本文說明擷取增強的世代(RAG),以及開發人員需要建置生產就緒的RAG解決方案。
若要瞭解建置「透過您的資料聊天」應用程式的兩種方式,這是企業最上層的 AI 使用案例之一,請參閱 使用 RAG 增強 LLM 或微調。
下圖顯示 RAG 的主要步驟:
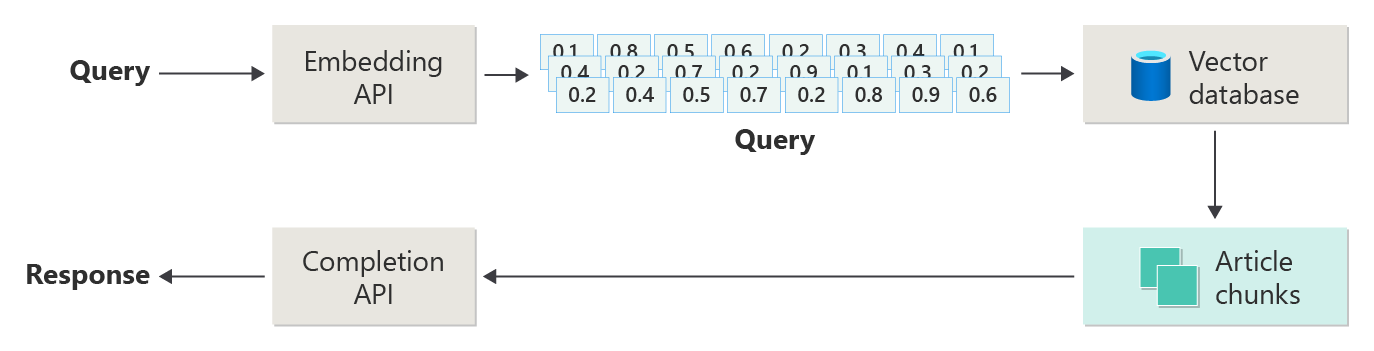
此程序稱為 天真RAG。 它可協助您瞭解以RAG為基礎的聊天系統中的基本元件和角色。
真實世界的RAG系統需要更多前置處理和後置處理來處理發行項、查詢和回應。 下圖顯示更真實的設定,稱為 進階RAG:

本文提供簡單的架構,讓您了解真實世界 RAG 型聊天系統中的主要階段:
- 擷取階段
- 推理管線階段
- 評估階段
擷取
擷取表示儲存貴組織的檔,以便快速找到使用者的解答。 主要挑戰是尋找和使用最符合每個問題的檔部分。 大部分的系統都會使用向量內嵌和餘弦相似性搜尋來比對問題與內容。 當您了解內容類型(例如模式和格式)並在向量資料庫中妥善組織數據時,您會取得更好的結果。
設定擷取時,請專注於下列步驟:
- 內容前置處理和擷取
- 分塊策略
- 區塊化組織
- 更新策略
內容前置處理和擷取
擷取階段的第一個步驟是預先處理和擷取檔中的內容。 此步驟非常重要,因為它可確保文字已清除、結構化,且已準備好編製索引和擷取。
全新且精確的內容可讓RAG型聊天系統運作得更好。 從查看您要編制索引之文件的形狀和樣式開始。 它們是否遵循一組模式,例如檔? 如果沒有,這些檔可以回答哪些問題?
至少將擷取管線設定為:
- 標準化文字格式
- 處理特殊字元
- 拿掉不相關的或舊內容
- 追蹤不同版本的內容
- 使用索引標籤、影像或數據表處理內容
- 擷取
如果您將其與向量資料庫中的檔保持一起,某些資訊,例如元數據,在擷取和評估期間會有所説明。 您也可以將它與文字區塊結合,以改善區塊的向量內嵌。
分塊策略
身為開發人員,決定如何將大型檔分成較小的區塊。 區塊化有助於將最相關的內容傳送至 LLM,以便更妥善地回答用戶問題。 此外,請思考如何在取得區塊之後使用區塊。 試用常見的產業方法,並在組織中測試您的區塊化策略。
區塊化時,請考慮:
- 區塊大小優化:挑選最佳區塊大小,以及如何依區段、段落或句子加以分割。
- 重疊和滑動視窗區塊:決定區塊是否應該分開或重疊。 您也可以使用滑動視窗方法。
- Small2Big:如果您依句子分割,請組織內容,以便找到附近的句子或完整段落。 為 LLM 提供這個額外的內容,可協助其更妥善地回答。 如需詳細資訊,請參閱下一節。
區塊化組織
在RAG系統中,您如何組織向量資料庫中的數據,讓您更容易且更快速地尋找正確的資訊。 以下是設定索引和搜尋的一些方式:
- 階層式索引:使用索引層。 最上層摘要索引可快速找到一小組可能區塊。 第二層索引會指向確切的數據。 此設定會先縮小選項範圍,再詳細查看,以加快搜尋速度。
- 特製化索引:挑選符合您數據的索引。 例如,如果您的區塊彼此連線,例如引文網路或知識圖表,請使用圖形型索引。 如果您的數據位於數據表中,請使用關係資料庫,並使用 SQL 查詢進行篩選。
- 混合式索引:結合不同的索引編製方法。 例如,先使用摘要索引,再使用圖形型索引來探索區塊之間的連線。
對齊優化
將擷取的區塊與其回答的問題類型比對,讓擷取的區塊更相關且準確。 其中一種方式是為每個區塊建立範例問題,其中顯示最能回答的問題。 此方法可透過數種方式來協助:
- 改善比對:在擷取期間,系統會比較用戶的問題與這些範例問題,以找出最佳的區塊。 這項技術可改善結果的相關性。
- 機器學習模型的定型數據:這些問題區塊組有助於訓練 RAG 系統中的機器學習模型。 模型會瞭解哪些區塊會回答哪些類型的問題。
- 直接查詢處理:如果用戶的問題符合範例問題,系統就可以快速尋找並使用正確的區塊,加速回應。
每個區塊的範例問題可作為引導擷取演算法的標籤。 搜尋會更加專注並感知內容。 當區塊涵蓋許多不同的主題或資訊類型時,這個方法可以正常運作。
更新策略
如果您的組織經常更新檔,您必須讓資料庫保持最新狀態,讓擷取程式一律可以找到最新資訊。 擷 取器元件 是搜尋向量資料庫並傳回結果之系統的一部分。 以下是讓向量資料庫保持最新狀態的一些方式:
累加式更新:
- 定期間隔:根據文件變更的頻率,設定依排程執行的更新(例如每日或每周)。 此動作可讓資料庫保持最新狀態。
- 以觸發程式為基礎的更新:當有人新增或變更檔時,設定自動更新。 系統只會重新編製受影響元件的索引。
部分更新:
- 選擇性重新編製索引:只更新變更的資料庫部分,而不是整個專案。 這項技術可節省時間和資源,特別是大型數據集。
- 差異編碼:只儲存新舊文件之間的變更,以減少要處理的數據量。
版本設定:
- 快照集:在不同的時間儲存檔集的版本。 此動作可讓您視需要返回或還原舊版。
- 檔版本控制:使用版本控制系統來追蹤變更,並保留檔的歷程記錄。
即時更新:
- 串流處理:使用串流處理,在文件變更時即時更新向量資料庫。
- 實時查詢:使用即時查詢來取得 up-to日期答案,有時會混合實時數據與快取的結果以取得速度。
優化技術:
- 批處理:將變更分組並套用在一起,以節省資源並降低額外負荷。
-
混合式方法:混合不同的策略:
- 針對小型變更使用累加式更新。
- 針對重大更新使用完整重新編製索引。
- 追蹤和記錄數據的重大變更。
挑選符合您需求的更新策略或混合。 請考慮:
- 文件主體大小
- 更新頻率
- 實時數據需求
- 可用的資源
檢閱您的應用程式的這些因素。 每個方法都有複雜度、成本以及更新顯示速度的取捨。
推斷管線
您的發行項現在會進行區塊化、向量化,並儲存在向量資料庫中。 接下來,專注於從您的系統取得最佳答案。
若要取得準確且快速的結果,請思考下列關鍵問題:
- 用戶的問題是否清楚且可能獲得正確的答案?
- 問題是否違反任何公司規則?
- 您是否可以重寫問題,以協助系統找到更好的相符專案?
- 資料庫的結果是否符合問題?
- 您應該在將結果傳送至 LLM 之前變更結果,以確定答案是否相關?
- LLM 的回答是否完全解決了用戶的問題?
- 答案是否遵循貴組織的規則?
整個推斷管線會實時運作。 沒有設定前置處理和後續處理步驟的單一正確方式。 您可以使用混合程式代碼和 LLM 呼叫。 最大的取捨之一是平衡成本和速度的精確度和合規性。
讓我們看看推斷管線每個階段的策略。
查詢前置處理步驟
查詢前置處理會在用戶傳送問題之後立即開始:

這些步驟有助於確保用戶的問題符合您的系統,並準備好使用餘弦相似度或「最接近鄰近」搜尋來尋找最佳文章區塊。
原則檢查:使用邏輯來找出並移除或標幟垃圾內容,例如個人資料、不良語言或嘗試違反安全規則(稱為「越獄」)。
查詢重寫:視需要變更問題—展開縮略字、移除俚語或重新整理,以專注於更大的想法(回溯提示)。
特殊版本的退步提示是 假設的檔案內嵌 (HyDE) 。 HyDE 具有 LLM 回答問題、從該答案進行內嵌,然後使用它搜尋向量資料庫。
子查詢 (部分機器翻譯)
子查詢會將較長或複雜的問題分成更小、更容易的問題。 系統會回答每個小型問題,然後結合答案。
例如,如果有人問:「誰為現代物理學、阿爾伯特·愛因斯坦或尼爾斯·波爾做出了更重要的貢獻?
- 子查詢 1:“阿爾伯特·愛因斯坦對現代物理學的貢獻是什麼?
- 子查詢 2:“尼爾斯·布爾對現代物理學的貢獻是什麼?
答案可能包括:
- 對於愛因斯坦:相對論、光電效應和 E=mc^2。
- 對於布爾:氫原子模型,研究量子力學,以及互補性的原則。
然後,您可以詢問後續問題:
- 子查詢 3:“愛因斯坦的理論是如何改變現代物理的?
- 子查詢 4:“布爾的理論是如何改變現代物理的?
這些後續研究將探討每個科學家的效果,例如:
- 愛因斯坦的工作如何導致宇宙學和量子理論的新想法
- 布爾的工作如何幫助我們瞭解原子和量子力學
系統會結合答案,為原始問題提供完整回應。 此方法可讓複雜的問題更容易回答,方法是將它們分成更清楚、較小的部分。
查詢路由器
有時候,您的內容會存在於數個資料庫或搜尋系統中。 在這些情況下,請使用查詢路由器。 查詢路由器會挑選最佳的資料庫或索引來回答每個問題。
查詢路由器會在使用者提出問題之後運作,但在系統搜尋答案之前。
以下是查詢路由器的運作方式:
- 查詢分析:LLM 或其他工具會查看問題,以找出需要哪種答案。
- 索引選取:路由器會挑選一或多個符合問題的索引。 有些索引比較適合事實,有些則適用於意見或特殊主題。
- 查詢分派:路由器會將問題傳送至所選的索引或索引。
- 結果匯總:系統會從索引收集並結合答案。
- 答案產生:系統會使用找到的資訊來建立清楚的答案。
針對下列專案使用不同的索引或搜尋引擎:
- 數據類型特製化:某些索引著重於新聞、學術論文或醫學或法律資訊等特殊資料庫。
- 查詢類型優化:某些索引對於簡單事實而言很快速(例如日期),而其他索引則處理複雜或專家問題。
- 演算法差異:不同的搜尋引擎使用不同的方法,例如向量搜尋、關鍵詞搜尋或進階語意搜尋。
例如,在醫療諮詢系統中,您可能有:
- 技術詳細數據的研究論文索引
- 真實世界範例的案例研究索引
- 基本問題的一般健康情況索引
如果有人詢問新葯的影響,路由器會將問題傳送給研究論文索引。 如果問題與常見徵兆有關,它會使用一般健康情況索引來取得簡單的答案。
擷取後處理步驟
擷取後處理會在系統在向量資料庫中尋找內容區塊之後發生:

接下來,請先檢查這些區塊對於 LLM 提示是否很有用,再將它們傳送至 LLM。
請記住下列事項:
- 額外的資訊可以隱藏最重要的詳細數據。
- 不相關的資訊會使答案變得更糟。
在 乾草袋問題中注意針頭 :LLM 通常比中間人更注重提示的開始和結束。
此外,請記住 LLM 的內容視窗上限和長時間提示所需的令牌數目,特別是大規模。
若要處理這些問題,請使用擷取後處理管線與下列步驟,例如:
- 篩選結果:只保留符合查詢的區塊。 建置 LLM 提示時,請忽略其餘部分。
- 重新排名:將最相關的區塊放在提示的開頭和結尾。
- 提示壓縮:使用小型、廉價的模型,在將區塊傳送至 LLM 之前,先將區塊摘要並合併成單一提示。
完成後處理步驟
完成後處理會在使用者的問題和所有內容區塊移至 LLM 之後發生:

LLM 提供答案之後,請檢查其精確度。 完成後處理管線可以包括:
- 事實檢查:尋找答案中聲稱為事實的陳述,然後檢查它們是否屬實。 如果事實檢查失敗,您可以再次詢問 LLM 或顯示錯誤訊息。
- 原則檢查:請確定答案不包含使用者或貴組織的有害內容。
評估
評估這類系統比執行一般單元或整合測試更為複雜。 請思考這些問題:
- 使用者對答案感到滿意嗎?
- 答案是否正確?
- 如何收集用戶意見反應?
- 是否有您可以收集哪些資料的規則?
- 您是否可以看到系統在答案錯誤時採取的每個步驟?
- 您是否保留詳細的記錄以進行根本原因分析?
- 如何更新系統,而不讓事情變得更糟?
從使用者擷取並採取行動
請與貴組織的隱私權小組合作,設計意見反應擷取工具、系統數據和記錄,以取得查詢會話的鑑識和根本原因分析。
下一個步驟是建置 評量管線。 評量管線可讓您更輕鬆且更快速地檢閱意見反應,並找出 AI 提供特定答案的原因。 檢查每個回應以查看 AI 如何產生、如果使用正確的內容區塊,以及檔如何分割。
此外,尋找可改善結果的額外前置處理或後續處理步驟。 這項密切的檢閱通常會發現內容差距,尤其是在用戶的問題沒有良好的檔存在時。
您需要評定管線,才能大規模處理這些工作。 良好的管線會使用自定義工具來測量答案品質。 它可協助您瞭解 AI 為何提供特定答案、其使用的檔,以及推斷管線的運作程度。
黃金數據集
檢查RAG聊天系統的運作方式之一,就是使用黃金數據集。 黃金數據集是一組具有已核准答案的問題、有用的元數據(例如主題和問題類型)、源文檔的連結,以及使用者可能詢問相同專案的不同方式。
黃金數據集會顯示「最佳案例」。開發人員會用它來查看系統的運作方式,以及在新增功能或更新時執行測試。
評估傷害
損害模型化可協助您在產品中找出可能的風險,並規劃降低風險的方式。
傷害評估工具應包含下列重要功能:
- 項目關係人識別:協助您列出並分組受技術影響的所有人,包括直接使用者、間接受影響的人員、子孫後代,甚至是環境。
- 傷害類別和描述:列出可能的傷害,例如隱私權損失、情感痛苦或經濟傷害。 引導您完成範例,並協助您思考預期和非預期的問題。
- 嚴重性和機率評估:協助您判斷每個傷害有多嚴重且可能,因此您可以先決定要修正什麼。 您可以使用資料來支援您的選擇。
- 風險降低策略:建議降低風險的方法,例如變更系統設計、新增保護措施或使用其他技術。
- 意見反應機制:可讓您從項目關係人收集意見反應,以便在深入瞭解時持續改善程式。
- 文件和報告:讓您輕鬆建立報告,以顯示您所找到的內容,以及降低風險的作業。
這些功能可協助您找出並修正風險,同時也協助您從頭考慮所有可能的影響,以建置更多道德和負責任的 AI。
如需詳細資訊,請參閱下列文章:
測試及驗證防護
Red-teaming 是關鍵—這表示要像攻擊者一樣在系統中尋找弱點。 此步驟對於停止越獄尤其重要。 如需規劃及管理負責任 AI 之紅色小組的秘訣,請參閱 規劃大型語言模型及其應用程式的紅色小組。
開發人員應該在不同的案例中測試RAG系統防護,以確保其運作正常。 此步驟讓系統更強大,也有助於微調遵循道德標準和規則的回應。
應用程式設計的最終考慮
以下是本文中要記住的一些重要事項,可協助您設計應用程式:
- Generative AI Unpredictability
- 使用者提示變更及其對時間和成本的影響
- 平行 LLM 要求以加快效能
若要建置產生 AI 應用程式,請參閱 使用您自己的 Python 數據範例開始使用聊天。 本教學課程也適用於 .NET、Java和 JavaScript。