此筆記本示範如何使用自定義連結庫搭配 HDInsight 上的 Apache Spark 分析記錄數據。 我們使用的自定義連結庫是稱為 iislogparser.py 的 Python 連結庫。
必要條件
HDInsight 上的 Apache Spark 叢集。 如需指示,請參閱在 Azure HDInsight 中建立 Apache Spark 叢集。
將原始資料儲存為 RDD
在本節中,我們使用 與 HDInsight 中 Apache Spark 叢集相關聯的 Jupyter Notebook 來執行處理原始範例數據的作業,並將其儲存為 Hive 數據表。 根據預設,範例數據是所有叢集上可用的.csv檔案(hvac.csv)。
將數據儲存為 Apache Hive 數據表之後,在下一節中,我們將使用 Power BI 和 Tableau 等 BI 工具連線到 Hive 數據表。
從網頁瀏覽器瀏覽至
https://CLUSTERNAME.azurehdinsight.net/jupyter,其中CLUSTERNAME是叢集的名稱。建立新的 Notebook。 選取 [新增],然後選取 [PySpark]。
 Notebook“ border=”true“:::
Notebook“ border=”true“:::系統隨即會建立新 Notebook,並以 Untitled.pynb 的名稱開啟。 在頂端選取筆記本名稱,然後輸入好記的名稱。
由於您使用 PySpark 核心建立筆記本,因此不需要明確地建立任何內容。 當您執行第一個程式碼儲存格時,系統會自動為您建立 Spark 和 Hive 內容。 您可以從匯入此案例所需的類型開始。 將下列代碼段貼到空白儲存格中,然後按 Shift + Enter 鍵。
from pyspark.sql import Row from pyspark.sql.types import *使用叢集上已有的範例記錄數據建立 RDD。 您可以在存取與叢集相關聯的預設記憶體帳戶中的數據
\HdiSamples\HdiSamples\WebsiteLogSampleData\SampleLog\909f2b.log。 執行下列程式代碼:logs = sc.textFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/909f2b.log')擷取範例記錄集,以確認上一個步驟是否已順利完成。
logs.take(5)您應該會看到如下所示的文字:
[u'#Software: Microsoft Internet Information Services 8.0', u'#Fields: date time s-sitename cs-method cs-uri-stem cs-uri-query s-port cs-username c-ip cs(User-Agent) cs(Cookie) cs(Referer) cs-host sc-status sc-substatus sc-win32-status sc-bytes cs-bytes time-taken', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step2.png X-ARR-LOG-ID=2ec4b8ad-3cf0-4442-93ab-837317ece6a1 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 53175 871 46', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step3.png X-ARR-LOG-ID=9eace870-2f49-4efd-b204-0d170da46b4a 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 51237 871 32', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step4.png X-ARR-LOG-ID=4bea5b3d-8ac9-46c9-9b8c-ec3e9500cbea 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 72177 871 47']
使用自定義 Python 連結庫分析記錄數據
在上述輸出中,前幾行包含標頭資訊,而其餘的每一行都符合該標頭中所述的架構。 剖析這類記錄可能會很複雜。 因此,我們使用自定義 Python 連結庫 (iislogparser.py),讓剖析這類記錄變得更容易。 根據預設,此連結庫會隨附於 HDInsight 上的 Spark 叢集。
/HdiSamples/HdiSamples/WebsiteLogSampleData/iislogparser.py不過,此連結庫不在 中
PYTHONPATH,因此無法使用匯入語句,例如import iislogparser。 若要使用此連結庫,我們必須將其散發給所有背景工作節點。 執行下列代碼段。sc.addPyFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/iislogparser.py')iislogparser提供函式,這個函parse_log_line式會在記錄行是標頭數據列時傳回None,並在遇到記錄行時傳回 類別的LogLine實例。 使用 類別LogLine僅從 RDD 擷取記錄行:def parse_line(l): import iislogparser return iislogparser.parse_log_line(l) logLines = logs.map(parse_line).filter(lambda p: p is not None).cache()擷取幾個擷取的記錄行,以確認步驟是否已順利完成。
logLines.take(2)輸出應該類似下列文字:
[2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step2.png X-ARR-LOG-ID=2ec4b8ad-3cf0-4442-93ab-837317ece6a1 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 53175 871 46, 2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step3.png X-ARR-LOG-ID=9eace870-2f49-4efd-b204-0d170da46b4a 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 51237 871 32]類別
LogLine接著會有一些有用的方法,例如is_error(),它會傳回記錄專案是否有錯誤碼。 使用此類別來計算擷取記錄行中的錯誤數目,然後將所有錯誤記錄到不同的檔案。errors = logLines.filter(lambda p: p.is_error()) numLines = logLines.count() numErrors = errors.count() print 'There are', numErrors, 'errors and', numLines, 'log entries' errors.map(lambda p: str(p)).saveAsTextFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/909f2b-2.log')輸出應該會指出
There are 30 errors and 646 log entries。您也可以使用 Matplotlib 來建構數據的視覺效果。 例如,如果您想要隔離長時間執行的要求原因,您可能會想要尋找平均使用最多時間的檔案。 下列代碼段會擷取前 25 個資源,這些資源花費了最多時間來處理要求。
def avgTimeTakenByKey(rdd): return rdd.combineByKey(lambda line: (line.time_taken, 1), lambda x, line: (x[0] + line.time_taken, x[1] + 1), lambda x, y: (x[0] + y[0], x[1] + y[1]))\ .map(lambda x: (x[0], float(x[1][0]) / float(x[1][1]))) avgTimeTakenByKey(logLines.map(lambda p: (p.cs_uri_stem, p))).top(25, lambda x: x[1])您應該會看到如下文字的輸出:
[(u'/blogposts/mvc4/step13.png', 197.5), (u'/blogposts/mvc2/step10.jpg', 179.5), (u'/blogposts/extractusercontrol/step5.png', 170.0), (u'/blogposts/mvc4/step8.png', 159.0), (u'/blogposts/mvcrouting/step22.jpg', 155.0), (u'/blogposts/mvcrouting/step3.jpg', 152.0), (u'/blogposts/linqsproc1/step16.jpg', 138.75), (u'/blogposts/linqsproc1/step26.jpg', 137.33333333333334), (u'/blogposts/vs2008javascript/step10.jpg', 127.0), (u'/blogposts/nested/step2.jpg', 126.0), (u'/blogposts/adminpack/step1.png', 124.0), (u'/BlogPosts/datalistpaging/step2.png', 118.0), (u'/blogposts/mvc4/step35.png', 117.0), (u'/blogposts/mvcrouting/step2.jpg', 116.5), (u'/blogposts/aboutme/basketball.jpg', 109.0), (u'/blogposts/anonymoustypes/step11.jpg', 109.0), (u'/blogposts/mvc4/step12.png', 106.0), (u'/blogposts/linq8/step0.jpg', 105.5), (u'/blogposts/mvc2/step18.jpg', 104.0), (u'/blogposts/mvc2/step11.jpg', 104.0), (u'/blogposts/mvcrouting/step1.jpg', 104.0), (u'/blogposts/extractusercontrol/step1.png', 103.0), (u'/blogposts/sqlvideos/sqlvideos.jpg', 102.0), (u'/blogposts/mvcrouting/step21.jpg', 101.0), (u'/blogposts/mvc4/step1.png', 98.0)]您也可以以繪圖形式呈現此資訊。 作為建立繪圖的第一個步驟,讓我們先建立臨時表 AverageTime。 數據表會依時間將記錄分組,以查看在任何特定時間是否有任何不尋常的延遲尖峰。
avgTimeTakenByMinute = avgTimeTakenByKey(logLines.map(lambda p: (p.datetime.minute, p))).sortByKey() schema = StructType([StructField('Minutes', IntegerType(), True), StructField('Time', FloatType(), True)]) avgTimeTakenByMinuteDF = sqlContext.createDataFrame(avgTimeTakenByMinute, schema) avgTimeTakenByMinuteDF.registerTempTable('AverageTime')然後,您可以執行下列 SQL 查詢,以取得 AverageTime 數據表中的所有記錄。
%%sql -o averagetime SELECT * FROM AverageTime%%sqlmagic 後面緊接著-o averagetime可確保查詢的輸出會保存在 Jupyter 伺服器的本機上 (通常是叢集的前端節點)。 輸出會保存為具有指定名稱 averagetime 的 Pandas 數據框架。您應該會看到類似下圖的輸出:
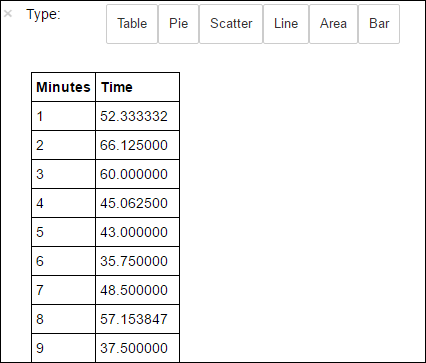 yter sql 查詢輸出“ border=”true“:::
yter sql 查詢輸出“ border=”true“:::如需魔術的詳細資訊
%%sql,請參閱 %%sql magic 支援的參數。您現在可以使用 Matplotlib,這是用來建構數據視覺效果的連結庫,用來建立繪圖。 由於繪圖必須從本機保存的 averagetime 數據框架建立,代碼段必須以 magic 開頭
%%local。 這可確保程式代碼會在 Jupyter 伺服器上本機執行。%%local %matplotlib inline import matplotlib.pyplot as plt plt.plot(averagetime['Minutes'], averagetime['Time'], marker='o', linestyle='--') plt.xlabel('Time (min)') plt.ylabel('Average time taken for request (ms)')您應該會看到類似下圖的輸出:
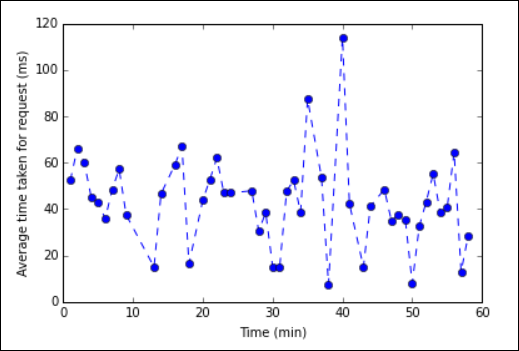 eb log analysis plot“ border=”true“::
eb log analysis plot“ border=”true“::應用程式執行完畢之後,您應該關閉 Notebook 以釋放資源。 若要這麼做,請從 Notebook 的 [檔案] 功能表中,選取 [關閉並終止]。 此動作將會關閉並關閉筆記本。
下一步
探索下列文章: