Apache Hadoop 是原始的開放原始碼建構,用於分散式處理和分析叢集上的巨量資料集。 Hadoop 生態系統包含相關的軟體和公用程式,其中包括 Apache Hive、Apache HBase、Spark、Kafka 等等。
Azure HDInsight 是雲端中供企業使用的完全受控、全方位的開放原始碼分析服務。 Azure HDInsight 中的 Apache Hadoop 叢集類型可讓您使用 Apache Hadoop 分散式檔案系統 (HDFS)、Apache Hadoop YARN 資源管理和簡單 MapReduce 程式設計模型,來平行處理和分析批次資料。 HDInsight 中的 Hadoop 叢集也能與 Azure Data Lake Storage Gen2 相容。
若要查看 HDInsight 上可用的 Hadoop 技術堆疊元件,請參閱 HDInsight 可用的元件和版本。 若要深入了解 HDInsight 中的 Hadoop,請參閱 HDInsight 的 Azure 功能頁面。
什麼是 MapReduce
Apache Hadoop MapReduce 是一種可撰寫工作來處理大量資料的軟體架構。 輸入的資料會分割成獨立的區塊。 每個區塊會在叢集的節點之間平行處理。 MapReduce 工作由兩項功能組成:
對應程式:取用輸入資料、分析 (通常使用篩選及排序作業),以及發出 Tuple (機碼值組)
減壓器:取用對應程式發出的 Tuple 並執行摘要作業,從對應程式資料建立較小的組合結果
下圖說明了基本字數統計 MapReduce 工作範例:
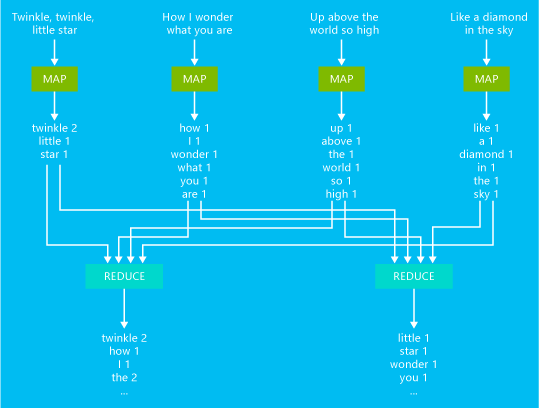
此工作的輸出是文字中每個單字出現的次數統計。
- 對應程式從輸入的文字中取得每一行當作一個輸入,然後將其打散成單字。 對應程式會在單字出現時發出機碼/值組,並在該字之後加上 1。 輸出會先經過排序再傳送至減壓器。
- 接著,減壓器會加總每個單字的個別計數並發出單一機碼/值組,其中包含該單字和尾隨在後的出現次數總和。
MapReduce 可在各種語言中實作。 Java 是最常見的實作,基於示範目的用於此文件中。
開發語言
以 Java 及 Java Virtual Machine 為基礎的語言或架構可以 MapReduce 工作的形式直接執行。 本文件中使用的範例是 Java MapReduce 應用程式。 非 Java 語言 (例如 C#、Python 或獨立可執行檔) 必須使用 Hadoop 串流。
Hadoop 串流會透過 STDIN 與 STDOUT 與對應工具和歸納工具進行通訊。 對應工具和歸納工具會一次從 STDIN 讀取一行資料,並將輸出寫入至 STDOUT。 對應工具和歸納工具所讀取或發出的每行資料,必須為機碼/值組格式,並以索引標籤字元分隔:
[key]\t[value]
如需詳細資訊,請參閱 Hadoop 資料流(英文)。
如需搭配 HDInsight 使用 Hadoop 資料流的範例,請參閱下列文件:
我該從哪裡開始
- 快速入門:使用 Azure 入口網站,在 Azure HDInsight 中建立 Apache Hadoop 叢集
- 教學課程:在 HDInsight 中提交 Apache Hadoop 作業
- 開發適用於 HDInsight 上 Apache Hadoop 的 Java MapReduce 程式
- 使用 Apache Hive 作為擷取、 轉換和載入 (ETL) 工具
- 大規模擷取、轉換和載入 (ETL)
- 使用資料分析管線進行作業