瞭解如何在 HDInsight 的 Apache Spark 叢集中,將 Jupyter Notebook 設定為使用外部、社群提供的 Apache maven 套件 (不是叢集中現成可用的)。
您可以搜尋 Maven 儲存機制 來取得可用套件的完整清單。 您也可以從其他來源取得可用套件清單。 例如,從 Spark 套件可以取得社群提供套件的完整清單。
在這篇文章中,您將瞭解如何搭配 Jupyter Notebook 使用 spark-csv 套件。
必要條件
HDInsight 上的 Apache Spark 叢集。 如需指示,請參閱在 Azure HDInsight 中建立 Apache Spark 叢集。
熟悉如何搭配使用 Jupyter Notebook 和 HDInsight 上的 Spark。 如需詳細資訊,請參閱使用 HDInsight 上的 Apache Spark 載入資料及執行查詢。
您叢集主要儲存體的 URI 配置。 適用於 Azure 儲存體的
wasb://,適用於 Azure Data Lake Storage Gen2 的abfs://。 如果針對 Azure 儲存體或 Data Lake Storage Gen2 已啟用安全傳輸,則 URI 分別會是wasbs://或abfss://。另請參閱安全傳輸。
搭配 Jupyter Notebook 使用外部套件
瀏覽至
https://CLUSTERNAME.azurehdinsight.net/jupyter,其中CLUSTERNAME是 Spark 叢集的名稱。建立新的 Notebook。 選取 [新增],然後選取 [Spark]。
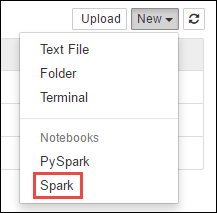
系統隨即會建立新 Notebook,並以 Untitled.pynb 的名稱開啟。 在頂端選取筆記本名稱,然後輸入好記的名稱。
您將使用
%%configuremagic 來設定讓筆記本使用外部套件。 在使用外部套件的 Notebook 中,確定您在第一個程式碼單元中呼叫%%configuremagic。 這可確保將核心設定為在啟動工作階段之前即使用此套件。重要
如果您忘記在第一個單元中設定核心,您可以搭配
-f參數使用%%configure,但這會重新啟動工作階段,而所有進度都將遺失。HDInsight 版本 Command HDInsight 3.5 和 HDInsight 3.6 %%configure{ "conf": {"spark.jars.packages": "com.databricks:spark-csv_2.11:1.5.0" }}HDInsight 3.3 和 HDInsight 3.4 %%configure{ "packages":["com.databricks:spark-csv_2.10:1.4.0"] }對於 Maven 中央儲存機制中的外部套件,上述程式碼片段預期會使用 Maven 座標。 在此程式碼片段中,
com.databricks:spark-csv_2.11:1.5.0是 spark-csv 套件的 maven 座標。 以下說明如何建立套件的座標。a. 在「Maven 儲存機制」中找出套件。 在本文中,我們使用 spark-csv。
b. 從儲存機制收集 [GroupId]、[ArtifactId] 及 [版本] 的值。 確定您收集的值符合您的叢集。 在此案例中,我們使用 Scala 2.11 與 Spark 1.5.0 套件,但您可能必須為叢集中的適當 Scala 或 Spark 版本選取不同的版本。 您可以透過在 Spark Jupyter 核心或 Spark 提交上執行
scala.util.Properties.versionString以查看您叢集上的 Scala 版本。 您可以透過在 Jupyter Notebook 上執行sc.version以查看叢集上的 Spark 版本。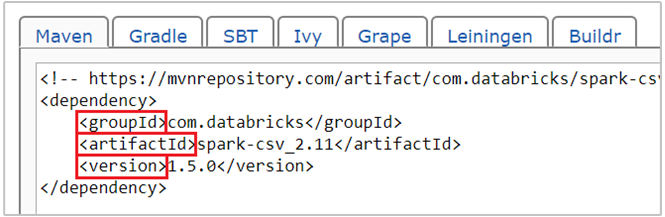
c. 串連三個值,其中以冒號分隔 (:)。
com.databricks:spark-csv_2.11:1.5.0以
%%configuremagic 執行程式碼單元。 這會將基礎 Livy 工作階段設定為使用您提供的套件。 在 Notebook 的後續單元中,您現在已可以使用套件,如以下所示。val df = spark.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")對於 HDInsight 3.4 和更低版本,您應該使用下列程式碼片段。
val df = sqlContext.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")接著,您可以執行程式碼片段 (如以下所示) 以檢視來自您在上一個步驟中所建立之資料框架的資料。
df.show() df.select("Time").count()
另請參閱
案例
- Apache Spark 和 BI:在 HDInsight 中搭配 BI 工具使用 Spark 執行互動式資料分析
- Apache Spark 和機器學習服務:使用 HDInsight 中的 Spark,使用 HVAC 資料來分析建築物溫度
- Apache Spark 和機器學習服務:在 HDInsight 中使用 Spark 預測食品檢查結果
- 在 HDInsight 中使用 Apache Spark 進行網站記錄分析
建立及執行應用程式
工具和延伸模組
- 在 HDInsight Linux 上的 Apache Spark 叢集中搭配 Jupyter Notebook 使用外部 Python 套件
- 使用 IntelliJ IDEA 的 HDInsight Tools 外掛程式來建立和提交 Spark Scala 應用程式
- 使用適用於 IntelliJ IDEA 的 HDInsight 工具外掛程式遠端偵錯 Apache Spark 應用程式
- 在 HDInsight 上搭配使用 Apache Zeppelin Notebook 和 Apache Spark 叢集
- 在適用於 HDInsight 的 Apache Spark 叢集中可供 Jupyter Notebook 使用的核心
- 在電腦上安裝 Jupyter 並連接到 HDInsight Spark 叢集