在以 Linux 為基礎的 HDInsight 上存取 Apache Hadoop YARN 應用程式記錄
瞭解如何在 Azure HDInsight 中的 Apache Hadoop 叢集上存取 Apache Hadoop YARN(又一個資源交涉器)應用程式的記錄。
什麼是 Apache YARN?
YARN 支援多個程序設計模型(Apache Hadoop MapReduce 是其中之一),方法是將資源管理與應用程式排程/監視分離。 YARN 會使用全域 ResourceManager (RM)、每個背景工作節點 的 NodeManagers (NM),以及個別應用程式 ApplicationMasters (VM)。 每個應用程式 AM 會交涉資源(CPU、記憶體、磁碟、網路),以使用 RM 執行您的應用程式。 RM 會與 NM 搭配運作,以授與這些資源,這些資源會以容器的形式授與。 AM 負責追蹤 RM 指派給容器的進度。 應用程式可能需要許多容器,視應用程式的性質而定。
每個應用程式都可能包含多個 應用程式嘗試。 如果應用程式失敗,可能會以新的嘗試重試。 每次嘗試都會在容器中執行。 從某種意義上說,容器會提供 YARN 應用程式完成之基本工作單位的內容。 在容器內容內完成的所有工作,都會在指定容器的單一背景工作節點上完成。 如需進一步參考,請參閱 Hadoop:撰寫 YARN 應用程式或 Apache Hadoop YARN 。
若要調整叢集以支援更大的處理輸送量,您可以使用數種不同的語言,使用自動調整或手動調整叢集。
YARN 時間軸伺服器
Apache Hadoop YARN Timeline Server 提供已完成應用程式的一般資訊
YARN 時間軸伺服器包含下列資料類型:
- 應用程式標識碼,應用程式的唯一標識碼
- 啟動應用程式的使用者
- 嘗試完成應用程式的相關信息
- 任何指定的應用程式嘗試所使用的容器
YARN 應用程式和記錄
對有問題的 Hadoop 應用程式進行偵錯時,應用程式記錄檔(和相關容器記錄)非常重要。 YARN 提供一個很好的架構,可讓您使用記錄匯總來收集、匯總及儲存應用程式記錄。
記錄匯總功能可讓存取應用程式記錄更具決定性。 它會匯總背景工作節點上所有容器的記錄,並將其儲存為每個背景工作節點的一個匯總記錄檔。 在應用程式完成之後,記錄檔會儲存在預設檔案系統上。 您的應用程式可能會使用數百或數千個容器,但單一背景工作節點上執行之所有容器的記錄一律會匯總至單一檔案。 因此,您的應用程式只會使用每個背景工作節點一個記錄。 HDInsight 叢集 3.0 版和更新版本預設會啟用記錄匯總。 彙總記錄位於叢集的預設儲存體。 下列路徑是記錄的 HDFS 路徑:
/app-logs/<user>/logs/<applicationId>
在路徑中, user 是啟動應用程式的用戶名稱。 applicationId是 YARN RM 指派給應用程式的唯一識別碼。
匯總的記錄無法直接讀取,因為它們是以 容器編製索引的二進位格式寫入 TFile。 使用 YARN ResourceManager 記錄或 CLI 工具,將這些記錄檢視為感興趣的應用程式或容器的純文字。
ESP 叢集中的 Yarn 記錄
必須在Ambari中將兩個組態新增至自定義 mapred-site 。
從網頁瀏覽器瀏覽至
https://CLUSTERNAME.azurehdinsight.net,其中CLUSTERNAME是叢集的名稱。從Ambari UI,流覽至 MapReduce2>設定>進階>自定義mapred-site。
新增 下列其中一 組屬性:
設定 1
mapred.acls.enabled=true mapreduce.job.acl-view-job=*設定 2
mapreduce.job.acl-view-job=<user1>,<user2>,<user3>儲存變更並重新啟動所有受影響的服務。
YARN CLI 工具
使用 ssh 命令來連線到您的叢集。 將 CLUSTERNAME 取代為您的叢集名稱,然後輸入 命令,以編輯下列命令:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.net使用下列命令列出目前執行中 Yarn 應用程式的所有應用程式識別碼:
yarn top記下要下載記錄之
APPLICATIONID數據行的應用程式標識碼。YARN top - 18:00:07, up 19d, 0:14, 0 active users, queue(s): root NodeManager(s): 4 total, 4 active, 0 unhealthy, 0 decommissioned, 0 lost, 0 rebooted Queue(s) Applications: 2 running, 10 submitted, 0 pending, 8 completed, 0 killed, 0 failed Queue(s) Mem(GB): 97 available, 3 allocated, 0 pending, 0 reserved Queue(s) VCores: 58 available, 2 allocated, 0 pending, 0 reserved Queue(s) Containers: 2 allocated, 0 pending, 0 reserved APPLICATIONID USER TYPE QUEUE #CONT #RCONT VCORES RVCORES MEM RMEM VCORESECS MEMSECS %PROGR TIME NAME application_1490377567345_0007 hive spark thriftsvr 1 0 1 0 1G 0G 1628407 2442611 10.00 18:20:20 Thrift JDBC/ODBC Server application_1490377567345_0006 hive spark thriftsvr 1 0 1 0 1G 0G 1628430 2442645 10.00 18:20:20 Thrift JDBC/ODBC Server您可以執行下列其中一個命令,將這些記錄檢視為純文字:
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> -containerId <containerId> -nodeAddress <worker-node-address>在執行這些命令時, <指定 applicationId>、 <user-who-started-the-application>、 <containerId> 和 <worker-node-address> 資訊。
其他範例命令
使用下列命令下載所有應用程式主機的 Yarn 容器記錄。 此步驟會以文字格式建立名為
amlogs.txt的記錄檔。yarn logs -applicationId <application_id> -am ALL > amlogs.txt使用下列命令,只下載最新應用程式主機的 Yarn 容器記錄:
yarn logs -applicationId <application_id> -am -1 > latestamlogs.txt使用下列命令下載前兩個應用程式主機的 YARN 容器記錄:
yarn logs -applicationId <application_id> -am 1,2 > first2amlogs.txt使用下列命令下載所有 Yarn 容器記錄:
yarn logs -applicationId <application_id> > logs.txt使用下列命令下載特定容器的 yarn 容器記錄:
yarn logs -applicationId <application_id> -containerId <container_id> > containerlogs.txt
YARN ResourceManager UI
YARN ResourceManager UI 會在叢集前端節點上執行。 它可透過Ambari Web UI存取。 使用下列步驟來檢視 YARN 記錄:
在您的網頁瀏覽器中,瀏覽至
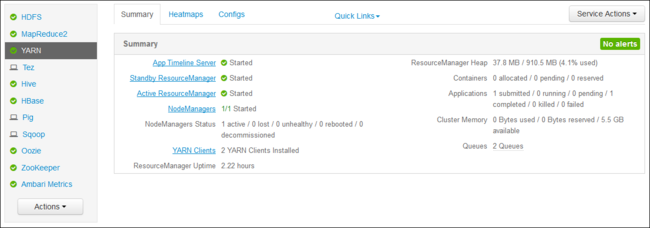
https://CLUSTERNAME.azurehdinsight.net。 以 HDInsight 叢集的名稱取代 CLUSTERNAME。從左側的服務清單中,選取 [YARN]。
從 [ 快速連結] 下拉式清單中,選取其中一個叢集前端節點,然後選取
ResourceManager Log。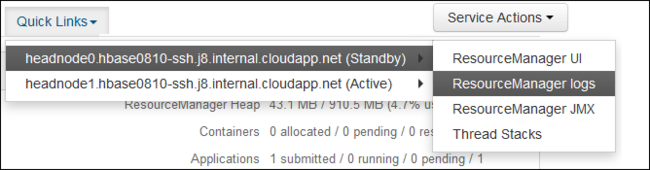
您會看到 YARN 記錄的連結清單。