使用 Azure Databricks 作業建立您的第一個工作流程
本文示範 Azure Databricks 作業 ,可協調工作來讀取及處理範例數據集。 在本快速入門中,您將:
- 建立新的筆記本並新增程序代碼,以依年份擷取包含熱門嬰兒名稱的範例數據集。
- 將範例數據集儲存至 Unity 目錄。
- 建立新的筆記本,並新增程式代碼以從 Unity 目錄讀取數據集、依年份篩選,以及顯示結果。
- 建立新的作業,並使用筆記本設定兩項工作。
- 執行作業並檢視結果。
需求
如果您的工作區已啟用 Unity 目錄,且 已啟用無伺服器工作流程 ,則作業預設會在無伺服器計算上執行。 您不需要叢集建立許可權,即可使用無伺服器計算來執行作業。
否則,您必須擁有 叢集建立許可權 ,才能建立作業計算或 所有用途計算資源的許可權 。
您必須在 Unity 目錄中有磁碟區。 本文會在名為 main的目錄中,使用名為 my-volume 的架構中名為 default 的磁碟區。 此外,您必須在 Unity 目錄中具有下列權限:
READ VOLUME和WRITE VOLUME、 或ALL PRIVILEGES,適用於磁碟區my-volume。USE SCHEMA或ALL PRIVILEGES架構。defaultUSE CATALOG或ALL PRIVILEGES目錄main。
若要設定這些許可權,請參閱 Databricks 系統管理員或 Unity 目錄許可權和安全性實體物件。
建立筆記本
擷取和儲存數據
若要建立筆記本以擷取範例數據集,並將它儲存至 Unity 目錄:
移至您的 Azure Databricks 登陸頁面,然後按下
 提要欄位中的 [新增 ],然後選取 [Notebook]。 Databricks 會在預設資料夾中建立並開啟新的空白筆記本。 默認語言是您最近使用的語言,而且筆記本會自動附加至您最近使用的計算資源。
提要欄位中的 [新增 ],然後選取 [Notebook]。 Databricks 會在預設資料夾中建立並開啟新的空白筆記本。 默認語言是您最近使用的語言,而且筆記本會自動附加至您最近使用的計算資源。如有必要, 請將默認語言變更為 Python。
複製下列 Python 程式代碼,並將它貼到筆記本的第一個數據格中。
import requests response = requests.get('https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv') csvfile = response.content.decode('utf-8') dbutils.fs.put("/Volumes/main/default/my-volume/babynames.csv", csvfile, True)
讀取和顯示篩選的數據
若要建立筆記本來讀取和呈現要篩選的數據:
移至您的 Azure Databricks 登陸頁面,然後按下
提要欄位中的 [新增 ],然後選取 [Notebook]。 Databricks 會在預設資料夾中建立並開啟新的空白筆記本。 默認語言是您最近使用的語言,而且筆記本會自動附加至您最近使用的計算資源。如有必要, 請將默認語言變更為 Python。
複製下列 Python 程式代碼,並將它貼到筆記本的第一個數據格中。
babynames = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/Volumes/main/default/my-volume/babynames.csv") babynames.createOrReplaceTempView("babynames_table") years = spark.sql("select distinct(Year) from babynames_table").toPandas()['Year'].tolist() years.sort() dbutils.widgets.dropdown("year", "2014", [str(x) for x in years]) display(babynames.filter(babynames.Year == dbutils.widgets.get("year")))
建立作業
按兩下
 提要欄位中的 [工作流程 ]。
提要欄位中的 [工作流程 ]。按一下
 。
。[工作] 索引標籤會顯示 [建立工作] 對話框。
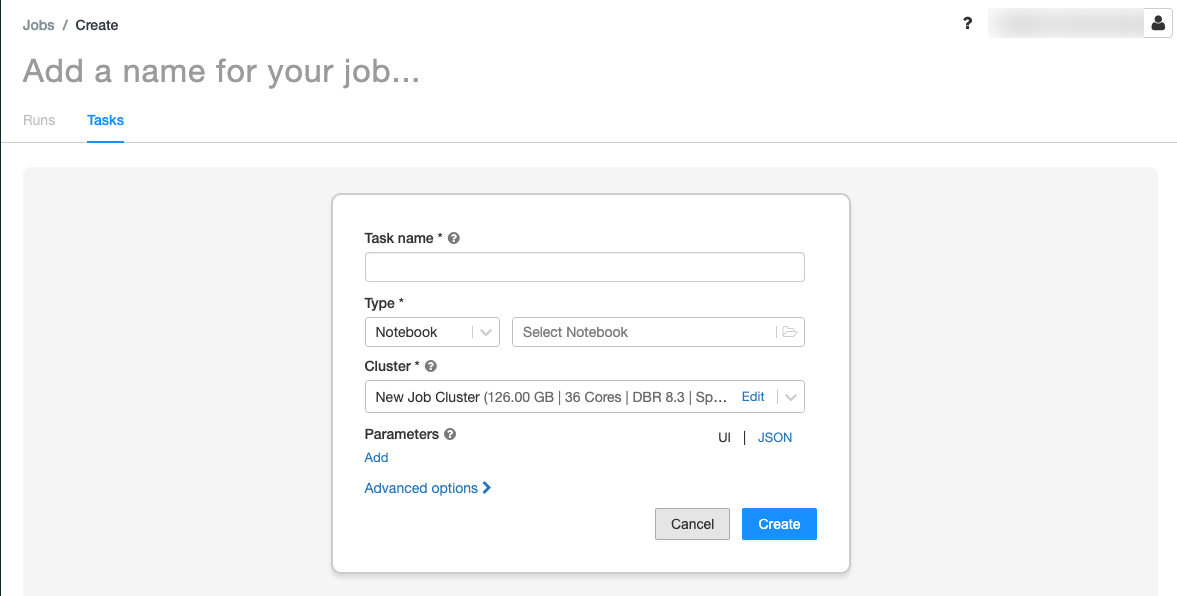
將 [新增作業的名稱...] 取代為您的作業名稱。
在 [ 任務名稱] 字段中,輸入工作的名稱 ;例如 retrieve-baby-name。
在 [ 類型 ] 下拉功能表中,選取 [筆記本]。
使用檔案瀏覽器來尋找您建立的第一個筆記本、按下筆記本名稱,然後按下 [ 確認]。
按兩下 [ 建立工作]。
按兩下
 您剛才建立的工作下方以新增另一個工作。
您剛才建立的工作下方以新增另一個工作。在 [ 任務名稱] 字段中,輸入任務的名稱 ;例如 filter-baby-names。
在 [ 類型 ] 下拉功能表中,選取 [筆記本]。
使用檔案瀏覽器來尋找您建立的第二個筆記本,按下筆記本名稱,然後按下 [ 確認]。
按兩下 [參數] 底下的 [新增]。 在 [ 金鑰 ] 欄位中, 輸入
year。 在 [ 值] 欄位中,輸入2014。按兩下 [ 建立工作]。
執行作業
若要立即執行作業,請按下 ![[立即執行] 按鈕](../../_static/images/workflows/jobs/run-now-button.png) 右上角的 。 您也可以按下 [執行] 索引標籤,然後按兩下 [作用中執行] 資料表中的 [立即執行] 來執行作業。
右上角的 。 您也可以按下 [執行] 索引標籤,然後按兩下 [作用中執行] 資料表中的 [立即執行] 來執行作業。
檢視執行詳細數據
按兩下 [執行] 索引標籤,然後按兩下 [使用中執行] 資料表或 [已完成執行] 資料表中執行的連結(過去 60 天) 資料表。
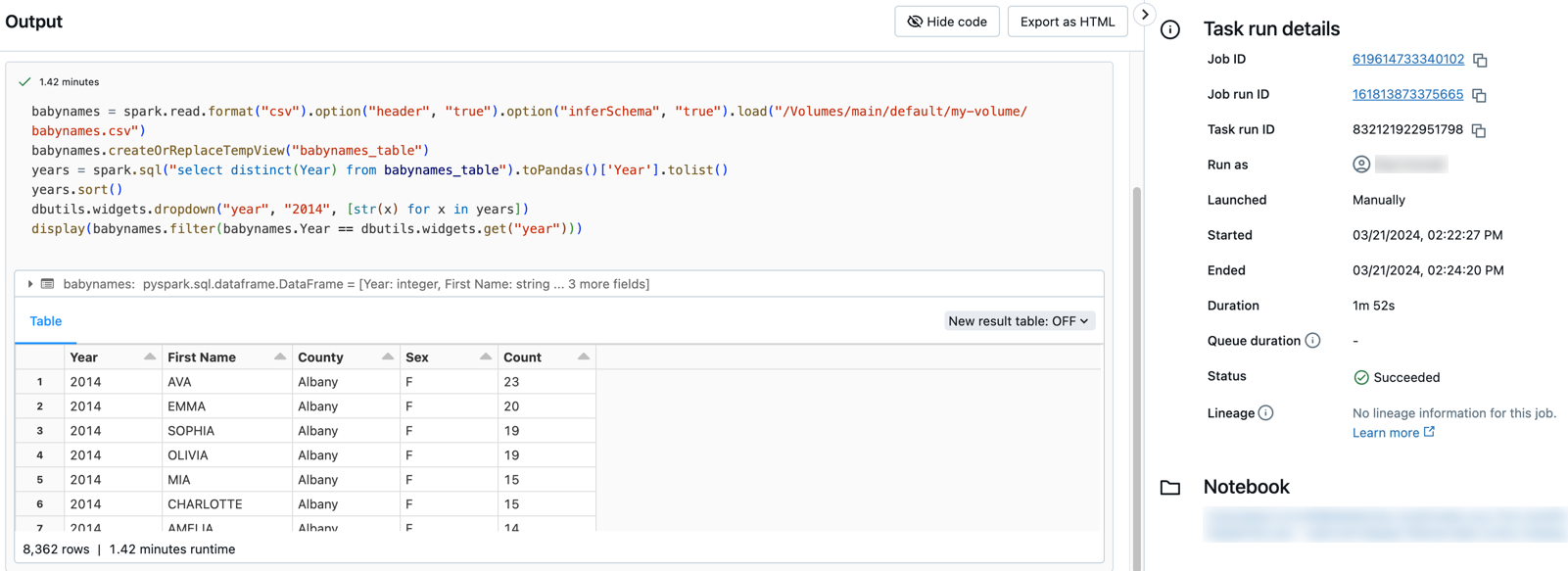
按兩下任一工作以查看輸出和詳細數據。 例如,按兩下 filter-baby-names 工作以檢視輸出並執行篩選工作的詳細資料:
使用不同的參數執行
若要重新執行作業,並篩選不同年份的嬰兒名稱:
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應