自動調整 Azure HDInsight 叢集規模
Azure HDInsight 的免費自動調整功能可以根據客戶採用的叢集計量和調整原則,自動增加或減少叢集中的背景工作角色節點數目。 自動調整功能的運作方式是根據效能計量或已定義的擴大和縮小作業排程,在預設限制內調整節點數目。
運作方式
自動調整功能使用兩種觸發調整事件的條件:各種叢集效能計量的閾值 (稱為負載型調整) 和時間型觸發程序 (稱為排程型調整)。 負載型調整會變更叢集中您所設定範圍內的節點數目,確保達到最佳的 CPU 使用量,並將執行成本降到最低。 排程型調整會根據擴大和縮小作業的排程,變更叢集中的節點數目。
下列影片會概要說明自動調整所能解決的難題,及如何協助您使用 HDInsight 控制成本。
選擇負載型調整或排程型調整
排程型調整可用於:
- 若工作預計會在可預測期間以固定排程執行,或預期一天特定時段的使用量較低。 例如下班時間、結束一日工作後的測試和開發環境。
負載型調整可用於:
- 負載模式在一天期間大幅變動且無法預測時。 例如負載模式中根據各種因素而隨機變動的訂單資料處理。
叢集計量
自動調整會持續監視叢集,並收集下列計量:
| 計量 | 描述 |
|---|---|
| 擱置的 CPU 總計 | 開始執行所有擱置中容器時所需的核心總數。 |
| 擱置的記憶體總計 | 開始執行所有擱置中容器時所需的記憶體總計 (MB)。 |
| 可用的 CPU 總計 | 作用中背景工作節點上所有未使用核心的總和。 |
| 可用的記憶體總計 | 作用中背景工作節點上所有未使用記憶體的總和 (MB)。 |
| 每個節點的已使用記憶體 | 背景工作節點上的負載。 已使用 10 GB 記憶體的背景工作節點會被視為所承受的負載高於已使用 2 GB 記憶體的背景工作節點。 |
| 每個節點的應用程式主機數目 | 背景工作節點上執行的應用程式主機 (AM) 容器數目。 裝載 2 個 AM 容器的背景工作角色節點的重要程度,會視為高於裝載 0 個 AM 容器的背景工作角色節點。 |
系統每隔 60 秒就會檢查上述計量。 自動調整將依據這些計量決定要進行擴大或縮小。
如需叢集計量的完整清單,請參閱 Microsoft.HDInsight/clusters 支援的計量。
以負載為基礎的調整條件
當偵測到下列情況時,自動調整會發出調整要求:
| 擴大 | 縮小 |
|---|---|
| 擱置中的 CPU 總計大於可用的 CPU 總計超過 3-5 分鐘。 | 擱置中的 CPU 總計小於可用的 CPU 總計超過 3-5 分鐘。 |
| 擱置中的記憶體總計大於可用的記憶體總計超過 3-5 分鐘。 | 擱置中的記憶體總計小於可用的記憶體總計超過 3-5 分鐘。 |
如需擴大,自動調整會發送擴大要求,新增所需的節點數目。 擴大的基準在於需要多少新的背景工作角色節點,才符合目前 CPU 和記憶體的需求。
針對縮小,自動調整會發出移除某些節點的要求。 縮小的基準在於每個節點的應用程式主機 (AM) 容器數目, 及目前 CPU 和記憶體的需求。 服務也會根據目前的作業執行狀況,偵測哪些節點是移除的候選項目。 相應減少作業會先解除委任節點,然後從叢集中移除它們。
自動調整的 Ambari DB 重設大小考量事項
建議您正確調整 Ambari DB 的大小,以獲得自動調整的優點。 客戶應該使用正確的 DB 層,並針對大型叢集使用自訂 Ambari DB。 請閱讀資料庫和前端節點大小調整建議。
叢集相容性
重要
Azure HDInsight 自動調整功能已於 2019 年 11 月 7 日正式發行,適用於 Spark 和 Hadoop 叢集,並包含功能預覽版本中未提供的改善項目。 如果您在 2019 年 11 月 7 日之前已建立 Spark 叢集,並想要在叢集上使用自動調整功能,建議的路徑是建立新叢集,並在新叢集上 enable Autoscale。
Interactive Query (LLAP) 的自動調整已於 2020 年 8 月 27 日正式發行 HDI 4.0。 自動調整僅適用於 Spark、Hadoop、Interactive Query、叢集
下表描述與自動調整功能相容的叢集類型和版本。
| 版本 | Spark | Hive | 互動式查詢 | hbase | Kafka |
|---|---|---|---|---|---|
| 不含 ESP 的 HDInsight 4.0 | Yes | Yes | 是* | No | No |
| 包含 ESP 的 HDInsight 4.0 | Yes | Yes | 是* | No | No |
| 不含 ESP 的 HDInsight 5.0 | Yes | Yes | 是* | No | No |
| 包含 ESP 的 HDInsight 5.0 | Yes | Yes | 是* | No | No |
* Interactive Query 叢集只能適用於排程型調整的設定,而不適用於負載型。
開始使用
建立使用負載型自動調整的叢集
若要啟用使用負載型調整的自動調整功能,請在一般叢集建立程序中完成下列步驟:
在 [設定 + 價格] 索引標籤上,選取
Enable autoscale核取方塊。選取 [自動調整類型] 下的 [以負載為基礎]。
針對下列屬性輸入所需的值:
- 背景工作角色節點的節點初始數目。
- 背景工作角色節點的最小數目。
- 背景工作角色節點的最大數目。
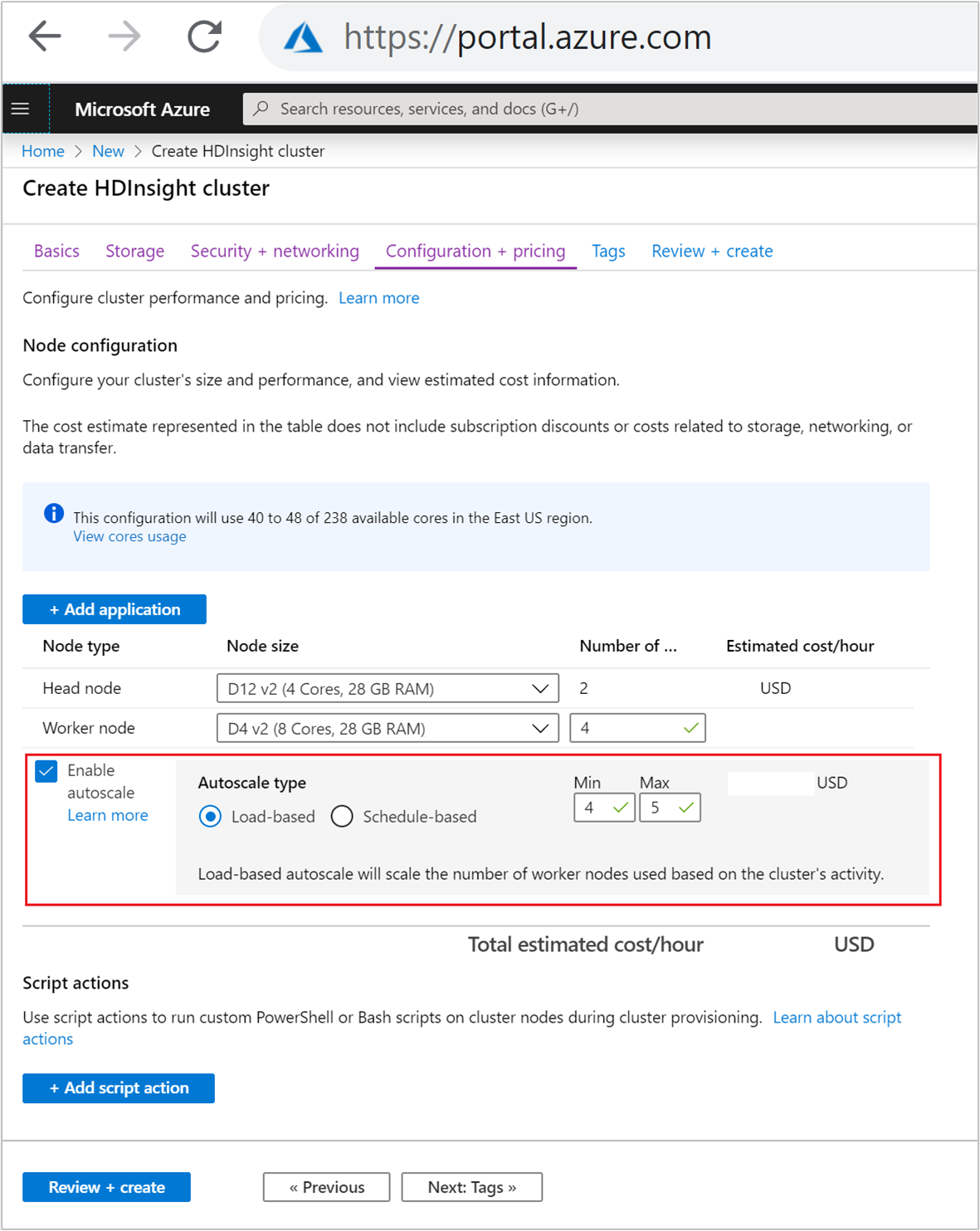
背景工作節點的初始數目必須介於最小值和最大值 (含) 之間。 建立後,此值會定義叢集的初始大小。 背景工作角色節點數目下限應設為三個以上。 將叢集調整為三個節點之下,可能因檔案複寫不足,導致無法脫離安全模式。 如需詳細資訊,請參閱無法脫離安全模式。
建立使用排程型自動調整的叢集
若要啟用使用排程型調整的自動調整功能,請在一般叢集建立程序中完成下列步驟:
在 [設定 + 價格] 索引標籤上,勾選
Enable autoscale核取方塊。輸入背景工作角色節點的節點數目,控制擴大叢集的限制。
在 [自動調整類型] 下,選取 [以排程為基礎] 選項。
選取 [設定] 開啟 [自動調整設定] 視窗。
選取您的時區,然後按一下 [+ 新增條件]
選取新條件應套用的工作日。
編輯條件應生效的時間,及叢集應調整的節點數目。
如果需要,請新增更多條件。
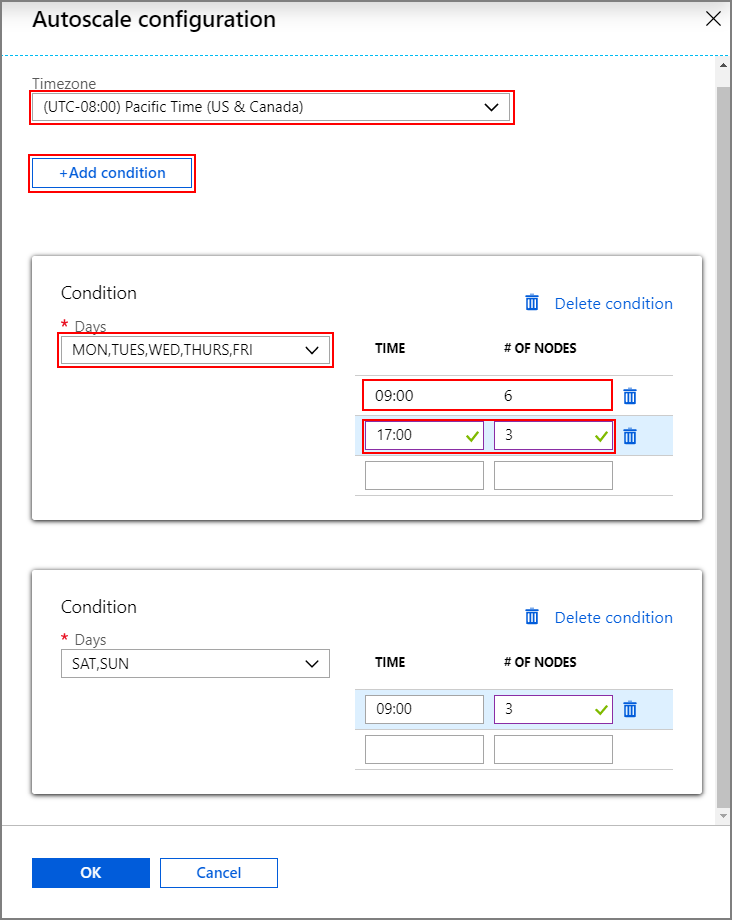
新增條件前,節點數目必須介於 3 到您輸入的背景工作角色節點數目上限。
最終建立步驟
從 [節點大小] 下的下拉式清單選取 VM,然後選取背景工作角色節點的 VM 類型。 為每個節點類型選擇 VM 類型後,您會看到整個叢集的預估成本範圍。 調整為符合您預算的 VM 類型。
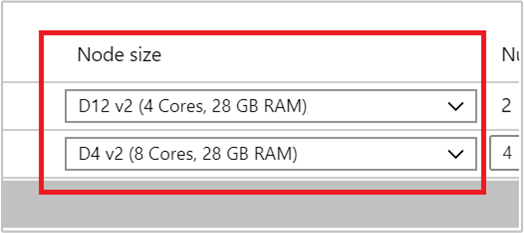
您的訂用帳戶擁有每個區域的容量配額。 前端節點的核心總數與背景工作角色節點的最大數目,不能超過容量配額。 但是這個配額是軟性限制;您一律可以建立支援票證,輕鬆增加配額。
注意
如果超過總核心配額限制,您會收到錯誤訊息「最大節點數超出此區域的可用核心數,請選擇其他區域或聯絡支援小組增加配額」。
如需使用 Azure 入口網站建立 HDInsight 叢集的詳細資訊,請參閱使用 Azure 入口網站在 HDInsight 中建立以 Linux 為基礎的叢集。
使用 Resource Manager 範本建立叢集
負載型自動調整
您可以新增 autoscale 節點至具有 minInstanceCount 和 maxInstanceCount 屬性的 computeProfile>workernode 區段,建立 HDInsight 叢集並使用負載型自動調整的 Azure Resource Manager 範本,如 JSON 程式碼片段所示。 如需完整的 Resource Manager 範本,請參閱快速入門範本:部署啟用負載型自動調整的 Spark 叢集。
{
"name": "workernode",
"targetInstanceCount": 4,
"autoscale": {
"capacity": {
"minInstanceCount": 3,
"maxInstanceCount": 10
}
},
"hardwareProfile": {
"vmSize": "Standard_D13_V2"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
},
"virtualNetworkProfile": null,
"scriptActions": []
}
排程型自動調整
您可以新增 autoscale 節點至 computeProfile>workernode 區段,建立 HDInsight 叢集並使用排程型自動調整的 Azure Resource Manager 範本。 autoscale 節點包含有 timezone 的 recurrence,及描述何時變更的 schedule。 如需完整的 Resource Manager 範本,請參閱部署啟用排程型自動調整的 Spark 叢集。
{
"autoscale": {
"recurrence": {
"timeZone": "Pacific Standard Time",
"schedule": [
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"timeAndCapacity": {
"time": "11:00",
"minInstanceCount": 10,
"maxInstanceCount": 10
}
}
]
}
},
"name": "workernode",
"targetInstanceCount": 4
}
針對正在執行的叢集啟用和停用自動調整
使用 Azure 入口網站
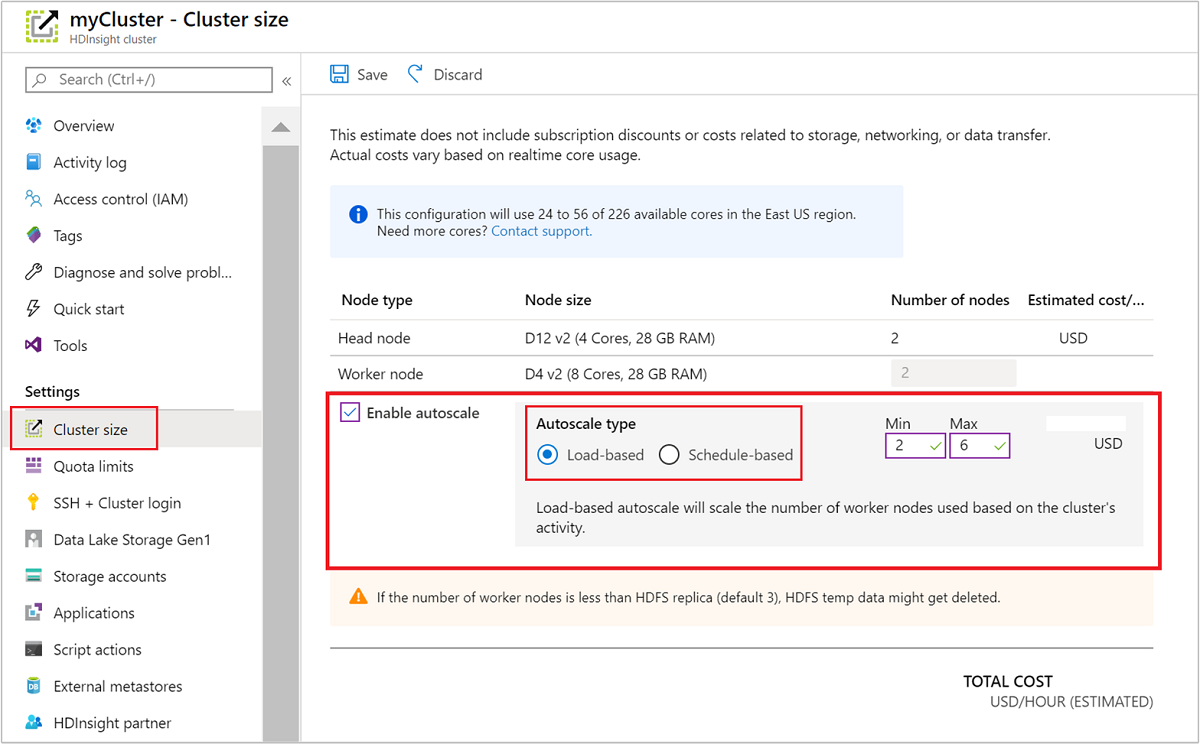
若要在執行中的叢集上啟用自動調整,請在 [設定] 下選取 [叢集大小]。 然後選取 [Enable autoscale]。 選取您要的自動調整類型,然後輸入負載型或排程型調整的選項。 最後,選取 [儲存]。
使用 REST API
若要使用 REST API 啟用或停用執行中叢集上的自動調整,請向自動調整端點提出 POST 要求:
https://management.azure.com/subscriptions/{subscription Id}/resourceGroups/{resourceGroup Name}/providers/Microsoft.HDInsight/clusters/{CLUSTERNAME}/roles/workernode/autoscale?api-version=2018-06-01-preview
在要求承載中使用適當的參數。 下列 json 承載可用於 enable Autoscale。 使用承載 {autoscale: null} 停用自動調整。
{ "autoscale": { "capacity": { "minInstanceCount": 3, "maxInstanceCount": 5 } } }
如需所有承載參數的完整描述,請參閱上一節的啟用負載型自動調整。 不建議在執行中的叢集上強制停用自動調整服務。
監視自動調整活動
叢集狀態
Azure 入口網站中列出的叢集狀態可協助您監視自動調整活動。
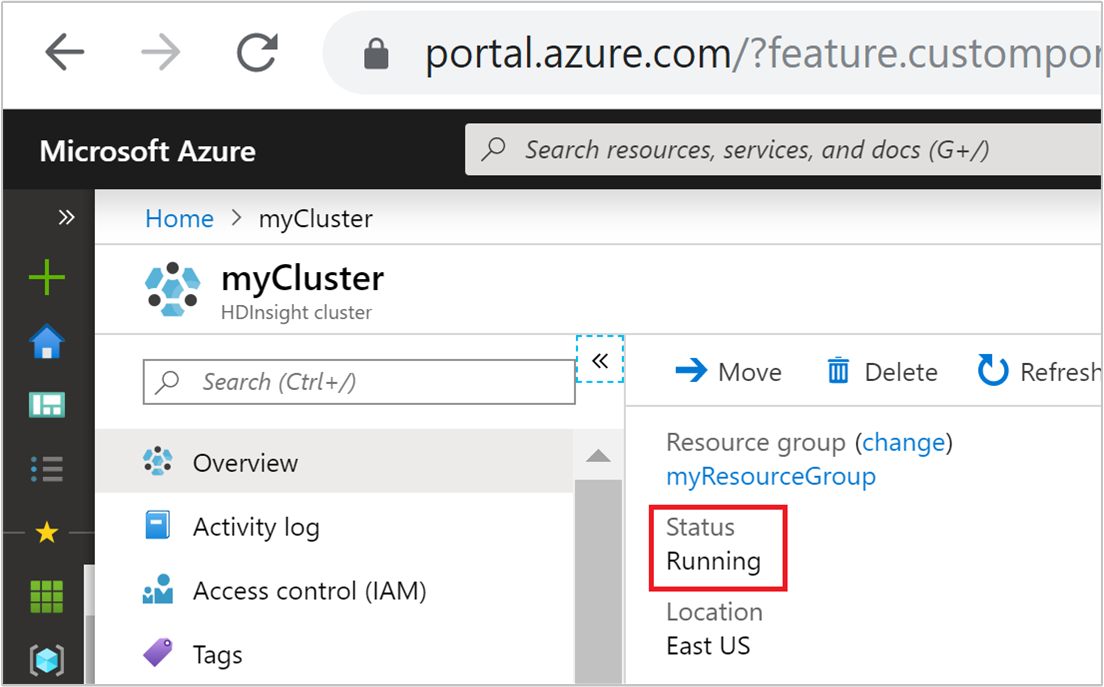
下列清單說明您可能看到的所有叢集狀態訊息。
| 叢集狀態 | 描述 |
|---|---|
| 執行中 | 叢集正常執行。 所有之前的自動調整活動都已順利完成。 |
| 更新 | 正在更新叢集自動調整設定。 |
| HDInsight 設定 | 叢集擴大或縮小作業正在進行中。 |
| 正在更新錯誤 | HDInsight 在自動調整設定更新期間遇到問題。 客戶可以選擇重試更新或停用自動調整。 |
| 錯誤 | 叢集發生錯誤,而且無法使用。 刪除叢集,並建立新的叢集。 |
若要檢視叢集中目前的節點數目,請移至叢集 [概觀] 頁面上的 [叢集大小] 圖表。 或在 [設定] 下,選取 [叢集大小]。
作業記錄
您可以檢視叢集計量包含的叢集擴大和縮小記錄。 您也可以列出過去一天、一週或其他時期所有的調整動作。
在 [監視] 下,選取 [計量]。 然後從 [計量] 下拉式方塊中,選取 [新增計量] 和 [作用中背景工作角色數目]。 選取右上方的按鈕,變更時間範圍。
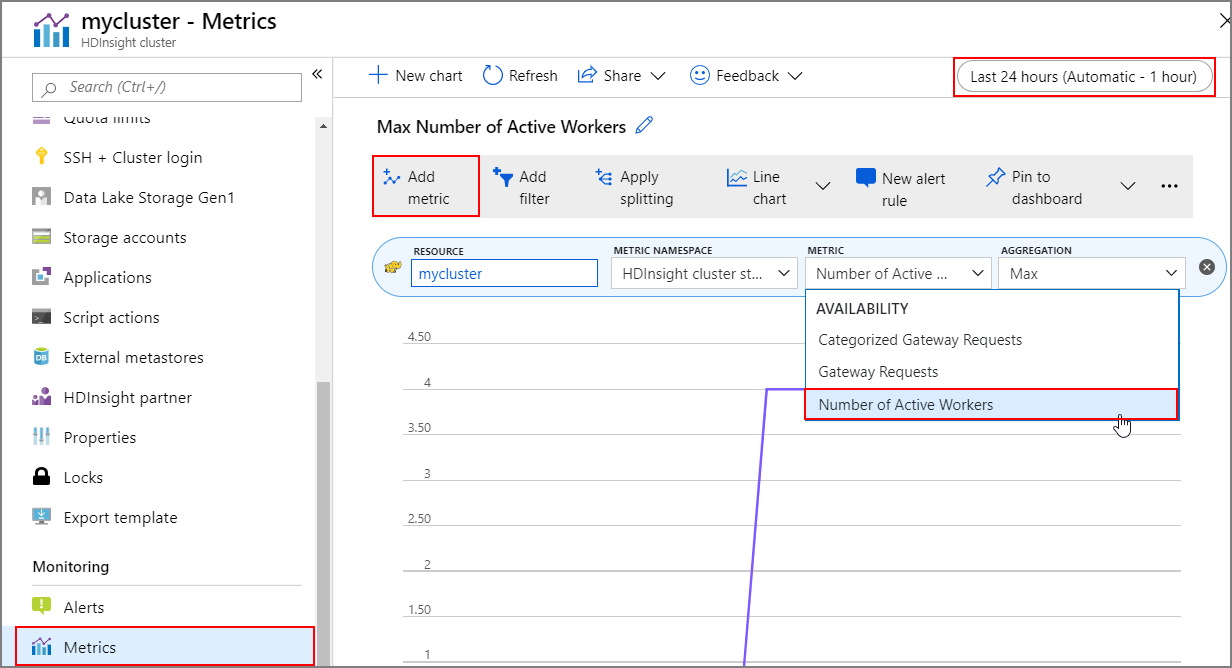
最佳作法
考量擴大和縮小作業的延遲
完成調整作業可能需要 10 到 20 分鐘。 設定自訂排程時,請為此類延做好事先規劃。 例如,如果您需要叢集大小在上午 9:00 為 20,請將排程觸發程式設為較早的時間,例如上午 8:30 或更早時間,讓調整作業在上午 9:00 前完成。
準備縮小
在叢集縮小程序期間,自動調整會解除節點來配合目標大小。 在負載型自動調整中,如果工作在這些節點上執行,自動調整會等到 Spark 和 Hadoop 叢集的工作完成。 因為每個背景工作角色節點也在 HDFS 中扮演一個角色,所以暫存資料會轉移至其餘的背景工作角色節點。 請確定其餘的節點上有足夠的空間可以裝載所有暫存資料。
注意
如果是排程型自動調整縮小,即不支援正常解除。 這可能導致在縮小作業期間發生工作失敗,所以建議您根據預期的工作排程模式來規劃排程,以包含足夠的時間來結束進行中的工作。 為避免作業失敗,您可以參考完成時間的記錄設定排程。
根據使用模式設定排程型自動調整
設定排程型自動調整前,請了解您的叢集使用模式。 Grafana 儀表板可協助您了解查詢負載和執行位置。 您可以從儀表板取得可用的執行程式位置和執行程式位置總數。
以下方式可以估計您需要多少背景工作角色節點。 建議您提供額外 10% 的緩衝區,處理工作負載的變化。
使用的執行程式位置數目 = 執行程式位置總數 – 可用的執行程式位置總數。
必要的背景工作角色節點數目 = 實際使用的執行程式位置數目 / (hive.llap.daemon.num.executors + hive.llap.daemon.task.scheduler.wait.queue.size)。
*hive.llap.daemon.num.executors 可以設定,且預設值為 4。
*hive.llap.daemon.task.scheduler.wait.queue.size 可以設定,且預設值為 10。
自訂指令碼動作
自訂指令碼動作主要用來自訂節點 (HeadNode / WorkerNodes),讓客戶可以設定所使用的特定程式庫和工具。 其中一個常見的使用案例是,在叢集上執行的工作可能對客戶擁有的協力廠商程式庫具有某些相依性,而節點上應可使用協力廠商程式庫,讓工作能順利成功。 對於自動調整,我們目前支援會持續留存的自訂指令碼動作,因此每次在擴大作業中新增新節點至叢集時,就會執行這些留存的指令碼動作,並發佈配置在動作上的容器或作業。 雖然自訂指令碼動作有助新節點的啟動程序,但建議盡可能減少動作數量,因為動作會加重整體擴大的延遲,而且可能影響排程的工作。
請注意叢集大小的下限
請勿將叢集縮小到三個節點以下。 將叢集調整為三個節點之下,可能因檔案複寫不足,導致無法脫離安全模式。 如需詳細資訊,請參閱無法脫離安全模式。
Microsoft Entra Domain Services 和調整作業
如果您使用 HDInsight 叢集搭配已加入 Microsoft Entra Domain Services 受控網域的企業安全性套件 (ESP),建議您節流 Microsoft Entra Domain Services 上的負載。 在複雜的目錄結構範圍同步中,建議避免影響調整作業。
設定尖峰使用方式情節的 Hive 設定最大並行查詢總數
自動調整事件不會變更 Ambari 中 Hive 設定的最大並行查詢總數。 亦即 Hive Server 2 互動式服務在任何時間點,只能處理指定的並行查詢數目,即使 Interactive Query 精靈計數是根據負載和排程擴大或縮小。 為避免手動操作,一般建議是針對使用方式情節設定此設定。
但如果只有少量的背景工作角色節點,且並行查詢上限值設定太高,您可能遇到 Hive Server 2 重新啟動失敗。 最小背景工作角色節點數目至少要可以容納 Tez Ams 的指定數目 (等於「並行查詢總數上限」設定)。
限制
Interactive Query 精靈計數
如果是啟用自動調整的 Interactive Query 叢集,自動擴大/縮小事件也會擴大/縮小 Interactive Query 精靈的數目為作用中的背景工作角色節點數目。 精靈數目的變更不會保存在 Ambari 中的 num_llap_nodes 設定中。 如果手動重新啟動 Hive 服務,Interactive Query 精靈的數目會根據 Ambari 中的每個設定重設。
如果是手動重新啟動 Interactive Query 服務,為符合目前作用中的工作者節點計數,請在進階 hive-interactive-env 下,手動變更 num_llap_node 設定 (執行 Hive Interactive Query 精靈必要的節點數目)。 Interactive Query 叢集僅支援排程型自動調整。
下一步
請閱讀調整指導方針中的手動調整叢集指導方針。