了解如何設定 HDInsight 上的 Apache Kafka 所使用的受控磁碟數目。
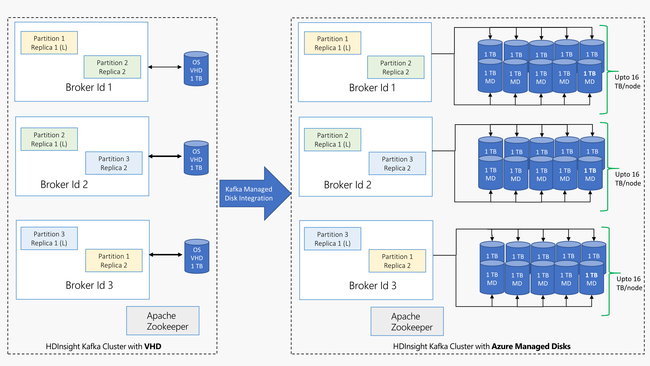
HDInsight 上的 Kafka 會在 HDInsight 叢集中使用虛擬機器的本機磁碟。 由於 Kafka 的 I/O 非常大量,因此會使用 Azure 受控磁碟來提供高輸送量,並提供每個節點更多儲存空間。 如果將傳統的虛擬硬碟 (VHD) 用於 Kafka,每個節點就會限制為 1 TB。 使用受控磁碟時,您可以利用多個磁碟在叢集中的每個節點達到 16 TB。
下圖提供 HDInsight 上的 Kafka 採用受控磁碟之前與 HDInsight 上的 Kafka 採用受控磁碟之間的比較:
設定受控磁碟:Azure 入口網站
請遵循建立 HDInsight 叢集中的步驟,了解使用入口網站建立叢集的一般步驟。 請勿完成入口網站建立程序。
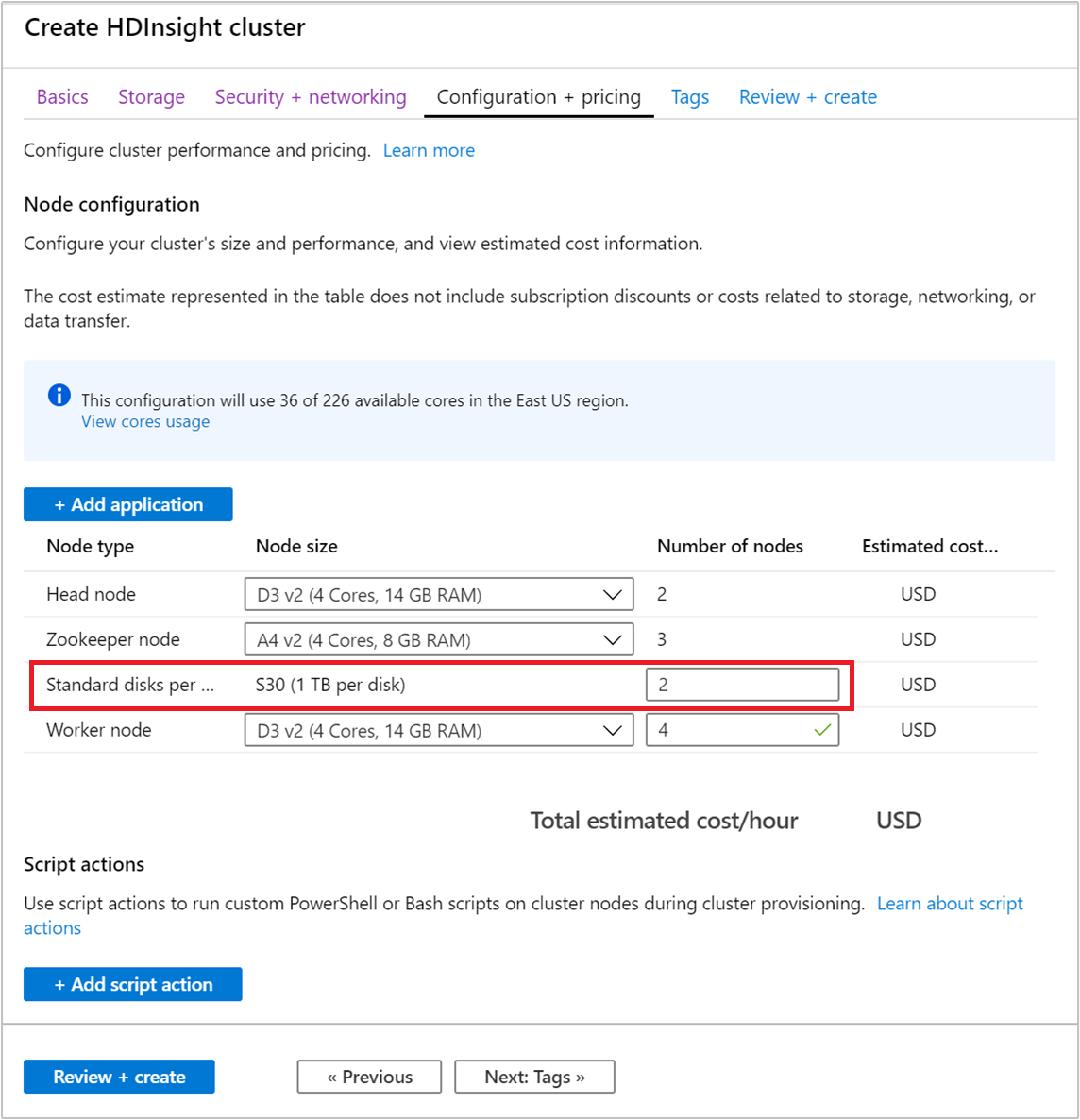
從 [設定與價格] 區段中,使用 [節點數目] 欄位,以設定磁碟數目。
注意
受控磁碟的類型可以是標準 (HDD) 或進階 (SSD)。 進階磁碟會與 DS 和 GS 系列搭配使用。 所有其他的 VM 類型是使用標準磁碟。
設定受控磁碟:Resource Manager 範本
若要控制背景工作角色節點在 Kafka 叢集中所使用的磁碟數目,請使用下列區段的範本:
"dataDisksGroups": [
{
"disksPerNode": "[variables('disksPerWorkerNode')]"
}
],
下一步
如需使用 HDInsight 上 Apache Kafka 的詳細資訊,請參閱下列文件: