本頁介紹筆記型電腦運算資源的選項。 您可以在通用計算資源、無伺服器計算上運行筆記本,或者,對於 SQL 命令,您可以使用 SQL 儲存庫,這是一種針對 SQL 分析優化的計算類型。 欲了解更多關於計算型別的資訊,請參見 Compute。
預設運算
在啟用 Unity Catalog 的工作區中,新筆記型電腦預設為無伺服器運算。 如果你沒有手動選擇運算資源並執行一個儲存格,筆記本會自動連接到無伺服器運算。
自動附加計算
在開發者的設定中,你可以設定筆記本自動連接到運算資源,並在與編輯器互動時啟動工作階段:
點擊左上角的使用者圖示。
點選 [設定]。
點選 開發 者以進入開發者設定。
切換「 自動建立編輯器互動會話 」,即可自動啟動編輯器互動的計算工作階段。 Databricks 預設會根據你的偏好選擇計算資源(無伺服器或 SQL 倉庫)以及最後使用的運算資源。
OR
如果你不想讓筆記本自動連接並啟動運算資源,請關閉這個設定。
程式碼輔助功能,包括自動補全、程式碼格式化及除錯器,都需要筆記本連接到活躍的運算會話。 如果筆記本還沒啟動運算會話,程式碼協助功能就會失效。
筆記本的無伺服器運算
無伺服器計算可讓您快速將筆記本連線到隨需計算資源。
要連接到無伺服器運算,請在筆記本中點擊計算下拉選單,選擇 無伺服器。
如需詳細資訊,請參閱筆記本的無伺服器計算。
無伺服器筆記本的自動化會話還原
閒置終止無伺服器運算可能會導致你在筆記本中遺失正在進行的工作,例如 Python 變數值。 為了避免這種情況,請開啟 無伺服器筆記本的自動會話還原功能。
- 點選工作區右上角的使用者名稱,然後在下拉選單中點選 設定 。
- 在 [設定] 側邊欄中,選取 [開發人員]。
- 在 實驗性功能 下,切換開啟 無伺服器筆記本的自動化會話還原 設定。
啟用此設定後,Databricks 能在閒置終止前快照無伺服器筆記本的記憶體狀態。 當您因閒置而中斷連線後返回筆記本時,頁面頂端會出現橫幅。 按一下 重新連線 以還原您的工作狀態。
當您重新連線時,Databricks 會還原您的整個工作環境,包括:
- Python變數、函式和類別定義:Python狀態在過程中用 pickle/cloudpickle 序列化,並恢復到新的 REPL,所以你不需要重新匯入或重新宣告。
- Spark DataFrames、快取與臨時視圖:您已載入、轉換或快取的資料(包括暫存視圖)會被保留,避免昂貴的重新載入或重新計算。
- Spark session 狀態:Spark 層級的設定設定、暫時檢視、目錄修改及使用者自訂函數(UDF)會透過 Spark Connect 會話遷移恢復,因此無需重置。
如果環境發生了導致反序列化不安全的變化,例如不相容的 Python 或套件版本,快照會失效,筆記本會退回到新的會話。
快照資料儲存
快照資料會儲存在你工作區 的預設儲存中。 筆記本本身僅儲存元資料,包括帶有筆記本 ID 的指標、時間戳記和會話資訊。 資料有效載荷並未儲存在筆記本中。 blob 路徑在儲存在筆記本屬性前會先加密,快照路徑則被排除在筆記本匯出與匯入之外,以防止狀態還原到其他工作區。
