本檔提供 MLflow 追蹤數據模型的詳細概觀。 瞭解此模型是運用 MLflow 追蹤來觀察性和分析 Generative AI 應用程式的關鍵。
MLflow 追蹤的設計目的是 要與 OpenTelemetry 規格相容,這是廣為採用的可觀察性業界標準。 這可確保互作性,並允許導出 MLflow 追蹤,並與其他 OpenTelemetry 相容系統搭配使用。 MLflow 藉由定義 Generative AI 使用案例的特定結構和屬性,為品質和效能提供更豐富的內容和更深入的見解,藉此增強基本的 OpenTelemetry Span 模型。
追蹤的結構
從高層次來看,MLflow Trace 由兩個主要物件組成:
小提示
如需如何轉換或擷取數據的詳細資訊,請參閱 API 檔以取得這些資料類別對象的協助程式方法。
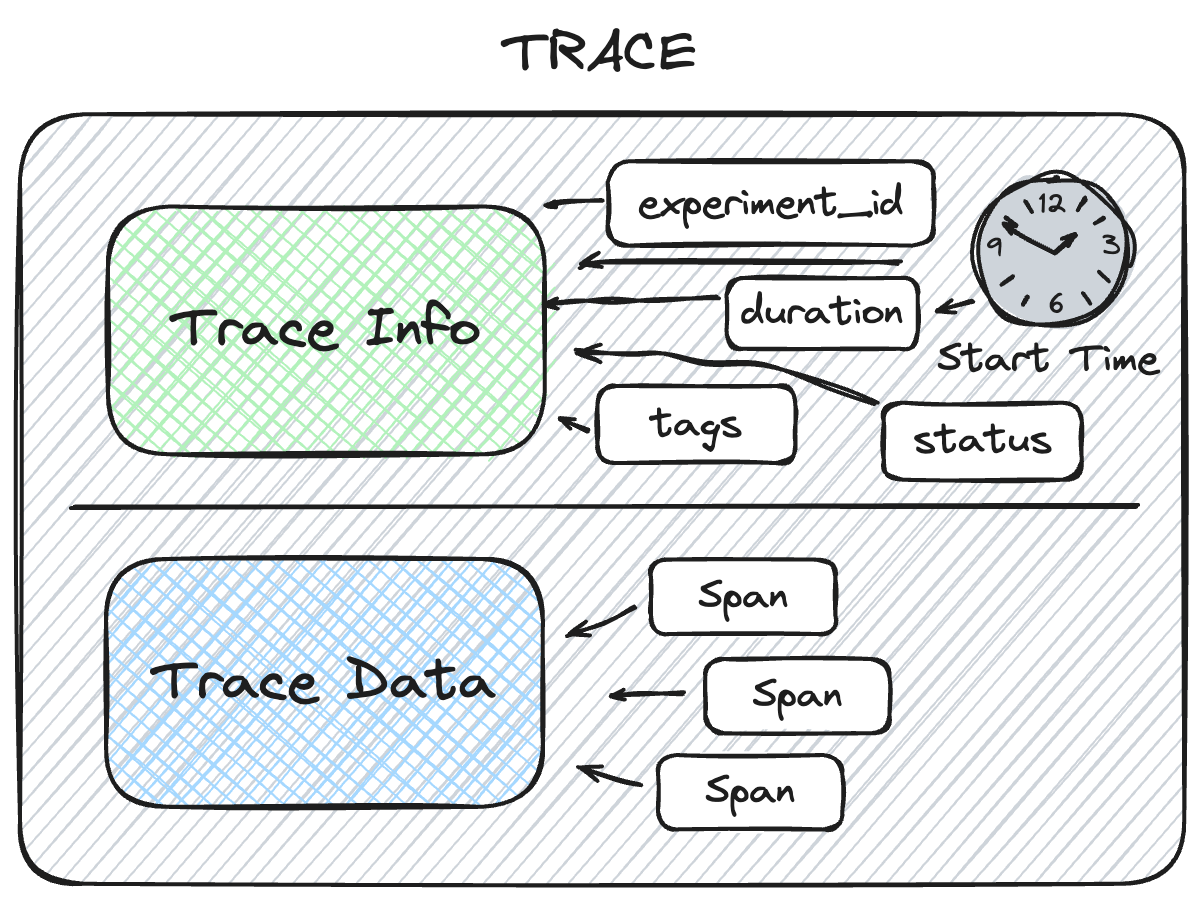
1.追蹤資訊
TraceInfo MLflow 的追蹤功能旨在提供有關整體追蹤的重要數據的輕量快照集。
TraceInfo 是一個包含跟蹤元數據的資料類別物件。
此元數據包含有關追蹤的來源、狀態及各種其他數據的資訊,這些資訊可在 MLflow UI 中使用 mlflow.client.MlflowClient.search_traces 時,協助擷取和篩選追蹤,以及導航追蹤。 若要深入瞭解元數據如何 TraceInfo 用於搜尋,您可以 在這裡查看範例。
| 參數 | 數據類型 | 說明 |
|---|---|---|
trace_id |
str |
追蹤的主要識別碼。 |
trace_location |
TraceLocation |
儲存追蹤的位置,以 :p y:class:~mlflow.entities.TraceLocation 物件表示。 MLflow 目前支援將 MLflow 實驗專案或 Databricks 推理資料表作為追蹤位置。 |
request_time |
int |
追蹤的開始時間,以毫秒為單位。 |
state |
TraceState |
追蹤的狀態,以 :py:class:~mlflow.entities.TraceState 列舉型別表示。 可以是 [OK、ERROR、IN_PROGRESS、STATE_UNSPECIFIED] 的一個選項。 |
request_preview |
Optional[str] |
向模型/代理程式發出的請求,相當於根本範圍的輸入,但以 JSON 編碼,且可能會被截斷。 |
response_preview |
Optional[str] |
來自模型/代理程式的回應,相當於根範圍的輸出,經 JSON 編碼,可截斷。 |
client_request_id |
Optional[str] |
用戶端提供與追蹤相關聯的要求標識碼。 這可用來從產生追蹤的外部系統識別追蹤/要求,例如 Web 應用程式中的會話識別碼。 |
execution_duration |
Optional[int] |
追蹤的持續時間,以毫秒為單位。 |
trace_metadata |
dict[str, str] |
與追蹤相關聯的索引鍵/值組。 它們專為不可變的值所設計,例如與追蹤相關聯的執行標識碼。 |
tags |
dict[str, str] |
與追蹤相關聯的標籤。 它們是針對可變動的值所設計,可在透過 MLflow UI 或 API 建立追蹤之後加以更新。 |
assessments |
list[Assessment] |
與追蹤相關聯的評量清單。 |
物件中包含的 TraceInfo 數據是用來填入 MLflow 追蹤 UI 內的追蹤檢視頁面,如下所示。
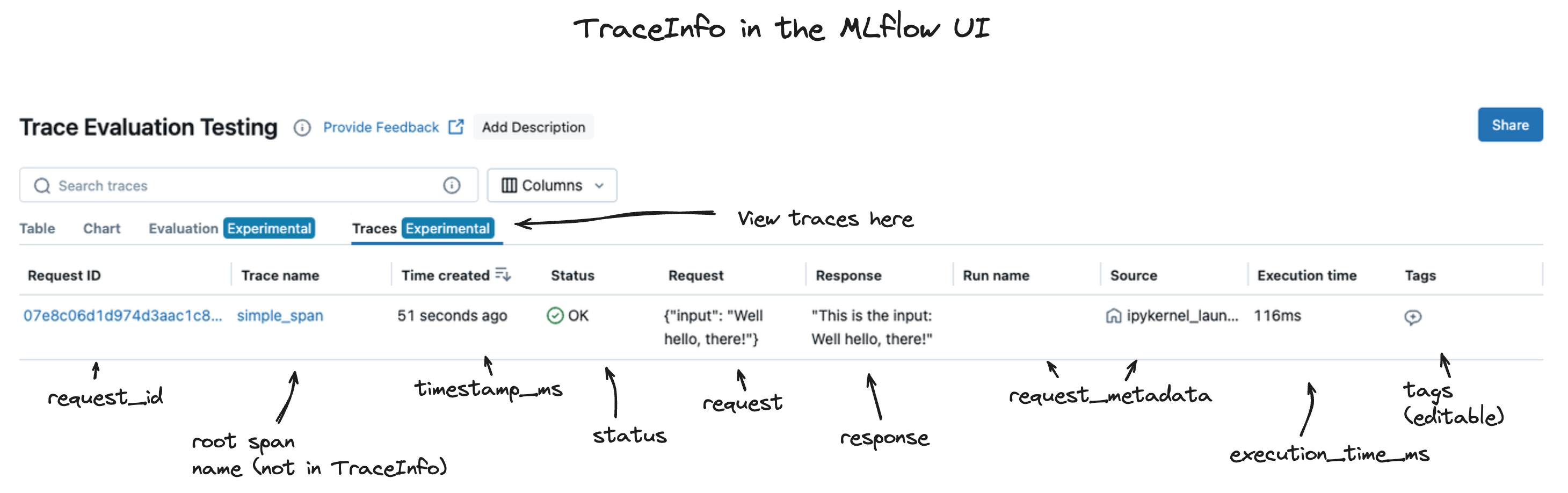
MLflow TraceInfo 物件的主要元件如下所列。
後設資料
評定
評估對於衡量 GenAI 應用程式在追蹤中擷取之行為的品質和正確性至關重要。 它們可讓您將結構化標籤、分數或真實資訊附加至一個追蹤或追蹤中的特定範圍。
MLflow 定義兩種主要評估類型,兩種都繼承自基底 Assessment 概念:
- 回饋:代表對作業輸出進行質化或量化的判斷。 這可以來自人類檢閱者、LLM 即評判或自定義評分功能。
- 預期:代表指定作業的基礎真相或預期結果,通常用於與實際輸出的直接比較。
評估通常會使用 mlflow.log_feedback()、mlflow.log_expectation(),或 mlflow.log_assessment() 這類較一般的函式來記錄到追蹤日志中。
評定來源
每個評量都會與來源相關聯,以追蹤其來源。
-
source_type:mlflow.entities.AssessmentSourceType的枚舉。 核心價值包括:-
HUMAN:由人類提供的意見反應或期望。 -
LLM_JUDGE:由擔任法官的 LLM 所產生的評估。 -
CODE:程序設計規則、啟發學習法或自定義計分器所產生的評量。
-
-
source_id:特定來源的字串標識碼(例如使用者識別碼、LLM 判斷員的模型名稱、腳本名稱)。
from mlflow.entities import AssessmentSource, AssessmentSourceType
# Example: Human source
human_source = AssessmentSource(
source_type=AssessmentSourceType.HUMAN,
source_id="reviewer_alice@example.com"
)
# Example: LLM Judge source
llm_judge_source = AssessmentSource(
source_type=AssessmentSourceType.LLM_JUDGE,
source_id="gpt-4o-mini-evaluator"
)
