注意
本文中的建議不適用於 Unity 目錄受控數據表。 Databricks 建議為所有新建的資料表使用 Unity Catalog 管理的資料表,並使用預設的設定。
在 Databricks Runtime 13.3 及以上版本中,Databricks 建議使用叢集來進行資料表佈局。 請參閱 針對數據表使用液體叢集。
Databricks 建議使用預測優化來自動執行 OPTIMIZE 和 VACUUM,針對資料表。 請參閱 Unity Catalog 受控資料表的預測性最佳化。
在 Databricks Runtime 10.4 LTS 和更新版本中,一律會針對 MERGE、 UPDATE和 DELETE 作業啟用自動壓縮和優化寫入。 您無法停用此功能。
有手動或自動設定寫入及 OPTIMIZE 操作目標檔案大小的選項。 Azure Databricks 會自動調整其中許多設定,並啟用能透過適當調整檔案大小來自動改善資料表性能的功能。
針對 Unity 目錄受控數據表,如果您使用 SQL 倉儲或 Databricks Runtime 11.3 LTS 或更新版本,Databricks 會自動調整大部分的設定。
如果您要從 Databricks Runtime 10.4 LTS 或以下版本升級工作負載,請參閱 升級至背景自動壓縮。
執行時機 OPTIMIZE
自動壓縮和優化寫入會減少小型檔案問題,但並非 完全取代 OPTIMIZE。 特別是對於大於 1 TB 的數據表,Databricks 建議依排程執行 OPTIMIZE 以進一步合併檔案。 Azure Databricks 不會自動對表格執行 ZORDER,因此您必須執行 OPTIMIZE 和 ZORDER,才能啟用增強的資料略過。 詳見資料跳過。
什麼是 Azure Databricks 上的自動優化?
有時候,術語自動優化用來描述由autoOptimize.autoCompact和autoOptimize.optimizeWrite設定所控制的功能。 此字詞已淘汰,以利個別描述每個設定。 請參見 自動壓縮 與 最佳化寫入。
自動壓縮
自動壓縮會將小檔案合併在資料表分割區中,以自動減少小檔案問題。 自動壓縮會在成功寫入資料表之後進行,並在已執行寫入的叢集上同步執行。 自動壓縮只會壓縮先前尚未壓縮的檔案。
透過設定 Spark 設定spark.databricks.delta.autoCompact.maxFileSize Delta 或 spark.databricks.iceberg.autoCompact.maxFileSize Iceberg 來控制輸出檔案大小。 Databricks 建議根據工作負載或數據表大小使用自動調整。 請參閱 根據工作負載 自動調整檔案大小,以及 根據數據表大小自動調整檔案大小。
只有至少有一定數目小型檔案的分割區或數據表,才會觸發自動壓縮。 可以選擇設定 Delta spark.databricks.delta.autoCompact.minNumFiles 或設定 Iceberg spark.databricks.iceberg.autoCompact.minNumFiles,以調整觸發自動壓縮所需的最小檔案數量。
請使用以下設定在資料表或會話層級啟用自動壓縮:
- 表格屬性:
autoOptimize.autoCompact - SparkSession 設定:
spark.databricks.delta.autoCompact.enabled(Delta)或spark.databricks.iceberg.autoCompact.enabled(Iceberg)
這些設定接受下列選項:
| 選項 | 行為 |
|---|---|
auto (建議) |
調整目標檔案大小,同時遵守其他自動調整功能。 需要 Databricks Runtime 10.4 LTS 或更新版本。 |
legacy |
true 的別名。 需要 Databricks Runtime 10.4 LTS 或更新版本。 |
true |
使用 128 MB 作為目標檔案大小。 沒有動態尺寸。 |
false |
關閉自動壓縮。 可在會話層級設定,覆蓋工作負載中所有修改過的資料表的自動壓縮。 |
重要
在 Databricks Runtime 9.1 LTS 中,當其他寫入器同時執行 DELETE、MERGE、UPDATE 或 OPTIMIZE 等作業時,自動壓縮可能會導致那些作業因交易衝突而失敗。 這不是 Databricks Runtime 10.4 LTS 和更新版本的問題。
優化寫入
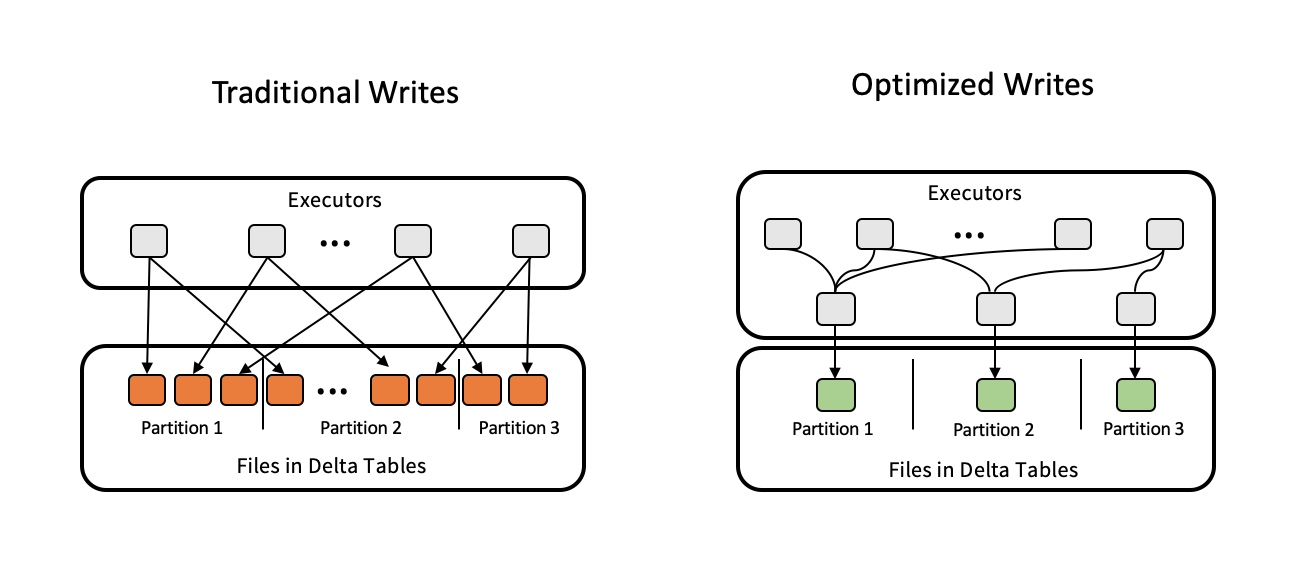
最佳化寫入可改善檔案大小,因為資料會寫入,並有利於資料表上的後續讀取。
最佳化寫入對分割表格最有效,因為這些會減少寫入到每個分割區的小型檔案數量。 寫入較少的大型檔案比寫入許多小型檔案更有效率,但由於數據在寫入前會重新排列,您仍然可能會看到寫入延遲增加。
下圖示範優化寫入的運作方式:
注意
您可能會在資料寫入之前執行程式碼 coalesce(n) 或 repartition(n),以控制生成的檔案數目。 優化的寫入不需要使用此模式。
Databricks Runtime 9.1 LTS 和更新版本中的下列作業預設會啟用優化寫入:
MERGE-
UPDATE含子查詢 -
DELETE含子查詢
使用 SQL 倉儲時,將會針對 CTAS 語句和 INSERT 作業啟用優化的寫入功能。 在 Databricks Runtime 13.3 LTS 及以上版本中,Unity 目錄中所有註冊的資料表都啟用了針對分割資料表的 CTAS 語句與 INSERT 操作的最佳化寫入功能。
您可以使用下列設定,在資料表或工作階段層級啟用優化寫入:
- 表格屬性:
autoOptimize.optimizeWrite - SparkSession 設定:
spark.databricks.delta.optimizeWrite.enabled(Delta)或spark.databricks.iceberg.optimizeWrite.enabled(Iceberg)
這些設定接受下列選項:
| 選項 | 行為 |
|---|---|
true |
使用 128 MB 作為目標檔案大小。 |
false |
關閉優化的寫入。 可在會話層級設定,覆蓋工作負載中所有修改過的資料表的自動壓縮。 |
設定目標檔案大小
如果你想調整表格中檔案大小,請將 表格屬性targetFileSize 設定為所需的大小。 如果設定這個屬性,所有數據配置優化作業都會盡最大努力嘗試產生指定大小的檔案。 這裡的範例包括 優化 或 Z 順序、 自動壓縮和 優化的寫入。
注意
使用 Unity 目錄受控數據表和 SQL 倉儲或 Databricks Runtime 11.3 LTS 和更新版本時,只有 OPTIMIZE 命令會遵守 targetFileSize 設定。
| 房產 | Description |
|---|---|
delta.targetFileSize (德爾塔)iceberg.targetFileSize (冰山) |
類型:以位元組或更高單位為單位大小。 說明:目標檔案大小。 例如, 104857600 (位元元組)或 100mb。預設值:無 |
對於現有的數據表,您可以使用 SQL 命令 ALTER TABLESET TBL PROPERTIES來設定和取消設定屬性。 您也可以在使用 Spark 工作階段設定建立新資料表時自動設定這些屬性。 詳情請參閱「表格屬性參考」。
根據工作負載自動調整檔案大小
不論 Databricks 執行環境、Unity Catalog 或其他優化技術為何,針對被多個 tuneFileSizesForRewrites 或 DML 作業操作的所有資料表,Databricks 建議將資料表屬性 true 設定為 MERGE。 當設定為 true時,數據表的目標檔案大小會設定為較低的閾值,以加速大量寫入作業。
若未明確設定,Azure Databricks 會自動偵測資料表中最近 10 次操作中有 9 次為 MERGE 操作,並將此資料表屬性設定為 true。 您必須明確地將這個屬性設定為 , false 以避免這種行為。
| 房產 | Description |
|---|---|
delta.tuneFileSizesForRewrites (德爾塔)iceberg.tuneFileSizesForRewrites (冰山) |
類型:Boolean說明:是否要調整檔案大小以優化資料版面。 預設值:無 |
對於現有的數據表,您可以使用 SQL 命令 ALTER TABLESET TBL PROPERTIES來設定和取消設定屬性。 您也可以在使用 Spark 工作階段設定建立新資料表時自動設定這些屬性。 詳情請參閱「表格屬性參考」。
根據數據表大小自動調整檔案大小
為了減少手動調整的需求,Azure Databricks 會根據資料表大小自動調整資料表的檔案大小。 Azure Databricks 會針對較小的數據表使用較小的檔案大小,而較大的數據表則使用較大的檔案大小,讓數據表中的檔案數目不會成長太大。 Azure Databricks 不會自動調整您已針對特定 目標大小 微調的數據表,或根據經常重寫的工作負載。
目標檔案大小是根據目前資料表的大小決定的。 對於小於 2.56 TB 的數據表,自動調整的目標檔案大小為 256 MB。 對於大小介於 2.56 TB 到 10 TB 之間的數據表,目標大小會以線性方式從 256 MB 成長至 1 GB。 對於大於 10 TB 的數據表,目標檔案大小為 1 GB。
注意
當數據表的目標檔案大小成長時,命令不會將現有的檔案重新優化為較大的檔案 OPTIMIZE 。 因此,大型數據表一律會有一些小於目標大小的檔案。 如果需要將這些較小的檔案優化為較大的檔案,您可以使用 table 屬性來設定數據表 targetFileSize 的固定目標檔案大小。
以累加方式寫入數據表時,目標檔案大小和檔案計數會根據數據表大小接近下列數位。 此數據表中的檔案計數只是範例。 實際結果會根據許多因素而有所不同。
| 資料表大小 | 目標檔案大小 | 數據表中檔案的近似數目 |
|---|---|---|
| 10 GB | 256 MB | 40 |
| 1 TB | 256 MB | 4096 |
| 2.56 TB | 256 MB | 10240 |
| 3TB | 307 MB | 12108 |
| 5 TB (兆位元組) | 512 MB | 17339 |
| 7TB | 716 MB | 20,784 |
| 10 結核病 | 1 GB | 24437 |
| 20 TB(兆字節) | 1 GB | 34437 |
| 50 TB | 1 GB | 64437 |
| 100 結核病 | 1 GB | 114437 |
限制在資料檔案中寫入的行數
有時候,具有窄數據的數據表可能會遇到錯誤,其中指定數據檔中的數據列數目超過 Parquet 格式的支援限制。 為了避免這個錯誤,你可以使用 SQL 會話設定 spark.sql.files.maxRecordsPerFile ,指定一個資料表要寫入單一檔案的最大記錄數。 指定零的值或負值不代表任何限制。
在 Databricks Runtime 11.3 LTS 及以上版本中,使用 DataFrame API 寫入資料表時,也可以使用 DataFrameWriter 選項 maxRecordsPerFile 。 當指定 maxRecordsPerFile 時,會忽略 SQL 會話設定 spark.sql.files.maxRecordsPerFile 的值。
注意
除非有必要避免上述錯誤,否則 Databricks 不建議使用此選項。 某些具有非常窄數據的 Unity 目錄受控數據表可能仍然需要此設定。
升級至背景自動壓縮
在 Databricks Runtime 11.3 LTS 及以上版本中,Unity Catalog 管理的資料表可用背景自動壓縮功能。 移轉舊版工作負載或數據表時,請執行下列動作:
- 從叢集或筆記型電腦設定中移除 Spark 設定
spark.databricks.delta.autoCompact.enabled(Delta)或spark.databricks.iceberg.autoCompact.enabled(Iceberg)。 - 對每個資料表,執行
ALTER TABLE <table_name> UNSET TBLPROPERTIES (delta.autoOptimize.autoCompact)(Delta) 或ALTER TABLE <table_name> UNSET TBLPROPERTIES (iceberg.autoOptimize.autoCompact)(Iceberg) 以移除任何舊有的自動壓縮設定。
拿掉這些舊版設定之後,您應該會看到針對所有 Unity 目錄受控數據表自動觸發的背景自動壓縮。