快照會遵循你的雲端儲存 TTL 預設值(約一個月)並自動過期。 刪除筆記本時,快照備份也將被刪除。 您的雲端帳號會因標準工作空間儲存使用而產生儲存費用。 此功能使用 Python 程序序列化,取代容器層級檢查點,讓快照更小且更快建立。
安全性與存取控制
快照還原會尊重筆記本的權限。 還原狀態需要筆記本上的 RUN 權限。 加密的元資料防止檢視器直接擷取快照塊狀資料,且還原時會強制執行權限檢查。
局限性
此功能有限制,且不支援還原以下內容:
- 超過 4 天的 Spark 狀態資料
- Spark 狀態大於 50 MB
- 與 SQL 腳本相關的資料
- 文件控制代碼
- 鎖定和其他並行基本類型
- 網路連線
將筆記本附加至所有用途的計算資源
若要將筆記本連結到通用計算資源,您需要在計算資源上具有 CAN ATTACH TO 權限。
重要
只要筆記本附加至計算資源,任何具有筆記本上 CAN RUN 許可權的使用者 具有存取計算資源的隱含許可權。
要將筆記本連接到運算資源,請在 筆記本工具列中點擊計算選擇器 ,從下拉選單中選擇該資源。
功能表會顯示您最近使用或目前正在執行之所有用途計算和 SQL 倉儲的選取範圍。

若要從所有可用的計算中選取,請按一下 [更多...]。 從可用的一般計算或 SQL 倉儲中選取 。

你也可以從下拉選單選擇「建立新資源......」來建立一個多功能的運算資源。
重要
連結的筆記本已定義下列 Apache Spark 變數。
| 類別 | 變數名稱 |
|---|---|
SparkContext |
sc |
SQLContext/HiveContext |
sqlContext |
SparkSession (Spark 2.x) |
spark |
不要建立 SparkSession、 SparkContext或 SQLContext。 這樣做會導致行為不一致。
搭配使用筆記本與 SQL 倉儲
當筆記本連結至 SQL 倉儲時,您可以執行 SQL 和 Markdown 儲存格。 用其他語言(例如 Python 或 R)執行儲存格會丟出錯誤。 在 SQL 倉儲上執行的 SQL 數據格會出現在 SQL 倉儲的查詢歷程記錄中。 透過按下輸出底部的已耗用時間,執行查詢的使用者可以從筆記本中檢視查詢設定檔。
綁定在 SQL 倉庫上的筆記本支援 SQL 倉庫會話,你可以定義變數、建立暫存視圖,並在多次查詢執行中持續保存狀態。 你可以迭代地建立 SQL 邏輯,而不需要一次執行所有語句。 請參閱什麼是 SQL 資料庫工作階段?。
執行筆記本需要專業或無伺服器 SQL 倉儲。 您必須能夠存取工作區和 SQL 倉儲。
若要將筆記本連結至 SQL 倉儲,請執行下列動作:
按下筆記本工具列中的計算選取器。 下拉選單顯示目前正在運行或你最近使用的運算資源。 SQL 倉儲會標示為
 。
。從功能表中,選取 SQL 倉儲。
要查看所有可用的 SQL 倉庫,請從下拉選單中選擇「更多」。 隨即出現一個對話方塊,其中顯示筆記本可用的計算資源。 選擇 SQL Warehouse,選擇你想使用的倉庫,然後點 選附加。
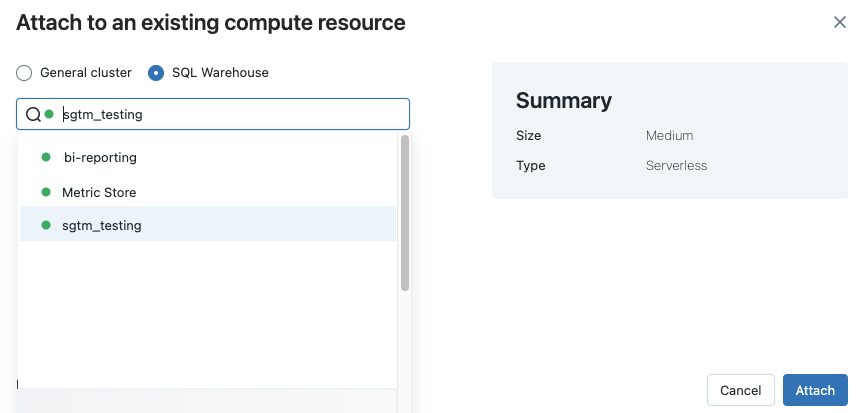
您也可以在建立工作流程或排程作業時,選取 SQL 倉儲作為 SQL 筆記本的計算資源。
SQL 倉儲限制
欲了解更多資訊,請參閱 Databricks 筆記本的已知限制 。