如何在 Azure HDInsight 叢集中使用 Apache Hive 複寫
在資料庫和倉儲的內容中,複寫是將實體從某個倉儲複製到另一個倉儲的程式。 重複可以套用至整個資料庫或較小的層級,例如數據表或分割區。 目標是讓每當基底實體變更時變更的複本。 Apache Hive 上的復寫著重於災害復原,並提供單向主要複寫。 在 HDInsight 叢集中,Hive 複寫可用來單向複寫 Hive 中繼存放區和 Azure Data Lake 儲存體 Gen2 上相關聯的基礎數據湖。
這些年來,Hive 復寫隨著較新版本的演進,提供更佳的功能,而且需要更快速且較少的資源。 在本文中,我們會討論 HDInsight 3.6 和 HDInsight 4.0 叢集類型支援的 Hive 複寫 (Replv2)。
replv2 的優點
Hive ReplicationV2 (也稱為 Replv2)在使用 Hive IMPORT-EXPORT 的第一個 Hive 復寫版本上具有下列優點:
- 事件型累加式複寫
- 時間點複寫
- 降低頻寬需求
- 減少中繼複本數目
- 復寫狀態會維持
- 限制式複寫
- 支援中樞和輪輻模型
- 支援 ACID 資料表 (在 HDInsight 4.0 中)
複寫階段
Hive 事件型復寫是在主要和次要叢集之間設定。 此複寫包含兩個不同的階段:啟動載入和累加式執行。
啟動
啟動載入的目的是執行一次,以將資料庫的基底狀態從主要復寫到次要資料庫。 您可以視需要設定啟動載入,以在需要啟用複寫的目標資料庫中包含資料表的子集。
累加執行
啟動載入之後,累加式執行會在主要叢集上自動執行,並在次要叢集上播放這些累加執行期間所產生的事件。 當次要叢集趕上主要叢集時,次要叢集會與主要的事件一致。
複寫命令
Hive 提供一組 REPL 命令 – DUMP、 LOAD和 STATUS - 來協調事件的流程。 此命令 DUMP 會產生主要叢集上所有 DDL/DML 事件的本機記錄。 LOAD此命令是延遲複製記錄至擷取複寫傾印輸出之元數據和數據的方法,而且會在目標叢集上執行。 STATUS此命令會從目標叢集執行,以提供成功複寫最近一次復寫負載的最新事件識別符。
設定複寫來源
開始復寫之前,請確定要復寫的資料庫已設定為複寫來源。 您可以使用 DESC DATABASE EXTENDED <db_name> 命令來判斷參數 repl.source.for 是否以原則名稱設定。
如果已排程原則且 repl.source.for 未設定 參數,則必須先使用 ALTER DATABASE <db_name> SET DBPROPERTIES ('repl.source.for'='<policy_name>')來設定此參數。
ALTER DATABASE tpcds_orc SET DBPROPERTIES ('repl.source.for'='replpolicy1')
將元數據傾印至 Data Lake
命令REPL DUMP [database name]. => location / event_id會在啟動程序階段中使用,將相關的元數據傾印至 Azure Data Lake 儲存體 Gen2。 event_id指定已放入 Azure Data Lake 儲存體 Gen2 中相關元數據的最低事件。
repl dump tpcds_orc;
範例輸出︰
| dump_dir | last_repl_id |
|---|---|
| /tmp/hive/repl/38896729-67d5-41b2-90dc-46eeed4c5dd0 | 2925 |
將數據載入目標叢集