# Example: Code-based scorer source
code_source = AssessmentSource(
source_type=AssessmentSourceType.CODE,
source_id="custom_metrics/flesch_kincaid_scorer.py"
)
反饋
意見反應會擷取追蹤或範圍輸出品質或特性的判斷。
關鍵欄位:
| 參數 | 數據類型 | 說明 |
|---|---|---|
name |
str |
評量的名稱。 如果未提供,則會使用預設名稱 「feedback」。 |
value |
Optional[FeedbackValueType] |
回饋值。 可以是 float、int、str、bool、這些類型的清單,或是以字串作為鍵和具有這些類型為值的字典。 |
error |
Optional[Union[Exception, AssessmentError]] |
與意見反應相關聯的選擇性錯誤。 這用來指出意見反應無效或無法處理。 接受例外狀況物件、:py:class:~mlflow.entities.Exception 物件或 AssessmentError。 |
rationale |
Optional[str] |
意見反應的原因/正當性。 |
source |
Optional[AssessmentSource] |
評量的來源。 如果未提供,則預設來源為 CODE。 |
trace_id |
Optional[str] |
與評量相關聯的追蹤標識碼。 如果未設定,則評估尚未與任何記錄相關聯。 |
metadata |
Optional[dict[str, str]] |
與評量相關聯的元數據。 |
span_id |
Optional[str] |
如果評量需要與追蹤中的特定範圍相關聯,則為與評量相關聯的範圍 ID。 |
create_time_ms |
Optional[int] |
評估的建立時間,以毫秒為單位。 如果未設定,則會使用目前的時間。 |
last_update_time_ms |
Optional[int] |
評估的最後一次更新時間,以毫秒為單位。 如果未設定,則會使用目前的時間。 |
範例:
import mlflow
from mlflow.entities import Feedback, AssessmentSource, AssessmentSourceType
# Log simple binary feedback
mlflow.log_feedback(
trace_id="trace_123",
name="is_correct",
value=True,
source=AssessmentSource(source_type=AssessmentSourceType.HUMAN, source_id="user_bob"),
rationale="The answer provided was factually accurate."
