpoint",
config=EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
name="ads-entity",
entity_name="catalog.schema.my-ads-model",
entity_version="3",
workload_size="Small",
scale_to_zero_enabled=False
)
]
)
)
您也可以:
- 啟用推論表,自動捕捉傳入的請求和傳出至模型服務端點的回應。
- 如果您的端點上已啟用推論表,您可以將 功能查詢 DataFrame 記錄 到推論表。
GPU 工作負載類型
GPU 部署與下列套件版本相容:
- PyTorch 1.13.0 - 2.0.1
- TensorFlow 2.5.0 - 2.13.0
- MLflow 2.4.0 和更新版本
下列範例顯示如何使用不同的方法建立 GPU 端點。
提供 UI 服務
若要使用 服務 UI設定GPU工作負載的端點,請在建立端點時從計算 型別 下拉式清單中選取所需的GPU型別。 請遵循 建立端點中的相同步驟,但選取 GPU 工作負載類型,而不是 CPU。
REST API
若要使用 GPU 部署模型,請在端點組態中包含欄位 workload_type 。
POST /api/2.0/serving-endpoints
{
"name": "gpu-model-endpoint",
"config": {
"served_entities": [{
"entity_name": "catalog.schema.my-gpu-model",
"entity_version": "1",
"workload_type": "GPU_SMALL",
"workload_size": "Small",
"scale_to_zero_enabled": false
}]
}
}
MLflow SDK 部署
下列範例示範如何使用 MLflow 部署 SDK 建立 GPU 端點。
import mlflow
from mlflow.deployments import get_deploy_client
mlflow.set_registry_uri("databricks-uc")
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="gpu-model-endpoint",
config={
"served_entities": [{
"entity_name": "catalog.schema.my-gpu-model",
"entity_version": "1",
"workload_type": "GPU_SMALL",
"workload_size": "Small",
"scale_to_zero_enabled": False
}]
}
)
工作區用戶端
下列範例示範如何使用 Databricks 工作區用戶端 SDK 建立 GPU 端點。
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput
w = WorkspaceClient()
w.serving_endpoints.create(
name="gpu-model-endpoint",
config=EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name="catalog.schema.my-gpu-model",
entity_version="1",
workload_type="GPU_SMALL",
workload_size="Small",
scale_to_zero_enabled=False
)
]
)
)
下表摘要說明支援的可用 GPU 工作負載類型。
| GPU 工作負載類型 | GPU 執行個體 | GPU 記憶體 |
|---|---|---|
GPU_SMALL |
1xT4 | 16 GB |
GPU_LARGE |
1xA100 | 80GB |
GPU_LARGE_2 |
2×A100 | 160GB |
修改自訂模型端點
啟用自訂模型端點之後,您可以視需要更新計算組態。 如果您需要模型的其他資源,此組態特別有用。 工作負載大小和計算組態在配置哪些資源來為您的模型提供服務方面扮演重要角色。
在新的組態準備就緒之前,舊組態會持續為預測流量提供服務。 當某個更新正在進行時,無法進行另一個更新。 不過,您可以從服務 UI 取消進行中的更新。
提供 UI 服務
啟用模型端點之後,請選取 [編輯端點]
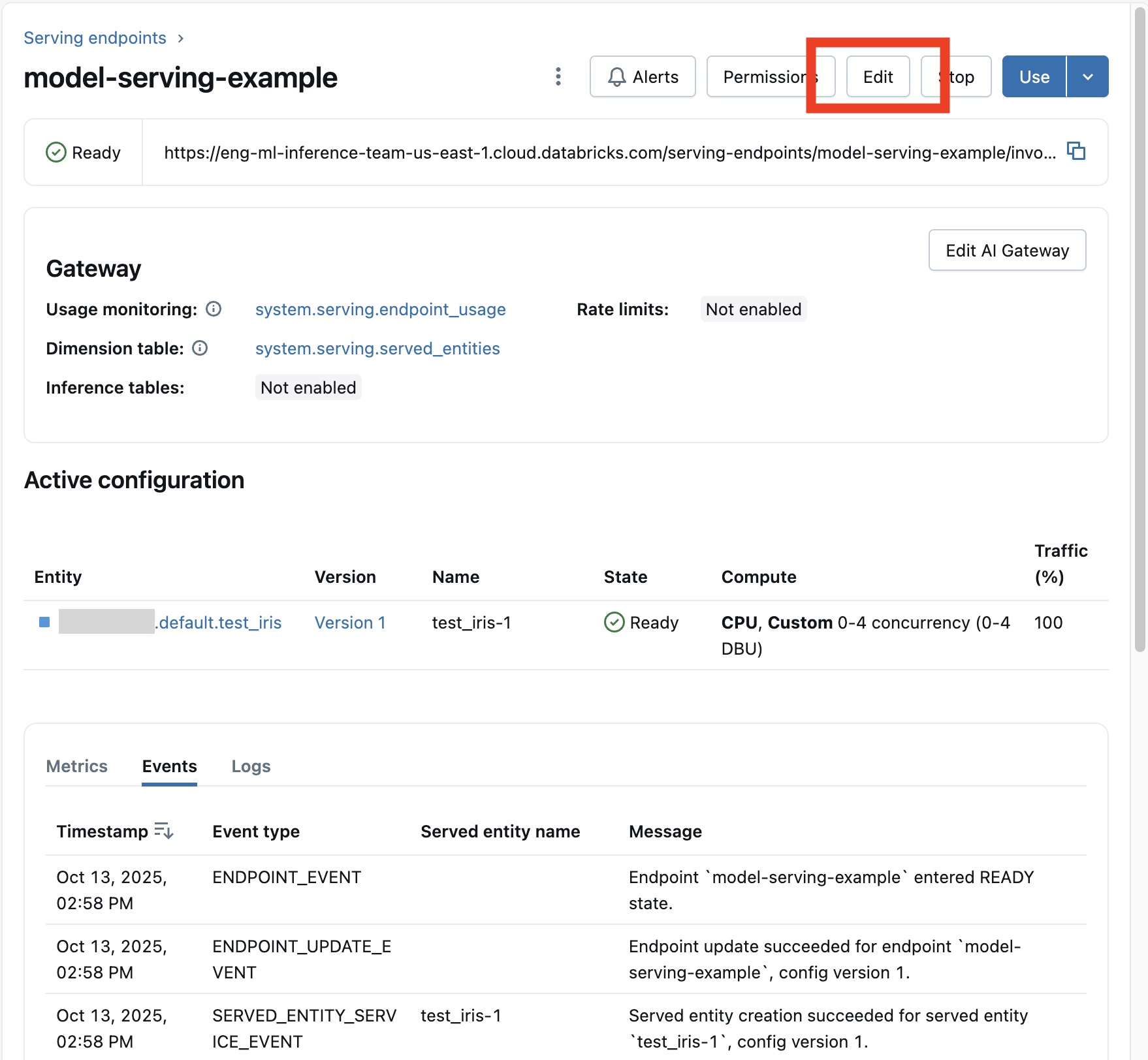
您可以變更端點組態的大部分層面,但端點名稱和某些不可變屬性除外。
您可以在端點的詳細資訊頁面上選取 [取消更新 ],以取消進行中的組態更新。
REST API
以下是使用 REST API 的端點組態更新範例。 請參閱 PUT /api/2.0/service-endpoints/{name}/config。
PUT /api/2.0/serving-endpoints/{name}/config
{
"name": "unity-catalog-model-endpoint",
"config":
{
"served_entities": [
{
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "5",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config":
{
"routes": [
{
"served_model_name": "my-ads-model-5",
"traffic_percentage": 100
}
]
}
}
}
MLflow SDK 部署
MLflow 部署 SDK 使用與 REST API 相同的參數,請參閱 PUT /api/2.0/service-endpoints/{name}/config 以取得要求和回應架構詳細數據。
下列程式代碼範例會使用 Unity 目錄模型登錄中的模型:
import mlflow
from mlflow.deployments import get_deploy_client
mlflow.set_registry_uri("databricks-uc")
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name=f"{endpointname}",
config={
"served_entities": [
{
"entity_name": f"{catalog}.{schema}.{model_name}",
"entity_version": "1",
"workload_size": "Small",
"scale_to_zero_enabled": True
}
],
"traffic_config": {
"routes": [
{
"served_model_name": f"{model_name}-1",
"traffic_percentage": 100
}
]
}
}
)
對模型端點評分
若要對模型評分,請將要求傳送至模型服務端點。
- 請參閱 自定義模型的查詢端點服務。
- 請參閱 使用基礎模型。
其他資源
- 管理服務端點的模型。
- 馬賽克 AI 模型服務中的外部模型。
- 如果您偏好使用 Python,可以使用 Databricks Python 即時服務 SDK。
筆記本範例
以下筆記本包含不同的 Databricks 已註冊模型,您可用來快速啟動和操作模型服務端點。 如需其他範例,請參閱 教學課程:部署和查詢自定義模型。
您可以遵循匯入 筆記本中的指示,將模型範例匯入工作區。 從其中一個範例中選擇並建立模型之後, 請在 Unity 目錄中註冊模型,然後遵循模型服務的 UI 工作流程 步驟。