REPL LOAD [database name] FROM [ location ] { WITH ( ‘key1’=‘value1’{, ‘key2’=‘value2’} ) }命令可用來將數據載入目標叢集,以進行啟動程式與復寫的累加階段。 [database name]可以與目標叢集上的來源或不同名稱相同。 [location]表示先前REPL DUMP命令輸出中的位置。 這表示目標叢集應該能夠與來源叢集交談。 子 WITH 句主要已新增,以防止重新啟動目標叢集,允許複寫。
repl load tpcds_orc from '/tmp/hive/repl/38896729-67d5-41b2-90dc-46eeed4c5dd0';
輸出最後一個復寫的事件標識碼
REPL STATUS [database name]這個指令會在目標叢集上執行,並輸出最後一個複event_id寫的 。 此命令也可讓使用者知道其目標叢集已復寫到哪些狀態。 您可以使用此指令的輸出來建構下一個 REPL DUMP 用於累加式複寫的命令。
repl status tpcds_orc;
範例輸出︰
| last_repl_id |
|---|
| 2925 |
將相關數據和元數據傾印至 Data Lake
REPL DUMP [database name] FROM [event-id] { TO [event-id] } { LIMIT [number of events] }此命令可用來將相關的元數據和數據傾印至 Azure Data Lake 儲存體。 此命令會用於累加階段,並在來源倉儲上執行。 FROM [event-id]累加階段需要 ,而且的值event-id可以藉由在目標倉儲上執行 REPL STATUS [database name] 命令來衍生。
repl dump tpcds_orc from 2925;
範例輸出︰
| dump_dir | last_repl_id |
|---|---|
| /tmp/hive/repl/38896729-67d5-41b2-90dc-466466agad0 | 2960 |
Hive 複寫程式
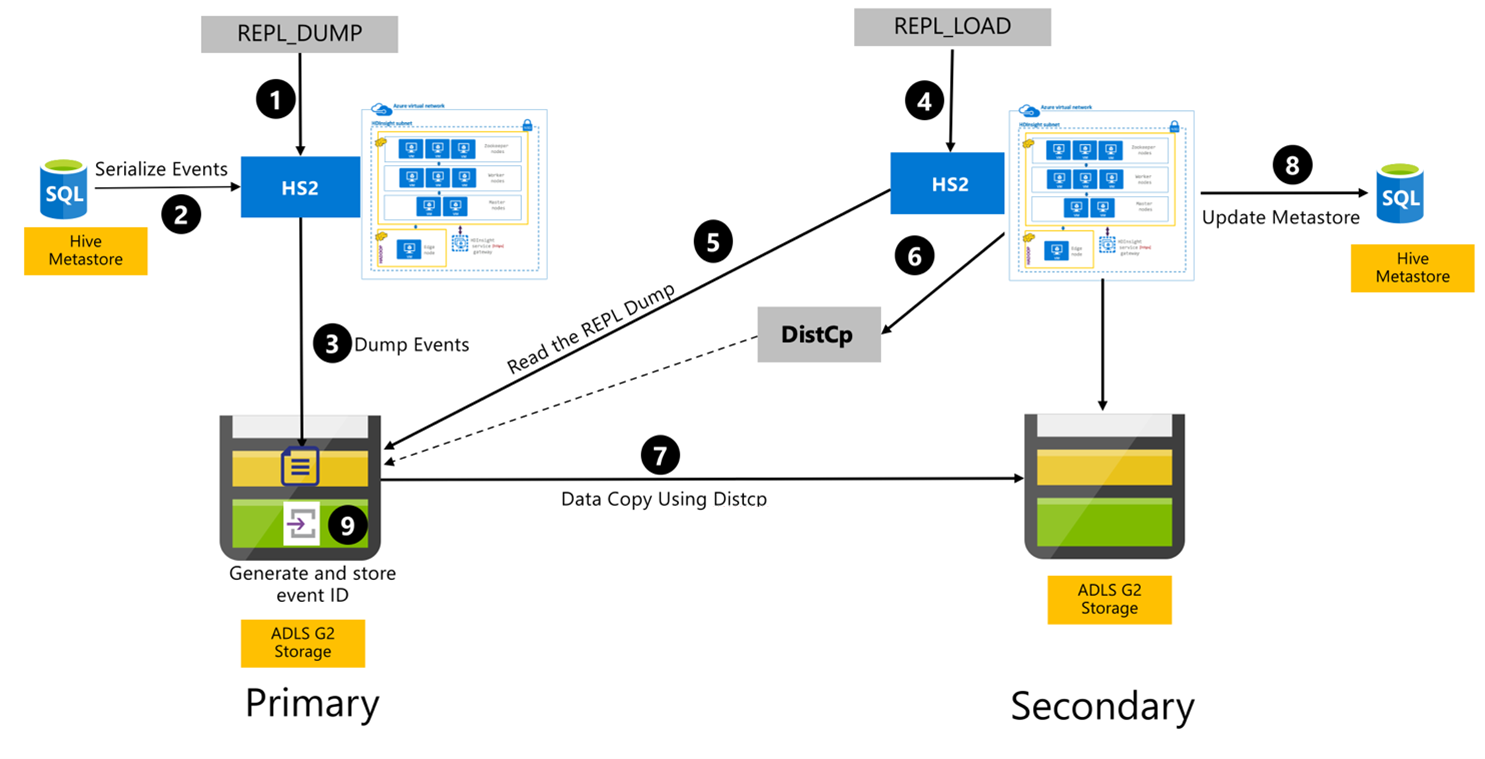
下列步驟是Hive複寫程式期間發生的循序事件。
確定要復寫的數據表已設定為特定原則的復寫來源。
此命令
REPL_DUMP會發出給主要叢集,其中包含相關聯的條件約束,例如資料庫名稱、事件標識符範圍,以及 Azure Data Lake 儲存體 Gen2 儲存體 URL。系統會將所有追蹤事件的傾印串行化,從中繼存放區到最新的事件。 此傾印會儲存在主要叢集上的 Azure Data Lake 儲存體 Gen2 儲存器帳戶中,且 URL 是由 所
REPL_DUMP指定的。主要叢集會將復寫元數據保存到主要叢集的 Azure Data Lake 儲存體 Gen2 記憶體。 路徑可在Ambari的Hive設定UI中設定。 此程式提供儲存元數據的路徑,以及最新追蹤 DML/DDL 事件的識別碼。
此命令
REPL_LOAD會從次要叢集發出。 命令會指向步驟 3 中所設定的路徑。次要叢集會讀取元數據檔案,其中包含在步驟 3 中建立的追蹤事件。 確定次要叢集具有與儲存所追蹤事件
REPL_DUMP之主要叢集之 Azure Data Lake 儲存體 Gen2 記憶體的網路連線。次要叢集會產生分散式複本 (
DistCP) 計算。次要叢集會從主要叢集的記憶體複製數據。
次要叢集上的中繼存放區已更新。
最後一個追蹤的事件標識符會儲存在主要中繼存放區中。
累加式複寫會遵循相同的程式,而且需要最後一個復寫的事件標識碼做為輸入。 這會導致自上次復寫事件之後的累加複製。 累加式複寫通常會以預先決定的頻率自動化,以達到必要的恢復點目標(RPO)。
複寫模式
復寫通常會以主要和次要之間的單向方式進行設定,其中主要復寫會迎合讀取和寫入要求。 次要叢集只迎合讀取要求。 如果發生災害,則次要復寫允許寫入,但需要將反向複寫設定回主要複寫。