)
# Log a numeric score from an LLM judge
llm_judge_feedback = Feedback(
name="relevance_score",
value=0.85,
source=AssessmentSource(source_type=AssessmentSourceType.LLM_JUDGE, source_id="claude-3-sonnet"),
rationale="The response directly addressed the user's core question.",
metadata={"judge_prompt_version": "v1.2"}
)
# Assuming trace_id is known, you can also use log_assessment
# mlflow.log_assessment(trace_id="trace_456", assessment=llm_judge_feedback)
期望
期望會定義作業的基礎真相或目標輸出。
關鍵欄位:
| 參數 | 數據類型 | 說明 |
|---|---|---|
name |
str |
評量的名稱。 |
value |
Any |
作業的預期值。 這可以是任何 JSON 可串行化值。 |
source |
Optional[AssessmentSource] |
評量的來源。 如果未提供,則預設來源為 HUMAN。 (如需詳細資訊,請參閱 評定來源 )。 |
trace_id |
Optional[str] |
與評量相關聯的追蹤標識碼。 如果未設定,則評估尚未與任何記錄相關聯。 |
metadata |
Optional[dict[str, str]] |
與評量相關聯的元數據。 |
span_id |
Optional[str] |
如果評量需要與追蹤中的特定範圍相關聯,則為與評量相關聯的範圍 ID。 |
create_time_ms |
Optional[int] |
評估的建立時間,以毫秒為單位。 如果未設定,則會使用目前的時間。 |
last_update_time_ms |
Optional[int] |
評估的最後一次更新時間,以毫秒為單位。 如果未設定,則會使用目前的時間。 |
範例:
import mlflow
from mlflow.entities import Expectation, AssessmentSource, AssessmentSourceType
# Log a ground truth answer
mlflow.log_expectation(
trace_id="trace_789",
name="ground_truth_response",
value="The Battle of Hastings was in 1066.",
source=AssessmentSource(source_type=AssessmentSourceType.HUMAN, source_id="history_expert_01")
)
# Log an expected structured output for a tool call
expected_tool_output = Expectation(
name="expected_tool_call_result",
value={"result": {"status": "success", "data": "item_abc_123"}},
metadata={"tool_name": "inventory_check"}
)
# Assuming trace_id is known:
# mlflow.log_assessment(trace_id="trace_101", assessment=expected_tool_output)
評定錯誤
用來記錄在產生或計算意見反應或預期期間發生的錯誤(例如 LLM 判斷失敗)。
關鍵欄位:
-
error_code(str):錯誤代碼(例如“RATE_LIMIT_EXCEEDED”、“JUDGE_ERROR”)。 -
error_message(選擇性[str]):詳細的錯誤訊息。 -
stack_trace(選擇性[str]):如果有的話,堆疊追蹤。
範例:
import mlflow
from mlflow.entities import AssessmentError, Feedback, AssessmentSource, AssessmentSourceType
judge_error = AssessmentError(
error_code="LLM_JUDGE_TIMEOUT",
error_message="The LLM judge timed out after 30 seconds while assessing relevance."
)
mlflow.log_feedback(
trace_id="trace_error_example",
name="relevance_with_judge_v2",
source=AssessmentSource(source_type=AssessmentSourceType.LLM_JUDGE, source_id="custom_judge_model"),
error=judge_error
# Note: `value` is typically None when an error is provided
)
這些實體提供彈性且結構化的方式,可將豐富的質化和量化數據與您的追蹤產生關聯,形成MLflow追蹤內可觀察性和評估功能的重要部分。
標籤
MLflow tags 物件中的 TraceInfo 屬性是用來為追蹤提供額外上下文。 這些標籤可用於搜尋、篩選或提供追蹤的其他資訊。
標記是索引鍵/值組,而且是可變動的。 這表示您隨時都可以新增、修改或移除標籤,即使在追蹤被記錄到實驗後也一樣。
若要瞭解如何新增自定義標籤以擷取自定義元數據檢視 附加自定義標籤/元數據。
標準標籤
MLflow 會使用一組標準標記來取得使用者、會話和環境的相關常見內容資訊,以啟用 MLflow UI 和 SDK 內的增強篩選和分組功能:
-
mlflow.trace.session:在追蹤使用者和會話中引進的會話標識碼標準標籤。 -
mlflow.trace.user:在追蹤使用者和會話中引進的使用者 ID 標準標籤。 -
mlflow.source.name:產生追蹤的進入點或腳本。 -
mlflow.source.git.commit:如果從 Git 存放庫執行,則原始程式碼的認可哈希。 -
mlflow.source.type:產生追蹤的來源類型,通常是PROJECT(針對 MLflow 專案執行)或NOTEBOOK(如果從筆記本執行)。
您可以在追蹤 使用者和工作階段 和 追蹤環境與內容的指南中深入瞭解如何實作這些專案。
2. 追蹤數據
可透過TraceData 存取的 MLflow Trace.data 物件,保存了追蹤的核心載荷。 它主要包含發生的作業順序(spans),以及觸發追蹤的初始要求和產生的最終回應。
關鍵欄位:
spans(列表[Span]):- 這是一個遵循
Span和 OpenTelemetry 規格的mlflow.entities.Span物件清單,代表追蹤內個別步驟、作業或函數調用。 每個範圍都會詳細說明特定工作單位。 - 範圍會依階層方式
parent_id組織,以表示執行流程。 - 如需對象的詳細明細,請參閱下方的 Span架構 一
Span節。
- 這是一個遵循
備註
request和 response 屬性會保留以供回溯相容性使用。 其值取自根範圍中的各自 inputs 和 outputs 屬性,並且不會直接由使用者在 TraceData 物件上設定。
request(str):- JSON 串行化字串,表示追蹤根範圍的輸入數據。 這通常是使用者的要求或叫用追蹤應用程式或工作流程的初始參數。
-
範例:
'{"query": "What is MLflow Tracing?", "user_id": "user123"}'
response(str):- JSON 串行化字串,表示來自追蹤應用程式或工作流程根範圍的最終輸出數據。
-
範例:
'{"answer": "MLflow Tracing provides observability...", "confidence": 0.95}'
概念表示法:
雖然您通常會透過用戶端擷取的一個TraceData對象與mlflow.entities.Trace進行互動(例如 client.get_trace(trace_id).data),但從概念上講,它會將這些核心元件組合在一起:
# Conceptual structure (not direct instantiation like this)
class TraceData:
def __init__(self, spans: list[Span], request: str, response: str):
self.spans = spans # List of Span objects
self.request = request # JSON string: Overall input to the trace
self.response = response # JSON string: Overall output of the trace
瞭解 TraceData 是以程序設計方式分析 GenAI 應用程式生命週期中詳細執行路徑和資料轉換的關鍵。
範圍
MLflow 追蹤功能內的 Span 物件會提供有關追蹤個別步驟的詳細資訊。
它符合 OpenTelemetry Span 規格。每個Span物件都包含所檢測步驟的相關信息,包括span_id、名稱、start_time、parent_id、狀態、輸入、輸出、屬性和事件。
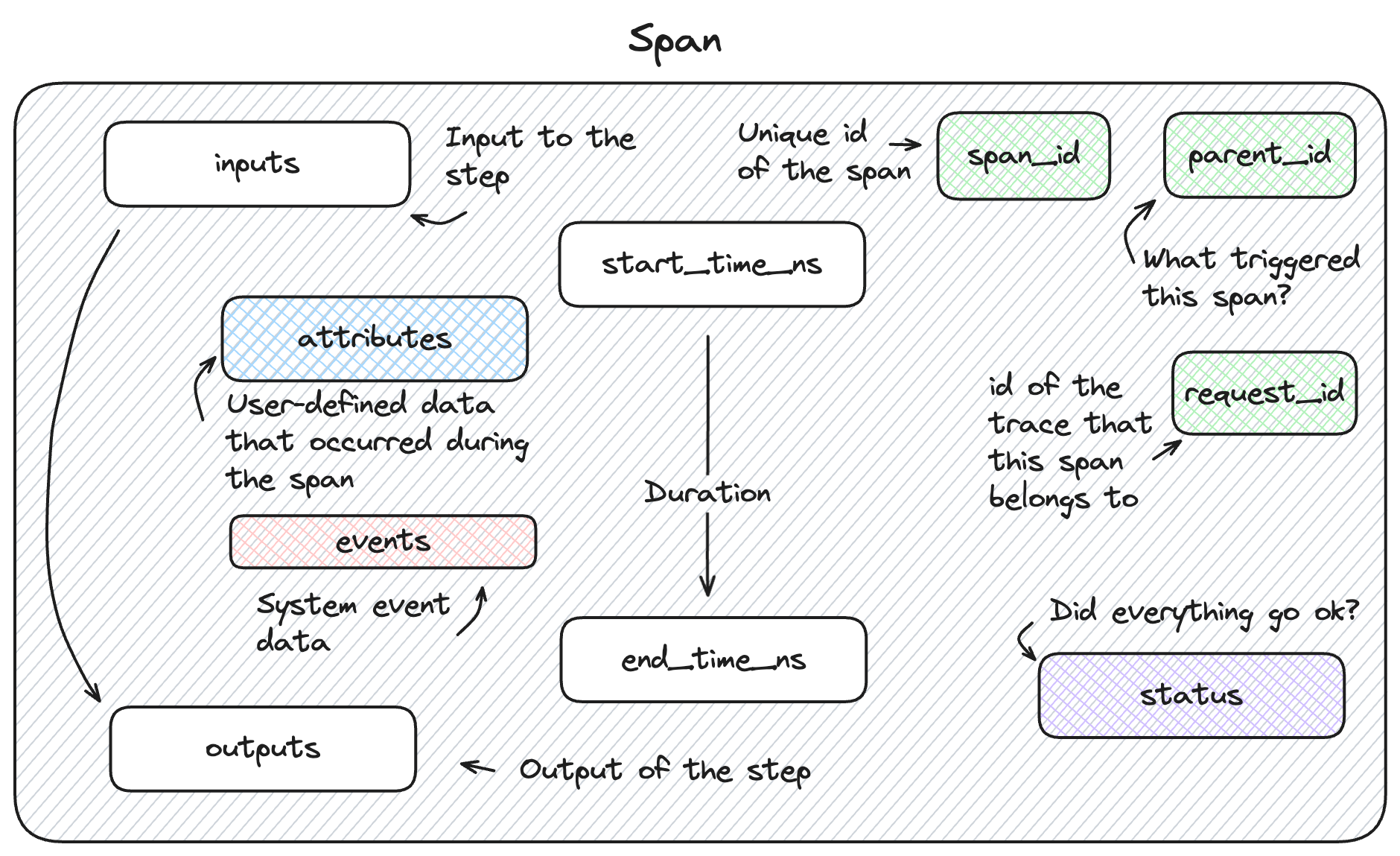
Span 架構
區段是追蹤資料的核心。 他們會記錄 Genai 應用程式內每個步驟的關鍵關鍵數據。
當您在 MLflow UI 中檢視追踪資料時,您會看到一系列資料範圍,如下所示。
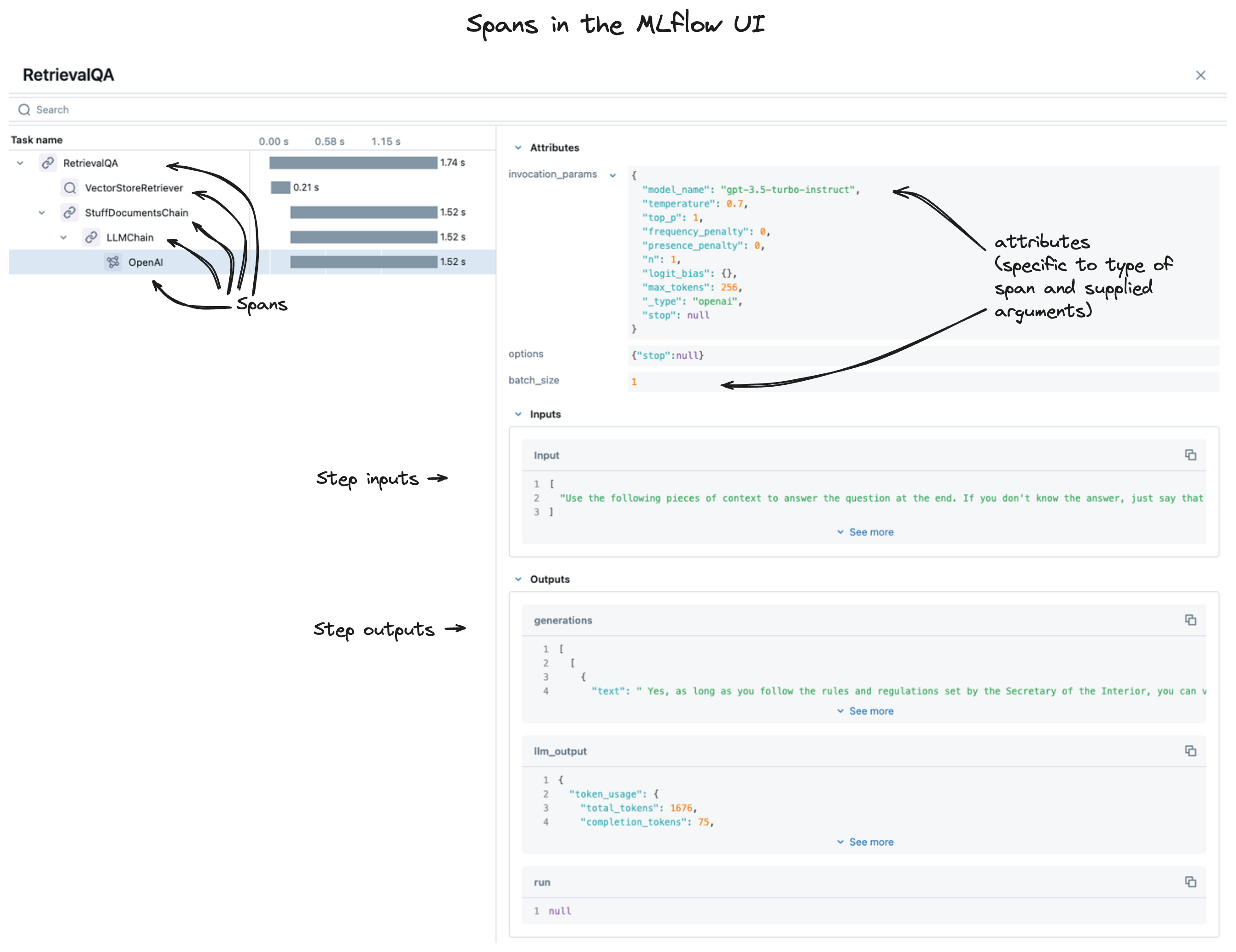
下列各節提供跨度結構的詳細檢視。
範圍類型
Span 類型是一種用來分類追蹤中範圍的方法。 根據預設,使用追蹤裝飾專案時,範圍類型會設定為 "UNKNOWN" 。 MLflow 會針對常見的使用案例提供一組預先定義的範圍類型,同時可讓您設定自定義範圍類型。
下列範圍類型可供使用。 此外,您可以將範圍類型設定為任何開發人員指定的 str 值。
| 範圍類型 | 說明 |
|---|---|
"CHAT_MODEL" |
表示聊天模型的查詢。 這是 LLM 互動的特殊案例。 |
"CHAIN" |
表示一系列的操作。 |
"AGENT" |
表示自主代理作業。 |
"TOOL" |
表示工具執行(通常是由代理程序執行),例如查詢搜尋引擎。 |
"EMBEDDING" |
表示文字內嵌作業。 |
"RETRIEVER" |
表示內容擷取作業,例如查詢向量資料庫。 |
"PARSER" |
表示剖析作業,將文字轉換成結構化格式。 |
"RERANKER" |
表示重新排名作業,並根據相關性排序擷取的內容。 |
"UNKNOWN" |
未指定其他範圍類型時使用的預設範圍類型。 |
若要設定範圍類型,您可以將 參數傳遞 span_type 至 mlflow.trace 裝飾專案或 mlflow.start_span 內容管理員。 當您使用 自動追蹤時,範圍類型會自動由 MLflow 設定。
import mlflow
from mlflow.entities import SpanType
# Using a built-in span type
@mlflow.trace(span_type=SpanType.RETRIEVER)
def retrieve_documents(query: str):
...
# Setting a custom span type
with mlflow.start_span(name="add", span_type="MATH") as span:
span.set_inputs({"x": z, "y": y})
z = x + y
span.set_outputs({"z": z})
print(span.span_type)
# Output: MATH
特定範圍類型的架構
MLflow 有一組預先定義的範圍類型(請參閱 mlflow.entities.SpanType),而特定範圍類型具有必要的屬性,才能在UI和下游工作中啟用其他功能,例如評估。
檢索器範圍
範圍 RETRIEVER 類型用於涉及從數據存放區擷取數據的作業(例如,從向量存放區查詢檔)。 跨距 RETRIEVER 的輸出預期是文件清單。
清單中的每份檔都應該是字典(或可以使用下列索引鍵串行化至字典的物件),而且理想情況下包括:
-
page_content(str):所擷取檔區塊的文字內容。 -
metadata(Optional[Dict[str, Any]]):與文件相關聯的其他元數據字典。- MLflow UI 和評估指標可能會在此元數據中特別尋找
doc_uri(檔案來源的字串 URI)和chunk_id(如果檔案是較大區塊檔案的一部分,則為字串識別符),以增強顯示和功能。
- MLflow UI 和評估指標可能會在此元數據中特別尋找
-
id(Optional[str]):文件區塊本身的選擇性唯一標識符。
Retriever Span 運作的範例:
import mlflow
from mlflow.entities import SpanType, Document
def search_store(query: str) -> list[(str, str)]:
# Simulate retrieving documents (e.g., from a vector database)
return [
("MLflow Tracing helps debug GenAI applications...", "docs/mlflow/tracing_intro.md"),
("Key components of a trace include spans...", "docs/mlflow/tracing_datamodel.md"),
("MLflow provides automatic instrumentation...", "docs/mlflow/auto_trace.md")
]
@mlflow.trace(span_type=SpanType.RETRIEVER)
def retrieve_relevant_documents(query: str):
# Get documents from the search store
docs = search_store(query)
# Get the current active span (created by @mlflow.trace)
span = mlflow.get_current_active_span()
# Set the outputs of the span in accordance with the tracing schema
outputs = [Document(page_content=doc, metadata={"doc_uri": uri}) for doc, uri in docs]
span.set_outputs(outputs)
# Return the original format for downstream usage
return docs
# Example usage
user_query = "MLflow Tracing benefits"
retrieved_docs = retrieve_relevant_documents(user_query)
# Read path: Reconstructing the document list from the span outputs
trace_id = mlflow.get_last_active_trace_id()
trace = mlflow.get_trace(trace_id)
span = trace.search_spans(name="retrieve_relevant_documents")[0]
documents = [Document(**doc) for doc in span.outputs]
print(documents)
符合此結構,尤其包括 page_content 和類似的相關 metadatadoc_uri,可確保 RETRIEVER 範圍在 MLflow UI 中以提供相關資訊的方式呈現(例如,顯示文件內容並提供連結),並使下游評估任務能正確地處理擷取的內容。
聊天完成和工具通話範圍
類型為 CHAT_MODEL 或 LLM 的範圍可用來表示與聊天完成 API 的互動(例如,OpenAI 的 聊天完成或 Anthropic 的 訊息 API)。 這些範圍也可以擷取模型提供給或使用的工具(函式)相關信息。
由於提供者可以有不同的 API 架構,因此對原始 LLM 呼叫本身之範圍輸入和輸出的格式沒有嚴格的限制。 不過,若要啟用豐富的UI功能(例如交談顯示和工具通話視覺效果),以及標準化數據以進行評估,MLflow 會定義聊天訊息和工具定義的特定屬性。
如需了解如何使用上述公用程式函式進行快速示範,以及如何使用 `span.get_attribute()` 函式來擷取這些函式,請參閱下列範例:
import mlflow
from mlflow.entities.span import SpanType # Corrected from mlflow.entities.span import SpanType
from mlflow.tracing.constant import SpanAttributeKey
from mlflow.tracing import set_span_chat_messages, set_span_chat_tools
# example messages and tools
messages = [
{
"role": "system",
"content": "please use the provided tool to answer the user's questions",
},
{"role": "user", "content": "what is 1 + 1?"},
]
tools = [
{
"type": "function",
"function": {
"name": "add",
"description": "Add two numbers",
"parameters": {
"type": "object",
"properties": {
"a": {"type": "number"},
"b": {"type": "number"},
},
"required": ["a", "b"],
},
},
}
]
@mlflow.trace(span_type=SpanType.CHAT_MODEL)
def call_chat_model(messages, tools):
# mocking a response
response = {
"role": "assistant",
"tool_calls": [
{
"id": "123",
"function": {"arguments": '{"a": 1,"b": 2}', "name": "add"},
"type": "function",
}
],
}
combined_messages = messages + [response]
span = mlflow.get_current_active_span()
set_span_chat_messages(span, combined_messages)
set_span_chat_tools(span, tools)
return response
call_chat_model(messages, tools)
trace = mlflow.get_last_active_trace()
span = trace.data.spans[0]
print("Messages: ", span.get_attribute(SpanAttributeKey.CHAT_MESSAGES))
print("Tools: ", span.get_attribute(SpanAttributeKey.CHAT_TOOLS))
後續步驟
使用這些建議的動作和教學課程繼續您的旅程。
- 在您的應用程式中整合追蹤功能 - 應用這些數據模型概念以將追蹤功能新增至您的應用程式
- 透過 SDK 查詢追蹤 - 使用資料模型以程式設計方式分析追蹤
- 附加自訂標籤/元數據 - 使用內容資訊擴充追蹤
參考指南
請查閱有關相關概念的詳細文件。