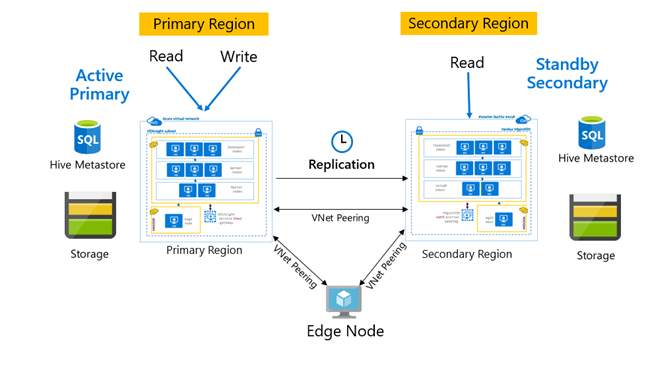
有許多模式適用於Hive複寫,包括主要 – 次要、中樞和輪輻和轉接。
在 HDInsight 作用中主要 – 待命次要復本是常見的商務持續性和災害復原 (BCDR) 模式,HiveReplicationV2 可以搭配具有 VNet 對等互連的區域分隔 HDInsight Hadoop 叢集使用此模式。 與這兩個叢集對等互連的通用虛擬機可用來裝載復寫自動化腳本。 如需可能 HDInsight BCDR 模式的詳細資訊,請參閱 HDInsight 商務持續性檔。
使用企業安全性套件的Hive複寫
在具有企業安全性套件的 HDInsight Hadoop 叢集上規劃 Hive 複寫的情況下,您必須考慮 Ranger 中繼存放區和 Microsoft Entra Domain Services 的復寫機制。
使用 Microsoft Entra Domain Services 複本集功能,為每個跨多個區域的 Microsoft Entra 租使用者建立多個 Microsoft Entra Domain Services 複本集。 每個個別的復本集都必須與其各自區域中的 HDInsight VNet 對等互連。 在此設定中,Microsoft Entra Domain Services 的變更,包括設定、使用者身分識別和認證、群組、組策略對象、計算機物件和其他變更,都會使用 Microsoft Entra Domain Services 複寫,套用至受控網域中的所有複本集。
Ranger 原則可以使用 Ranger 匯入-匯出功能,定期備份並從主要復寫至次要複寫。 您可以選擇根據您要在次要叢集上實作的授權層級,複寫所有或 Ranger 原則的子集。
範例指令碼
下列程式代碼順序提供如何在稱為 tpcds_orc的範例數據表上實作啟動載入和累加式複寫。
將數據表設定為複製策略的來源。
ALTER DATABASE tpcds_orc SET DBPROPERTIES ('repl.source. for'='replpolicy1');主要叢集的啟動程序傾印。
repl dump tpcds_orc with ('hive.repl.rootdir'='/tmpag/hiveag/replag');範例輸出︰
dump_dir last_repl_id /tmpag/hiveag/replag/675d1bea-2361-4cad-bcbf-8680d305a27a 2925 在次要叢集載入啟動程式。
repl load tpcds_orc from '/tmpag/hiveag/replag 675d1bea-2361-4cad-bcbf-8680d305a27a';REPL檢查次要叢集的狀態。repl status tpcds_orc;last_repl_id 2925 主要叢集上的累加傾印。
repl dump tpcds_orc from 2925 with ('hive.repl.rootdir'='/tmpag/hiveag/ replag');範例輸出︰
dump_dir last_repl_id /tmpag/hiveag/replag/31177ff7-a40f-4f67-a613-3b64ebe3bb31 2960 次要叢集的累加式載入。
repl load tpcds_orc from '/tmpag/hiveag/replag/31177ff7-a40f-4f67-a613-3b64ebe3bb31';檢查
REPL次要叢集的狀態。repl status tpcds_orc;last_repl_id 2960
下一步
若要深入瞭解本文所討論的專案,請參閱: